Introduction
From gathering market insights to monitoring competitor activities and obtaining public data for research, web scraping has emerged as a critical tool, empowering businesses and individuals alike with data-driven insights in a rapidly-changing digital landscape.
However, as web data extraction has gained popularity, it has prompted websites to employ more sophisticated methods to protect their data from bots and scrapers, driven by privacy concerns and platform integrity. While understandable, these protective measures can create substantial hurdles for legitimate web scraping projects conducted by businesses, individuals, or researchers.
One particularly challenging measure is the implementation of CAPTCHAs (Completely Automated Public Turing tests to tell Computers and Humans Apart). You've probably encountered them before - those little puzzles or challenges designed to distinguish between automated bots/scrapers and human users.
In this post, we will look at how and why CAPTCHAs are generated, the obstacles they pose for your data collection attempts, and how to get around them while using the Scraping Browser, a Puppeteer/Playwright/Selenium-compatible headful GUI browser that comes with out-of-the-box CAPTCHA-bypassing technology.
Understanding CAPTCHAs and Their Impact on Web Scraping
We've all encountered these frustrating challenges on websites where we have to prove that we are not robots - they typically involve visually distorted letters, numbers, or images that users must identify and input correctly to gain access to certain parts of the website. These are CAPTCHAs, which are security measures employed by websites to differentiate between bots/scrapers and legitimate human users.
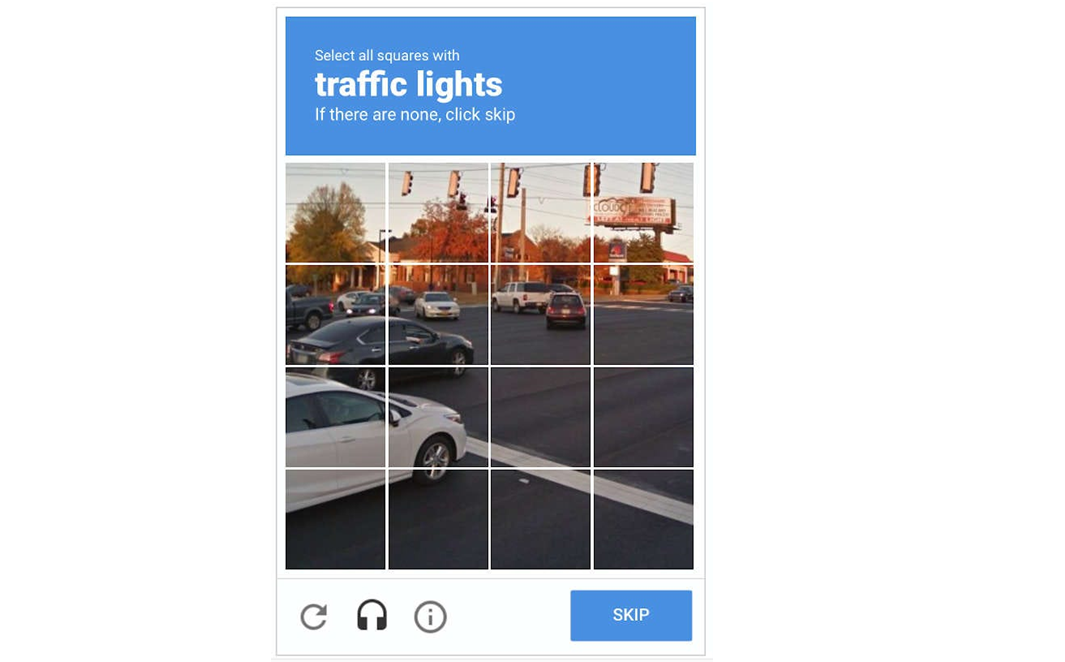
An example of a CAPTCHA
When your web crawler encounters a CAPTCHA, it faces a challenge. Since CAPTCHAs are designed to be visually or interactively solved by humans, automated scraping processes can't easily tackle them. As a result, the web crawler gets stuck, and your scraping progress comes to a standstill until the CAPTCHA is successfully completed.
But what prompts a website to generate a CAPTCHA in the first place (which consequently blocks our scraping attempt)? Let's look at some of the reasons for this:
- Browser Fingerprinting: Websites may use techniques like browser or device fingerprinting to identify bots or scrapers. These techniques analyze various attributes of the user's browser and device, such as screen resolution, installed fonts, and browser plugins, to create a unique fingerprint containing information about the configuration of a user's browser as well as software/hardware environment. When a scraper's fingerprint is detected, the website may respond with a CAPTCHA to validate the user.
- Unusual User-Agent: Web scrapers often use default or identifiable User-Agent strings, making them easily detectable by websites. When a website detects a non-standard or suspicious User-Agent, it may trigger a CAPTCHA to verify the legitimacy of the request.
- Cookie Tracking: Websites may use cookies to track user activity and identify bots. Scrapers may not handle cookies properly or may lack valid session information, which can prompt the website to present a CAPTCHA to verify the user's identity.
- Mouse Movement and Click Patterns: Modern CAPTCHAs like ReCaptcha may analyze mouse movement and click patterns to determine human-like behavior. Bots often have predictable movement, which can trigger the presentation of a CAPTCHA.
For large scale web scraping projects, CAPTCHAs present a significant obstacle, as they require manual intervention to solve. Implementing CAPTCHA-bypassing logic into your code manually is an extremely difficult task, often involving complex algorithms and continuous updates to adapt to evolving CAPTCHA challenges and website defenses.
Sure, you can make use of third-party libraries and proxies, but they come with their own set of challenges:
- You'll need to integrate them into your existing tech stack, which can be time-consuming and may require substantial changes to your codebase.
- These solutions may not always be entirely reliable, especially in the long term when websites update their CAPTCHA-generation mechanisms. You could find yourself constantly struggling to adapt and maintain scraping efficiency.
- They require you to invest in additional infrastructure, leading to increased costs and management complexities.
Let us now look into how an advanced solution like Bright Data's Scraping Browser can help us bypass CAPTCHAs and other challenges automatically.
Overcoming CAPTCHAs with the Scraping Browser's Unlocker Technology

Bright Data's Scraping Browser is an all-in-one comprehensive solution that combines the convenience of a real, automated browser with Bright Data's powerful unlocker infrastructure and proxy management services. It's also fully compatible with Puppeteer/Playwright/Selenium APIs.
Learn more: Scraping Browser - Automated Browser for Web Scraping
Let's look at how simple it is to set up and use the Scraping Browser:
- Before you write any scraping code, you use Puppeteer/Playwright/Selenium to connect to Bright Data's Scraping Browser using your credentials, via Websockets.
- From then on, all you have to worry about is developing your scraper using the standard Puppeteer/Playwright/Selenium libraries, and nothing more.
There is no need for you to handle numerous third-party libraries that deal with tasks such as proxy and fingerprint management, IP rotation, automated retries, logging, or CAPTCHA solving internally. The Scraping Browser takes care of all this and more on Bright Data's server-side infrastructure.
How is it able to do this? This is because, as previously mentioned, the Scraping Browser comes in-built with Bright Data's powerful unlocker infrastructure which means it arrives with CAPTCHA-bypassing technology right out of the box, no additional measures needed on your part.
The web unlocker technology:
- Enables near-perfect emulation of browser fingerprint information including plugins, fonts, browser version, cookies, HTML5 canvas element or WebGL fingerprint, Web Audio API fingerprint, operating system, screen resolution and more.
- Automatically configures relevant header information (such as User-Agent strings) and manages cookies according to the requirements of the target website so that you can avoid getting detected and blocked as a "crawler".
- Mimics all devices connected to any given system, including their corresponding drivers, mouse movements, screen resolution, and other device properties, achieving full device enumeration imitation.
- Efficiently handles HTTP header management both during the process of decoding (when the request is received) and encoding (when the response is sent).
- Seamlessly upgrades HTTP protocols with ease and rotates TLS/SSL fingerprinting so that the protocol versions making the requests match that of your browser's header and your requests appear genuine.
- Can solve reCAPTCHA, hCaptcha, px_captcha, SimpleCaptcha, and GeeTest CAPTCHA, and it is constantly updated to deal with websites that discover new ways to detect your scraping efforts.
- Is a managed service, meaning that you don't have to worry about updating your code to keep up with a website's ever-changing CAPTCHA-generation mechanisms. Bright Data takes care of all of that for you, handling the updates and maintenance on their end.
💡 Note: From CAPTCHA-solving to User-agent generation to cookie management and fingerprint emulation, Bright Data's unlocker infrastructure can bypass even the most sophisticated anti-scraping measures. Learn more here.
Let's now see the Scraping Browser in action. We'll use Playwright.
Configuring Bright Data's Scraping Browser
To use the Scraping Browser, you'll first need to sign up for a free trial (click on 'Start free trial' and enter the relevant information). After you enter your payment method, a free $5 credit is added so that you can get started.
Once signed in, follow these steps:
- At the dashboard, move to the 'My Proxies' section and under Scraping Browser, click on 'Get Started'.
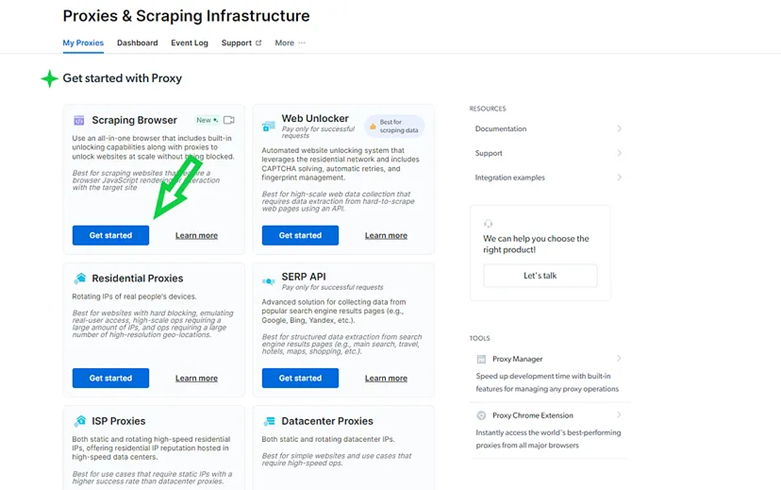
- At the 'Create a new proxy' page, input a name for your Scraping Browser proxy zone. Remember, to choose the right name for your browser since it can't be changed after creating it.
- Click on 'Add Proxy' to create and save your browser.
- To scrape a website with the Scraping Browser in Node.js or Python, go to your proxy zone's 'Access Parameters' tab. You'll find your API credentials including your Username (Customer_ID), Zone name (attached to username), and Password - copy these somewhere safe as we'll be using them in our code.
The Code: Scraping Amazon using The Scraping Browser and Python
Once you have the Scraping Browser's details in hand, install the following Python packages in your project directory. Here, you will be using the Playwright API to perform web scraping asynchronously.
pip install asyncio pip install playwright
We're going to visit a product category page on Amazon, and scrape the first page of results using Playwright, compiling our scraping results into an array of item names and their prices.
import asyncio
from playwright.async_api import async_playwright
# should look like 'brd-customer-<ACCOUNT ID>-zone-<ZONE NAME>:<PASSWORD>'
auth = 'USERNAME:PASSWORD'
async def main():
async with async*playwright() as playwright:
browser = await playwright.chromium.connect_over_cdp(f'wss://${auth}@brd.superproxy.io:9222')
page = await browser.new_page()
await page.set_default_navigation_timeout(2 * 60 _ 1000)
await page.goto('https://www.amazon.in/b?ie=UTF8&node=14439003031')
await page.wait_for_selector('div[class*="a-section a-spacing-base"]', timeout=5000)
elements = await page.query_selector_all('div[class*="a-section a-spacing-base"]')
results = []
for element in elements:
item_name = await element.query_selector('div[class*="s-title-instructions-style"]')?.text_content().strip() or ''
item_price = await element.query_selector('div[class*="s-price-instructions-style"] .a-price .a-offscreen')?.text_content().strip() or ''
results.append({
'itemName': item_name,
'itemPrice': item_price,
})
print(results)
await browser.close()
# Run the asynchronous function
asyncio.run(main())
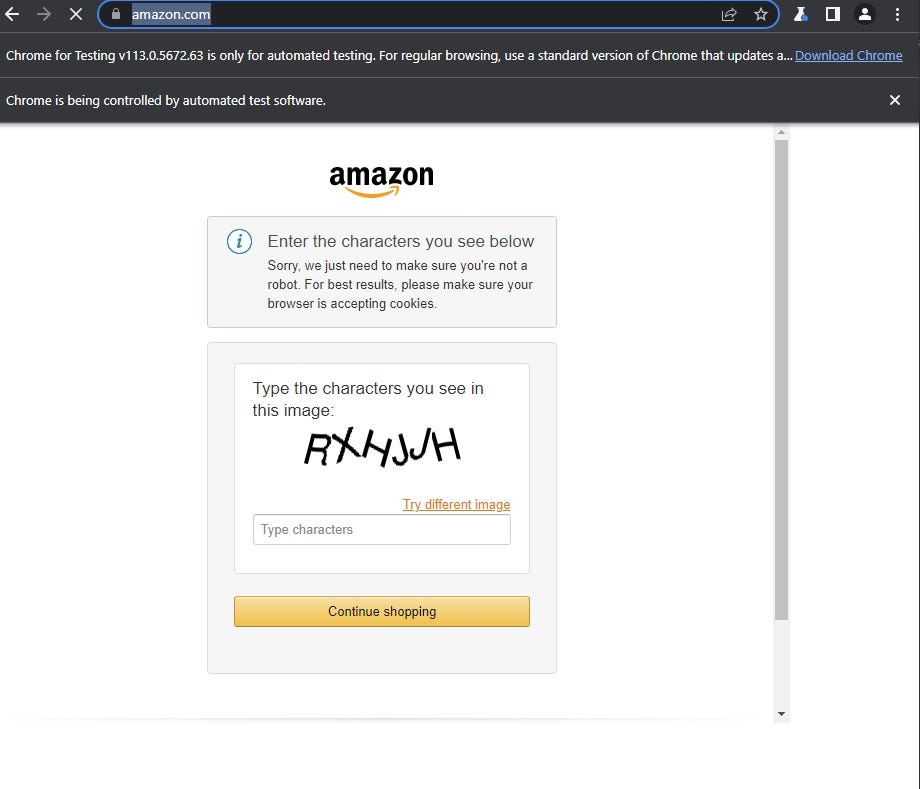
But, with the remote connection to Bright Data's Scraping Browser (via WebSockets and the Chrome DevTools Protocol) via Playwright's connect_over_cdp method...
browser = await
playwright.chromium.connect_over_cdp(f'wss://{auth}@brd.superproxy.io:9222')
...now, your Playwright script is being executed by the remote, headful Chromium instance on Bright Data's servers. It'll automatically take care of bypassing the CAPTCHA (and any other anti-scraping measure), and you'll see proper results, instead:
[
{
itemName: "U.S. POLO ASSN.US Polo Women's Button Down Shirt",
itemPrice: "₹646",
},
{
itemName: "Rain & RainbowRain and Rainbow Women's Straight Kurta",
itemPrice: "₹349",
},
{
itemName: "U.S. POLO ASSN.US Polo Women's Cotton Body Con Dress",
itemPrice: "₹1,136",
},
{
itemName: "U.S. POLO ASSN.US Polo Women's Solid T-Shirt",
itemPrice: "₹618",
},
// ...
];
Conclusion
CAPTCHAs can pose considerable challenges to web scraping projects, especially large-scale ones. The Scraping Browser offers an all-in-one solution with its powerful unlocker infrastructure, bypassing CAPTCHAs effortlessly.
From emulating device/browser fingerprints to header and cookie management, the Scraping Browser ensures uninterrupted scraping at scale, eliminating the need for manual CAPTCHA-bypassing logic, third-party libraries, or additional infrastructure on your part.
Additionally, Bright Data ensures full compliance with data protection laws, including the EU's General Data Protection Regulation (GDPR), and the California Consumer Privacy Act of 2018 (CCPA). This helps to ensure that your scraping operations do not breach a website's terms of compliance or data privacy laws.
Whether you're an individual or run a business, with the Scraping Browser, you can efficiently access web data uninterruptedly and extract crucial insights while respecting data privacy and integrity. Since it comes with a free trial, give it a shot and see the difference it can make in your web scraping experience.
-> Scraping Browser - Build Unblockable Scrapers with Playwright, Puppeteer and Selenium
Comments
Loading comments…