Computer vision is a field within artificial intelligence that focuses on training computers to interpret and comprehend digital images and videos visually. In simpler terms, the central goal is to empower machines with the ability to "see" by processing visual inputs, extracting useful information from them, making decisions based on the inputs, and taking relevant actions.
This field includes various core tasks and techniques for enabling computers to analyze images and videos digitally to garner high-level understanding. Let's explore some fundamental concepts.
Image Classification

Image classification refers to categorizing an entire image into a specific class or label. For instance, identifying an image as containing a "dog" or a "cat". This forms one of the most common computer vision applications with numerous real-world usage scenarios.
Popular techniques used for image classification involve convolutional neural networks (CNNs). These can automatically learn to identify visual features from substantial labeled image data. Developers who provide computer vision development services also employ classical techniques like SIFT and HOG to extract prominent image features.
Object Detection
Object detection goes past basic image classification. It necessitates identifying objects in an image and also locating them by drawing bounding boxes around them. Thus, the system doesn't just classify an image; it also isolates the object's location within the scene. This allows the computer vision model to identify and locate multiple objects in an image, such as detecting faces, traffic signs, tumors in medical scans etc.
Object detection builds on classification by adding a regional proposal and regression component to predict bounding boxes and classify those regions. Popular approaches utilize region-based CNNs like R-CNN and SSD.
Image Segmentation
Image segmentation aims to partition an image into multiple coherent regions or segments. The goal is to simplify the image into something more meaningful and easier to analyze by segmenting it into parts. For example, segmenting all the roads, buildings, trees etc, in an aerial image.
Common techniques for image segmentation include thresholding, edge detection, clustering methods, graph partitioning and deep learning approaches like U-Net. The output is typically a labeled mask identifying pixels belonging to each segment.
Image Recognition
Image recognition (or image retrieval) searches through databases for matches based on image content. Real-world usage includes face recognition for unlocking devices or identifying persons of interest, as well as recognizing logos, landmarks etc.
Traditional image recognition approaches used hand-crafted visual features like SIFT and Bag of Words. But deep learning methods like Siamese networks now dominate, learning embeddings that encode visual similarity between images.
Pose Estimation
Pose estimation refers to detecting key body joint positions in images or videos to determine the posture or movement of people (and even animals). This has applications in fitness tracking, animation, health monitoring etc.
Pose estimation employs machine learning approaches to build statistical body models that can infer the spatial relationships between joints from visual cues. Deep learning methods now focus on heatmaps and 2D/3D spatial offsets to identify joint locations.
Text Detection & Recognition
The ability to detect and recognize text in images is crucial for understanding visual scenes. Use cases include translating text in images/videos, assisting the visually impaired, and automating data entry.
Text detection locates regions containing text, while recognition extracts the actual sequence of characters. Classical techniques rely on sliding windows and hand-crafted features for character patterns. More recently, deep learning methods like EAST and CRNN have demonstrated superior performance.
Image Captioning
Image captioning requires higher-level computer vision and natural language processing to automatically produce textual descriptions of images' content.
Typical approaches utilize CNN encoders to generate image features, combined with RNN or transformer decoder models to turn features into coherent sentences in a human-readable caption.
Visual SLAM
Simultaneous localization and mapping (SLAM) enables autonomous agents like robots and self-driving cars to navigate environments by constructing a spatial map and updating their location within it. Performing SLAM with visual data from cameras is termed visual SLAM.
Algorithms like ORB-SLAM leverage keyframes, sparse feature mapping, bundle adjustment optimization and more to achieve accurate, long-term tracking and mapping with six degrees of freedom movement.
Applications of Computer Vision
Computer vision has vast applications across many industries, from healthcare to manufacturing to security. As the capabilities of computer vision systems continue improving year over year, more and more companies are integrating these technologies to solve real-world problems.
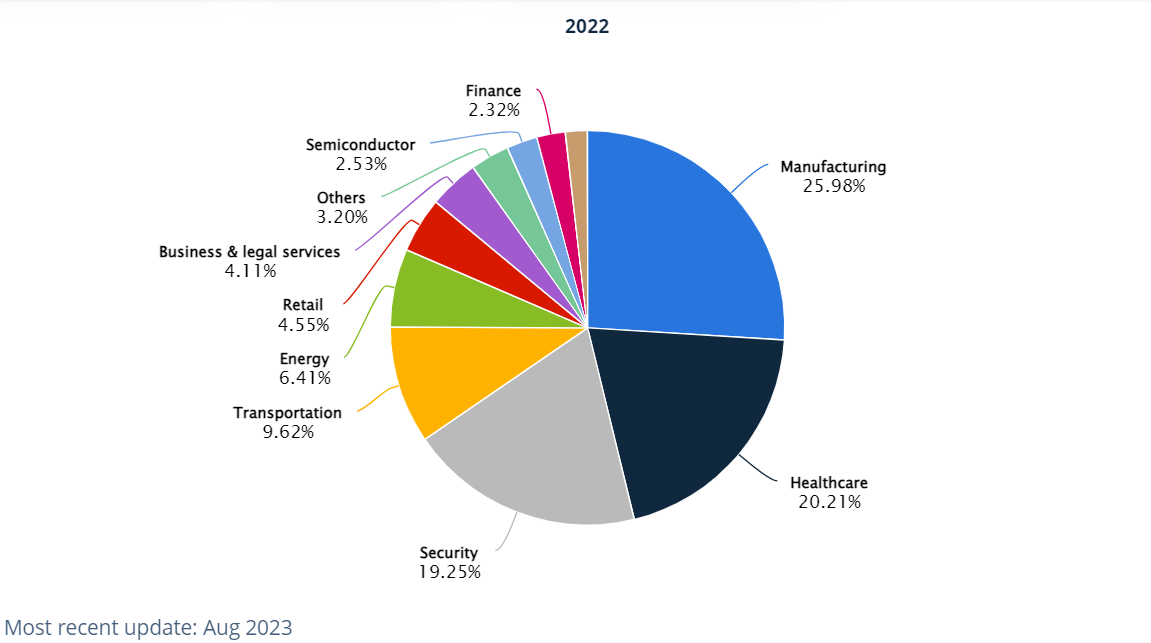
Here is a partial list of impactful applications of computer vision in 2024:
Healthcare & Medical Imaging
- Detecting cancerous tumors and anomalies in medical scans
- Analysis of medical images to automate disease screening
- Performing lab studies like blood sample analysis and microscopy
- Aiding in robotic surgeries with enhanced visualization and navigation
- Tracking patient rehabilitation progress with pose estimation systems
Autonomous Vehicles & Drones
- Allowing self-driving vehicles to interpret and respond to visual surroundings
- Carrying out key functionality like lane detection, traffic sign recognition, object and pedestrian detection
- Providing drones with visual intelligence for inspection, search/rescue and delivery operations
Assistive & Accessibility Technology
- Facilitating vision for the visually impaired via intelligent wearables and voice interfaces
- Sign language recognition through computer vision for enhanced deaf communication
- Automating photo descriptions on websites/apps to improve accessibility
Security & Surveillance
- Face recognition technologies for authentication and access control systems
- Real-time analysis of surveillance footage for safety monitoring
- Detection of threats, criminal activity, and restricted items using smart cameras
- Forensic-based image and video analysis for investigations
Augmented & Virtual Reality
- Enables more immersive visual environments by integrating computer graphics and real-world data
- Object detection and plane recognition allow the placement of augmented content anchored to physical spaces
- Eye and pose tracking support intuitive AR/VR controls and interactions
And many more scenarios! The responsiveness of computer vision models combined with their scalability via cloud infrastructure means almost every industry is finding applications for this remarkable technology. With more powerful AI accelerators and algorithms bringing down computing costs, computer vision is only the beginning of what it can enable for society.
So, in summary, computer vision incorporates a diverse set of techniques for unlocking visual scene understanding. The rapid advancement of deep learning and neural networks is enabling previously impossible feats like image generation and whole-scene parsing. We are steadily marching towards human-level visual intelligence in machines.
The key tasks fueling progress in computer vision include image classification, object detection and localization, image segmentation, recognition and retrieval, pose estimation, text detection and recognition, image captioning and visual SLAM.
Common methods across many areas now utilize convolutional neural networks and specialized architectures are being developed to push the state-of-the-art in each domain. However, classical computer vision techniques still remain useful when deep learning is infeasible.
As algorithms and computing power improve, computer vision promises to revolutionize areas such as medical imaging, autonomous vehicles, robotics, augmented reality, industrial automation, security, photography, and more in the coming years.
Comments
Loading comments…