GPT4All is an intriguing project based on Llama, and while it may not be commercially usable, it’s fun to play with.
GPT4All learned from a massive collection of helper interactions like word puzzles, stories, conversations, and code. They shared the process of gathering data, the training code, and the final model details to encourage open research and to make it easy to repeat. Plus, a simpler version of the model, so almost anyone can run it on their computer’s CPU.

Screenshot by Author, GPT4ALL Technical report
Is GPT4All your new personal ChatGPT? While it might not be a full-fledged replacement for ChatGPT, it certainly brings some exciting functionality.

This blog will explore GPT4All, an open-source project that takes fine-tuning beyond Alpaca, and see how it compares to ChatGPT.
Intro to GPT4All: What’s the Deal?
The team behind GPT4All created a report detailing their process. They used a million prompt responses generated with GPT-3.5 Turbo, which may be against OpenAI’s terms of service. Seeing how they constructed their dataset and fine-tuned the model is interesting.
Nomic.ai: The Company Behind the Project
Nomic.ai is the company behind GPT4All. One of their essential products is a tool for visualizing many text prompts. This tool was used to filter the responses they got back from the GPT-3.5 Turbo API. They compiled their dataset using various sources, including the CHIP-2 dataset, Stack Overflow coding questions, and the P3 dataset. After filtering out the not-so-good responses, they had around 500,000 pairs of prompts and continuations. They then fine-tuned the Llama model, resulting in GPT4All.
GPT4All Setup: Easy Peasy
The setup was the easiest one. Their Github instructions are well-defined and straightforward. There are two options, local or google collab. I tried both and could run it on my M1 mac and google collab within a few minutes.
Local Setup
- Download the
gpt4all-lora-quantized.binfile from Direct Link. - Clone this repository, navigate to
chat, and place the downloaded file there. - Run the appropriate command for your OS:
- M1 Mac/OSX:
cd chat;./gpt4all-lora-quantized-OSX-m1 - Linux:
cd chat;./gpt4all-lora-quantized-linux-x86 - Windows (PowerShell):
cd chat;./gpt4all-lora-quantized-win64.exe - Intel Mac/OSX:
cd chat;./gpt4all-lora-quantized-OSX-intel
Google Collab
Running on google collab was one click but execution is slow as its uses only CPU.
I executed the two code blocks and pasted. cd /content/gpt4all/chat;./gpt4all-lora-quantized-linux-x86
Captured by Author, Google Collab GPT4ALL
GPT4All in Action: How Does it Perform?
Testing GPT4All with a series of prompts, it becomes clear that the model is quite good at providing coherent answers.
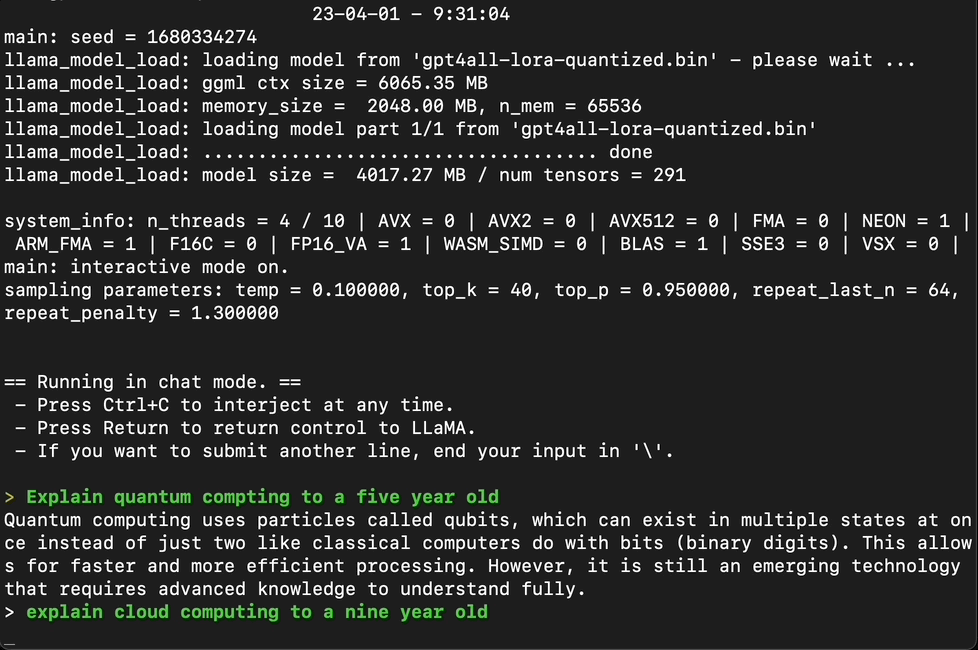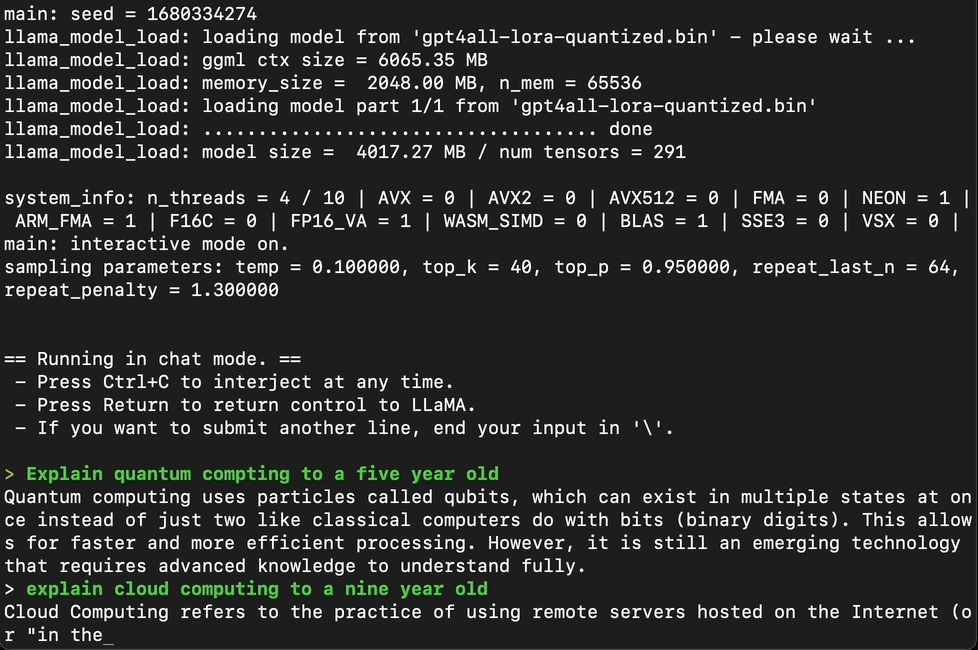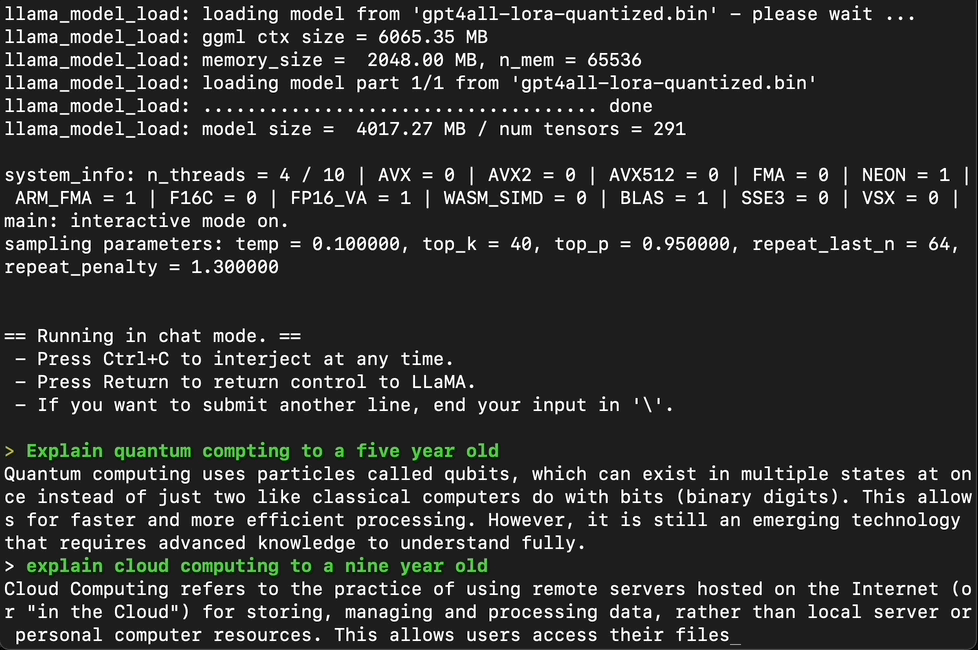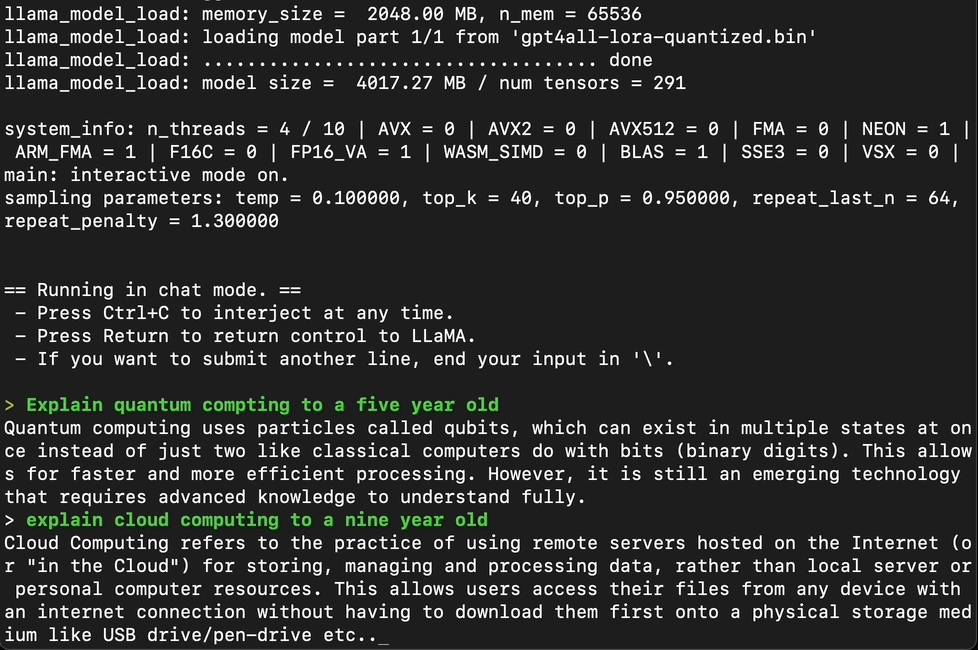
Captured by Author, GPT4ALL in Action
However, when testing the model with more complex tasks, such as writing a full-fledged article or creating a function to check if a number is prime, GPT4All falls short. It’s evident that while GPT4All is a promising model, it’s not quite on par with ChatGPT or GPT-4.
GPT4All Data Collection
The team collected approximately one million prompt-response pairs using the GPT-3.5-Turbo OpenAI API between March 20th and March 26th, 2023. They leveraged three publicly available datasets to gather a diverse sample of questions and prompts: Raw Data:
- The unified chip2 subset of LAION OIG
- Coding questions with a random sub-sample of Stackoverflow Questions
- Instruction-tuning with a sub-sample of Bigscience/P3

Captured by author, Train RAW Data responses Captured by author, Train RAW Data responses During data preparation and curation, the researchers removed examples where GPT-3.5-Turbo failed to respond to prompts and produced malformed output. After cleaning, the dataset contained 806,199 high-quality prompt-generation pairs. The team removed the entire Bigscience/P3 subset due to low output diversity. The final dataset consisted of 437,605 prompt-generation pairs.
Model Training and Reproducibility
The researchers trained several models fine-tuned from an instance of LLaMA 7B (Touvron et al., 2023). They used LoRA (Hu et al., 2021) to train their initial public release model on the 437,605 post-processed examples for four epochs. The team released all data, training code, and model weights to ensure reproducibility. Producing these models was approximately $800 in GPU costs and $500 in OpenAI API spend. Trained LoRa Weights:
- gpt4all-lora (four full epochs of training): https://huggingface.co/nomic-ai/gpt4all-lora
- gpt4all-lora-epoch-2 (three full epochs of training) https://huggingface.co/nomic-ai/gpt4all-lora-epoch-2 Raw Data:
- Training Data Without P3
Explorer: https://atlas.nomic.ai/map/gpt4all%5Fdata%5Fclean%5Fwithout%5Fp3> - Full Dataset with P3
Explorer: https://atlas.nomic.ai/map/gpt4all%5Fdata%5Fclean> You can train and generate your own model. Follow their documentation for more reference. **Find the google collab to train your own personal ChatGPT.
Evaluation and Use Considerations
GPT4All was evaluated using human evaluation data from the Self-Instruct paper (Wang et al., 2022). The results showed that models fine-tuned on this collected dataset exhibited much lower perplexity in the Self-Instruct evaluation than Alpaca. Although not exhaustive, the evaluation indicates GPT4All’s potential. The authors released data and training details to accelerate open LLM research, especially in the alignment and interpretability domains. GPT4All model weights and data are intended and licensed for research purposes only, with commercial use prohibited. The assistant data is gathered from OpenAI’s GPT-3.5-Turbo, whose terms of service prohibit developing models that compete commercially with OpenAI.
Future Roadmap
As per their GitHub page the roadmap consists of three main stages, starting with short-term goals that include training a GPT4All model based on GPTJ to address llama distribution issues and developing better CPU and GPU interfaces for the model, both of which are in progress. Plans also involve integrating llama.cpp bindings, creating a user-friendly conversational chat interface, and allowing users to submit their chats for future training, but these tasks have not been started yet. In the medium term, the focus will shift to integrating GPT4All with Atlas for document retrieval (blocked by GPT4All based on GPTJ) and Langchain, as well as developing simple custom training scripts for user model fine-tuning. Lastly, the long-term goals aim to enable anyone to curate training data for future GPT4All releases using Atlas and to democratize AI, with the latter currently in progress.

My Takeaway
While GPT4All is a fun model to play around with, it’s essential to note that it’s not ChatGPT or GPT-4. It may not provide the same depth or capabilities, but it can still be fine-tuned for specific purposes. If an open-source model like GPT4All could be trained on a trillion tokens, we might see models that don’t rely on ChatGPT or GPT-4 APIs. So, while GPT4All may not be the ChatGPT replacement you were hoping for, it’s still an exciting project showcasing open-source AI models' potential. So what do you think? Leave a comment so Medium can recommend you more such excellent content. The best part of reading articles is scrolling down to the comment section and finding some bonus information or funny comment. So, come on, let’s vibe the AI community! Follow me on social YouTube, Twitter, and Instagram.
Comments
Loading comments…