LLaMA-Adapter (source: marktechpost.com)
Introduction
The field of natural language processing has witnessed incredible advancements with large language models (LLMs) like ChatGPT. However, these models have their limitations. They may pose privacy concerns, adhere to a fixed set of rules, and be limited to the date of their last training. Another limitation for pre-trained LLMs like PaLM and GPT-3.5 are not open-source. This means that developers and researchers do not have access to the internal workings of the model, limiting their ability to fine-tune and customize it to specific use cases.
Fortunately, a new era has arrived with LLama 2.0, an open-source LLM introduced by Meta, which allows fine-tuning on your own dataset, mitigating privacy concerns and enabling personalized AI experiences. Moreover, the innovative QLora approach provides an efficient way to fine-tune LLMs with a single GPU, making it more accessible and cost-effective for customizing models to suit individual needs.
Introducing LLama 2.0: A New Horizon of Possibilities
Meta’s latest innovation, LLama 2.0, unveils a collection of pre-trained and fine-tuned models, ranging from 7 billion to a staggering 70 billion parameters. This impressive lineup includes:
- LLama 2: A revamped version of its predecessor, LLama 1, equipped with updated training data sourced from various publicly available resources. It offers three variants: 7B, 13B, and 70B parameters.
- LLama 2-Chat: An optimized version of LLama 2, finely tuned for dialogue-based use cases. Like LLama 2, it offers three variants: 7B, 13B, and 70B parameters.
Llama 2.0 introduces significant advancements,
- Expanding the context window from 2048 to 4096 tokens enables the model to process a larger amount of information.
- To address the quadratic cost of attention scaling with token numbers, the authors incorporate Grouped-Query Attention, sharing key and value projections across multiple heads.
- Leverage a greater volume of data for training, incorporating a combination of scraped online data and fine-tuned data based on feedback from human annotators. The model’s astute choice to use public data ensures compatibility with open-source platforms while mitigating potential legal issues arising from data usage.

(source: ai.meta.com)
The outcomes demonstrate the superiority of Llama 2.0 over open-source models in various benchmarks. Although it falls short of competing with closed-source models like GPT-4 and PaLM, this is expected given their significantly larger parameter sizes and training with private data. The entire family of LLama 2 models is an open-source treasure trove, free for both research and commercial use.
Parameter-Efficient Fine Tuning (PEFT): QLoRA
The potential of fine-tuning language models on your own dataset is unparalleled. However, the process often demands substantial GPU memory and can be a resource-intensive endeavor. For instance, fine-tuning a model with 65 billion parameters necessitates a staggering 780 GB of GPU memory, equivalent to ten A100 80 GB GPUs. Such resource demands have hindered the seamless fine-tuning of consumer hardware.
This is where LoRA: Low-Rank Adaptation of Large Language Models, introduced by EJ Hu in 2021, steps in to revolutionize the landscape. LoRA’s architecture involves freezing the pre-trained model weights and training the additional weight changes in a matrix without sacrificing crucial information. This process occurs in each layer of the Transformer architecture.
Consider a weight update matrix ΔW for an A × B weight matrix. We can decompose ΔW into two smaller matrices, WA and WB, such that ΔW = WA * WB. Here, WA is an A × r-dimensional matrix, and WB is an r × B-dimensional matrix. The key idea is to keep the original weight W frozen and solely train the new matrices WA and WB. This concise approach characterizes the essence of the LoRA method, as depicted in the accompanying figure.
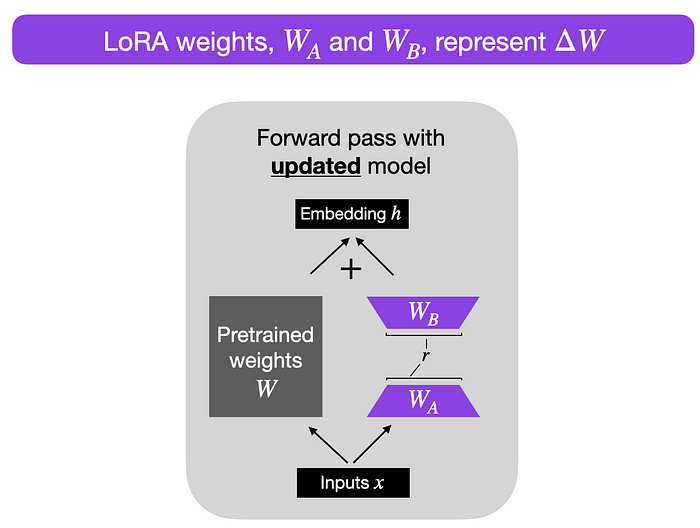
The structure of Lora in each Transformer Layers (credit: lightning.ai)
QLoRA (Efficient Finetuning of Quantized LLMs), introduced by Dettmers et al. in 2023, takes LoRA a step further by introducing
- 4-bit NormalFloat Quantization: QLoRA introduces a novel quantization method that improves upon traditional quantile quantization. The 4-bit NormalFloat quantization ensures an equal number of values in each quantization bin, mitigating computational issues and errors for outlier values.
- Double Quantization: QLoRA takes a step further by quantizing the quantization constants, resulting in additional memory savings. This ingenious approach compresses model information while maintaining overall performance.
- Paging with Unified Memory: Leveraging the NVIDIA Unified Memory feature, QLoRA orchestrates seamless page-to-page transfers between the CPU and GPU. This intelligent memory management ensures error-free GPU processing, even in scenarios where the GPU faces memory constraints.
Implementation
Get Started
Alright, enough of the theory! Let’s dive straight into the technical part and start coding from the ground up. First things first, we need to install and import the required libraries to get our hands dirty with the implementation. Let’s get started!
pip install transformers datasets peft accelerate bitsandbytes safetensors
import os, sys
import torch
import datasets
from transformers import (
AutoTokenizer,
AutoModelForCausalLM,
BitsAndBytesConfig,
DataCollatorForLanguageModeling,
DataCollatorForSeq2Seq,
Trainer,
TrainingArguments,
GenerationConfig
)
from peft import PeftModel, LoraConfig, prepare_model_for_kbit_training, get_peft_model
Model Loading
### config ###
model_id = "NousResearch/Llama-2-7b-hf"
max_length = 512
device_map = "auto"
batch_size = 128
micro_batch_size = 32
gradient_accumulation_steps = batch_size // micro_batch_size
# nf4" use a symmetric quantization scheme with 4 bits precision
bnb_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_use_double_quant=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_compute_dtype=torch.bfloat16
)
# load model from huggingface
model = AutoModelForCausalLM.from_pretrained(
model_id,
quantization_config=bnb_config,
use_cache=False,
device_map=device_map
)
# load tokenizer from huggingface
tokenizer = AutoTokenizer.from_pretrained(model_id)
tokenizer.pad_token = tokenizer.eos_token
tokenizer.padding_side = "right"
Let’s now take a step forward to download the impressive Llama 2.0 model and tokenizer “NousResearch/Llama-2–7b-hf” from Hugging Face. The code also specifies the BitsAndBytesConfig object which is used for double quantization and 4bit model format to optimize the model’s performance.
def print_number_of_trainable_model_parameters(model):
trainable_model_params = 0
all_model_params = 0
for _, param in model.named_parameters():
all_model_params += param.numel()
if param.requires_grad:
trainable_model_params += param.numel()
print(f"trainable model parameters: {trainable_model_params}. All model parameters: {all_model_params} ")
return trainable_model_params
ori_p = print_number_of_trainable_model_parameters(model)
Meanwhile, we have created a convenient helper function called “print_number_of_trainable_model_parameters” to inspect the trainable parameters of the original model. Upon running this function, it provides us the output trainable model parameter: 262,410,240
# LoRA config
model = prepare_model_for_kbit_training(model)
peft_config = LoraConfig(
r=8,
lora_alpha=32,
lora_dropout=0.1,
target_modules=["q_proj", "v_proj"],
bias="none",
task_type="CAUSAL_LM",
)
model = get_peft_model(model, peft_config)
### compare trainable parameters #
peft_p = print_number_of_trainable_model_parameters(model)
print(f"# Trainable Parameter \nBefore: {ori_p} \nAfter: {peft_p} \nPercentage: {round(peft_p / ori_p * 100, 2)}")
Next, we can start packing the model into the LoRA format while keeping the original parameters frozen and introducing additional weights as discussed earlier. The LoRA model has several configurable parameters:
rdetermines the rank of the update matrices, also known as Lora attention dimension. Lower rank results in smaller update matrices with fewer trainable parameters. Increasing r (not more than 32) will lead to more robust model but higher memory consumption at the same time.lora_alpha**** controls the LoRA scaling factortarget_modulesis a list of module names, such as “q_proj” and “v_proj,” which serves as the targets for the LoRA model. The specific module names may vary depending on the underlying model.bias: Specifies if thebiasparameters should be trained. Can be''none'',''all''or''lora_only''.
After attaching model with the LoRA adapter, let’s print the trainable parameters again and compare them to the original model. Remarkably, the trainable model parameter: 4,194,304is now represent only less than 2% of the original model’s size.
### generate ###
prompt = "Write me a poem about Singapore."
inputs = tokenizer(prompt, return_tensors="pt")
generate_ids = model.generate(inputs.input_ids, max_length=64)
print(''\nAnswer: '', tokenizer.decode(generate_ids[0]))
res = tokenizer.batch_decode(generate_ids, skip_special_tokens=True, clean_up_tokenization_spaces=False)[0]
print(res)
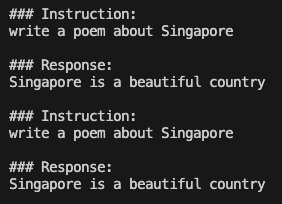
Just before the thrilling fine-tuning process, let’ not skip the process of generating an output from a pre-trained language model and observe its response. In this case, when asking the model to write a poem about Singapore, the generated output appears to be quite vague and repetitive, indicating that the model struggles to provide a coherent and meaningful response.
The pre-trained model gives repeat answer from the instruction:
Data Loading
To demonstate the process of fine-tuning an Instruction-LLM, we are going to use a public dataset sourced from databricks/databricks-dolly-15k`` which presents an array of instruction-response pairs. Notably, certain samples in this dataset also incorporate contextual information, adding an extra layer of complexity and richness to the model’s comprehension process. Allow me to present a captivating sample record extracted from this intriguing raw data:
{
''instruction'': ''Why can camels survive for long without water?'',
''context'': '',
''response'': ''Camels use the fat in their humps to keep them filled with energy and hydration for long periods of time.'',
''category'': ''open_qa'',
}
A prompt_template is created to enhance the learning capabilities of the model. This ingenious template consists of two distinct types: prompt_input and prompt_no_input. The former is employed for samples that encompass an input context, while the latter caters to instances lacking such contextual information. By precisely pairing each task’s instruction with the appropriate context (if available), we foster a deeper understanding and context-awareness within the model.
max_length = 256
dataset = datasets.load_dataset(
"databricks/databricks-dolly-15k", split=''train''
)
### generate prompt based on template ###
prompt_template = {
"prompt_input": \
"Below is an instruction that describes a task, paired with an input that provides further context.\
Write a response that appropriately completes the request.\
\n\n### Instruction:\n{instruction}\n\n### Input:\n{input}\n\n### Response:\n",
"prompt_no_input": \
"Below is an instruction that describes a task.\
Write a response that appropriately completes the request.\
\n\n### Instruction:\n{instruction}\n\n### Response:\n",
"response_split": "### Response:"
}
def generate_prompt(instruction, input=None, label=None, prompt_template=prompt_template):
if input:
res = prompt_template["prompt_input"].format(
instruction=instruction, input=input)
else:
res = prompt_template["prompt_no_input"].format(
instruction=instruction)
if label:
res = f"{res}{label}"
return res
We first generate the full prompt by combining the instruction, context, and response using the generate_prompt function. Once the full prompt is crafted, we tokenize it using the provided tokenizer, which transforms the text into input_ids and attention_mask. Notably, to train the model to predict the next word, we designate the labelsimilar to the input_idsand facilitate a shift-right operation by the trainer. However, to avoid the model focusing on the next word in the instruction and context, we shall mask all the original tokens in these segments, replacing them with -100, while retaining only the response input. The data is further organized into training and validation sets, and unnecessary columns are removed, thus culminating in a refined and highly effective dataset poised for training.
def tokenize(tokenizer, prompt, max_length=max_length, add_eos_token=False):
result = tokenizer(
prompt,
truncation=True,
max_length=max_length,
padding=False,
return_tensors=None)
result["labels"] = result["input_ids"].copy()
return result
def generate_and_tokenize_prompt(data_point):
full_prompt = generate_prompt(
data_point["instruction"],
data_point["context"],
data_point["response"],
)
tokenized_full_prompt = tokenize(tokenizer, full_prompt)
user_prompt = generate_prompt(data_point["instruction"], data_point["context"])
tokenized_user_prompt = tokenize(tokenizer, user_prompt)
user_prompt_len = len(tokenized_user_prompt["input_ids"])
mask_token = [-100] * user_prompt_len
tokenized_full_prompt["labels"] = mask_token + tokenized_full_prompt["labels"][user_prompt_len:]
return tokenized_full_prompt
dataset = dataset.train_test_split(test_size=1000, shuffle=True, seed=42)
cols = ["instruction", "context", "response", "category"]
train_data = dataset["train"].shuffle().map(generate_and_tokenize_prompt, remove_columns=cols)
val_data = dataset["test"].shuffle().map(generate_and_tokenize_prompt, remove_columns=cols,)
Model Training
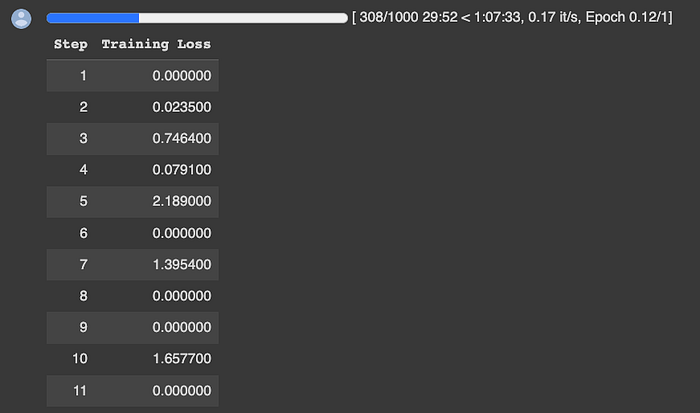
With extensive preparation of the data and model, the moment has come to initiate the training process. With the flexibility to fine-tune the trainer’s settings as needed, I run 200 steps on a crucial five-hour training session, with Google Colab.
args = TrainingArguments(
output_dir="./llama-7b-int4-dolly",
num_train_epochs=20,
max_steps=200,
fp16=True,
optim="paged_adamw_32bit",
learning_rate=2e-4,
lr_scheduler_type="constant",
per_device_train_batch_size=micro_batch_size,
gradient_accumulation_steps=gradient_accumulation_steps,
gradient_checkpointing=True,
group_by_length=False,
logging_steps=10,
save_strategy="epoch",
save_total_limit=3,
disable_tqdm=False,
)
trainer = Trainer(
model=model,
train_dataset=train_data,
eval_dataset=val_data,
args=args,
data_collator=DataCollatorForSeq2Seq(
tokenizer, pad_to_multiple_of=8, return_tensors="pt", padding=True),
)
# silence the warnings. re-enable for inference!
model.config.use_cache = False
trainer.train()
model.save_pretrained("llama-7b-int4-dolly")
Training Progress in Google Colab:
Generation
After several hours of training with a single GPU, it’s time to test the model’s performance using the input prompt “Write me a poem about Singapore” which we previously used. The code snippet starts by loading the pre-trained Llama-2–7b-hf model and Peft weights. The model’s generation configuration is set to control factors such as
temperaturecontrols the randomness of the generation process. When the temperature is high, the generator is more random and generates diverse but less coherent outputs. When the temperature is low, the generator is less random and generates more coherent but less diverse outputs.top-pselect the most promising candidates from a set of generated options. The “p” in top-p stands for “probability,” and it refers to the probability of a given candidate being the best option.top-kis similar to top-p, but instead of selecting a percentage of candidates, it selects a fixed number of candidates with the highest probability scores.num_beamin Beam search algorithm that allows the model to consider multiple possible outputs simultaneously. It works by maintaining a set of possible outputs, called the “beam,” and iteratively expanding the beam by adding new outputs that are likely to be correct.
# model path and weight
model_id = "NousResearch/Llama-2-7b-hf"
peft_path = "./llama-7b-int4-dolly"
# loading model
model = AutoModelForCausalLM.from_pretrained(
model_id,
quantization_config=bnb_config,
use_cache=False,
device_map="auto"
)
# loading peft weight
model = PeftModel.from_pretrained(
model,
peft_path,
torch_dtype=torch.float16,
)
model.eval()
# generation config
generation_config = GenerationConfig(
temperature=0.1,
top_p=0.75,
top_k=40,
num_beams=4, # beam search
)
# generating reply
with torch.no_grad():
prompt = "Write me a poem about Singapore."
inputs = tokenizer(prompt, return_tensors="pt")
generation_output = model.generate(
input_ids=inputs.input_ids,
generation_config=generation_config,
return_dict_in_generate=True,
output_scores=True,
max_new_tokens=64,
)
print(''\nAnswer: '', tokenizer.decode(generation_output.sequences[0]))
The model’s output is now showing promising improvements compared to the pre-trained model. Although the result might not meet our high poetic expectations, it’s essential to consider that we employed the smallest available 7b-Llama2.0 model and trained only on a limited weight using Lora for a short period. Nevertheless, this outcome is already impressive, considering the constraints.
Model Output after fine-tuning:

In addition to fine-tuning the pre-trained vanilla model Llama 2.0, there is another enticing option: utilizing the “meta-llama/Llama-2–7b-chat-hf”, a dialogue-optimized model capable of comprehending and following instructions. Starting with this chat model as a foundation is a strategic approach to customizing the model with your own private data.
For a full running code, kindly check out my repo!
Conclusion
Combining the prowess of LLama 2.0 with the efficiency of Qlora opens the doors to unparalleled AI personalization. The ability to fine-tune models on your own dataset, powered by state-of-the-art open-source models, brings AI applications to new heights of relevance and customization. Qlora’s resource-efficient approach democratizes fine-tuning, enabling seamless training even on single GPUs.
As the AI landscape evolves, the responsible development of AI remains imperative. Ethical considerations, fairness, and inclusivity should serve as guiding principles in our journey towards innovative AI applications. Armed with LLama 2.0 and Qlora, we are equipped to shape AI into a personalized, human-centric experience that benefits all. The future of AI is indeed exciting, and the possibilities are limitless! Happy fine-tuning! 🚀
Comments
Loading comments…