
I have been wondering how to upload multiple files from the client-side of my web application for a couple of days now. And I found a similar question on StackOverflow but the accepted answer was implemented using the AWS CLI. I can certainly implement this using the CLI through child processes using Node.js in the backend. But surely there exist a better and faster approach than this.
Another article was talking about uploading using promise.all but that is certainly not an option on the client-side. I also found some implementation using python and boto3 but my app was written in Node.js so I can't afford to add another language to my dependency list. Then I searched for more on this topic and I found this article written by Akmal Sharipov. Surely, his article was helpful but I faced some issues using this library (might be my fault how I implemented it).
After some digging, I found that the structure of the zip file has its Central Directory located at the last of the file, and there exist local headers that are a copy of the Central Directory but are highly unreliable. And the read methods of most other streaming libraries buffers the entire zip file in the memory thus, defeating the entire purpose of streaming it in the first place. So here's another algorithm I came up with using the yauzl library which he mentioned in his article as well.
-
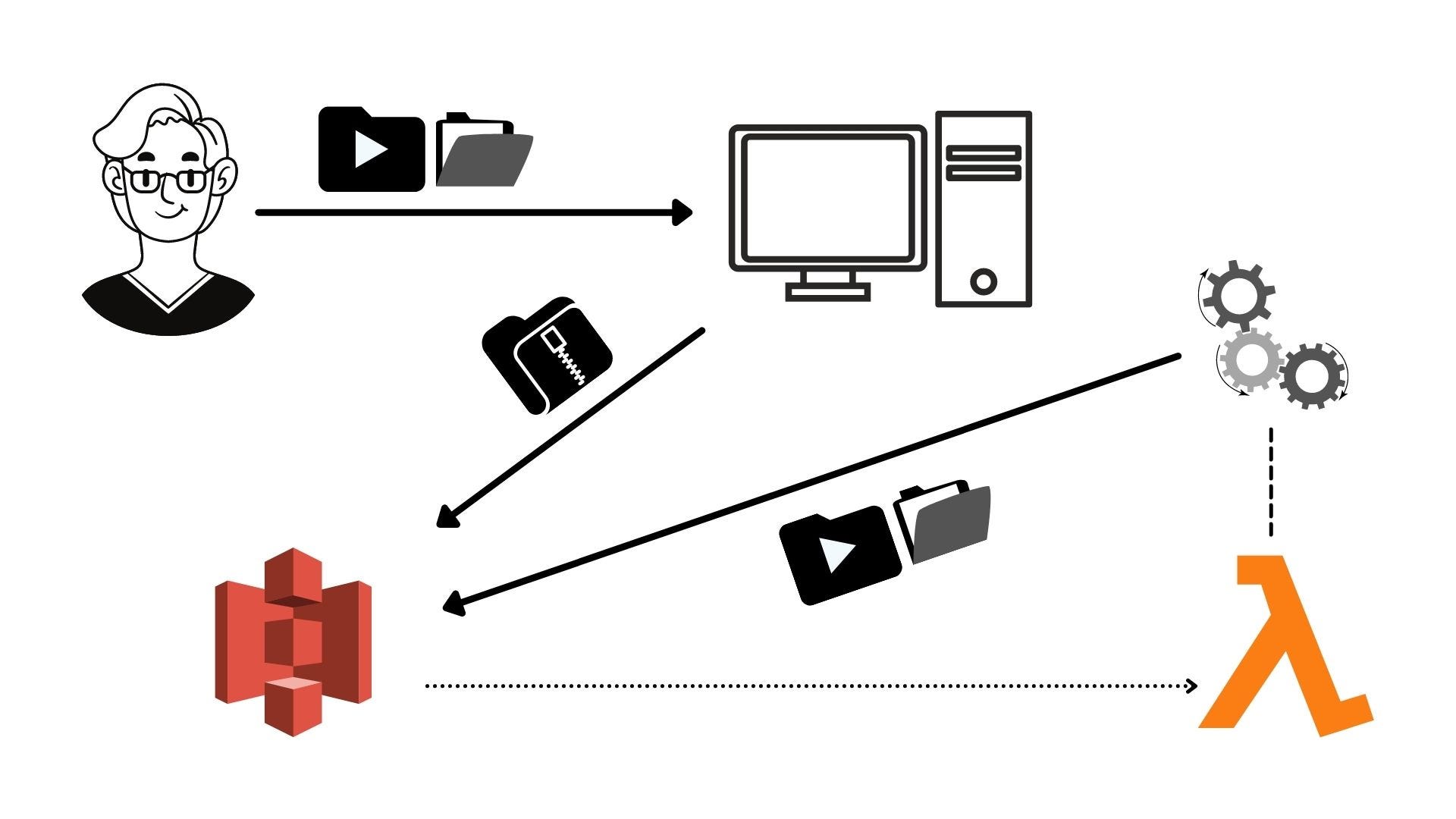
The user uploads lots of files through my app.
-
My app zips those files using the yazl library and uploads it in an S3 bucket on the client-side.
-
An S3 'put' event triggers the lambda function.
-
Lambda function pulls the whole object (zip file)into its memory buffer.
-
It reads one entry and uploads it back to S3.
-
When the upload finishes, it proceeds to the next entry and repeats step 5.
This algorithm never hits the RAM limit of the lambda function. The max memory usage was under 500MB for extracting a 254MB zip file containing 2.24GB of files.
Create a Lambda function and add an S3 trigger
Before creating the lambda function, create an IAM role with full S3 and lambda permissions. Now go to the lambda services section and then click on the 'Create Function' button on the top right corner. On the next page, select 'Author from scratch' and give a name for the function. In the Permissions section, select 'use an existing role' and choose a role that you defined earlier — you can always change the permission later. Then click on the 'Create Function' button on the bottom right corner of the page.
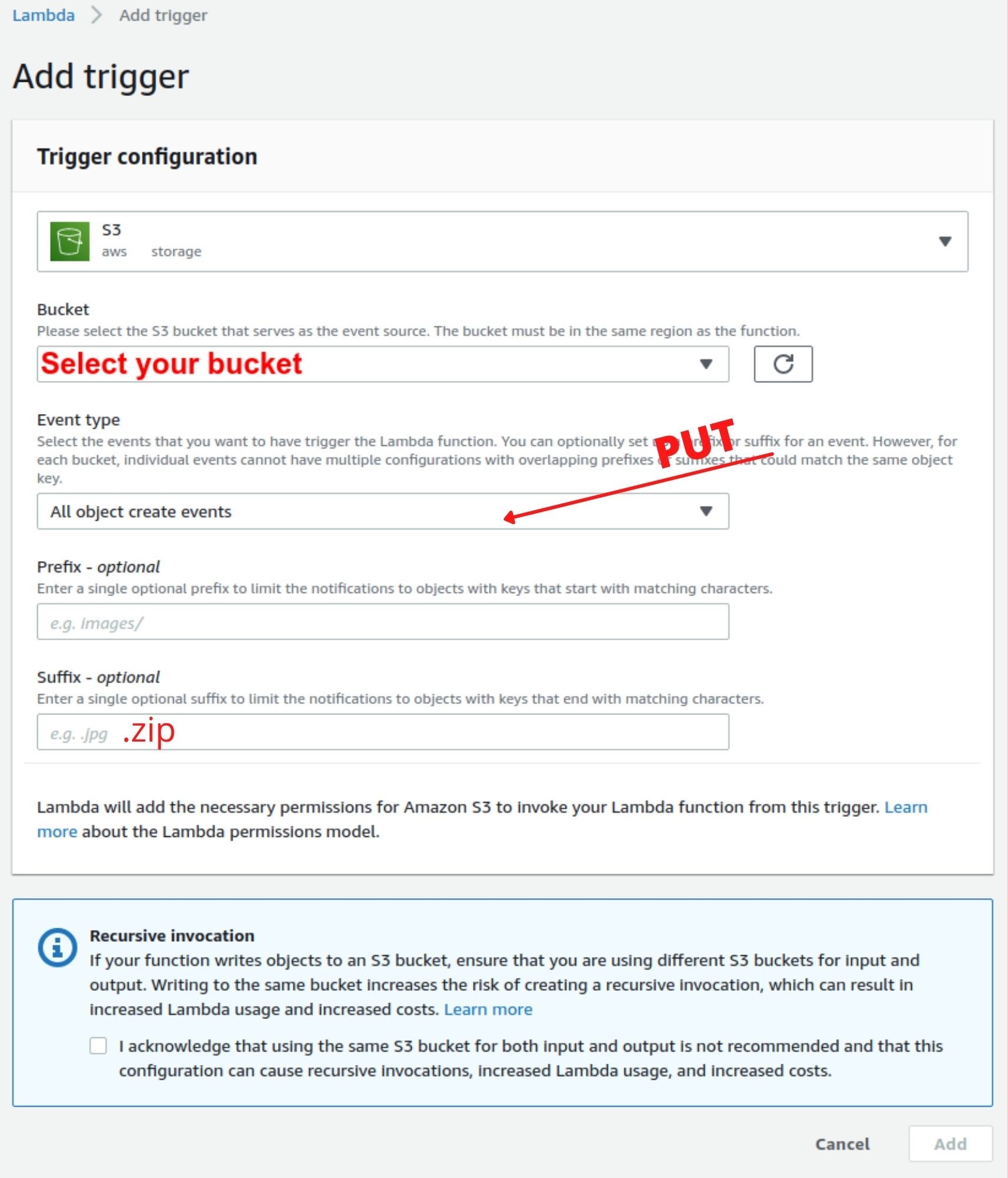
Configure the Lambda function such that it'll be triggered whenever a zip file is uploaded to the S3 bucket. Click on the 'add trigger' button on the Function overview section and select an S3 event from the dropdown. Then choose your bucket and select 'PUT' as the event type and also don't forget to add '.zip' in the suffix field or it'll self invoke the function in a loop. Then click on 'add' to add the trigger on the lambda function.
Lambda function to fetch objects from the S3 bucket
We will use the AWS SDK to get the file from the S3 bucket. Inside the event object of the handler function, we have the Records array that contains the S3 bucket name and the key of the object that triggered this lambda function. We will use the Records array to get the bucket and the key for the S3.getObject(params, [callback]) method to fetch the zip file.
Upload object to S3 bucket from a stream
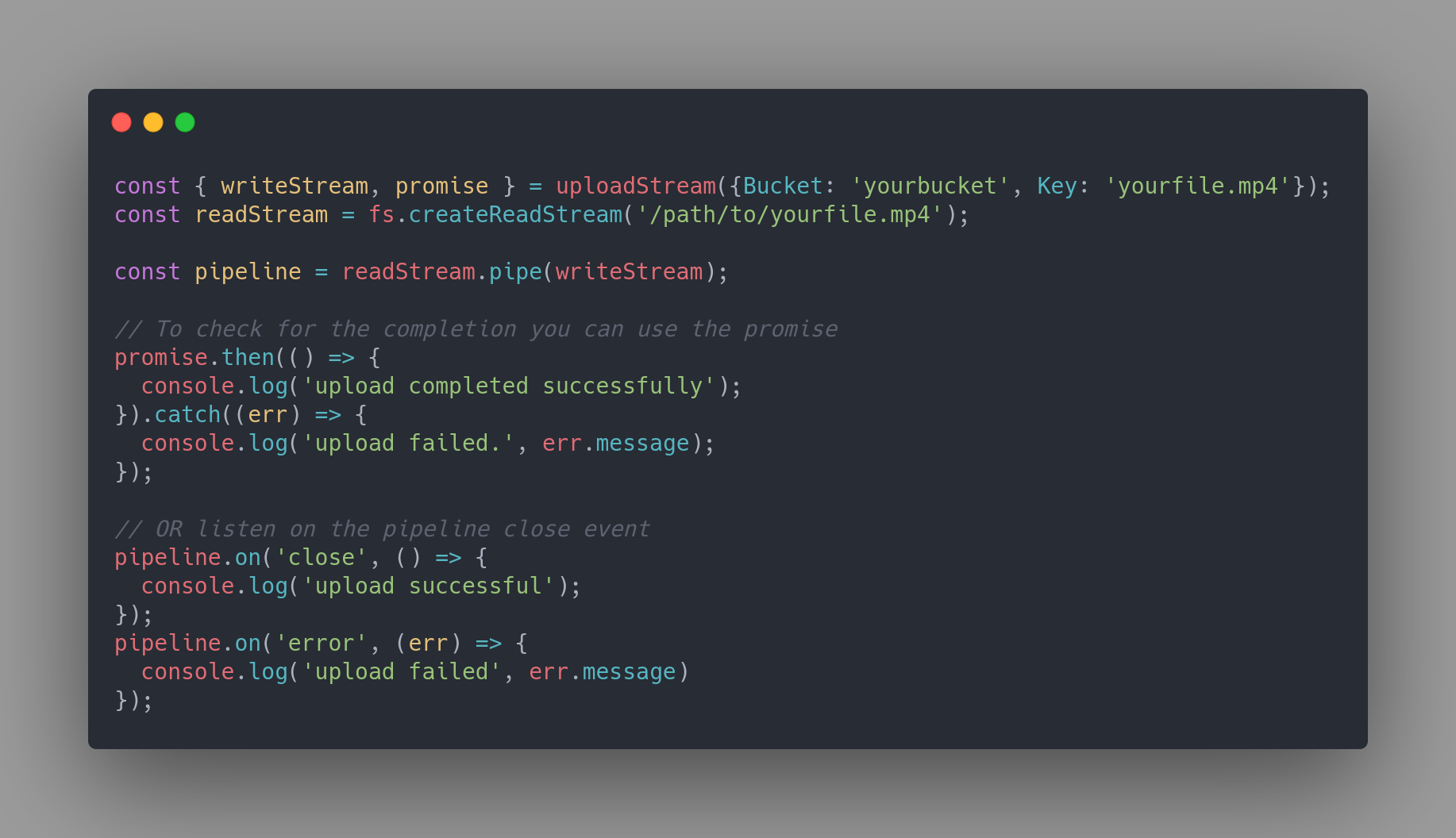
This is the main piece of the code that was a little tricky. Apparently, passing the readable stream directly to the Body property of the params parameter doesn't work at least in the lambda environment. So I searched in GOOGLE — as I do usually — and I found this StackOverflow question which fits my requirement perfectly. Here's the code.
To use this function we need to call the function first and then pipe the readable stream to writeStream property returned by it.
uploadStream function?Unzip the object and upload each entry back to S3
Yauzl library is the most popular library in the npm registry. This library is also very reliable and I don't want my app to crash for some silly library issue. The documentation is very user-friendly as well. I'll use the fromBuffer method as the zip file will be available to us via the buffer only. Let's dive into the code for unzipping the file.
This function will read one entry from the zip file and then upload it back to the S3 bucket using the uploadStream function we implemented earlier. After the upload of one entry/file has finished, then only it will read the next entry and upload it and the loop goes on until the end of the zip file is encountered. It resolves the promise with the 'end' message when there's nothing left in the zip file.
Putting it all together
Repository: GitHub - ankanbag101/lambda-zip-extractor
The entire code is available in the above repository. You just need to clone the repository and then run npm install followed by npm run zip. Then upload the lambda.zip file in the lambda's code section of the console.
Don't worry if you don't want to clone my repository, you can paste all the functions I shared inside the index.js file and replace console.log(object) at line 15 of the 'exports.handler' with this line const result = await extractZip(Bucket, object.Body);
Last Words
I just implemented the algorithm a little differently than the other implementation I discussed earlier. My approach was to not stream the zip file but to stream the entries one at a time. But all the other algorithms are great as well.
Happy hacking!
Comments
Loading comments…