
Are you interested in building a chatbot that can read your PDF documents and answer questions about their content? In this tutorial, I’ll show you how to create a chatbot using OpenAI’s GPT language model and the Streamlit library for Python. We’ll also use the LangChain library for natural language processing tasks.
Below, you’ll find a step-by-step guide to creating a chatbot like the one in chatpdf.com, which can answer questions about a PDF file you upload.
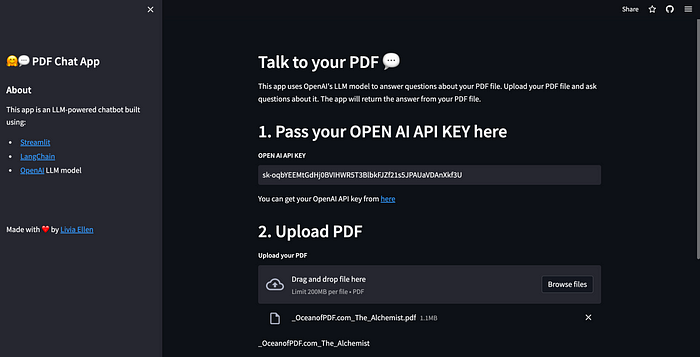
This is the website we are going to create:
https://ask-gpt-pdf.streamlit.app/
The best part is that user can use their own OpenAI API key to use it. User can get their OpenAI API key from here.
Whether you need to extract information from reports, academic papers, or any other PDF document, this tool can save you time and effort.
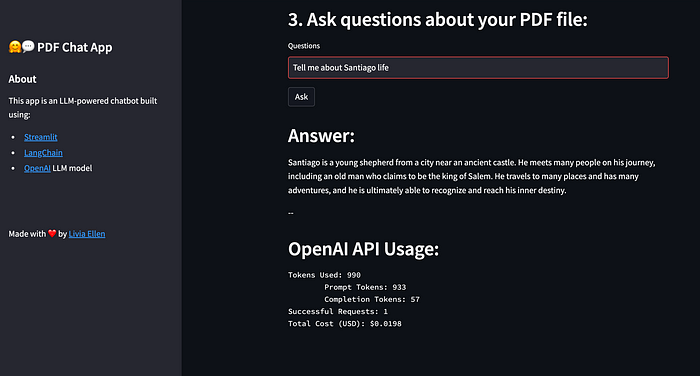
Furthermore, this tool can also provide you with information about the cost of each question answered. This feature allows you to keep track of your API usage and expenses.
In this tutorial, we’ll show you how to create this chat PDF tool using OpenAI’s GPT language model, Streamlit, and LangChain. The chat PDF tool will answer questions about the content of any uploaded PDF file.
Prerequisites
Make sure you have Python 3.10.6 installed on your machine.
You need two files for this project: requirements.txt and app.py.
You’ll also need the following Python libraries, add these to the requirements.txt excluding the bullet point / dash.
- langchain==0.0.154
- PyPDF2==3.0.1
- python-dotenv==1.0.0
- streamlit==1.18.1
- faiss-cpu==1.7.4
- streamlit-extras
- altair==4.1.0
- openai
- tiktoken
You can install them using the following command:
pip install -r requirements.txt
Step-by-Step Guide to create app.py
1. Set up Streamlit
First, initialize Streamlit with the desired page title and create a sidebar with relevant information:
st.set_page_config(page_title=’🤗💬 PDF Chat App — GPT’)
with st.sidebar:
st.title('🤗💬 PDF Chat App')
st.markdown('## About')
st.markdown('This app is an LLM-powered chatbot built using:')
st.markdown('- [Streamlit](https://streamlit.io/)')
st.markdown('- [LangChain](https://python.langchain.com/)')
st.markdown('- [OpenAI](https://platform.openai.com/docs/models) LLM model')
add_vertical_space(5)
st.write('Made with ❤️ by [Livia Ellen](https://liviaellen.com/portfolio)')
2. Create Main Function
Next, define the main function of the app that will handle user interactions:
def main():
#…
3. Gather User Inputs
Prompt the user for their OpenAI API key, let them upload a PDF file, and input a question:
st.header("1. Pass your OPEN AI API KEY here")
openai_key = st.text_input("**OPEN AI API KEY**")
st.write("You can get your OpenAI API key from [here](https://beta.openai.com/account/api-keys)")
os.environ["OPENAI_API_KEY"] = openai_key
st.header("2. Upload PDF")
pdf = st.file_uploader("**Upload your PDF**", type='pdf')
st.header("3. Ask questions about your PDF file:")
query = st.text_input("Questions", value="Tell me about the content of the PDF")
4. Process the PDF file
Once the user uploads a PDF, extract the text from the PDF and split it into manageable chunks:
if pdf is not None:
pdf_reader = PdfReader(pdf)
text = ""
for page in pdf_reader.pages:
text += page.extract_text()
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=1000,
chunk_overlap=200,
length_function=len
)
chunks = text_splitter.split_text(text=text)
5. Create Embeddings
Now, create embeddings for the text chunks using the OpenAIEmbeddings class from LangChain:
file_name = pdf.name[:-4]
if os.path.exists(f"{file_name}.pkl"):
with open(f"{file_name}.pkl", "rb") as f:
VectorStore = pickle.load(f)
else:
embeddings = OpenAIEmbeddings()
VectorStore = FAISS.from_texts(chunks, embedding=embeddings)
with open(f"{file_name}.pkl", "wb") as f:
pickle.dump(VectorStore, f)
6. Answer Questions
Use the LangChain library and the OpenAI model to answer the user’s questions based on the PDF content:
if st.button("Ask"):
if openai_key == '':
st.write('Warning: Please pass your OPEN AI API KEY on Step 1')
else:
docs = VectorStore.similarity_search(query=query, k=3)
llm = OpenAI()
chain = load_qa_chain(llm=llm, chain_type="stuff")
with get_openai_callback() as cb:
response = chain.run(input_documents=docs, question=query)
st.header("Answer:")
st.write(response)
st.write('--')
st.header("OpenAI API Usage:")
st.text(cb)
7. Run the Streamlit App
Finally, add the following lines to run the Streamlit app:
Finally, add the following lines to run the Streamlit app:
if __name__ == '__main__':
main()
Launch the app with the following command in terminal:
streamlit run app.py
Once you are done, you can upload it to github and host it in share.streamlit.io for free.
Conclusion
In this tutorial, we created a chatbot that can answer questions about a PDF’s content using the OpenAI GPT language model, Streamlit, and LangChain. This chatbot can help you extract information from PDFs without having to read the entire document. Try it out and see how it can assist you in navigating and understanding your PDF files more efficiently.
Resources
You can access the complete code for this project on the following GitHub repository:
https://github.com/liviaellen/ask_pdf
Feel free to clone or fork the repository and experiment with the code. Modify the code to suit your specific needs or use it as a base for your own projects. Don’t forget to star the repository if you find it useful!
Comments
Loading comments…