
Photo by Kaleidico on Unsplash
Introduction
A 2021 survey revealed that 17 percent of North American and European e-commerce companies planned to adopt dynamic pricing, while 21 percent were already leveraging this strategy.
Because of the dynamic nature of today's online markets - with varying demand patterns, competitor pricing, and rapidly changing consumer behavior - traditional static pricing models are no longer cutting it. The adoption of dynamic pricing is becoming increasingly crucial for e-commerce companies seeking to maintain a competitive edge and optimize their pricing strategies, allowing them to remain agile and responsive to market fluctuations.
By leveraging web scraping, e-commerce companies can gain real-time insights into product prices, availability, and customer preferences. This enables them to make informed and dynamic pricing decisions, optimizing revenues and maximizing profitability.
However, while web scraping can offer significant advantages for dynamic pricing strategies in e-commerce, it also comes with its fair share of challenges.
In this article, we'll delve into how web scraping can enhance and optimize dynamic pricing strategies, the challenges we have to overcome, and finally, we'll introduce an advanced and innovative solution in the form of the Scraping Browser that can help us get around these challenges, ensuring a seamless and continuous data gathering process.
-> Scraping Browser - Build Unblockable Scrapers with Puppeteer, Playwright and Selenium
Enhancing Dynamic Pricing Strategies with Web Scraping
Understanding Dynamic Pricing
Dynamic pricing is a real-time pricing strategy that involves adjusting product costs based on demand, competitor pricing, and market conditions.
Unlike traditional static pricing, dynamic pricing enables e-commerce companies to swiftly respond to market changes and optimize revenue.
A prime example is how Amazon dynamically adjusts the prices of its products based on factors like customer demand, competitor prices, and even the time of day. For instance, prices of certain products may drop during periods of low demand or increase during peak shopping times like Black Friday.
Having understood how dynamic pricing works, let us now look into how web scraping can significantly enhance and optimize dynamic pricing strategies in the context of e-commerce.
Benefits of Web Scraping for Dynamic Pricing
From real-time market insights to competitor monitoring, web scraping (the extraction of publicly available data from e-commerce sites) can play a crucial role in helping your e-commerce company adopt, enhance and optimize a dynamic pricing strategy:
- Real-Time Market Insights: The simplest use case - companies can use web scraping to track the prices of its competitors' products in real-time. By continuously monitoring competitor prices, they can quickly identify instances where their prices are higher and adjust their pricing accordingly to remain competitive.
- Price Matching and Undercutting: By employing algorithms and machine learning models, e-commerce companies can determine ideal price points for products based on various factors. For example, using historical sales data and scraping competitor prices, a company may discover that a particular product sells better at a slightly lower price than their current static price. They can then adjust the pricing dynamically to maximize revenue.
- Monitoring Product Availability: Web scraping enables e-commerce companies to monitor product availability across various online platforms. For instance, a company can use web scraping to check the stock status of products they offer on multiple marketplaces. If a product becomes scarce or goes out of stock in a competitor's store, they can adjust the prices dynamically to reflect scarcity, optimizing profits during such periods.
- Competitor Analysis: Keeping an eye on competitors is crucial in the ever-evolving e-commerce landscape. Web scraping facilitates comprehensive competitor analysis, allowing companies to track their pricing strategies, promotions, and product offerings. For instance, by scraping competitor websites regularly, a company can identify when a competitor launches a sale or offers discounts on certain products. Armed with this knowledge, they can respond promptly with their own dynamic pricing adjustments to retain their customer base.
- Demand Analysis: Dynamic pricing relies on monitoring and analyzing demand and trends. E-commerce companies can use web scraping to track usage trends of high-traffic competitors. For instance, since demand for swimwear increases during summer, an e-commerce company can adjust the pricing for their own swimwear line to offer competitive prices during peak demand periods
By leveraging these benefits when it comes to dynamic pricing, your e-commerce business can improve revenue generation, increase customer satisfaction, and secure a sustainable competitive advantage in the online marketplace.
However, implementing reliable web scraping for dynamic pricing does come with its fair share of challenges. Let's delve into some of these.
Challenges of Web Scraping for Dynamic Pricing in E-commerce
Let's shed some light on some key obstacles companies are likely to run into while web scraping competitors. These challenges include:
- Anti-Scraping Measures: Many websites employ anti-scraping measures to prevent bots and scrapers from accessing their data. These can include CAPTCHAs, IP blocking, and bot detection measures that might not block you - but feed you false information, knowing it's a good bet you're a competitor - and other techniques that hinder web scraping activities. Overcoming these measures requires implementing logic in your code that can mimic human behavior and relying on third-party libraries for CAPTCHA-solving mechanisms, using proxies, or rotating user agents. Trying to implement this manually in your code can get messy real quick in practical terms, and make it significantly harder to maintain your codebase.
- Rate Limiting and IP Blocking: When you extract data at too high a frequency from a website, your IP addresses may be blocked, preventing further access. Moreover, some E-commerce websites might implement geolocation blocks, restricting access to information from certain regions or countries based on your IP address. Some websites may even blacklist known ranges of free proxies.
- Legal and Ethical Considerations: Web scraping practices can raise legal and ethical concerns, as scraping data from certain websites may violate their terms of service, or copyright laws. It is crucial you ensure that the proxies you are using are ethically sourced, as unethically sourced proxies may be a violation of data privacy laws, or simply blacklisted en masse by websites.
- Scalability and Performance: As your e-commerce business grows and expands its product offerings, the volume of data to be scraped also increases. Ensuring the scalability and performance of web scraping is essential to maintain real-time market insights for dynamic pricing. But this may require investing in additional infrastructure to store all the data which may quickly become another resource-drain.
Considering the number of challenges involved, the task of implementing a scalable and seamless web scraping approach for dynamic pricing may seem overwhelming. However, what if you could implement a comprehensive all-in-one solution that streamlined the entire process while carefully addressing all the mentioned factors?
That's precisely where Bright Data's Scraping Browser comes in.
The Scraping Browser: A Comprehensive Solution for Dynamic Pricing in E-Commerce
The Scraping Browser is a headful, fully GUI browser that is perfectly compatible with Puppeteer/Playwright/Selenium APIs. Making use of Bright Data's robust proxy network and unlocker infrastructure, it comes with block bypassing technology right out of the box. It can automate IP address rotation, avoid bot detection, and circumvent CAPTCHAs with ease.

Generally, fully GUI headful browsers have the best chance of not being identified and blocked by anti-bot techniques; however, they tend to be performance intensive and aren't always a viable option, particularly for serverless deployments.
The Scraping Browser solves this problem by offering the best of both worlds:
- It isn't another Puppeteer/Playwright/Selenium alternative, but instead, a potentially infinite number of remote, headless, fully managed browser instances running on Bright Data's servers,
- All of these instances use Bright Data's powerful unlocker infrastructure, providing seamless emulation of headers and browsers, effectively overcoming IP/Device based fingerprinting.
- It automatically solves CAPTCHAs and other JavaScript-based challenges like CloudFlare and HUMAN, with no external libraries or coding required on your part.
All of which you are able to seamlessly integrate with your existing headless Puppeteer/Playwright/Selenium workflows via the Chrome DevTools Protocol (CDP) over a WebSocket connection to Bright Data's servers.
This possibility of scaling your scraping workload horizontally across multiple concurrent remote sessions - in the cloud, fully managed, with no infrastructure required on your part - makes the Scraping Browser an excellent choice for scalable data extraction in the field of e-commerce.
Learn more about the Scraping Browser's functionalities:
Scraping Browser - Automated Browser for Scraping *Scraping Browser is a GUI browser designed for web scraping. An automated browser that is experienced as a headless...*brightdata.com
How to Use the Scraping Browser
Our goal for this project is simple: we'll assume we are a retailer selling high-end headphones - and we want to essentially use Amazon's bestseller listing for headphones as a guide to price our own products, dynamically.
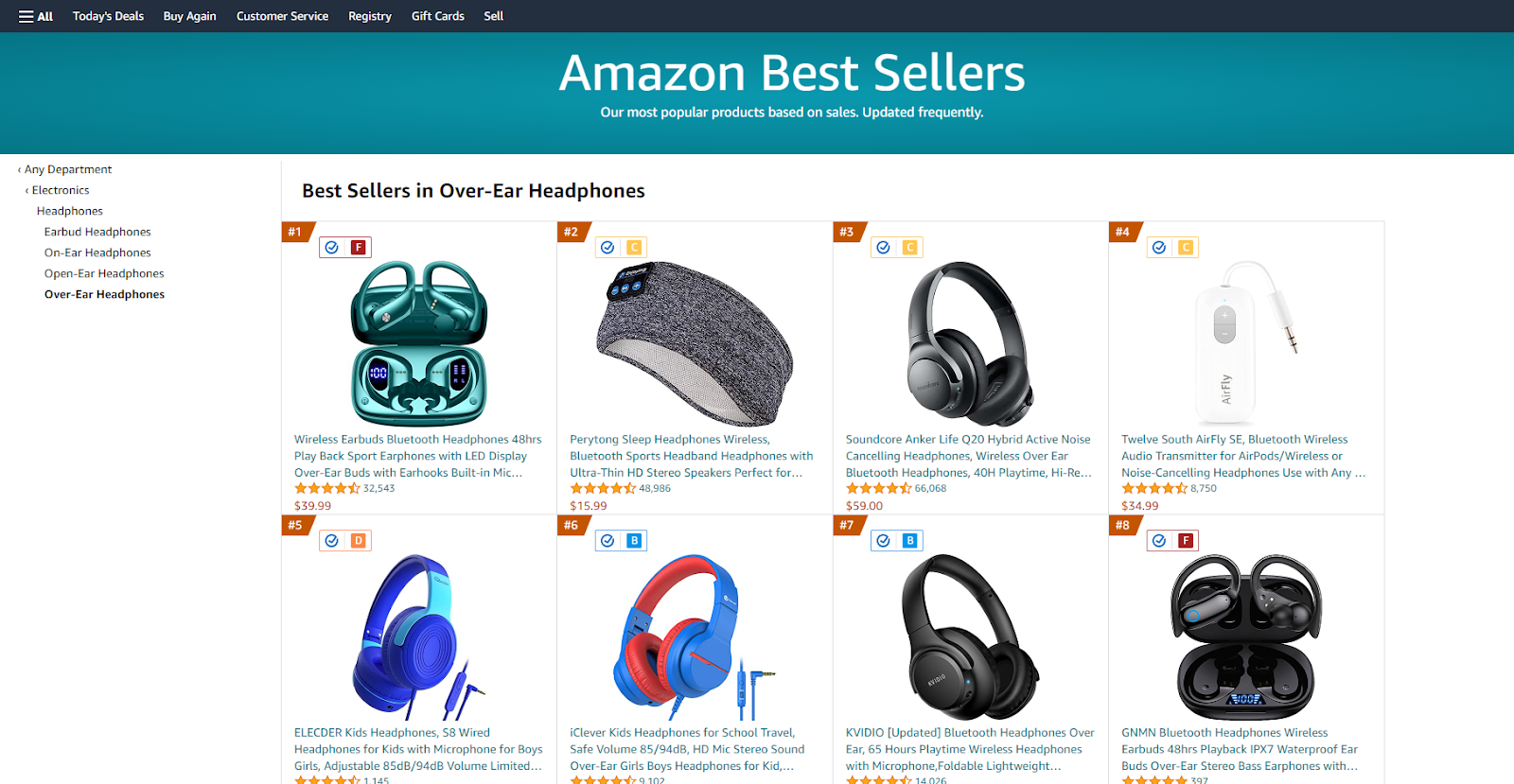
For this, the first step is to actually scrape the pricing data for our niche. Amazon employs considerable anti-scraping measures, so Bright Data's Scraping Browser - with its unlocker infrastructure - will serve us well. We can rely on it entirely, and not have any anti-bot bypass logic in our code, keeping it clean and only focused on our business logic i.e. scraping prices.
Step 1: Create an account
If you haven't yet signed up for Bright Data, don't hesitate to do so as signing up is completely free (click on 'Start free trial' and enter your details). During the registration process, you will be prompted to enter your payment method, and as a welcome bonus, you'll receive a $5 credit to jumpstart your scraping projects.
Step 2: Add Scraping Browser to your account
Once you've successfully signed up and logged in, head straight to the 'My Proxies' page on your dashboard. Under the 'Scraping Browser' section, click on the 'Get started' button to begin creating your very own Scraping Browser zone.

Step 3: Name a proxy zone
On the 'Create a new proxy' page, you'll need to choose a name for your newly created Scraping Browser proxy zone. Be mindful when selecting a name, as it cannot be changed after creation. Opt for a descriptive and memorable name to help you identify its purpose easily.
Step 4: Create the Proxy
After providing a suitable name, click on the 'Add proxy' button to create and save your Scraping Browser zone. This step is essential to ensure you have a dedicated space to carry out your web scraping activities smoothly.
Step 5: Get API Credentials
To integrate the Scraping Browser with your preferred programming language, such as Node.js or Python, you'll need your API credentials. Go to your proxy zone's 'Access parameters' tab to access your Username (Customer_ID), Zone name (attached to username), and Password. These credentials will be crucial for successful integrations.
Now, you're ready to incorporate it into existing Puppeteer code.
Step 6 : The Code
First, you'll need to instantiate a new Nodejs project and install Puppeteer. To do that, run the following command in your project's directory.
npm init -y
npm i puppeteer-core
Next, create a new file within your project directory (name it scraper.js) and paste in the following code.
const puppeteer = require("puppeteer-core");
// should look like 'brd-customer-<ACCOUNT ID>-zone-<ZONE NAME>:<PASSWORD>'
const auth = "<your username>:<your password>";
(async () => {
let browser;
try {
browser = await puppeteer.connect({
browserWSEndpoint: `wss://${auth}@brd.superproxy.io:9222`,
});
const page = await browser.newPage();
await page.goto(
"https://www.amazon.com/Best-Sellers-Over-Ear-Headphones/zgbs/electronics/12097479011"
);
// Wait for the elements to be available
await page.waitForSelector("div[class*='zg-grid-general-faceout']");
const data = await page.evaluate(() => {
const elements = Array.from(
document.querySelectorAll("div[class*='zg-grid-general-faceout']")
);
const results = [];
for (const element of elements) {
const itemName =
element.querySelector("a.a-link-normal span")?.textContent.trim() ||
"";
const itemPrice =
element
.querySelector("span[class*='a-color-price']")
?.textContent.trim() || "";
results.push({
itemName,
itemPrice,
});
}
return results;
});
console.log(data);
await browser.close();
} catch (err) {
console.error("Error:", err);
}
})();
With puppeteer.connect() we're initiating the remote connection between the client and the Chromium instance running on Bright Data's server, using the Chrome DevTools Protocol, over a WebSocketconnection (wss://), using our auth string as the credentials.
All done! Run the script using the following command:
node scraper.js
This will execute the script, and then display the content of the scraped page in the terminal.
[
{
itemName:
"Wireless Earbuds Bluetooth Headphones 48hrs Play Back Sport Earphones with LED Display Over-Ear Buds with Earhooks Built-in Mic Headset for Workout Green BMANI-VEAT00L",
itemPrice: "$39.99",
},
{
itemName:
"Perytong Sleep Headphones Wireless, Bluetooth Sports Headband Headphones with Ultra-Thin HD Stereo Speakers Perfect for Sleeping,Workout,Jogging,Yoga,Insomnia, Air Travel, Meditation, Grey",
itemPrice: "$15.99",
},
{
itemName:
"Soundcore Anker Life Q20 Hybrid Active Noise Cancelling Headphones, Wireless Over Ear Bluetooth Headphones, 40H Playtime, Hi-Res Audio, Deep Bass, Memory Foam Ear Cups, for Travel, Home Office",
itemPrice: "$59.00",
},
{
itemName:
"Beats Studio3 Wireless Noise Cancelling Over-Ear Headphones - Apple W1 Headphone Chip, Class 1 Bluetooth, 22 Hours of Listening Time, Built-in Microphone - Defiant Black-Red (Latest Model)",
itemPrice: "$238.99",
},
// ...
];
Now that you have a working, reliable script for scraping pricing data from the Amazon bestsellers list for your niche, you can run this periodically, perhaps via a cron job, writing data over time to a database - or however you wish to store it.
Once you have a working, reliable store of pricing data, you can adjust prices for your own products accordingly, offering price match guarantees to your consumers, or just price yourself lower when Amazon has it in stock - raising prices slightly when they don't.
It's a delicate balancing act, but having this data at your disposal enables you to use dynamic pricing strategies and match up with heavyweights in the e-commerce industry.
Conclusion
Web scraping offers e-commerce companies significant benefits for dynamic pricing strategies, including real-time market insights, competitor analysis, demand analysis, price optimization, and product availability monitoring. However, it also comes with challenges to overcome in even getting the data to begin with - anti-scraping measures, rate limiting, and legal concerns.
Bright Data's Scraping Browser provides a comprehensive solution to overcome these challenges. With its robust proxy network and unlocker infrastructure, it efficiently bypasses anti-bot techniques and automates IP rotation. It ensures ethical compliance, offers 24x7 support, and scales seamlessly for large-scale data extraction.
And all without any infrastructure required on your part, or third-party libraries to maintain. One websocket connection is all you need to integrate it into your existing workflow, and reap the benefits.
By leveraging the Scraping Browser, your e-commerce business can implement dynamic pricing with confidence, and gain a competitive edge in the rapidly changing online marketplace.
👉 Sign up today and start experiencing the power of Bright Data's Scraping Browser.
Comments
Loading comments…