
1. Introduction
Transitioning machine learning (ML) models from proof of concept to production is a crucial step for data scientists, yet it often poses significant challenges. One of the main hurdles lies in deploying locally trained models to the cloud for scalable inference and integration into various applications. However, with the right approach, this process can be streamlined, minimizing effort and maximizing efficiency.
FastAPI stands out as a modern, high-performance web framework tailored for API development with Python. Known for its user-friendly interface and scalability, it has become a preferred choice among developers.
AWS Lambda offers a direct pathway to expose models and deploy ML applications using your preferred open-source framework, providing flexibility and cost-effectiveness.
This blog post demonstrates a straightforward approach to deploying and running serverless ML inference, exposing your ML model using FastAPI, Docker, Lambda, and API Gateway.
1.1 Introduction to FastAPI
FastAPI emerges as a standout choice in this area, offering a modern, high-performance web framework for building APIs with Python. It excels in developing serverless applications, especially for RESTful microservices and ML inference at scale. With built-in features such as automatic API documentation, FastAPI simplifies the deployment of high-performance inference APIs. Combining the strengths of established frameworks like Flask and Django with its innovations, FastAPI is built on the Starlette asynchronous web framework, ensuring efficient management of concurrent requests and high traffic loads.
Leveraging FastAPI you can effortlessly scale out and manage complex business logic, testing locally and hosting on Lambda, then exposing through a unified API gateway, seamlessly integrating the power of an open-source web framework into Lambda without requiring extensive code refactoring.
1.2 Why FastAPI
- High Performance: FastAPI harnesses
asynchronouscapabilities and type hints to optimize web framework performance. - Ease of Use: With a declarative approach and auto-generated documentation, FastAPI simplifies API development and maintenance.
- Type Safety: Leveraging type hints, FastAPI ensures robust data validation and serialization, enhancing code reliability and readability.
- Compatibility: Seamlessly integrating with popular Python libraries and frameworks such as Pydantic enhances developer productivity.
- Scalability: FastAPI’s asynchronous architecture enables it to handle high loads and concurrent requests effectively.
2. Setting Up the Project
Before diving into development, establishing the project environment is crucial. This involves installing FastAPI along with any necessary dependencies for our API. Utilizing virtual environments ensures a secure development setup.
2.1 Creating the Environment
Creating a virtual environment is fundamental for project development, offering numerous benefits such as dependency isolation, reproducibility, and collaboration facilitation. It guarantees that project dependencies are contained, permits precise package version specification, and ensures a tidy development environment.
To Create a Virtual Environment:
- Open the command prompt.
- Navigate to the project directory using the
cdcommand.
Create a virtual environment using the command:
python -m venv myenv
Activate the virtual environment with:
myenv\Scripts\activate
2.2 Installing dependencies and libraries
After creating and activating the environment, the next step is to install the necessary dependencies for your project. Dependencies are additional packages or libraries that your project relies on to function properly. To install dependencies, you can use a package manager such as pip, or you can use the following command to install all at once:
pip install -r requirements.txt
By installing dependencies, you ensure that your project has access to the required functionality and libraries. It’s important to keep track of the dependencies and their versions to maintain consistency and avoid compatibility issues.
3. Preparing the Model
3.1 Quick Overview of the Diabetes Prediction Model
The integrated prediction model within this API is a classification model tailored for diabetes prediction. This dataset is originally from the National Institute of Diabetes and Digestive and Kidney Diseases. The objective is to predict based on diagnostic measurements whether a patient has diabetes.
Utilizing input features, it delivers binary predictions for diabetes status, categorizing them as either 1 (indicating a positive prediction) or 0 (representing a negative prediction).
3.2 Storing the ML Components into Pickle Files
The classification model, feature pipeline, and all other ML components were saved as pickle files. This approach ensures model persistence, enabling effortless saving and loading while preserving its state and parameters, thereby enhancing portability and ease of deployment.
To save the trained model, the following code snippet was executed in the notebook:
import pandas as pd
import numpy as np
import pickle
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import f1_score, accuracy_score, roc_auc_score
# Read data into pandas dataframe
df=pd.read_csv('.\\data\\diabetes.csv')
#spliting data into 80% train and 20% test
train, test = train_test_split(df, test_size=0.2, random_state=42)
print(f'Train: {train.shape}, Test: {test.shape}')
# create features and targets from the train data
X_train = train.drop(columns=['Outcome'])
y_train = train['Outcome'].copy()
# create features and targets from test data
X_test = test.drop(columns=['Outcome'])
y_test = test['Outcome'].copy()
#model train
model = RandomForestClassifier(n_estimators=50, n_jobs=1,random_state=8)
model.fit(X_train, y_train)
# create predictions
y_pred = model.predict(X_test)
#evaluate
accuracy_score(y_pred, y_test), f1_score(y_pred, y_test)
#save all ML components to pickle
model_filename = './artifacts/model.pkl'
with open(model_filename, 'wb') as model_file:
pickle.dump(model, model_file)
To save all ML components, including the model, preprocessing steps, and any other relevant objects, here's a general approach to saving all components to a single pickle file:
import pickle
# Define your model and preprocessing steps
model = model # Your trained machine learning model
preprocessor = preprocessor # Your preprocessing steps (e.g., scaler, encoder, etc.)
# Other relevant objects
other_objects = {
'key1': value1,
'key2': value2,
# Add any other relevant objects here
}
# Combine all components into a dictionary
ml_components = {
'model': model,
'preprocessor': preprocessor,
**other_objects
}
# Save all components to a pickle file
with open('ml_components.pkl', 'wb') as f:
pickle.dump(ml_components, f)
4. Building the API
Let’s install FastAPI and Uvicorn. Uvicorn is a dependency of FastAPI and is the library that will build and manage the server.
Uvicorn is the server that is used to run and test our APIs. Uvicorn is an ASGI web server implementation for Python.
pip install fastapi uvicorn
4.1 Designing the API
The most important part of this repository is the Serverless-Deployment-Using-FastAPI-AWS directory. It contains the code and the resources that are going to be used for model serving.
data- Training dataartifacts- This directory containsmodel_endpointormodel.pickle, and all the ML components necessary that make up our serverless endpoint.Dockerfile– Dockerfile to build the Docker image that Lambda will use, the Lambda function code that uses FastAPI to handle inference requests and route them to the correct endpoint, and the model artifacts of the model that we want to deploy.requirements.txt– The code for the Lambda function and its dependencies specified.app.py– Contains the code that implements a Lambda function that wraps a FastAPI endpoint around an existing API gatewayutils.py– This includes an inference script that loads the necessary model artifacts so that the model can be passed to theapp.pythat will then expose it as an endpoint.
4.2 API Endpoints
- Root Endpoint: This endpoint serves as the entry point, welcoming users with a friendly message — “Welcome to the Diabetes API”.
- Health Check Endpoint: To ensure the API’s reliability, a health check endpoint is important. We’ll implement a straightforward endpoint to monitor the API’s status, affirming its operational state.
- Model Information Endpoint: Providing transparency, this endpoint furnishes details about the underlying model. It fetches the model’s name, parameters, and both categorical and numerical features utilized during training.
- Individual Prediction Endpoint: Catering to single predictions, this endpoint accepts input parameters and delivers predictions for individual data records. It’s a handy tool for users seeking predictions on a singular data point.
- Batch Prediction Endpoint: Streamlining predictions for multiple data points, this endpoint accepts a list of input records. It leverages our trained ML model to process the data and returns predictions for each input, facilitating bulk predictions.
- Data Upload Endpoint: Addressing real-world scenarios, this endpoint empowers users to upload their data for prediction. Accepting data files or JSON/CSV formatted data, the API processes the input and delivers predictions using our ML model.
4.3 Integrating ML Components Into API
To make accurate predictions, we need to integrate a trained ML model with all other components into our API.
We can load the trained model directly, or we can leverage the Lifespan Events functionality that FastAPI offers for better optimization.
4.3.1 Lifespan Events
In FastAPI, a lifespan function can indeed help in loading machine learning models across multiple users by allowing for efficient initialization and cleanup tasks. Lifespan functions are special asynchronous functions that can be registered to execute when the application starts up (startup event) or shuts down (shutdown event). Leveraging these functions, you can preload machine learning models during startup, ensuring they are readily available to handle incoming requests from multiple users.
Here’s how a lifespan function can assist in loading machine learning models:
- Startup Initialization: You can define a startup event handler to load the machine learning model into memory when the FastAPI application starts up. This ensures that the model is loaded only once, regardless of the number of concurrent users or requests.
- Efficient Resource Management: By preloading the model during startup, you avoid the overhead of loading the model for each individual request. This improves the overall performance and responsiveness of your application, as users don’t experience delays associated with model loading.
- Shared Model Across Users: Since the model is loaded during startup and remains in memory throughout the application’s lifecycle, it can be shared across multiple users and requests. This eliminates the need to reload the model for each user, leading to better resource utilization and scalability.
- Auto Shutdown: Additionally, you can define a shutdown event handler to perform cleanup tasks, such as releasing resources associated with the model, when the application shuts down. This ensures proper resource management and prevents memory leaks.
Read more about it from the documentation:
import uvicorn
from fastapi import FastAPI, Request, File, UploadFile
from fastapi.responses import JSONResponse
from utils import load_pickle, make_prediction, process_label, process_json_csv, output_batch, return_columns
import pandas as pd
import pickle
from contextlib import asynccontextmanager
from typing import List
from pydantic import BaseModel
from mangum import Mangum
###### load model with Lifespan Events #######
# model prediction
def diabetes_predictor(x: dict) -> dict:
with open("./artifacts/model.pkl", 'rb') as model_file:
model = pickle.load(model_file)
data_df = pd.DataFrame(x, index=[0])
prediction = model.predict(data_df)
if(prediction[0]>0.5):
prediction="Diabetic"
else:
prediction="Non Diabetic"
return {'prediction': prediction}
# Life Span Management
ml_models = {}
@asynccontextmanager
async def ml_lifespan_manager(app: FastAPI):
ml_models["diabetes_predictor"] = diabetes_predictor
yield
ml_models.clear()
# Create an instance of FastAPI
app = FastAPI(lifespan=ml_lifespan_manager, debug=True)
4.3.2 Loading ML Components without Lifespan Events
For this example, we are using just 1 ML component i.e. ML Model, but a bigger application will have other components as well. We can load them at the start.
import pickle
model = load_pickle("./artifacts/ml_components.pkl")
# Access individual components
model = ml_components['model']
preprocessor = ml_components['preprocessor']
other = ml_components['other']
4.3.3 Handling Data Preprocessing
Before making predictions, it’s essential to preprocess the data appropriately. This involves performing various preprocessing steps, such as scaling, encoding, and handling missing values, to ensure that the input data meets the requirements of our machine-learning model. We will follow these steps for data handling and preprocessing.
A. Collecting and Validating Inputs
To improve your models in FastAPI, you can leverage Pydantic’s powerful features for data validation, serialization, and schema generation.
Pydantic allows you to define data models with type annotations, making it easy to validate incoming request data. By specifying data types, constraints, and default values, you can ensure that your API handles input data correctly and gracefully handles validation errors.
Pydantic models can be used to generate JSON Schema representations of your data models. This can be useful for validating JSON data against a schema or for generating documentation for clients consuming your API.
- Individual Prediction Endpoint: For individual predictions, input data is directly passed into the endpoint as variables, a Pydantic BaseModel is employed to validate input ensuring seamless integration and straightforward processing.
- Batch Prediction Endpoint: When handling batch predictions, a Pydantic BaseModel is employed to validate structured batch input. This ensures consistency and accuracy across multiple data points, enhancing the reliability of predictions.
- Data Upload Endpoint: Users have the option to upload JSON or CSV files for prediction via the data upload endpoint. These files undergo careful validation for format and structure compatibility to handle potential errors effectively.
# Input Data Validation
class ModelInput(BaseModel):
Pregnancies : int
Glucose : int
BloodPressure : int
SkinThickness : int
Insulin : int
BMI : float
DiabetesPedigreeFunction : float
Age : int
# Input for Batch prediction
class ModelInputs(BaseModel):
all: List[ModelInput]
def return_dict_inputs(cls):
return [dict(input) for input in cls.all]
B. Feature Engineering
After collecting and validating the data, the next step is to create the features that were used to train the model. This involves transforming and manipulating the raw data to extract or create the same input variables for the prediction model.
It will be done using the preprocessor you just loaded from the pickle.
C. Handling Upload File types
The function below is used to process JSON and CSV files into formats that can be converted into data frames and used for prediction.
def process_json_csv(contents, file_type, valid_formats):
# Read the file contents as a byte string
contents = contents.decode() # Decode the byte string to a regular string
new_columns = return_columns() # return new_columns
# Process the uploaded file
if file_type == valid_formats[0]:
data = pd.read_csv(StringIO(contents)) # read csv files
elif file_type == valid_formats[1]:
data = pd.read_json(contents) # read json file
dict_new_old_cols = dict(zip(data.columns, new_columns)) # get dict of new and old cols
data = data.rename(columns=dict_new_old_cols) # rename colums to appropriate columns
return data
D. Making a Prediction
Now, we will have to make a prediction using the API. The make_prediction function was created to achieve this purpose.
def make_prediction(data, model):
new_columns = return_columns()
dict_new_old_cols = dict(zip(data.columns, new_columns)) # create a dict of original columns and new columns
data = data.rename(columns=dict_new_old_cols)
# feature_engineering_encoding(data) # create new features
# make prediction
label = model.predict(data) # make a prediction
probs = model.predict_proba(data) # predit sepsis status for inputs
return label, probs.max()
E. Formatting outputs
The outputs when a post request is made to API need to be formatted in a proper format. The function output_batch takes care of that.
def output_batch(data1, labels):
data_labels = pd.DataFrame(labels, columns=['Predicted Label']) # convert label into a dataframe
data_labels['Predicted Label'] = data_labels.apply(process_label, axis=1) # change label to understanding strings
results_list = [] # create an empty lits
x = data1.to_dict('index') # convert datafram into dictionary
y = data_labels.to_dict('index') # convert datafram into dictionary
for i in range(len(y)):
results_list.append({i:{'inputs': x[i], 'output':y[i]}}) # append input and labels
final_dict = {'results': results_list}
return final_dict
4.3.4 Define routes and functions
Building endpoints for FastAPI involves defining routes and functions that handle HTTP requests. Each endpoint corresponds to a specific URL path and HTTP method (e.g., GET, POST, PUT, DELETE). Here’s a general guide on how to build endpoints in FastAPI.
Use the app object to define routes using the @app.route() decorator. Each route corresponds to a specific URL path and HTTP method.
# Create an instance of FastAPI
app = FastAPI(lifespan=ml_lifespan_manager, debug=True)
# Root endpoint
@app.get('/')
def index():
return {'message': 'Welcome to the Diabetes API'}
# Health check endpoint
@app.get("/health")
def check_health():
return {"status": "ok"}
# Model information endpoint
@app.post('/model-info')
async def model_info():
model_name = ml_models["diabetes_predictor"].__class__.__name__ # get model name
model_params = ml_models["diabetes_predictor"].get_params() # get model parameters
# model_name = model.__class__.__name__ # get model name
# model_params = model.get_params() # get model parameters
model_information = {'model info': {
'model name ': model_name,
'model parameters': model_params
}
}
return model_information # return model information
# Single Prediction endpoint
@app.post("/predict")
async def predict(model_input: ModelInput):
data = dict(model_input)
return ml_models["diabetes_predictor"](data)
# Batch prediction endpoint
@app.post('/predict-batch')
async def predict_batch(inputs: ModelInputs):
# Create a dataframe from inputs
data = pd.DataFrame(inputs.return_dict_inputs())
labels, probs = make_prediction(data, model) # Get the labels
response = output_batch(data, labels) # output results
return response
# Upload data endpoint
@app.post("/upload-data")
async def upload_data(file: UploadFile = File(...)):
file_type = file.content_type # get the type of the uploaded file
valid_formats = ['text/csv', 'application/json'] # create a list of valid formats API can receive
if file_type not in valid_formats:
return JSONResponse(content={"error": f"Invalid file format. Must be one of: {', '.join(valid_formats)}"}) # return an error if file type is not included in the valid formats
else:
contents = await file.read() # read contents in file
data= process_json_csv(contents=contents,file_type=file_type, valid_formats=valid_formats) # process files
labels, probs = make_prediction(data, model) # Get the labels
response = output_batch(data, labels) # output results
return response
5. Testing the API
Testing APIs across various endpoints is essential to ensure their functionality, reliability, and performance. Run this command on the terminal:
uvicorn app:app --reload
- Open your browser at http://127.0.0.1:8000. Now go to http://127.0.0.1:8000/docs. You will see the automatic interactive API documentation (provided by Swagger UI)
Interactive API by Swagger UI
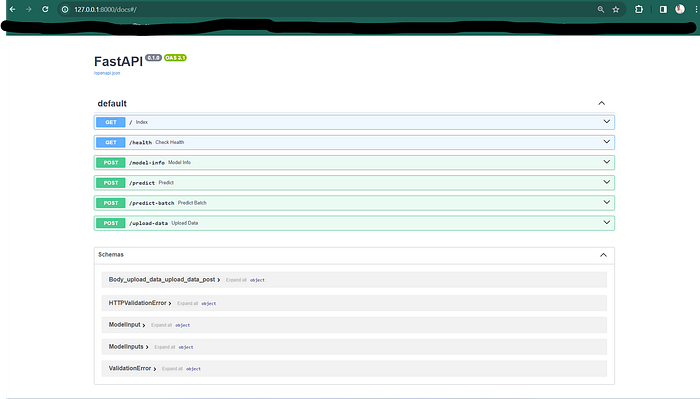
-
Test the health check endpoint by sending a GET request to the health URL or
/health. Verify that the response indicates that the API is running correctly. -
Test the model information endpoint by sending a get request to the model information URL/
model-info -
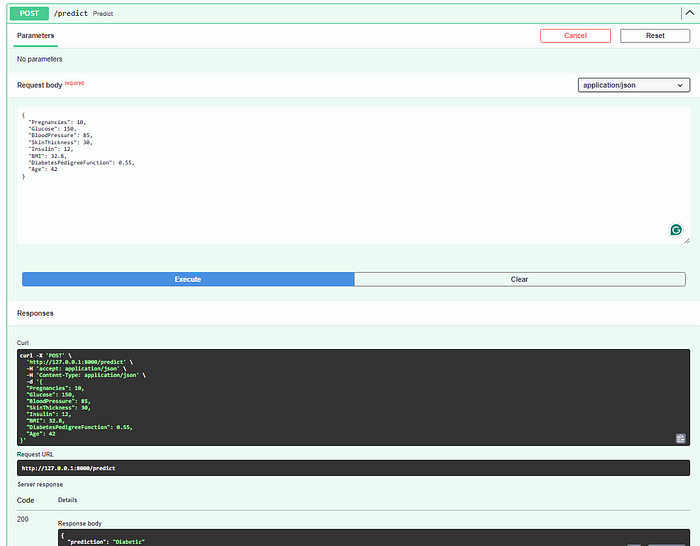
Test the Individual Prediction Endpoint URL/
predictdesigned for single predictions, this endpoint accepts input parameters and returns predictions for individual data records.
Individual Prediction Endpoint:
- Testing the Batch Prediction Endpoint URL/
predict-batchpredictions for multiple data points, this endpoint accepts a list of input records and returns predictions for each input. Testing this endpoint involves sending requests with batches of input data and verifying that the API processes the data correctly and returns accurate predictions for each input record.
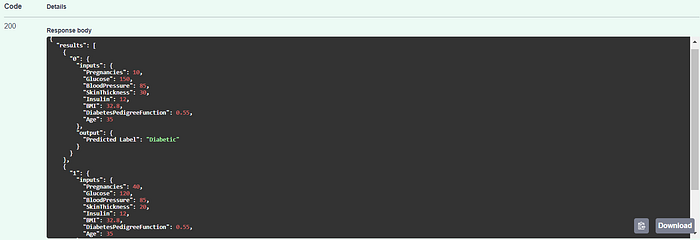
Batch Prediction Endpoint for 2 Samples:
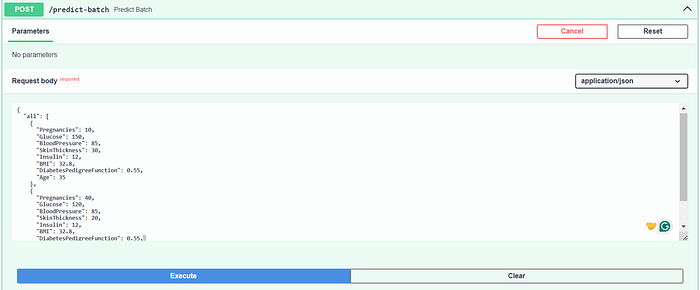
Request Body:
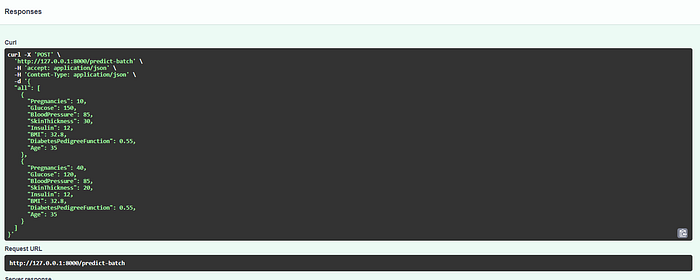
Response Body Sample 1:
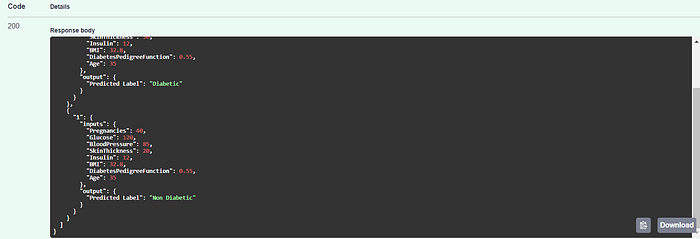
Response Body Sample 2:
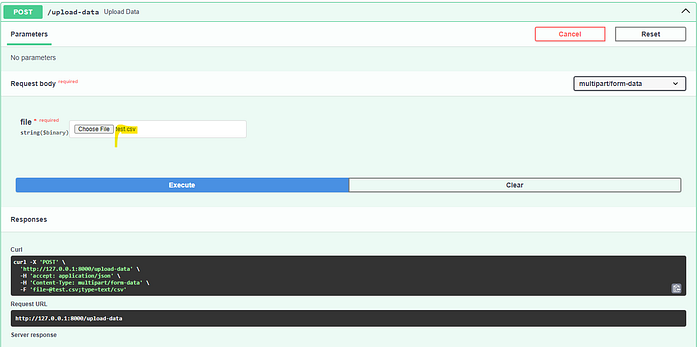
- Testing the Data Upload Endpoint URL/
upload-datafor real-world scenarios, this endpoint allows users to upload data for prediction in JSON or CSV format. I tested using theapi_upload_test.csvfile located on this path./data/api_upload_test.csvin the GitHub Repository.
Testing this endpoint involves uploading sample data files and validating that the API processes the data correctly and returns accurate predictions using the machine learning model.
Data Upload Endpoint:
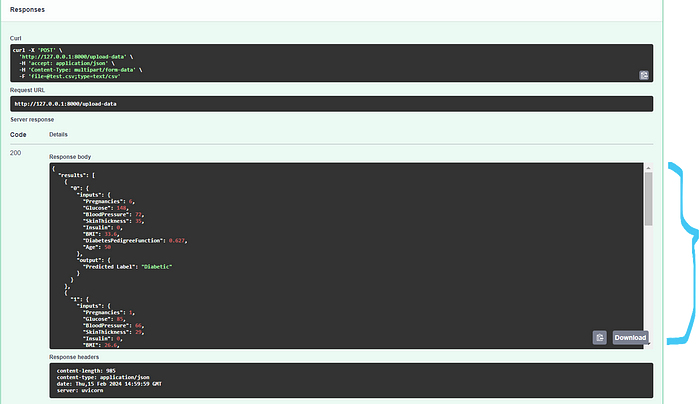
Response Body:
By thoroughly testing each of these API endpoints, you can ensure the overall functionality, reliability, and performance of your API, providing users with a seamless experience when interacting with it.
Now that the API is up and running on your local machine, it’s currently accessible only to you. However, to make it available to the public, it needs to be deployed to the cloud.
To achieve this, we’ll utilize AWS services, which provide robust infrastructure and scalable solutions for hosting applications. Let’s leverage the power of AWS to take your API to the next level and reach a broader audience.
Deployment Architecture
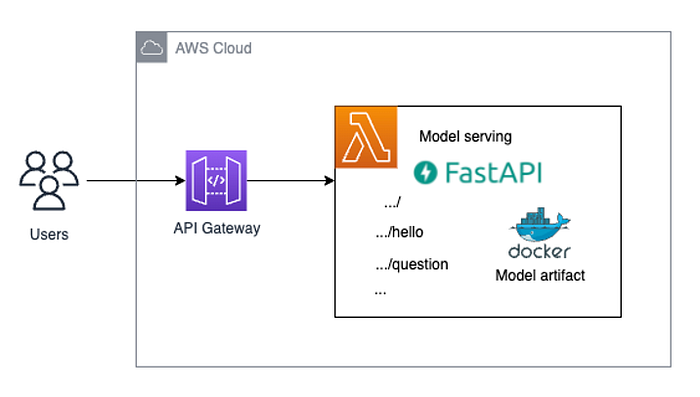
When considering which AWS service to utilize for deployment, several crucial questions should arise:
- Scaling: How can the hosting environment scale up seamlessly as traffic increases?
- Traffic Distribution: How can traffic be efficiently load-balanced across multiple instances?
- Updates Management: What is the process for performing rolling updates for the application?
- Security and Patching: How are operating systems and security patches managed?
- Cost Optimization: How can costs be optimized, considering that you pay for server uptime regardless of API usage?
Given these considerations, serverless computing with AWS Lambda emerges as an optimal solution for hosting APIs. AWS Lambda addresses all these concerns effectively compared to EC2:
- Auto-scaling: It automatically scales up or down in response to incoming traffic, ensuring that your API can handle any level of demand without manual intervention.
- Traffic Distribution: It integrates seamlessly with AWS API Gateway, which provides built-in capabilities for distributing incoming traffic across multiple Lambda instances.
- Rolling Updates: By decoupling code deployment from infrastructure management, AWS Lambda enables effortless rolling updates without disrupting service availability.
- Security and Patching: AWS manages the underlying infrastructure, including security and patching, ensuring that your API remains secure and up-to-date without additional maintenance overhead.
- Cost-effectiveness: With AWS Lambda, you only pay for the compute time consumed by your API requests, making it highly cost-effective compared to traditional server-based hosting models where you pay for server uptime regardless of usage.
But, the problem with running FastAPI on AWS Lambda is that Lambda doesn't understand the FastAPI ASGI interface like@app.get(‘/’), @app.post(‘/’) etc. Instead, lambda understands something known as a lambda handler.
A lambda handler refers to the entry point of your AWS Lambda function. It’s a function in your code that Lambda invokes when the function is triggered. This lambda handler is the entry point for your Lambda function. When you create a Lambda function, you specify the name of the function and the name of the handler function.
def lambda_handler(event, context):
pass
Here, event contains data that's passed into the function when it's invoked, and context provides runtime information.
In our example, when we trigger an AWS Lambda function through an API Gateway HTTP request, the event object that is passed to the Lambda function typically contains information about the HTTP request. This information is formatted as a JSON object and includes details such as the HTTP method, headers, query parameters, path parameters, and the request body.
To unpack the data and route it to the relevant FastAPI path or function, we can leverage the capabilities of the Mangum library.
Magnum
Magnum is a Python library designed to provide support for ASGI (Asynchronous Server Gateway Interface) and serves as a bridge between ASGI applications/frameworks and AWS Lambda, enabling developers to harness the power of serverless computing for their asynchronous web applications.
Magnum allows you to deploy ASGI applications as serverless functions on AWS Lambda. This integration enables you to leverage the scalability and pay-as-you-go pricing model of Lambda for your asynchronous web applications. This allows for efficient event-driven handling of incoming requests, maximizing performance and minimizing resource consumption.
Magnum integrates seamlessly with AWS API Gateway too, allowing you to expose your ASGI applications as HTTP endpoints accessible via API Gateway. This enables you to build RESTful APIs or web applications using ASGI frameworks and deploy them as serverless functions on Lambda.
Implementation
You can install it in your virtual environment using pip install mangumand wrap your entire app with the magnum handler.
# Create an instance of FastAPI
app = FastAPI(lifespan=ml_lifespan_manager, debug=True)
# Mangum wrapper for AWS deployment
handler = Mangum(app)
- Create DockerFile: We have to package all our dependencies into a Docker container, for that we have to create the blueprint using
DockerFile.
FROM public.ecr.aws/amazonlinux/amazonlinux:2023
WORKDIR /app
# Install software
RUN yum update -y && \
yum install -y python39 && \
python3 -m ensurepip --upgrade && \
python3 -m pip install --upgrade setuptools
COPY ./requirements.txt /app/requirements.txt
COPY ./artifacts /app/artifacts
COPY ./app.py /app/app.py
COPY ./utils.py /app/utils.py
RUN python3 -m pip install -r requirements.txt
RUN echo "Image Built"
# Set the CMD to your handler (could also be done as a parameter override outside of the Dockerfile) #"python3", "-u"
CMD ["app.handler"]
2. Create AWS ECR Repository: Log in to the AWS Management Console, navigate to the Amazon ECR service, and create a new repository to store your Docker images.
3. Build and Tag Docker Image: In your terminal, navigate to the root directory of your project and build the Docker image. Tag the image with the URI of your ECR repository.
docker build -t ml_serving_fastapi .
docker tag ml_serving_fastapi:latest <ecr-repo-path>:latest
docker push <ecr-repo-path>:latest
4. Configure Lambda Container Image: Select “Container image” as the runtime type, and choose the ECR repository and image you pushed.
5. Expose your API to the Internet: Below are the are 2 approaches but they differ in their complexity and feature set. Here’s a breakdown:
A. Lambda Function URLs:
- Simple and fast setup: Easily add an HTTPS endpoint directly to your Lambda function with minimal configuration.
- Limited features: No support for request validation, caching, custom domains, throttling, advanced authorization, or integration with other AWS services.
- Best for: Simple microservices, webhooks, testing, and quick prototypes.
- Response time: Up to 15 minutes.
You can simply create it from the Configuration tab:
B. API Gateway:
- Flexible and powerful: Create RESTful APIs, WebSocket APIs, and manage multiple Lambda functions together.
- Rich features: Request validation, caching, custom domains, throttling, integration with other AWS services, and more.
- More complex setup: Requires creating an API and configuring integrations with your Lambda functions.
- Best for: Production-ready APIs, secure access control, managing complex interactions with multiple services.
- Response time: Typically 30 seconds, but can be impacted by additional features.
To create an API Gateway that interacts with your AWS Lambda function, follow my earlier tutorial:
Deploying LLMs: Serverless Magic with Lambda, SageMaker DLC, and API Gateway
Conclusion
In conclusion, deploying a serverless machine learning inference solution using FastAPI and AWS offers a powerful combination of flexibility, scalability, and efficiency. Leveraging the robust capabilities of FastAPI for building high-performance APIs and the seamless scalability of AWS Lambda for executing code in response to incoming requests, developers can create and deploy ML models with ease.
By harnessing the agility of serverless computing, we can efficiently handle varying workloads, reduce operational overhead, and deliver real-time predictions to users at scale. With this approach, deploying ML inference becomes not only accessible but also cost-effective.
Refer to the complete code on Github:
GitHub - akashmathur-2212/Serverless-Deployment-Using-FastAPI-AWS
To refer to other AWS Serverless workflows, refer to this repo:
GitHub - akashmathur-2212/aws-serverless-workflows: aws-serverless-analytics-automation
Thank you for reading this article, I hope it added some pieces to your knowledge stack! Before you go, if you enjoyed reading this article:
👉 Be sure to clap and follow me, and let me know if any feedback.
👉I built versatile Generative AI applications using the Large Language Model (LLM), covered advanced RAG concepts, and serverless AWS architectures for Big Data processing. You’re welcome to take a look at the repo and star⭐it.
- ⭐ Generative AI applications Repository
- ⭐ Advanced RAG applications Repository
- ⭐ Serverless AWS architectures Repository
Comments
Loading comments…