
Photo by Igor Miske on Unsplash
In this article, you'll learn how to scrape an eCommerce using the Python programming language. You will also learn how to avoid getting blocked from scraping data from sophisticated eCommerce websites.
Web scraping is the process of extracting data from websites or APIs for different uses, including research, analysis or the creation of a data bank.
With an increasing demand for data by businesses, there has also been the need to extract data at scale via web scraping. This has become important for businesses and individuals these days because most of the data needed by them is mostly available and generated online.
However, the process of extracting this data is not without its quirks and hurdles. There are several challenges one will face when scraping the web such as IP blocking, honeypot traps, bot access, solving CAPTCHAs etc.
These are issues you'll encounter when scraping large data from secured and sophisticated websites. To overcome these, you'll learn how to make use of Bright Data's Scraping Browser, a headful Puppeteer/Playwright/Selenium-compatible fully GUI browser that comes with bot and CAPTCHA-bypassing technology right out of the box.
But first, let's learn about some of the challenges when you try to scrape with just regular Python libraries.
Challenges of Web Scraping with Python Libraries and Headless Browsers
If you're scraping out little data from a simple website, using Python and some web scraping libraries would suffice. However, when scraping for large-scale data from sophisticated websites and platforms, you will begin to experience some of the aforementioned challenges when you use Python and other stopgap solutions.
Let's consider some of these challenges faced during web scraping in more detail:
1. Solving CAPTCHAs:
CAPTCHA (Completely Automated Public Turing test to tell Computers and Humans Apart) is used by many websites to differentiate bot activities from that of real humans. CAPTCHAs comprise simple quizzes or logical puzzles that humans can solve. If an incoming request is suspicious, a CAPTCHA is presented and when solved the request is directed to the right page.
If you're scraping mostly with Python, this will pose a bit of a challenge for you, because the programming language in itself cannot solve CAPTCHAs. There are software solutions that help with solving CAPTCHAs, however, this might generally slow down the speed at which you scrape data from websites.
2. IP Blocking:
One way website owners limit web scraping on their sites is by implementing IP blocking. Usually, when a web server is hit with a high volume of requests from a particular IP address if an IP blocking security feature is implemented on that website, that IP address gets blocked from accessing it.
Your web scraping activity can be cut short if your IP address is blocked. Currently, there are IP proxy services that can be integrated into your web scraping bot to prevent getting blocked.
3. Honeypot Traps:
Honeypot traps are used by website owners to minimize unauthorized scraping of their sites. When a scraper bot follows a honeypot trap, details about it like the IP address are exposed which can be used to block it.
Honeypot traps are not visible to the human eye but can be accessible by a bot or web scraper. This is another pitfall associated with unauthorized and aggressive web scraping.
The above-listed challenges are some of the several hurdles you'll have to deal with when you embark on scraping large-scale data on sophisticated websites.
Scraping large-scale data has become a lot less challenging since I discovered Bright Data's powerful all-in-one Scraping Browser. The browser API can bypass CAPTCHA solving, IP blocking, and retries experienced when scraping data.
-> Scraping Browser - Automated Browser for Scraping
How to Scrape an eCommerce Site with Bright Data's Scraping Browser and Playwright
The Scraping Browser is compatible with existing data scraping tools like Selenium, Playwright and Puppeteer. Here, we will integrate it with Playwright to scrape a product category on eBay.
Scraping eBay Using Bright Data's Scraping Browser and Playwright
- The first step is to sign up for a Bright Data account. Click on 'Start free trial' and enter your details --- they offer a free trial to get you started.
- Once you have signed up, visit the dashboard, and navigate to the "My Proxies" page to set up your Scraping Browser.
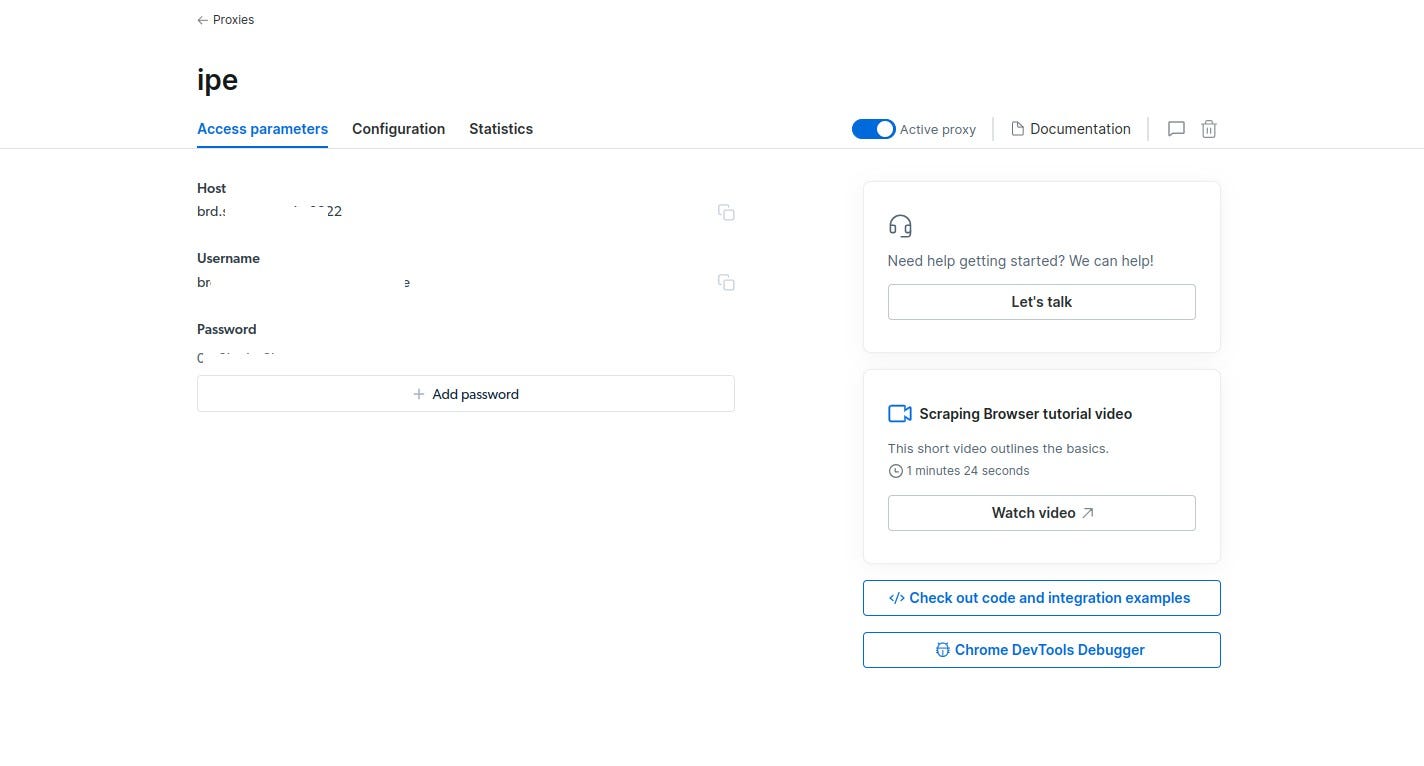
- Navigate to your Scraping Browser's "Access parameters" page which has your Host, Username and Password details.
- Create a file
scraper.pyin your IDE. This file would contain the script for the web scraping project with Bright Data's Scraper Browser and Playwright. - Run the following command on your IDE console to install Playwright for your project.
pip3 install playwright
As earlier mentioned, we would be scraping eBay's "Cell Phones and Smartphones" category for the following data; device name, present condition, price, review and shipping fee.
Let's see what the code snippet for this project would look like using Bright Data's Scraping Browser and Playwright:
import asyncio
from playwright.async_api import async_playwright
auth = 'brd-customer-hl_0ec80c63-zone-web_scraping_browser:7pw3h1e4q05d'
browser_url = f'wss://${auth}@brd.superproxy.io:9222'
product_data = []
async def main():
async with async_playwright() as pw:
print('connecting')
browser = await pw.chromium.connect_over_cdp(browser_url)
print('connected')
page = await browser.new_page()
print('goto')
await page.goto('https://shorturl.at/qxBDN', timeout=120000)
products = await page.locator('li.s-item.s-item**pl-on-bottom').all()
count = 0
for product in products:
count = count + 1
name = await product.locator('div.s-item**title > span').inner_text()
condition = await product.locator('.SECONDARY_INFO').inner_text()
price = await product.locator('span.s-item\_\_price').inner_text()
rating = await product.locator('div.x-star-rating span').all_inner_texts()
if len(rating) == 1:
rating = rating[0]
else:
rating = None
shipping_fee = await product.locator('span.s-item__shipping.s-item__logisticsCost').all_inner_texts()
if len(shipping_fee) == 1:
shipping_fee = shipping_fee[0][1:]
else:
shipping_fee = None
data = {'S/N':count, 'name':name, 'condition':condition, 'price':price, 'rating':rating, 'shipping fee':shipping_fee}
product_data.append(data)
print('done, evaluating')
await browser.close()
print(product_data)
if **name** == '**main**':
print(**name**)
asyncio.run(main())
Here is a brief explanation of the code snippet:
- All necessary imports for the
scraper.pyare done at the top. - The
authvariable is a combination of the Username and Password shown on the "Access parameters" page. - The
browser_urlidentifies Bright Data's Scraper Browser instance. - The
async main()function wraps the eBay data scraping algorithm. - The values for product
name,condition,price,ratingandshipping_feeare extracted for each product on that page coupled into a dictionary and saved in a list calledproduct_data.
Run the Python script on the IDE console.
python3 scraper.py
Once the code has completed, you should see the following output in your IDE console:
**main**
connecting
connected
goto
done, evaluating
[{'S/N': 1, 'name': 'Shop on eBay', 'condition': 'Brand New', 'price': '$20.00', 'rating': None, 'shipping fee': None},
...
{'S/N': 61, 'name': 'Samsung Galaxy S21 SM-S991U- 5G --- 128GB FACTORY Unlocked GSM+CDMA EXCELLENT', 'condition': 'Excellent --- Refurbished', 'price': '$268.48', 'rating': '5.0 out of 5 stars.', 'shipping fee': None}]
It is possible to debug your code while Scraping Browser is still at work. Bright Data provides a "Chrome DevTools Debugger" that would assist you in debugging your scraper code.
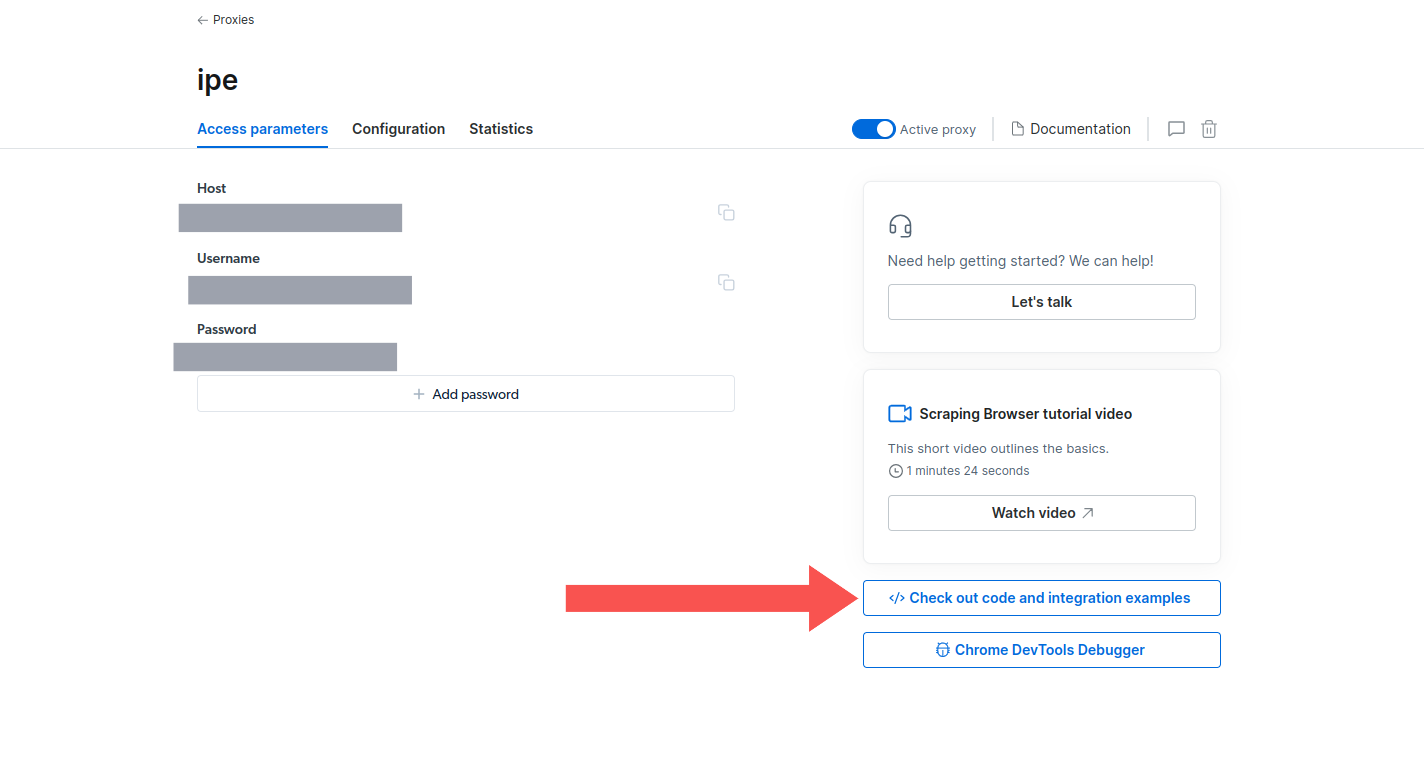
- Navigate to the "Access parameters" page and you'll find it on the lower right of your screen.
- Click on the "Chrome DevTools Debugger" button, and a modal pops up.
- Click on any of the links to access a live Scraper Browser session where you can debug via Chrome Dev Tools.
Below is a screenshot of the live scraping browser session.
Benefits of Web Scraping with the Scraping Browser
Here are some benefits of scraping data with Bright Data's Scraping Browser:
- It reduces the need for auxiliary data scraping software as it provides an all-in-one suite for all your data scraping needs.
- It can use multiple browsers simultaneously for scraping data at scale with reduced latency.
- The Scraping Browser has a debugger tool for refactoring code during scraping.
Conclusion
In this tutorial, you learned how to scrape data from one of the world's biggest eCommerce websites eBay. We listed out all the necessary steps and tools to get you started.
Whenever you're scraping big data from secured sites, you'll encounter some roadblocks, however, we used a combo of Playwright and Bright Data's Scraping Browser to bypass some of these hurdles earlier stated.
Scraping data at a large scale can be seamless and would require minimal effort on your path when using the tools mentioned in this article.
Comments
Loading comments…