Langchain is gradually emerging as the preferred framework for creating applications driven by large language models (LLMs). Experimenting with it quickly reveals its ability to empower non-NLP specialists in developing applications that were previously difficult and required extensive expertise.
Nonetheless, relying solely on LLMs is often insufficient for producing highly effective applications. The true potential of LLMs can be unlocked by integrating them with other sources of computation or knowledge. This is where LangChain comes in to address these challenge
It helps developers with the following:
- It provides developers with capabilities for prompt management and optimization.
- The framework enables developers to chain different LLMS and components together, such as an LLMChain that consists of a PromptTemplate, a model (which can be either an LLM or a ChatModel), and an optional output parser.
- Agents are included in the framework to assist in obtaining up-to-date data from the outside world, such as Google search, to enrich models with additional information!
- Memory integration allows developers to easily integrate memory into a user's previous interactions with the large language model.
- LangChain offers specially-designed prompts/chains for the evaluation of generative models, which can be difficult to evaluate using conventional metrics.
- Indexes are included to enable users to structure documents in a way that allows LLMs to interact with them effectively. This capability makes it possible to apply LLMs to custom data for tasks such as information retrieval, summarization, or building a custom chatbot to answer consumer questions.
This article aims to demonstrate the effectiveness of indexing in the Langchain framework, using a practical example.
Suppose we have a collection of CVs in PDF format, and we want to use an LLM to extract information about the candidates or evaluate their suitability for a particular role.
To start let's install the following libraries in a google collab for example:
!pip install chromadb
!pip install langchain
!pip install pypdf
!pip install llama-index
You need to add your OpenAI API key when using indexing in the Langchain framework because Langchain utilizes OpenAI's GPT-3 API for language processing. The API key is required to authenticate your access to the API and enable Langchain to interact with GPT-3.
Warning: When using the OpenAI API on your custome data, please be aware that OpenAI will have access to that data. As a result, sensitive information may be exposed to OpenAI, including but not limited to trade secrets, proprietary information, and personal data. It is important to carefully consider the potential risks and benefits of using the OpenAI API on your company data, and to take appropriate measures to protect your sensitive information.
import os
# add your openai api key
os.environ["OPENAI_API_KEY"] ="your openApi key"
You can find it by simply typing "Openai API key" in Google and downloading your personal key.
Screenshot by the author
To begin the indexing process, we must first select the type of document we have. Langchain provides loaders for various document types including CSV, Directory, PDF, Google BigQuery, and more. from langchain.document_loaders import PyPDFLoader from langchain.indexes import VectorstoreIndexCreator
add the path to the CV as a PDF
loader = PyPDFLoader('my_personal_cv.pdf')
intialize the Vector index creator
index = VectorstoreIndexCreator().from_loaders([loader])
Once the indexing process is ready, we can simply engage in a natural language conversation with the LLM to extract information from the indexed documents. This conversational approach eliminates the need for complex queries or programming, making it accessible to almost anyone.
Examples
To retrieve some information from the document we need to write our question in form of a query. The index object we just created has the function query which gives it the impression that we are querying a database.
query = "what is the name of the candidate you have ?"
index.query(query)

This is already impressive but let's see how it performs with slightly more complicated questions:
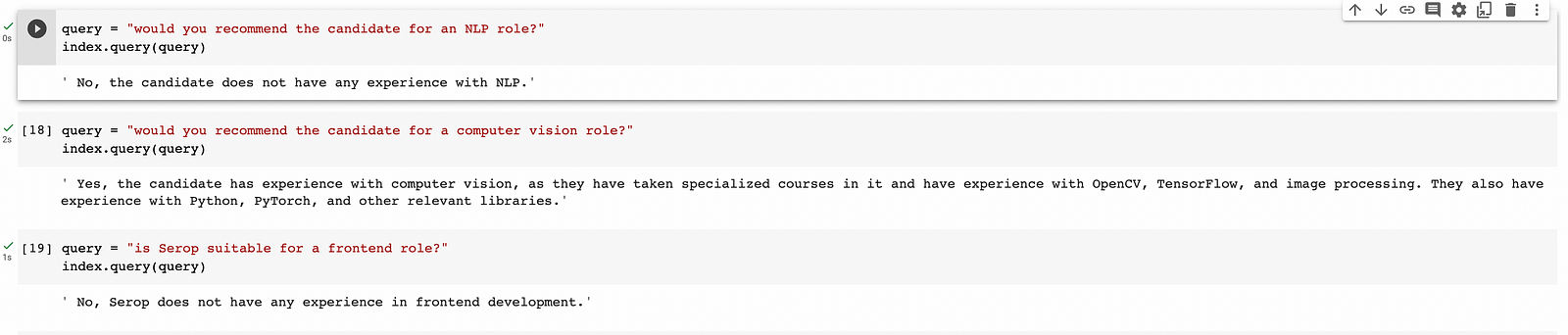
Langchain's indexing API is remarkable in its ability to comprehend our queries and accurately discern the necessary qualifications for specific positions, including Frontend, NLP, and computer vision roles. Its recommendation of the computer vision role, complete with a justification, is particularly impressive and highlights possible use cases for recruiters.

While the LLM can provide clarifications for our questions, it currently does not have the ability to offer further advice on which skills to prioritize in the future. However, we could enhance this framework's effectiveness by incorporating another LLM that specializes in skill recommendations on top of this indexing.
Adding multiple documents
By adding multiple documents to the loader, we can establish a database of unstructured text, which can provide us with a summary of information about our candidates. As an example, I included my personal CV and my colleague's, who is a Senior Machine Learning Engineer with a focus on NLP applications.
Adding both CVs is a straightforward process accomplished by creating a list of the loaders:
from langchain.document_loaders import PyPDFLoader
from langchain.indexes import VectorstoreIndexCreator
loaders = [PyPDFLoader('my_personal_cv.pdf'), PyPDFLoader('my_colleagues_cv.pdf')]
index = VectorstoreIndexCreator().from_loaders(loaders)
We now have the ability to ask questions about both candidates, such as making comparisons or receiving the better fit for specific roles.

Conclusion
Langchain's indexing API offers an effective solution for structuring and organizing unstructured data. By using this technology on custom data, we can gain valuable insights that were previously difficult to extract due to the lack of organization and structure of the data.
One of the key benefits of using Langchain's indexing API is the ability to add multiple documents to the loader and create a database of unstructured text. This database can provide a comprehensive and holistic view of a candidate's qualifications, experience, and skills, which is particularly useful when evaluating large numbers of candidates. Furthermore, the customized output generated by the API can be linked as a chain, creating a powerful framework for data analysis.
In summary, Langchain's indexing API is a powerful tool that can provide valuable insights and efficiencies when applied to custom data. Its ability to structure and organize unstructured data, provide recommendations and explanations, and create a powerful framework for data analysis makes it a valuable tool for various applications.
Comments
Loading comments…