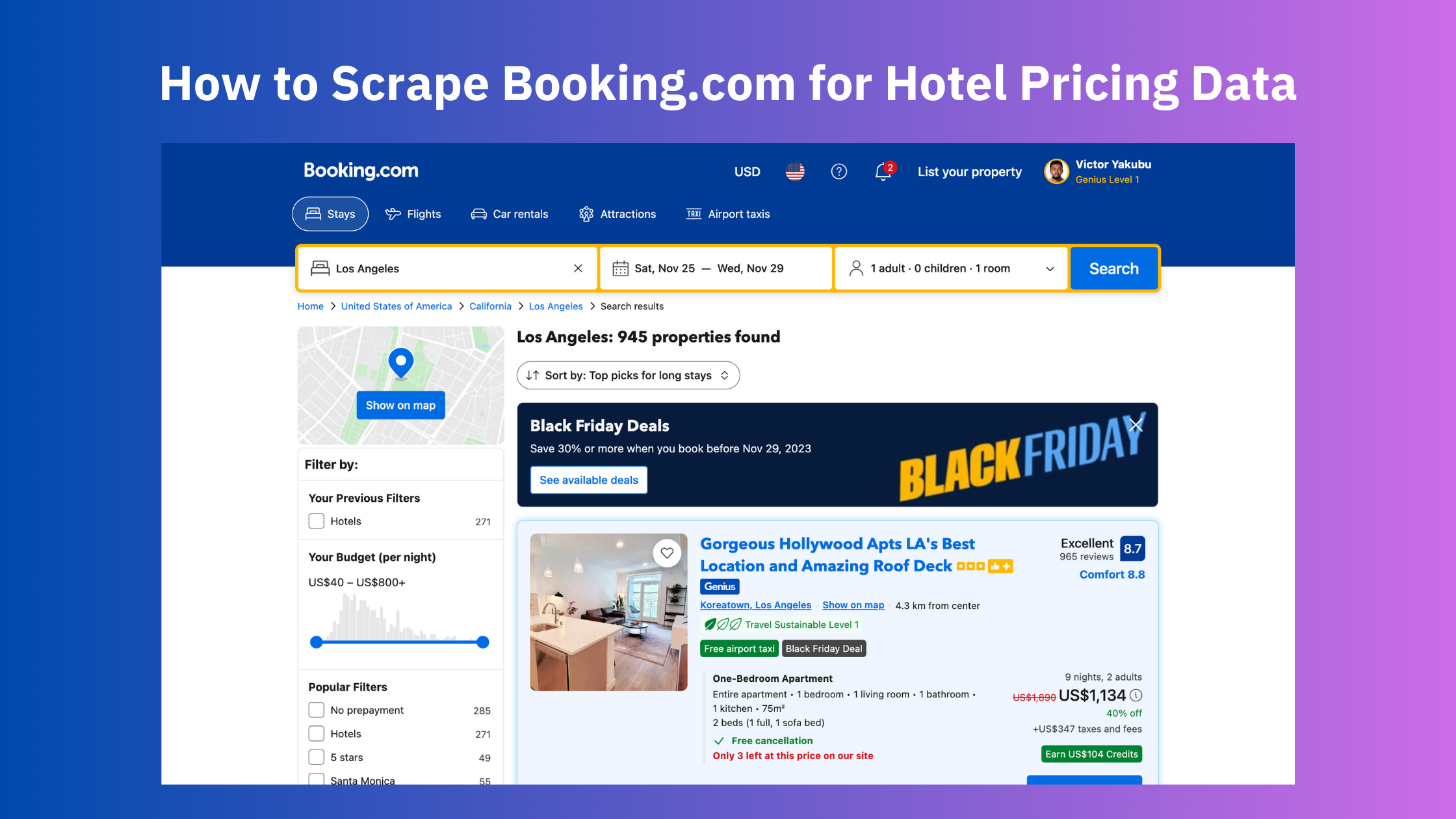
From capturing real-time data to extracting valuable data-driven insights, web scraping has evolved into an essential tool across diverse industries, for a myriad of use cases. The hotel industry is one industry where data collection can help provide crucial insights into an ever-evolving market landscape. By comprehensively collecting and analyzing publicly available hotel and tourism data, including hotel listings, prices, ratings, reviews, pictures, addresses, and more, you can understand market dynamics and maintain a competitive edge.
For this article, we’ll be looking at Booking.com. As a leading global online travel agency, Booking.com provides a wealth of hotel information, including their prices, availability, and customer reviews. This data can be invaluable for your business to:
- Understand market dynamics, such as changing demand patterns and more.
- Optimize room rates.
- Make informed pricing decisions.
- Identify emerging trends in customer preferences.
- Analyze customer reviews to identify areas that could use improvement.
In this article, we will look at how to scrape hotel pricing data from Booking.com using Node.js and Puppeteer. We’ll go through the entire setup, the scraping process and finally look at the result.
However, scraping data at scale from Booking.com is not a straightforward task as it makes use of blocks and other measures that can disrupt the seamlessness of your scraping process. Such blocks can include IP throttling, CAPTCHAs, having to deal with dynamic content, handling cookies and sessions, and more. To get around this and ensure that our scraping process remains unblocked, we will be integrating our Puppeteer script with the Scraping Browser — a fully GUI headless browser that comes with bot-bypassing technology right out of the box — with our Puppeteer script. Scraping Browser — Build Unblockable Scrapers with Puppeteer, Playwright and Selenium
Before we dive into the tutorial and the technical details, let’s first take a minute to understand some of these challenges in greater detail.
Challenges of Scraping Booking.com
Scraping Booking.com presents several challenges due to its dynamic nature and sophisticated anti-scraping measures. Some of these challenges include but are not limited to the following:
- Evading IP Blocks, Rate Limits, and CAPTCHAs: Booking.com, a behemoth in the online travel industry, employs sophisticated anti-scraping mechanisms to protect its data. These can include limiting your rate of access to the site or using browser fingerprints to block your IP or throwing up CAPTCHAs. Conventional scraping methods often struggle to bypass these defenses, often requiring the use of third-party proxies and additional infrastructure. Navigating through Booking.com’s defensive barriers requires a strategic approach to avoid disruption and ensure seamless data extraction.
- Dynamic Website Structure: The dynamic nature of Booking.com’s website poses a formidable challenge for conventional scraping techniques. The structure of the site frequently evolves, with elements such as pricing information and hotel details being loaded dynamically through JavaScript. Traditional scraping tools may falter in capturing this dynamic data, resulting in incomplete or inaccurate information.
- Handling Cookies and Sessions: As mentioned earlier, handling cookies and sessions can be a significant challenge. Booking.com uses cookies to manage sessions and track user interactions. If not handled properly, this can lead to inaccurate data retrieval or even get your IP address blocked.
- Pricing Data: Booking.com’s hotel pages do not contain pricing in the HTML data. Instead, additional requests are required to retrieve pricing calendar data. This adds an extra layer of complexity to the scraping process, requiring user interaction.
- Legal and Ethical Considerations: Scraping data from Booking.com raises legal and ethical considerations. The terms of service of many websites, including Booking.com, explicitly prohibit unauthorized data extraction. Conventional methods may inadvertently violate these terms, exposing businesses to legal risks and tarnishing their reputation. Navigating this legal landscape requires a solution that ensures compliance with ethical standards.
These are some of the challenges you are likely to face when scraping Booking.com. To bypass this, we generally make use of headless Browsers like Puppeteer/Playwright/Selenium but even these aren’t always foolproof and may still require reliance on third-party libraries. However, as we’ll see, Bright Data’s Scraping Browser can take care of all these challenges and more.
In the next section, we’ll be looking at what makes the Scraping Browser a great choice to integrate with your Puppeteer script to seamlessly scrape Booking.com data.
Tools and Setup
Bright Data’s Scraping Browser is a comprehensive web scraping solution that combines the convenience of a real, automated browser with Bright Data’s powerful unlocker infrastructure and proxy management services. It’s also fully compatible with Puppeteer/Playwright/Selenium APIs.
To set up and use the Scraping Browser is simple:
- Before you write any scraping code, you use Puppeteer/Playwright/Selenium to connect to Bright Data’s Scraping Browser using your credentials, via Websockets.
- From then on, all you have to worry about is developing your scraper using the standard Puppeteer/Playwright/Selenium libraries, and nothing more.
Learn more: Scraping Browser — Build Unblockable Scrapers with Puppeteer, Playwright and Selenium
Since the Scraping Browser also comes with the convenience of a real fully GUI browser, meaning that it can parse all JavaScript and XHR requests on a page, giving you the dynamic data you need.
But it also eliminates the need for you to handle numerous third-party libraries that deal with tasks such as proxy and fingerprint management, IP rotation, automated retries, logging, or CAPTCHA solving internally. The Scraping Browser takes care of all this and more on Bright Data’s server-side infrastructure.
How is it able to do this? This is because the Scraping Browser comes in-built with Bright Data’s powerful unlocker infrastructure and proxy network, which means it arrives with block-bypassing technology right out of the box, no additional measures are needed on your part.
The un-locker technology automatically configures relevant header information (such as User-Agent strings) and manages cookies according to the requirements of the target website so that you can avoid getting detected and blocked as a “crawler”. Meanwhile, Bright Data’s proxy management services allow you to automate IP rotation between four different kinds of proxy services.
💡Note: From CAPTCHA-solving to User-agent generation to cookie management and fingerprint emulation, Bright Data’s unlocker infrastructure can bypass even the most sophisticated anti-scraping measures. Learn more here.
Bright Data’s unlocker infrastructure Is a managed service, meaning that you don’t have to worry about updating your code to keep up with a website’s ever-changing CAPTCHA-generation mechanisms. Bright Data takes care of all of that for you, handling the updates and maintenance on their end.
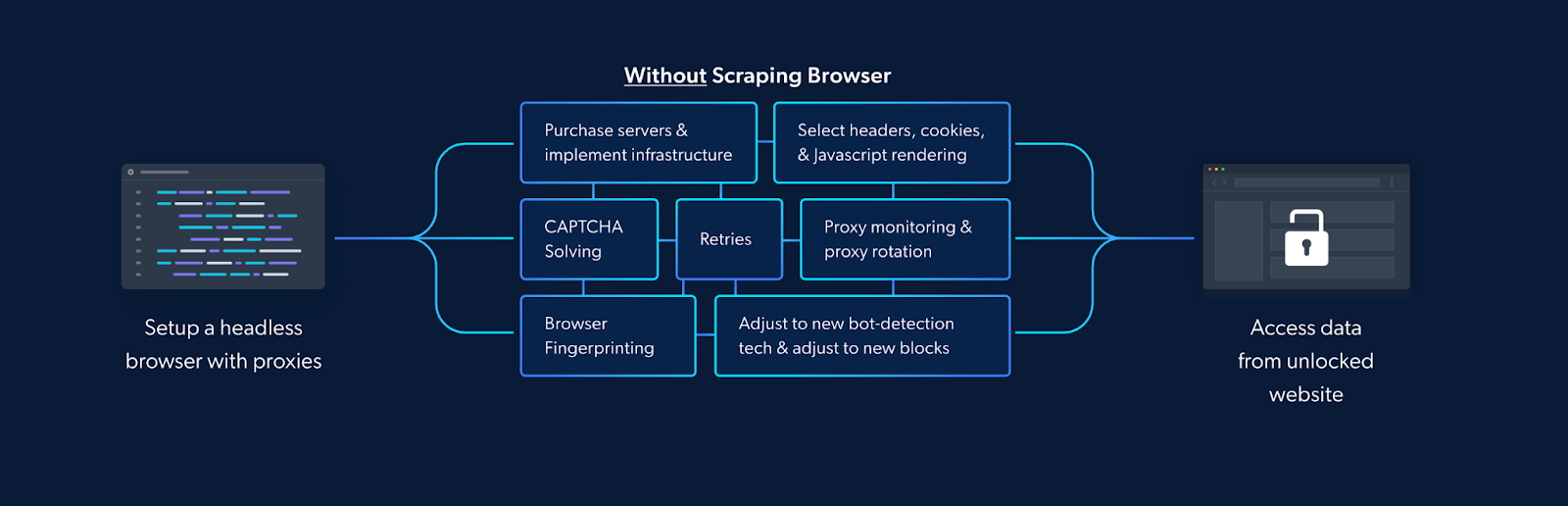
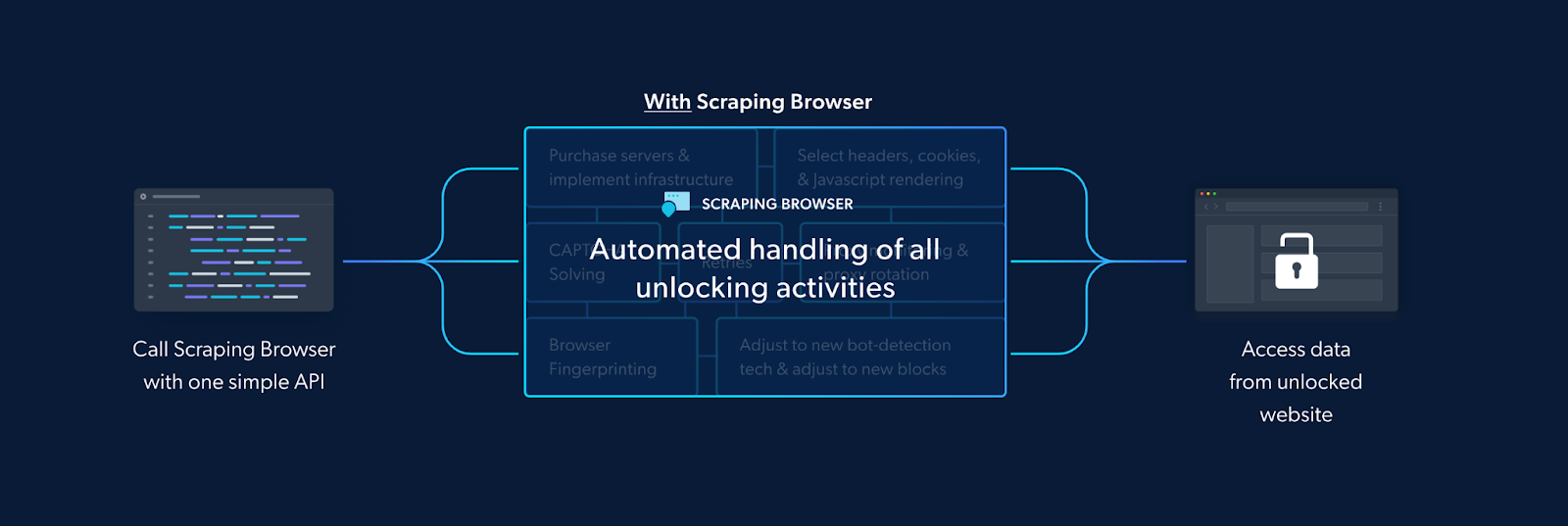
All this ensures that the Scraping Browser easily overcomes the challenges we mentioned earlier. In addition to that, it is highly scalable, allowing you to scale unlimited sessions using a simple browser API, saving infrastructure costs. This is particularly beneficial when you need to open as many Scraping Browsers as you need without an expansive in-house infrastructure.
With all that said, let’s now dive into setting up the Scraping Browser and our Puppeteer script and scrape Booking.com.
Getting Started with the Scraping Browser
The goal here is to create a new proxy with a username and password, which will be required in our code. You can do that by following these steps:
- Signing up — go to Bright Data’s homepage and click on “Start Free Trial”. If you already have an account with Bright Data, you can just log in.
- Once you sign in after entering your details and finishing the signup process, you will be redirected to a welcome page. There, click on “View Proxy Products”.
- You will be taken to the “Proxies & Scraping Infrastructure” page. Under “My proxies,” click on “Get started“ in the Scraping Browser card.
If you already have an active proxy, just click on “Add” and select “Scraping Browser.”
- Next, you will be taken to the “Add new proxy solution” page, where you will be required to choose a name for your new scraping browser proxy zone. After that, click on “Add”.
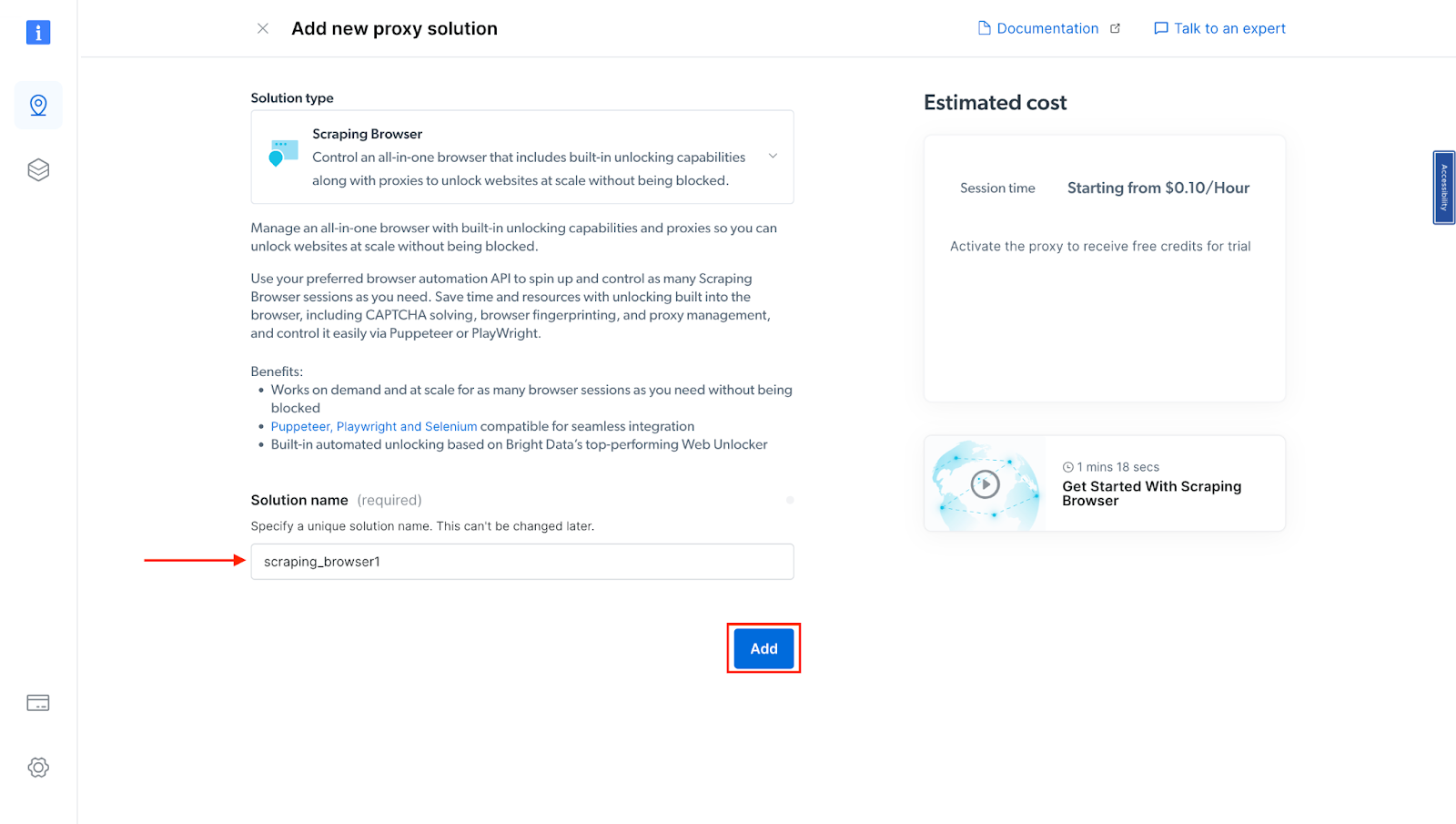
- At this point, if you haven’t yet added a payment method, you’ll be prompted to add one to verify your account. As a new user of Bright Data, you’ll receive a $5 bonus credit to get you started.
NB: This is mainly for verification purposes, and you will not be charged at this point
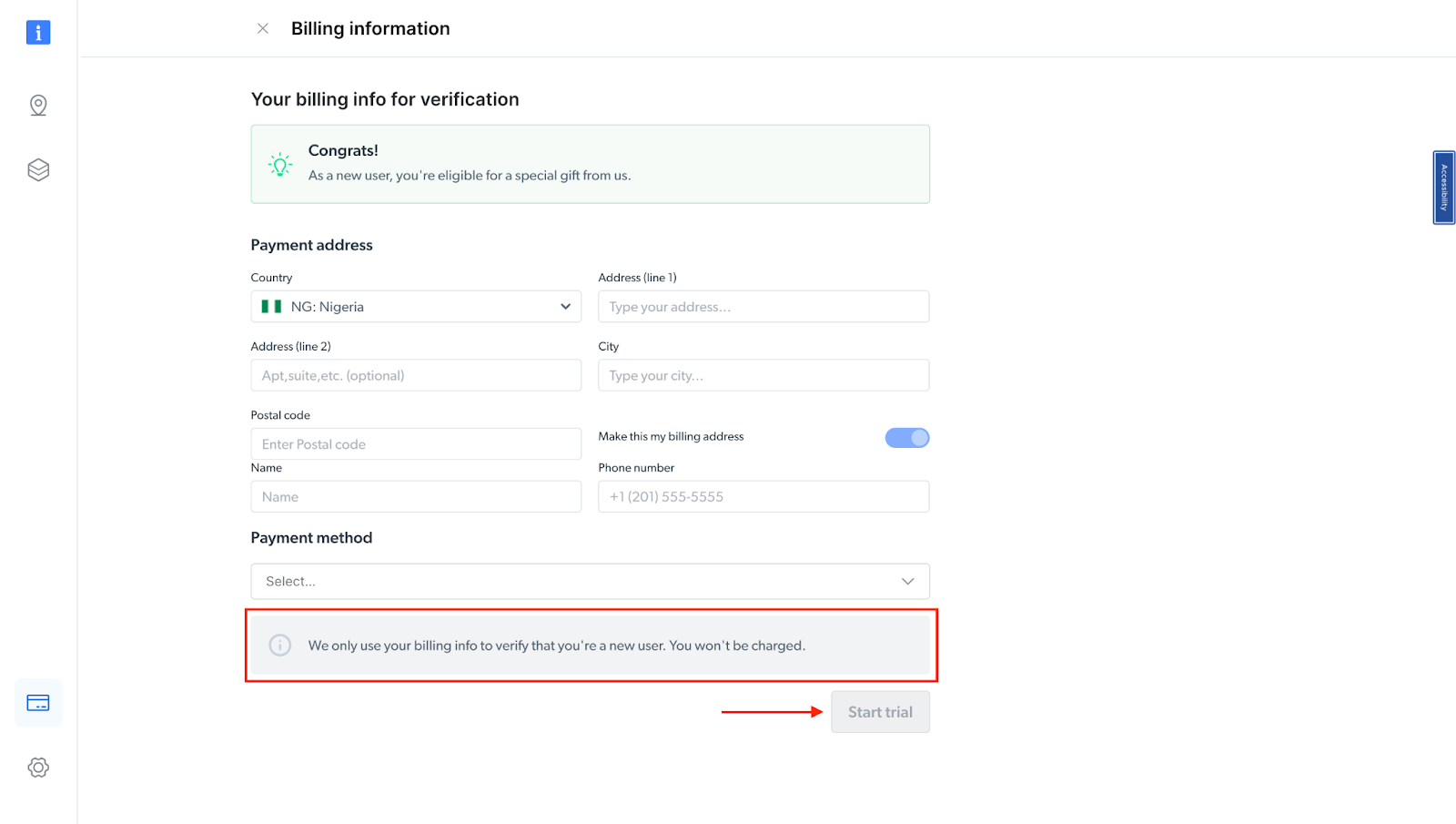
- After verifying your account, your proxy zone will be created.
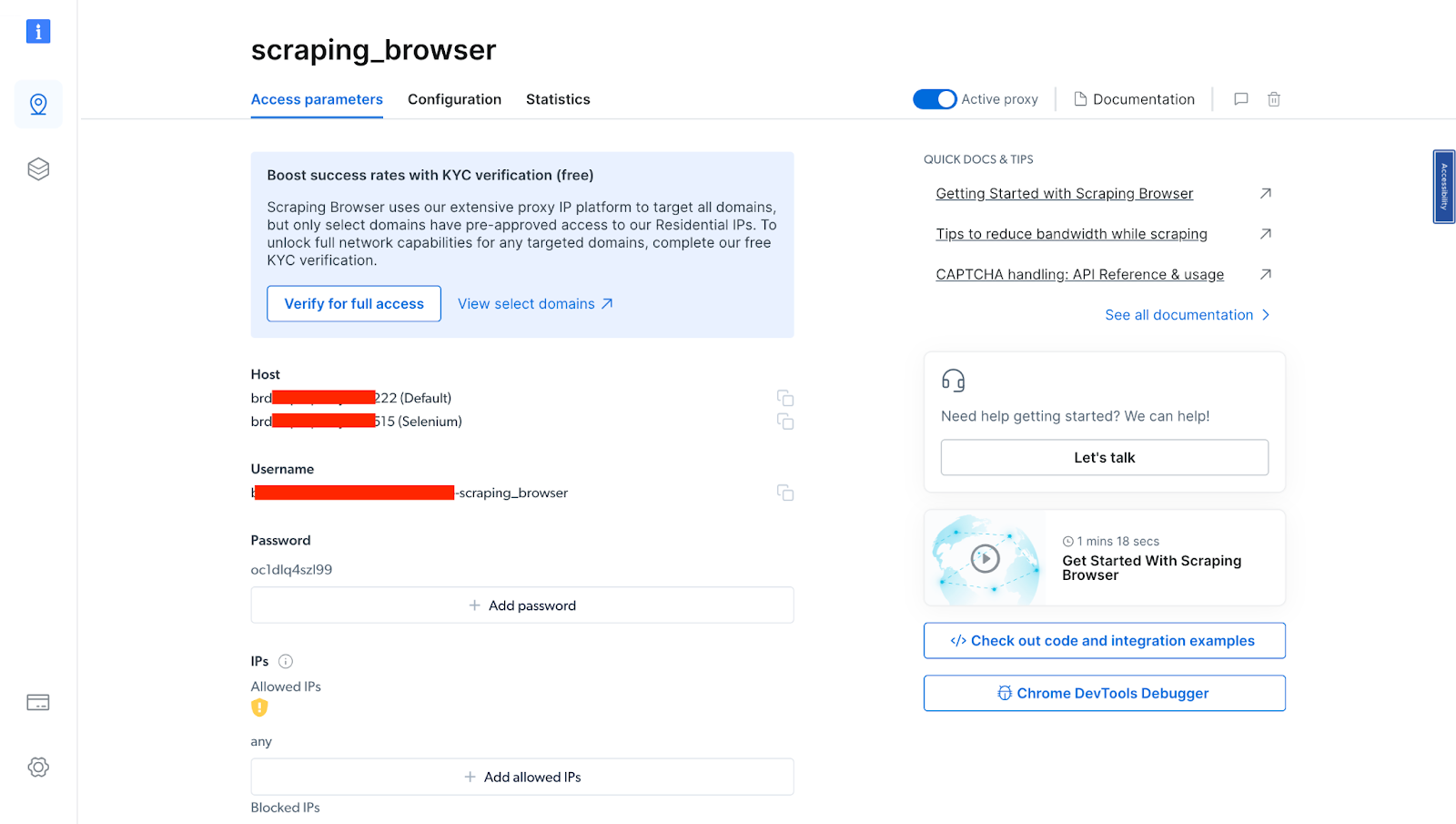
You will need these details in your code in the next section. So you either copy them down or leave the tab open.
How to Scrape Booking.com: A Step-By-Step Guide
Scraping Booking.com for hotel pricing data can be achieved using various methods. However, in this example, we will use JavaScript with Puppeteer, along with the Scraping Browser tool from Bright Data, to simplify the process.
- Create a new folder/directory and open it using your preferred code editor.
- Initialize it with NPM using the command below. (You will need NPM and Node.js installed to run this command).
npm init -y
Install Puppeteer using the command below
npm i puppeteer-core
Go to Booking.com and get the URL for your search query
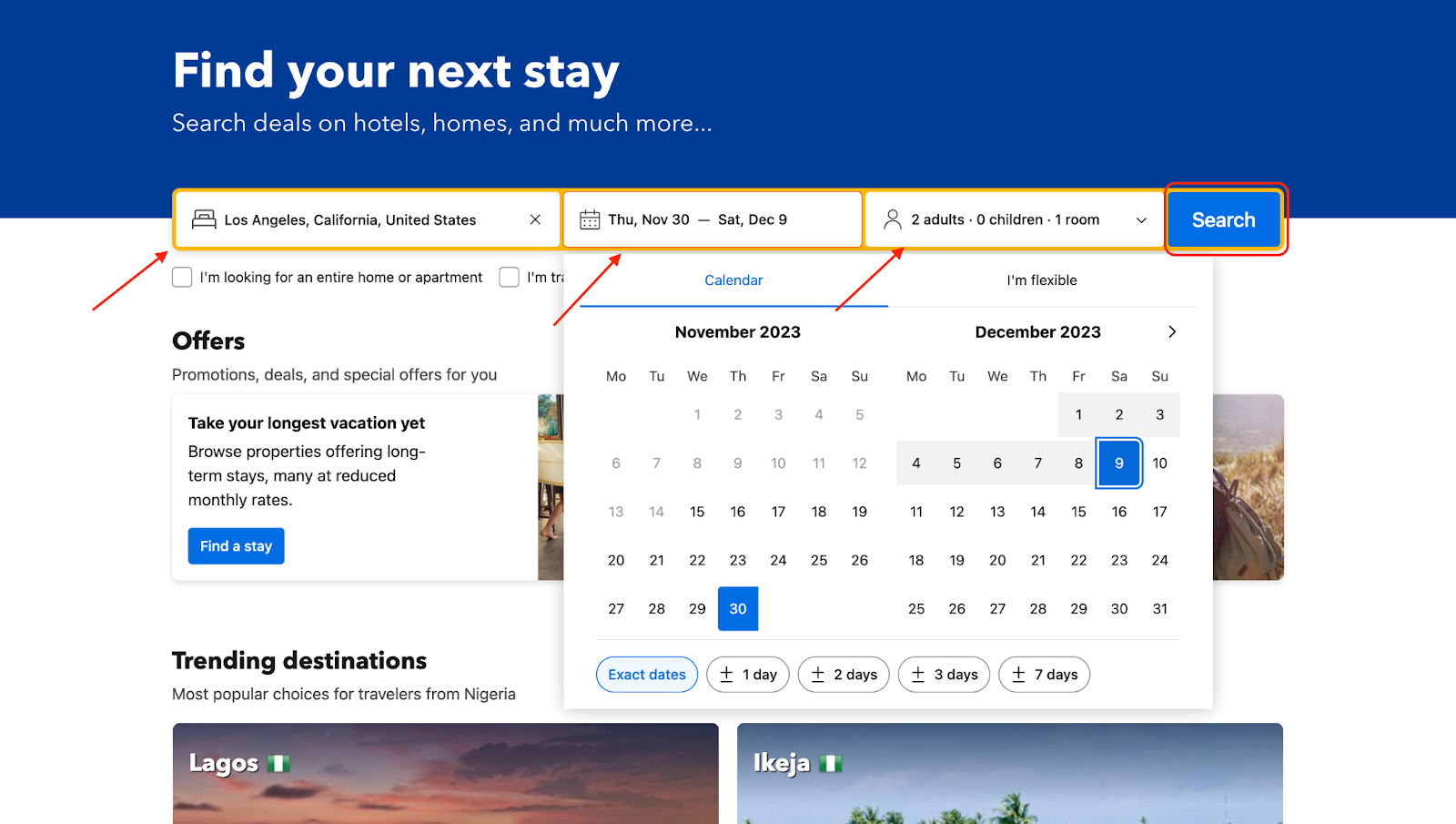
After inputting your search queries, click on “search”, you will then see a list of hotels, according to your queries.
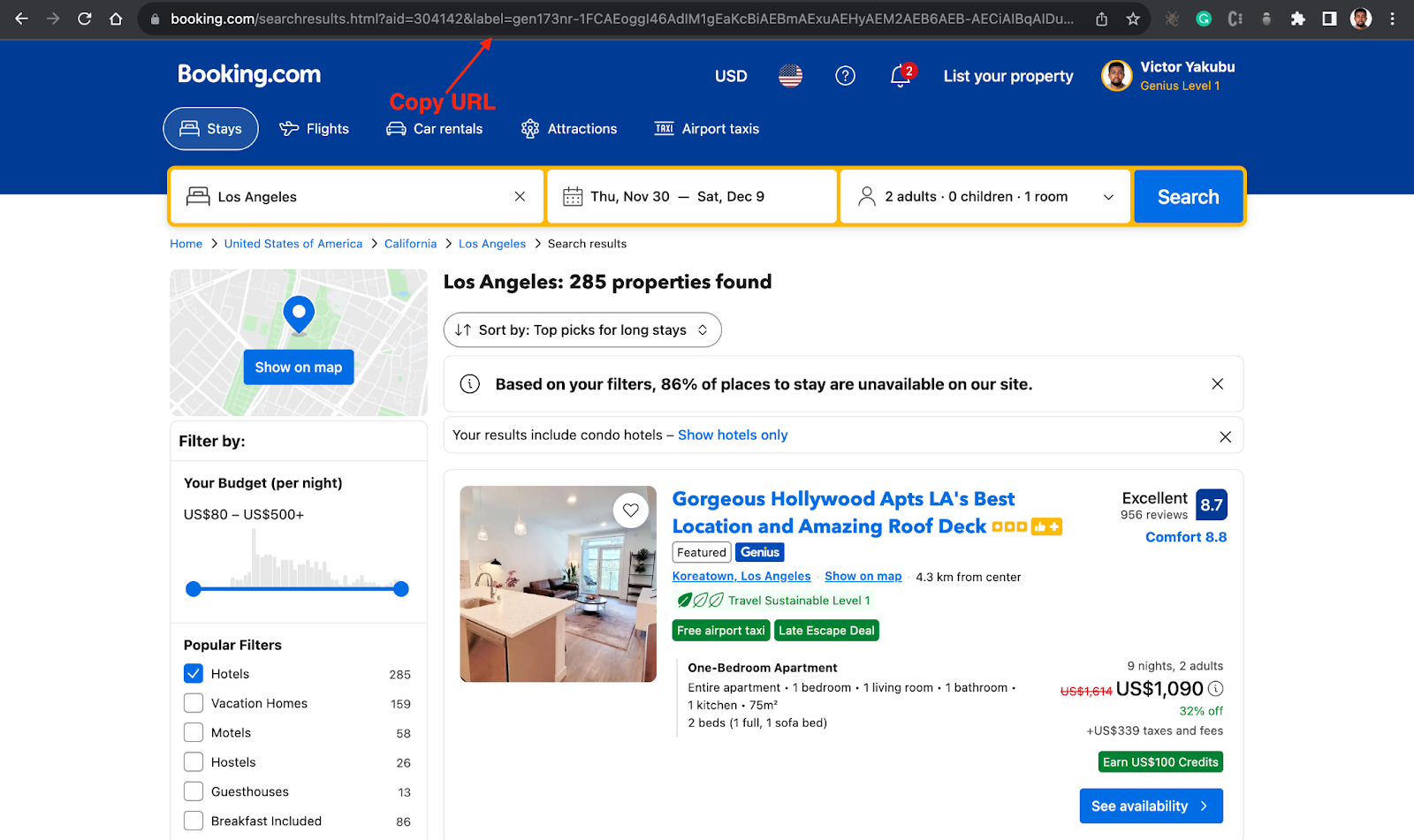
- Copy the URL of your search queries, you will need this in your code.
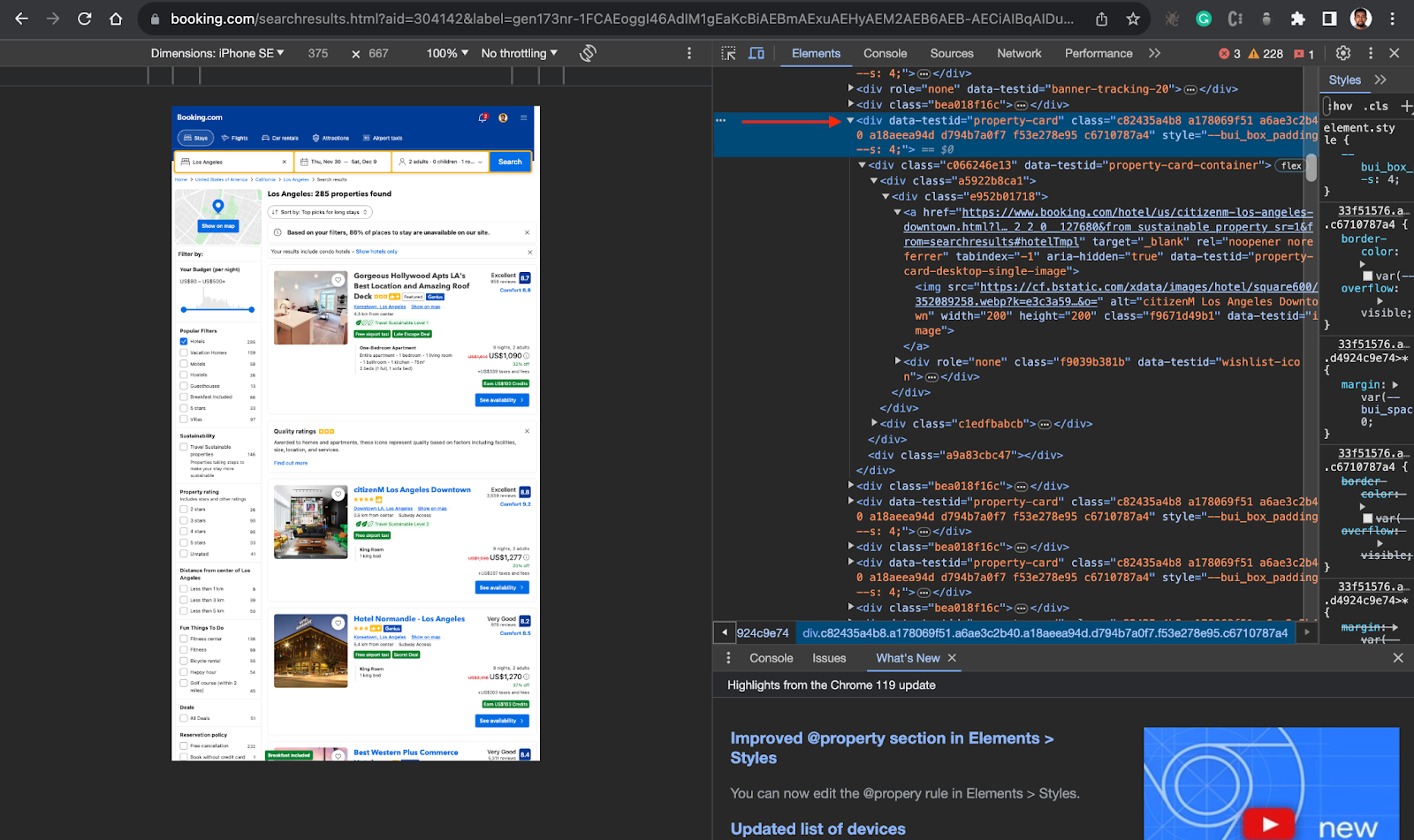
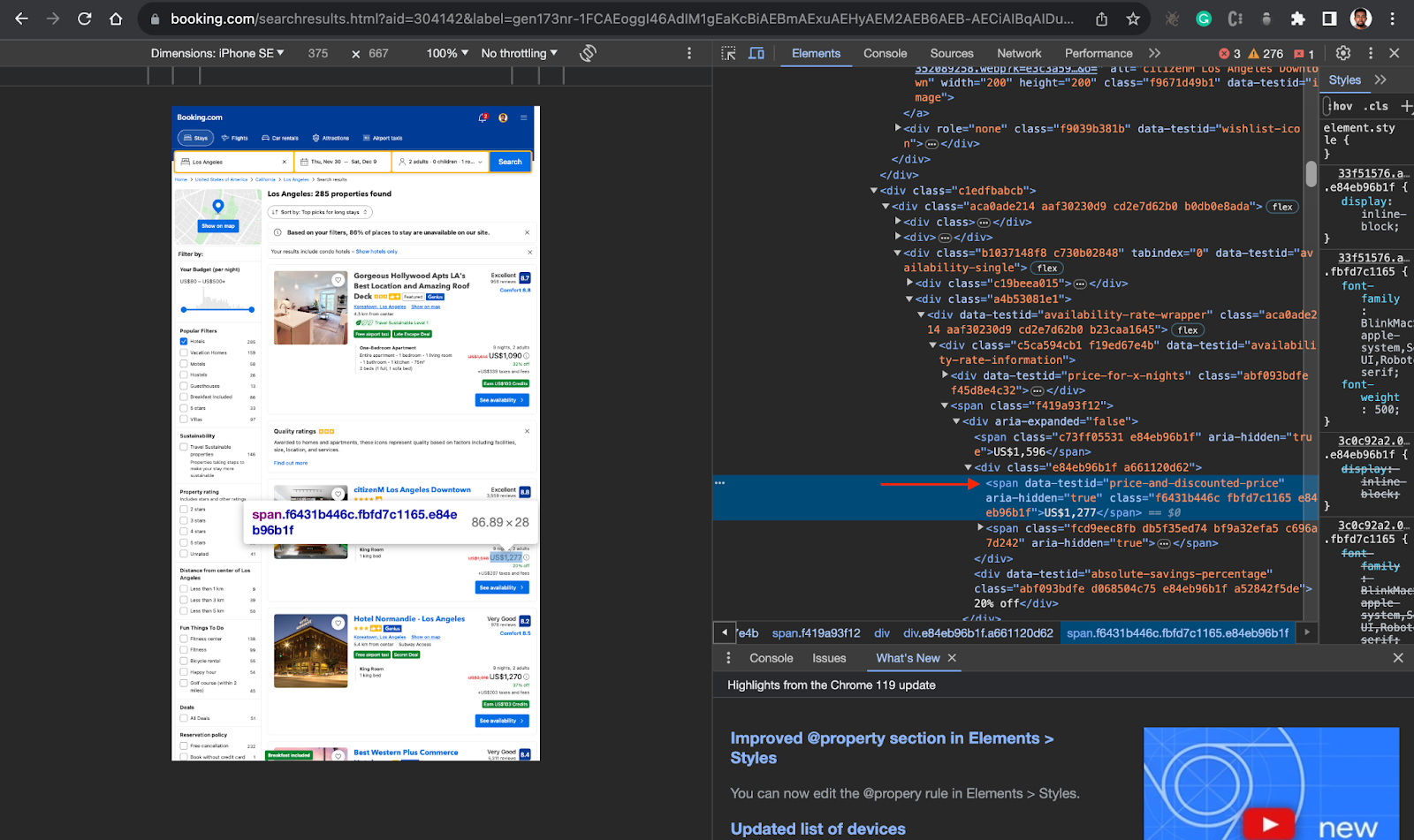
- Inspect the result page, to be able to target the right div or container, in this case, you will first target the parent
divelement for each hotel card which isdata-testid=”property-card”from the screenshot below.
- Inside the parent div, you can now locate the div or container holding the information you need, in this case, you need the hotel name/title(
data-testid=”title”), Price (data-testid=”price-and-discounted-price”), and review score (data-testid=”review-score”). See the screenshots below.
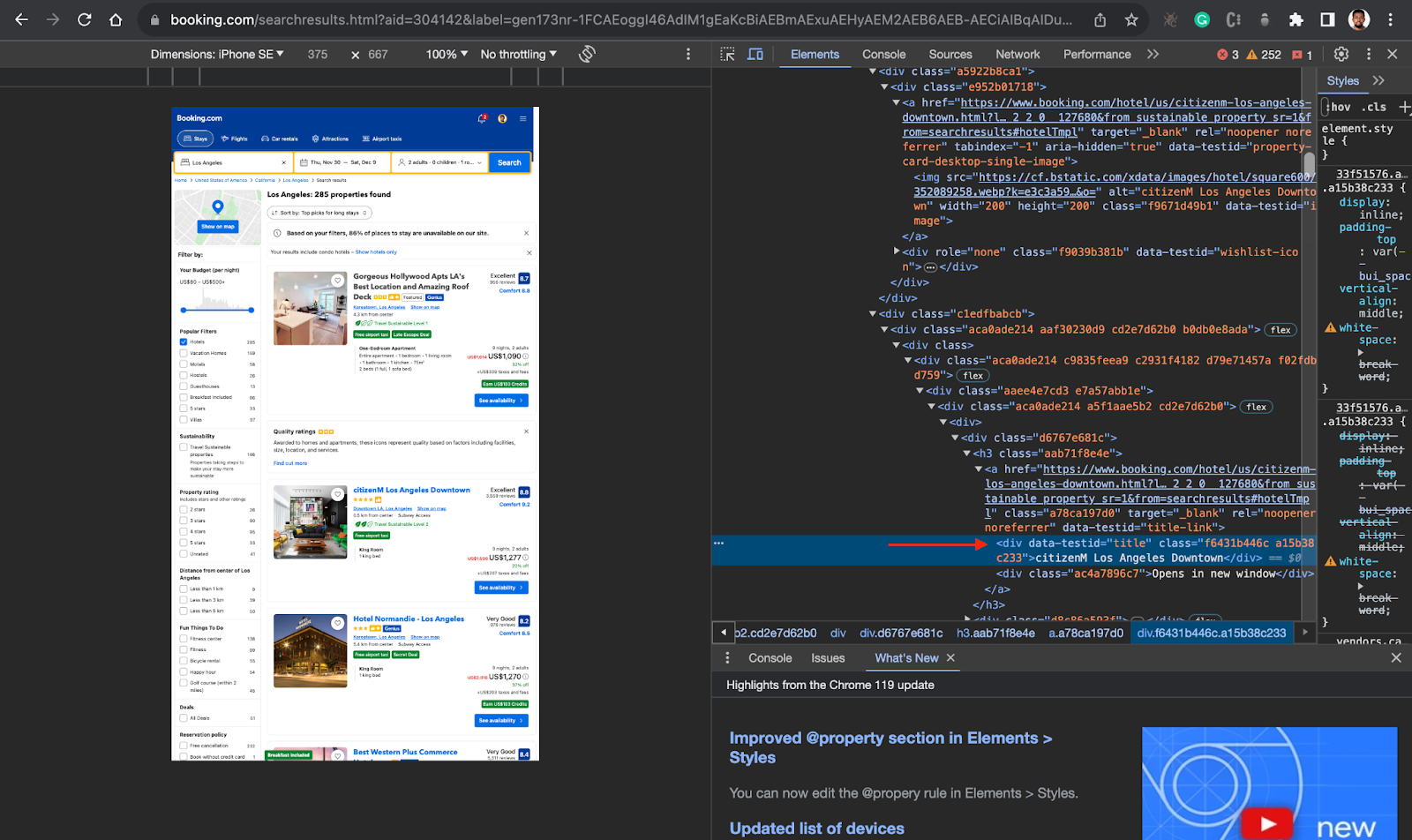
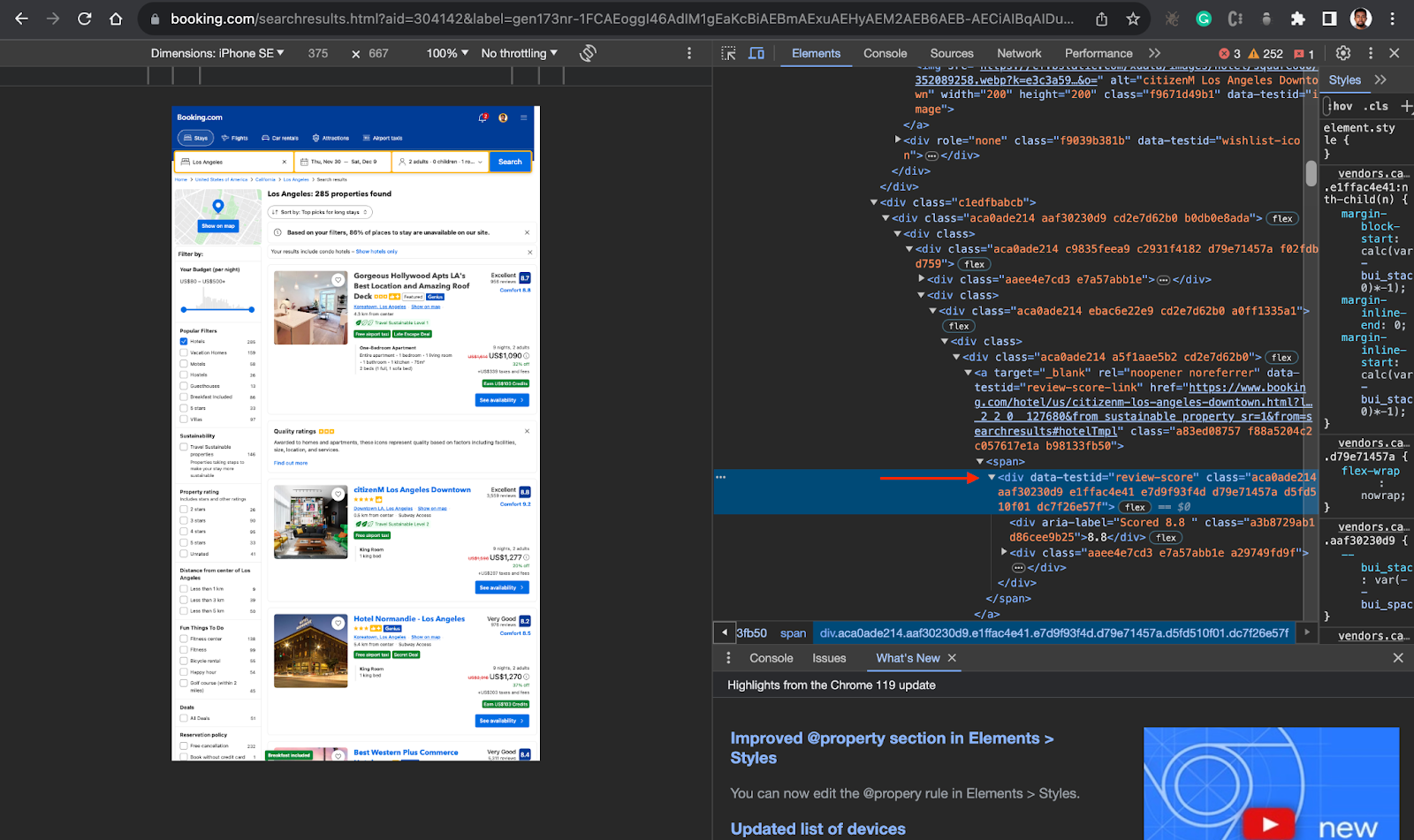
Now that you have this information, you can proceed to your code.
- Create a new file inside the project folder called script.js and implement the code below.
const puppeteer = require("puppeteer-core");
const fs = require("fs");
const auth = "<your username>:<your password>";
async function run() {
let browser;
try {
browser = await puppeteer.connect({
browserWSEndpoint: `wss://${auth}@zproxy.lum-superproxy.io:9222`,
});
const page = await browser.newPage();
page.setDefaultNavigationTimeout(2 * 60 * 1000);
// IMPORTANT: Change dates to future dates, otherwise it won't work
const checkinDate = "2023-11-30";
const checkoutDate = "2023-12-09";
await page.goto(
`https://www.booking.com/searchresults.html?aid=304142&label=gen173nr-1FCAEoggI46AdIM1gEaKcBiAEBmAExuAEHyAEM2AEB6AEB-AECiAIBqAIDuALK69aqBsACAdICJGIyNTBjMTkyLWVjOGQtNDZhOC1iMzExLWM4MmYzZTNiYzlhNdgCBeACAQ&checkin=${checkinDate}&checkout=${checkoutDate}&dest_id=20014181&dest_type=city&nflt=ht_id%3D204&group_adults=0&req_adults=0&no_rooms=0&group_children=0&req_children=0`
);
await new Promise((r) => setTimeout(r, 5000));
// Extract hotel data
const hotels = await page.$$('div[data-testid="property-card"]');
console.log(`There are: ${hotels.length} hotels.`);
const hotelsList = [];
for (const hotel of hotels) {
const hotelDict = {};
hotelDict["hotel"] = await hotel.$eval(
'div[data-testid="title"]',
(el) => el.innerText
);
hotelDict["price"] = await hotel.$eval(
'span[data-testid="price-and-discounted-price"]',
(el) => el.innerText
);
hotelDict["score"] = await hotel.$eval(
'div[data-testid="review-score"] > div:nth-child(1)',
(el) => el.innerText
);
hotelsList.push(hotelDict);
}
const csvData = hotelsList
.map((hotel) => Object.values(hotel).join(","))
.join("\n");
fs.writeFileSync("hotels_list.csv", csvData);
} catch (e) {
console.error("run failed", e);
} finally {
if (browser) {
await browser.close();
}
}
}
if (require.main == module) (async () => await run())();
Here is a breakdown of what the script does:
- Imports necessary libraries: The script starts by importing the necessary libraries. It uses
puppeteer-core, andfsto interact with the file system. - Defines authentication details: It defines a constant
auththat holds the username and password for the scraping browser. Replace<your username>:<your password>with your own scraping browser details - Connects to the browser: The
runfunction is defined as an asynchronous function. Inside this function, it connects to a browser instance using Puppeteer’sconnectmethod. ThebrowserWSEndpointoption is set to a WebSocket URL, which includes the authentication details and the address of the proxy service. - Browser and Page Setup:
const page = await browser.newPage():After connecting to the browser, it opens a new page in the browser.page.setDefaultNavigationTimeout(2 * 60 * 1000);and a default navigation timeout of 2 minutes is set - Page Navigation: The script navigates to a specific Booking.com search results page, providing check-in and check-out dates as well as other parameters in the URL.
const checkinDate = "2023–11–30";
const checkoutDate = "2023–12–09";
await page.goto(
`https://www.booking.com/searchresults.html?...&checkin=${checkinDate}&checkout=${checkoutDate}&...`
);
- Extracts hotel data: The script then extracts hotel data from the page. It selects all elements with a
data-testidattribute of“property-card”, which represents hotel listings. For each hotel, it extracts the hotel name, price, and score. - Saves data to a CSV file: The extracted data is then saved to a CSV file(hotels_list) using Node.js’s
fsmodule, the file will be located inside the project folder. - Closes the browser: Finally, the script ensures that the browser is closed, even if an error occurs during the execution of the script.
The extracted data can be opened using Excel. See the output data:
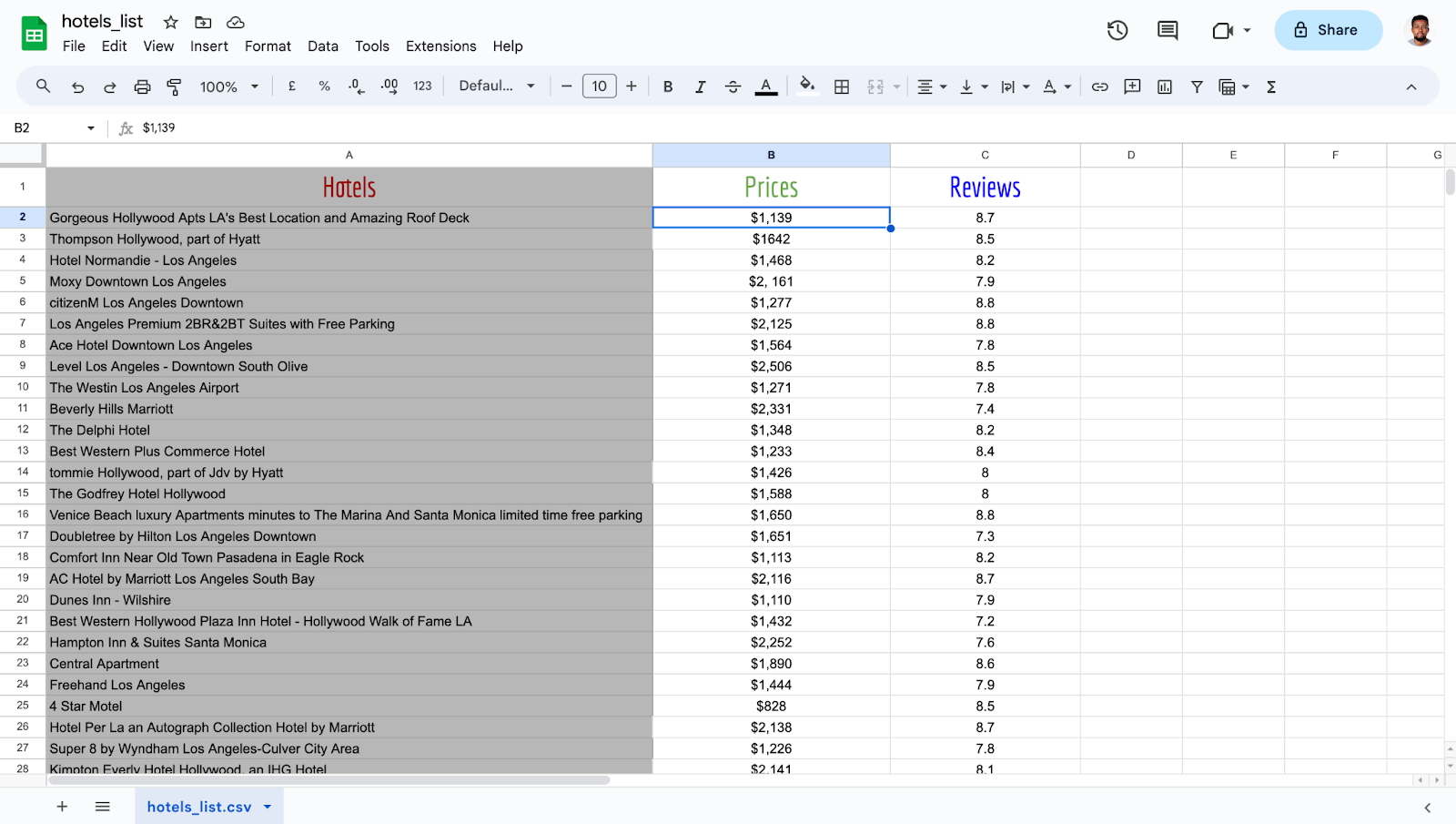
The extracted dataset in the image above provides a structured overview of hotel pricing data obtained from Booking.com. Each row in the dataset represents information about a specific hotel, including:
- Hotel Name: The name of the hotel.
- Location: The city or area where the hotel is situated.
- Price: The cost associated with staying at the hotel for the duration.
So depending on your needs, you might want to extract more data, handle more complex situations, or use more advanced techniques. This is just an example to show that with the right tools, the process of scraping websites shouldn’t be that complicated.
Conclusion
Scraping hotel pricing data from Booking.com opens up a world of possibilities. With this data, businesses can gain insights into market dynamics, optimize room rates and packages, and make informed pricing decisions. By understanding trends and patterns in demand, businesses can adjust their pricing accordingly to maximize revenue and occupancy.
For instance, a hotel might use hotel price data to identify periods of high demand and set higher prices, or to identify periods of low demand and offer promotions or discounts. This style of hotel pricing monitoring can help hotels maximize revenue and occupancy.
Moreover, the pricing landscape in the hotel industry is in a state of constant flux, influenced by factors such as seasonality, local events, and competitor pricing strategies. By monitoring hotel prices, businesses can glean insights into these market dynamics, which in turn, enables them to adjust their pricing strategies accordingly.
In this article, we have explored how to scrape hotel pricing data from Booking.com using the Scraping Browser tool from Bright Data. This tool simplifies the process by handling complexities such as dynamic content, cookies, and sessions, and bypassing anti-scraping measures.
The Scraping Browser tool from Bright Data is an ideal solution for such tasks. It is designed to handle dynamic content, manage cookies and sessions effectively, and bypass anti-scraping measures. It provides a more streamlined and efficient way to scrape data from such websites, allowing businesses to gather the data they need without getting blocked or dealing with inaccurate data.
If you’re interested in learning more about how the Scraping Browser tool from Bright Data can help you with your web scraping tasks, you can sign up for a free trial and explore what the Scraping Browser has to offer.
Comments
Loading comments…