
Image generated with DreamStudio
With millions of public profiles on Facebook, the platform is a treasure trove of data that can be useful for multiple industries. This data includes profile names, posts, friend lists, photos, and other publicly accessible information which can be used to make informed marketing strategies, improve customer engagement, and stay ahead of the competition. And you can easily extract this data from the platform using web scraping.
When it comes to web scraping, JavaScript is a popular language of choice, and headless browsers such as Selenium, Playwright, and Puppeteer are good solutions for automation and advanced data extraction.
However, mastering these tools may not be enough to extract data from Facebook because of its anti-scraping mechanisms. Extracting data from Facebook comes with several challenges since the website implements anti-bot measures such as CAPTCHAs and rate limits.
To bypass these blocks, it's not only crucial to have an in-depth knowledge of web scraping tools and techniques, but also a necessity to combine them with a set of reliable proxies. Or, better yet integrate some off-the-shelf scrapers to streamline your data extraction process. This is because for large-scale scraping projects, in-house scraping scripts often fall short because of the frequent layout changes most websites introduce.
At the same time, you should also ensure compliance with Facebook's regulations to avoid getting banned or worse.
Hence, for a seamless web scraping experience, you could opt for an off-the-shelf headful, full-GUI, remote browser like Bright Data's Scraping Browser which offers a powerful solution and is also a reliable option when it comes to legal compliance.
In this article, we'll delve into the importance of Facebook profile data, look at the several limitations to acquiring this data, and present the solutions through JavaScript, Puppeteer, and Bright Data's Scraping Browser.
👉 Robust scraping solutions and ready-made datasets for Facebook, LinkedIn, and more:
Bright Data - All in One Platform for Proxies and Web Scraping
Use cases of Facebook profile data
Only publicly available information on Facebook profiles can be used according to their data extraction policy. This public data can be valuable for companies and individuals in several ways. Here we'll look at fields such as research, business, and human resources and see several use cases in each one of them:
Research
- Demographic analysis: Extracting age, gender, location, and interests can help researchers understand population trends and characteristics.
- Psychological analysis: Facebook user engagement data offers a window into individuals' psychological characteristics, enabling researchers to infer traits such as political leanings. For instance, by analyzing this data, data scientists can develop predictive models to forecast the next elections.
- Epidemiology research: During the COVID-19 pandemic, social media platforms like Facebook emerged as valuable resources for epidemiology research. By analyzing user posts about their experiences with the virus, including diagnoses and personal losses, researchers could tap into a vast, real-time dataset that often outpaced traditional health center reporting.
Business
- Targeted advertising: Just like Facebook uses its own data to make tailored advertisements for its users, you can also use Facebook's publicly available data to create targeted ad campaigns.
- Customer insights: Facebook profile data gives a good understanding of customers' preferences, behaviours, and needs. Allowing companies to apply fine-tuned marketing strategies, driving more precise customer engagement and loyalty.
- Influencers and partnerships: Web scraping Facebook profile data, allows companies to identify and connect with influential individuals who possess large networks or specific characteristics that align with their brand values. These individuals, often referred to as influencers, can be valuable partners in promoting products and services.
Human Resources
- Candidate hunting: Just like LinkedIn, Facebook profile data can also be used to find potential job candidates based on their skills, experience, and interests.
- Customer satisfaction: Users' comments and engagement with the company's services or products, can be used to understand customer satisfaction.
Beyond the examples mentioned earlier, Facebook profile data applications can also extend to other fields, such as security, healthcare, and education. For instance, law enforcement agencies can utilize Facebook data to detect criminal activity and track down suspects. Healthcare organizations can identify clusters of individuals sharing similar health concerns and tailor their services to meet those needs.
In the next section, we'll delve into the challenges that may arise when scraping Facebook. And by the end of this article, you'll be well-equipped to extract data from Facebook public profiles, without getting blocked or getting into legal troubles.
👉** Find ready-made Facebook datasets:**
Facebook Datasets - Get a Free Sample
Challenges of web scraping Facebook profile data
While Facebook profile data offers immense potential for analysis and insight, harnessing this data is not easy. Extracting it seamlessly requires significant resources and capabilities, and even so, you may face several key challenges that can block your web scraping efforts. These challenges include:
- CAPTCHAs: Facebook uses CAPTCHAs to verify that you're a human. These can be difficult to bypass, even with advanced automation techniques using headless browsers like Puppeteer.
- Rate limiting: Too many requests will result in IP blocking. Hence IP rotation is key to web scrape Facebook profile data.
- Dynamic content loading: Facebook uses JavaScript to load content dynamically and standard HTML parsers don't process JavaScript. A good knowledge of automation with headless browsers is necessary.
- Website structure changes: From time to time, Facebook may change its HTML structure. Requiring constant maintenance of your web scraping infrastructure and applying changes when necessary, to ensure you don't miss out on valuable data.
- Ethical and legal issues: Scraping Facebook is not illegal, but you should only extract publicly available data, ensuring you respect the crawl rate and the robots.txt file.
- Data handling: Facebook profile data can be information a user puts in the bio, profile and cover images, followers/following, user's posts and comments, and so on. Therefore, the output can be messy and difficult to filter and structure.
Certain challenges can be mitigated with the use of headless browsers like Puppeteer, which can handle dynamic content loading, profile page navigation, and even overcome CAPTCHA challenges.
You'd also need to bypass blocking mechanisms like rate limiting, and for that, you'd surely need IP rotation. Now, you can get a lot of proxy services that offer IP rotation and they might be cheap or free, but you should always avoid those and opt for reliable options.
Free proxy services often offer IPs with bad reputations which might get flagged and fail frequently, disrupting your data extraction workflow. Hence, to avoid these and for seamless data extraction, always choose reputed providers, even if you're paying a bit more.
One such reliable proxy provider is Bright Data and in the next chapter, we will explore Bright Data's Scraping Browser, a headful browser that combines a vast proxy network and block-bypassing mechanism while offering seamless integration with JavaScript and Puppeteer.
👉 Find out more about Bright Data's proxy network and the types of proxies they offer:
Bright Data's Scraping Browser as a comprehensive solution for scraping Facebook profiles
Bright Data's Scraping Browser
Extracting data from Facebook profiles can be accomplished using JavaScript and headless browsers like Puppeteer, a Node.js library that offers a user-friendly API to control Chrome or Chromium browsers. This allows for automated web page interaction, screenshot generation, and data extraction from web pages.
However, as we've previously discussed, even with expertise in Puppeteer and JavaScript, some challenges may be very difficult to bypass. That's where Bright Data's Scraping Browser, a headful browser designed to overcome these obstacles and provide a seamless web scraping experience, comes in.
This tool is designed to overcome any anti-block measures while providing reliable, ethically sourced proxies and IP management so that users can focus on web scraping only and forget legal issues and complexities.
👉 Learn how Bright Data's Scraping Browser compares to a headless browser:
Scraping Browser vs. Headless Browsers - Complete Guide
As a prerequisite, a good knowledge of JavaScript and browser automation is necessary to use this tool.
Let's list the main advantages of Bright Data's Scraping Browser:
- Headful browsing: Unlike headless browsers, Bright Data's Scraping Browser runs in a visible browser window, allowing it to mimic human-like behaviour and evade detection by websites that use anti-scraping techniques.
- Advanced anti-scraping measures: The tool is equipped with advanced algorithms that can detect and bypass common anti-scraping measures, such as CAPTCHAs, rate limiting, and IP blocking.
- Premium proxies: The Scraping browser is equipped with Bright Data's premium residential proxies. You can use 72M high-speed IPs across 195 countries, ensuring anonymity and web scraping without interruptions.
- Fast and reliable: The Scraping Browser is optimized for speed and reliability, allowing users to extract large amounts of data quickly and efficiently.
- Seamless integration: The browser can be easily integrated with popular programming languages like Python, Java, and Node.js, making it a versatile tool for web scraping.
- Support for multiple browsers: The browser supports multiple browser types, including Chrome, Firefox, and Edge, allowing users to choose the best browser for their specific scraping needs.
- Reduced maintenance: The browser's ability to bypass anti-scraping measures reduces the need for constant maintenance and updates.
- Scalability: The Scraping Browser is designed to handle large-scale web scraping operations, making it an ideal solution for enterprises and businesses that require massive data extraction.
Overall, Bright Data's Scraping Browser is a powerful tool for web scraping and data extraction, offering advanced anti-scraping capabilities, fast and reliable performance, and easy integration with several programming languages.
👉 To know more about integrations, check out the official documentation:
Introduction - Bright Data Docs
In the next section, we'll learn how to use it with Javascript and Puppeteer and show a real-life example of Facebook profile data output.
How to Scrape Facebook with Bright Data's Scraping Browser: The Code
To start using Bright Data's Scraping Browser, you first need to create an account or sign up with Google and then start your free trial.
Once you do that, you'll have access to a user-friendly dashboard where you can activate proxies, the Scraping Browser, and other features.
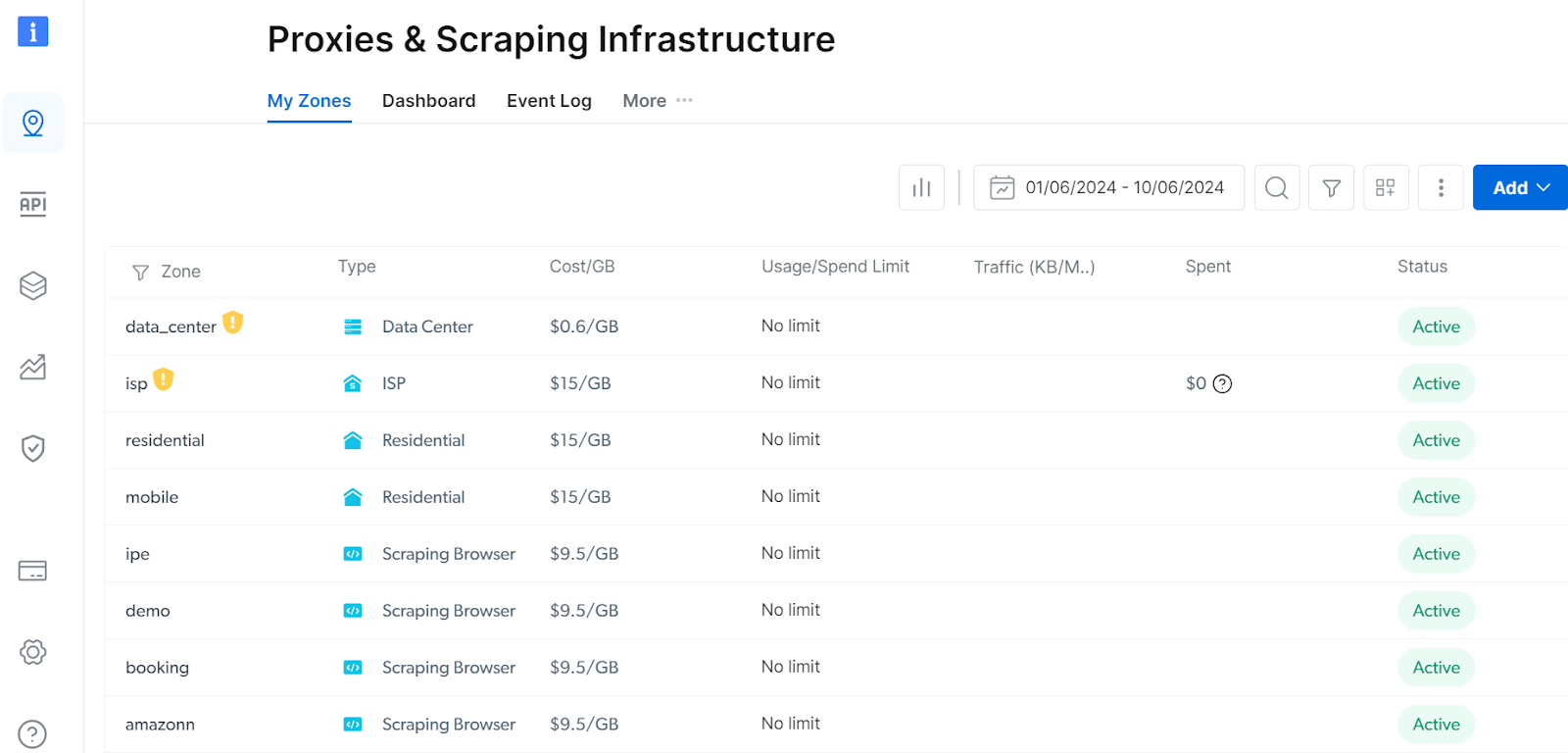
Bright Data's dashboard
Above you can see the different active options in Bright Data's dashboard, with types ranging from datacenter proxies, to residential ones and the Scraping Browser. For instance, you can click on one of the Scraping Browser options and access its authentication parameters.
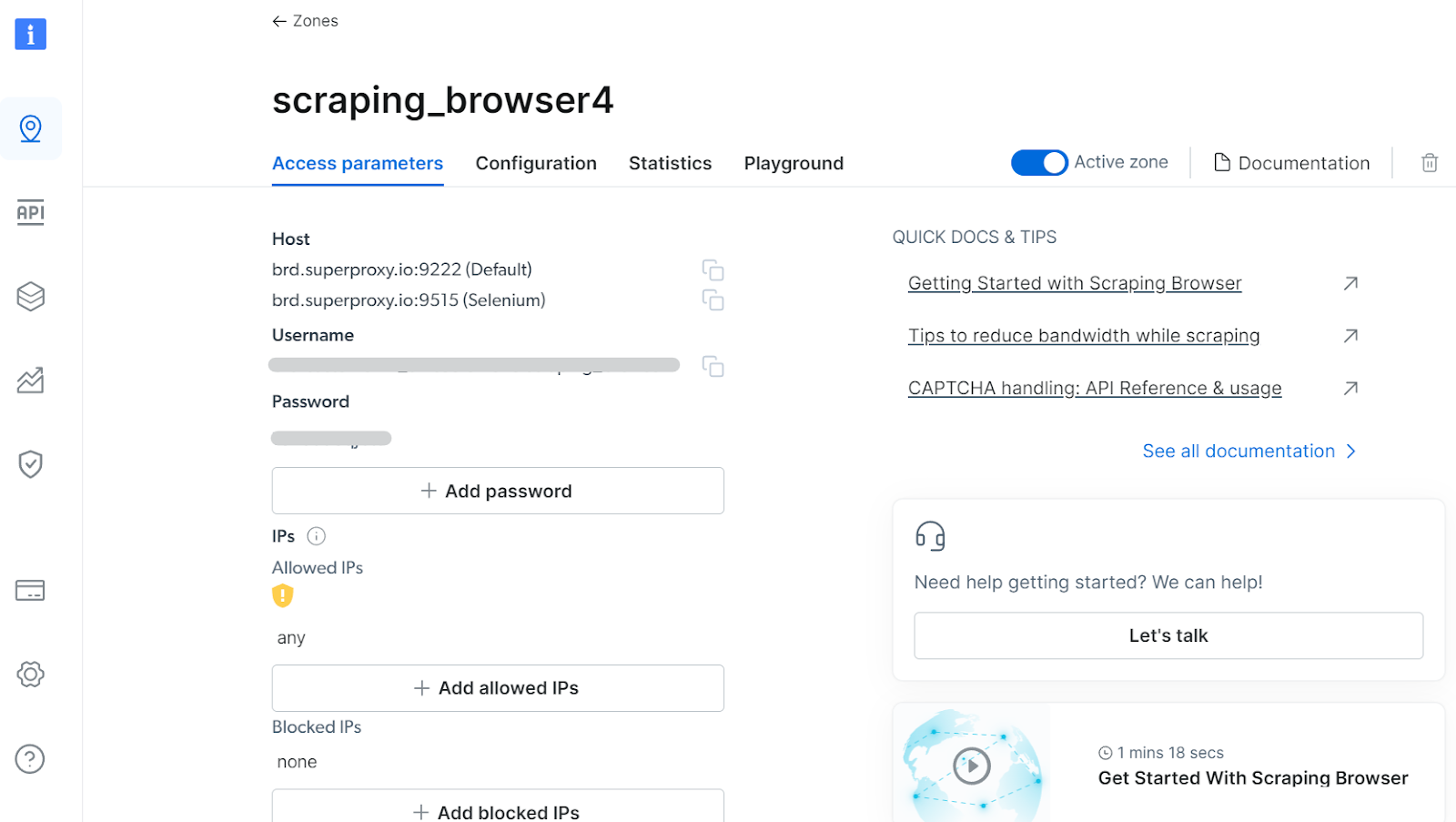
Scraping Browser parameters
With the host, username, and password parameters, you will be able to use the Scraping Browser API in your script, we'll see how in a bit.
But first, we need to install Puppeteer on our machine:
npm i puppeteer-core
Once installed, you can follow the JavaScript code example with Puppeteer on this documentation page:
Configuration - Bright Data Docs
Let's now take a look at our code.
const USERNAME = "<scraping_browser_username>";
const PASSWORD = "<scraping_browser_password>";
const puppeteer = require("puppeteer-core");
const AUTH = `${USERNAME}:${PASSWORD}`;
const SBR_WS_ENDPOINT = `wss://${auth}@zproxy.lum-superproxy.io:9222`;
async function main() {
console.log("Connecting to Scraping Browser...");
const browser = await puppeteer.connect({
headless: false,
browserWSEndpoint: SBR*WS_ENDPOINT,
});
try {
console.log("Connected! Navigating...");
const page = await browser.newPage();
console.log("Navigated! Scraping page content...");
await page.goto("https://www.facebook.com/zuck", {
timeout: 2 * 60 \_ 10000,
});
await new Promise(resolve => setTimeout(resolve, 5000)); // wait for 5 seconds
console.log("Extracting data!");
// Select all child elements within the parent container
const elements = await page.$$eval(
'.x1gan7if > \*', elements => elements.map(el => el.textContent));
console.log(elements);
console.log("Taking screenshot to page.png");
await page.screenshot({ path: "./page.png", fullPage: true });
} finally {
await browser.close();
}
}
if (require.main === module) {
main().catch((err) => {
console.error(err.stack || err);
process.exit(1);
});
}
At the beginning of the code, we add two variables, one for the username and another for the password, both taken from the Scraping Browser at Bright Data's dashboard. With them, we set up the SBR_WS_ENDPOINT which is used to create the Puppeteer browser object.
Once connected to the Scraping Browser endpoint, we create a page object which serves to apply automation tasks in the browser. By using the page object with the .goto() function, we open the target website, which in this case is Mark Zuckerberg's Facebook profile.
We wait for 5 seconds, to ensure we display the full page and then we extract the data from a specific class in the HTML code, which points to the "About" section of Mark Zuckerberg's profile page. You can see the x1gan7if class highlighted in the screenshot below:
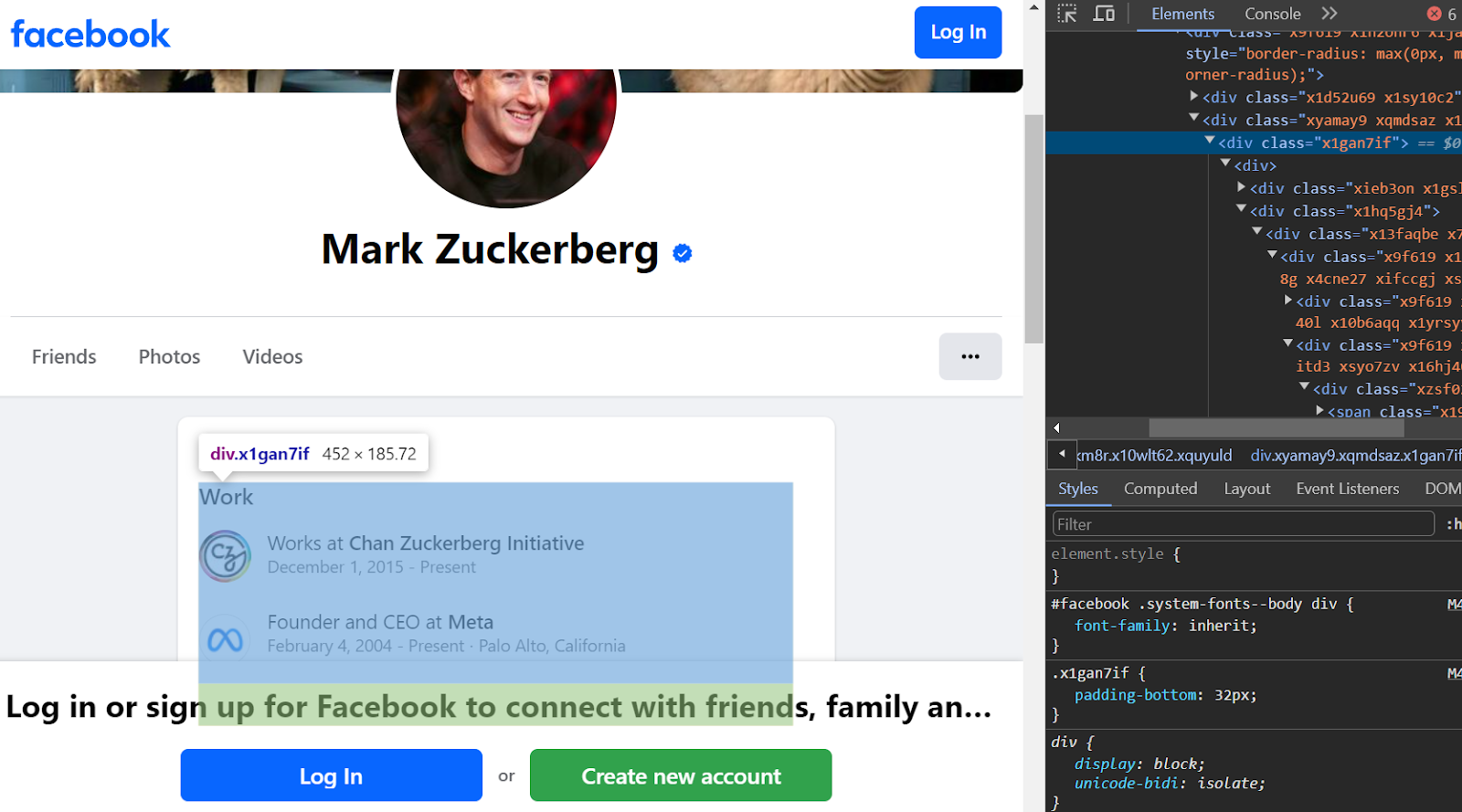
Screenshot of the HTML class of the "About" section
The elements from the class x1gan7if are extracted and this is the output:
[
'WorkWorks at Chan Zuckerberg InitiativeDecember 1, 2015 - PresentFounder and CEO at MetaFebruary 4, 2004 - Present-Palo Alto, CaliforniaBringing the world closer together.',
'WorkWorks at Chan Zuckerberg InitiativeDecember 1, 2015 - PresentFounder and CEO at MetaFebruary 4, 2004 - Present-Palo Alto, CaliforniaBringing the world closer together.',
'CollegeStudied Computer Science and Psychology at Harvard UniversityAugust 30, 2002 - April 30, 2004',
'CollegeStudied Computer Science and Psychology at Harvard UniversityAugust 30, 2002 - April 30, 2004',
'High schoolWent to Phillips Exeter AcademyClass of 2002Went to Ardsley High SchoolSeptember 1998 - June 2000'
]
The output above is taken from the "About" section, therefore you can see information regarding work, college, and high school. Nonetheless, there's much more you can scrape from Facebook profiles, such as followers, similar profiles, photos, videos, and comments.
Conclusion
In this guide, you saw how effortlessly we extracted data from Facebook profiles using Bright Data's Scraping Browser, JavaScript, and Puppeteer. By leveraging more Puppeteer functions, developers can access additional profile page features and structure the output data using JavaScript.
Notably, most public Facebook profiles can be scraped without logging in, but with Puppeteer, you can automate login and navigate multiple profiles without restrictions, just be sure to comply with Facebook's legal guidelines.
You also saw how you can address several Facebook web scraping challenges, including anti-bot measures, rate limiting, and dynamic content loading. While a good understanding of headless browsers and JavaScript can help bypass some challenges, it's unlikely to overcome CAPTCHAs and other anti-bot measures alone. Bright Data's Scraping Browser, paired with reputed proxies, provides a comprehensive solution to these issues, ensuring uninterrupted and legally compliant web scraping activities.
To test it yourself, go ahead and take their free trial.
Comments
Loading comments…