"Data is a precious thing and will last longer than the systems themselves."
> Tim Berners-Lee, the inventor of the World Wide Web.
In today's data-driven age, getting hold of data from the web is business-critical for every industry, whether it's e-commerce, finance, marketing, or research; web scraping is the go-to solution for obtaining this data.
However, traditional web scraping approaches can get messy real quick. Not only are they time-consuming and error-prone, but they also face numerous challenges - JavaScript-heavy websites that cannot be parsed consistently, IP blocking, user agent detection, and CAPTCHAs, among others.
That's precisely what this curated list addresses - giving you reliable, efficient ways to streamline this process for technical and non-technical users alike.
This list includes APIs and tools that abstract common scraping strategies and mechanisms, providing clean, structured, and actionable data. These solutions enable automated data extraction with custom filters, offering cost and time savings that free up resources for other critical business needs.
Let's begin!
1. Scrape.do
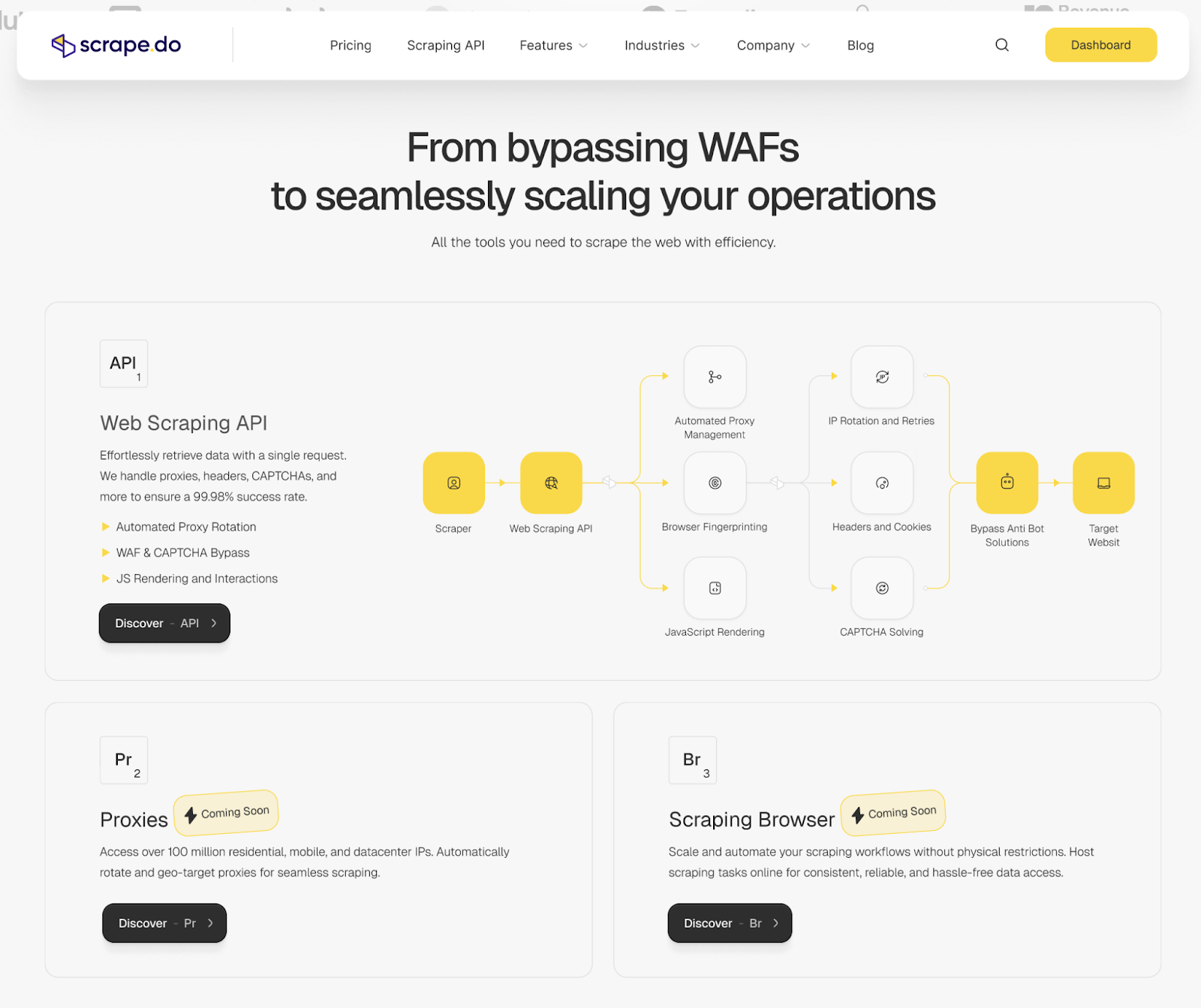
Scrape.do's web scraping API combines powerful anti-bot bypass capabilities with cost-effectiveness to offer technical teams of any level a way out of the headaches that usually come with web scraping. Available for any programming language that can send a HTTP request, it brings together the top features for unblocked data extraction:
- Premium residential and mobile proxies with pinpoint geo-targeting enables you to overcome geo-restrictions from anywhere in the world.
- CAPTCHA and anti-bot bypass capabilities make sure you can easily access public websites protected more than Fort Know.
- Headless browser functionalities and different output formats lets you scrape and export data the way you need for your use case; from price tracking to LLM training.
With on-ready solutions for popular web domains, Scrape.do can definitely handle going from single requests to billions of requests a month with a powerful infrastructure.
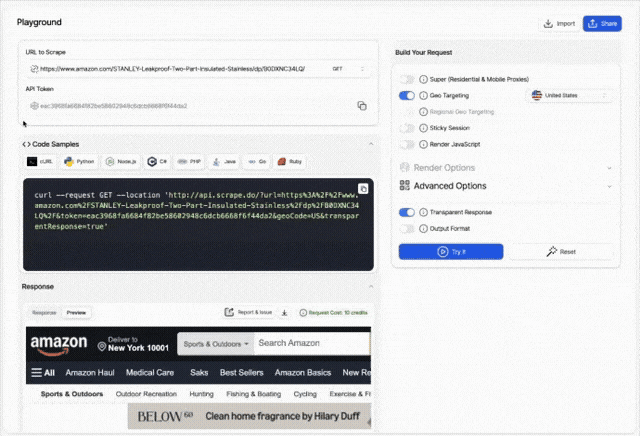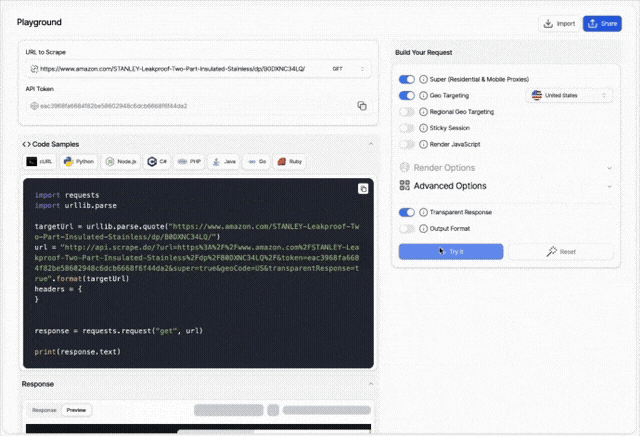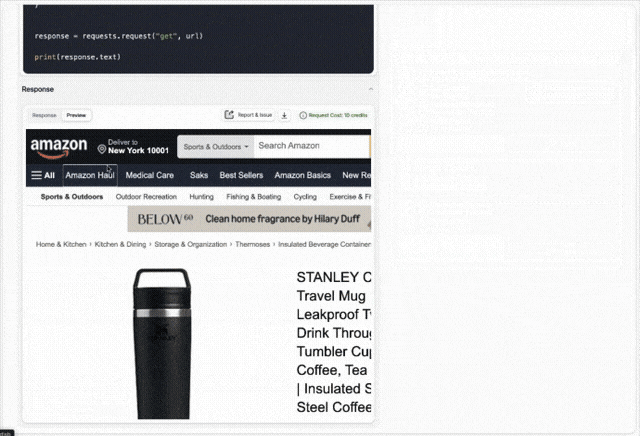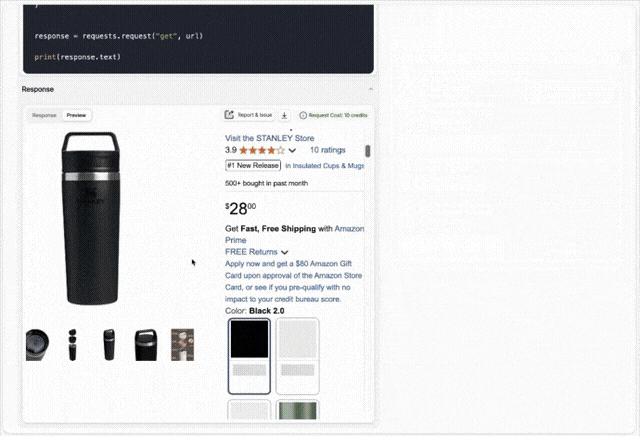
Web scraping APIs usually have dozens of parameters that you'll need to mix & match to access the data you need. Scrape.do's recently released dashboard helps you understand which parameters will get your scraper going by giving you a playground for web scraping requests.
Although the API removes a lot of worries for web scrapers, it still requires plenty of coding to set up custom scrapers as there is a lack of ready-to-use templates and APIs that extract data automatically.
2. Nimble
Nimble's Web API is a versatile, powerful, and zero-maintenance data collection solution that can turn any website into a real-time dataset, immediately ready for use. From accessing the data to delivering it to your preferred storage, every step of the data collection process is fully managed. To initiate the request, you only need to specify the target URL and you can start collecting highly accurate web data in real time.
Unlike the other solutions on this list, Nimble's Web API utilizes state-of-the-art AI-powered parsing and structuring for faster and more accurate results than traditional CSS selector or xPath-based scrapers, allowing for data extraction at any granularity you'd like.
→Learn more about the features offered by Nimble's Web API
This is a one-stop solution, meaning you can:
- Focus on generating insights that matter, not the busywork of data extraction. The Nimble Web API delivers intelligently parsed and structured data to your preferred storage so you don't have to waste time and resources managing the data; instead, you can directly skip ahead to the good part of data analysis**.**
- Automate your data extraction pipeline. Provide your storage details, grant the necessary permissions (if needed), and Nimble takes care of the rest - delivering your required data in real-time, in batches, or asynchronously (stored on your Cloud storage or Nimble's servers until you download it using a URL).
- Eliminate the need for coding, hosting, or maintenance. From your end, Nimble's API is a fully managed REST API in the cloud. Make simple API calls, then get back unlimited, structured data with zero engineering or infrastructural complexity involved. You can learn more about Nimble's flexible data delivery methods here.
Additionally, here are some of the powerful features offered by Nimble's Web API:
- Batch Processing: Batch processing enables Nimble's API to receive up to 1,000 URLs per batch, allowing users to save time and improve efficiency if they need to make several requests.
- Pre-built Templates: Nimble comes with several parsing templates out of the box that allow users to accurately extract specific snippets or key data points from a webpage. They make use of industry-standard CSS selectors and include built-in support for tables, JSON output, and custom objects.
- Page Interactions: One of Nimble's most useful features, page interactions enable users to perform operations on a webpage before the web data is collected and returned, such as clicking, typing, and scrolling. These are synchronous and run sequentially one by one, with an overall sequence limit of 60 seconds. They are supported by real-time, asynchronous, and batch requests. This feature is particularly helpful for pages using lazy loading and infinite scrolling, where the data needed is not (at least initially) in the HTML itself, but it really shines for websites that require user action (form inputs, button clicks, hover events) to dynamically display data.
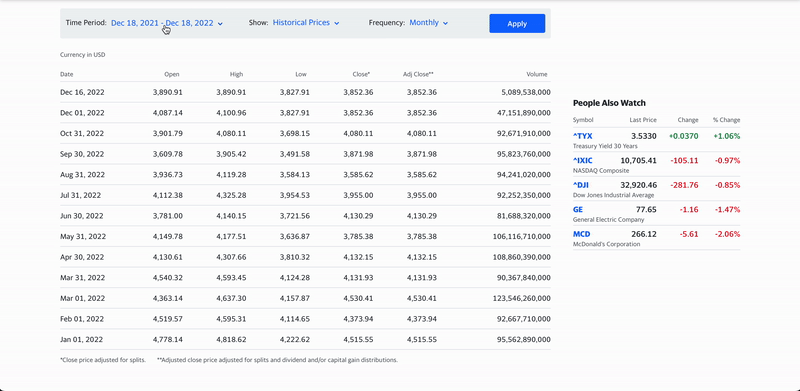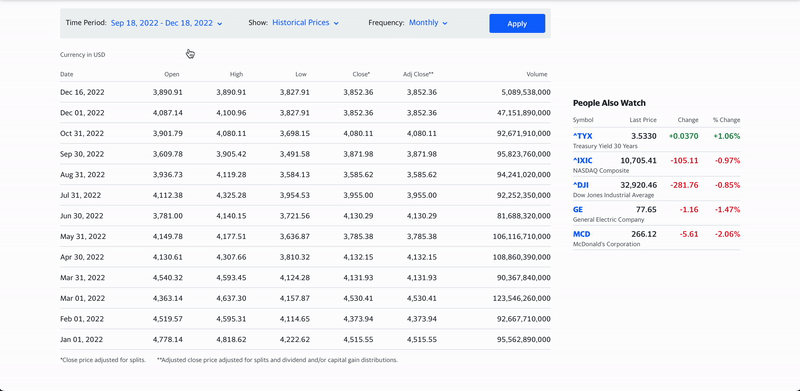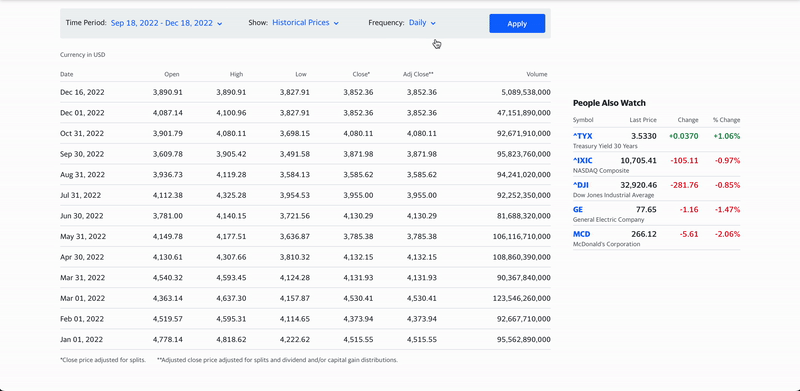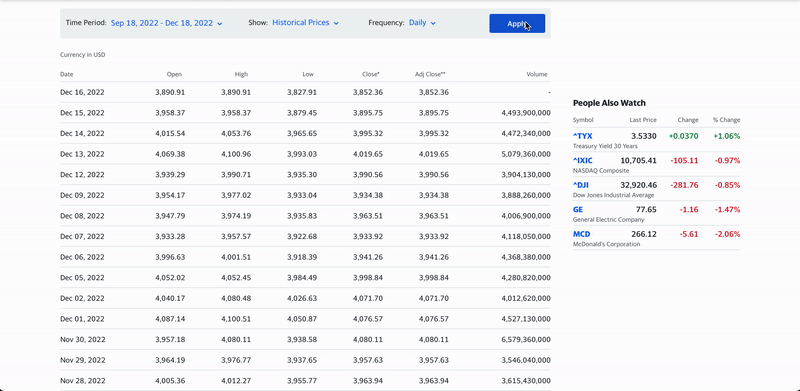
A visual representation of Nimble's page interactions feature
- Robust Fingerprint Management: One of the major challenges faced while scraping the web is bypassing device/browser fingerprints which flags and blocks your request as coming from a bot or crawler. Nimble's fingerprint engine automatically manages TLS fingerprints, canvas checking, headers, cookies, and more, ensuring unrestricted and uninterrupted access to public web data.
- Premium Proxy Network: Nimble's API comes with a premium zero-downtime IP infrastructure for continuous and effortless data gathering. It is optimized to intelligently select the best premium IPs for every request, and you can even granularly target down to state and city levels for any geolocation in the world, making localized web data gathering a breeze. Making use of Nimble's proxy rotation, you can choose among residential, data center, or ISP IPs as per your use case. This lets you bypass rate limits and ReCaptchas, ensuring maximum success rates even for particularly sensitive pages.
Learn more about Nimble's Premium Proxy Infrastructure
- Real-time Data Collection: As mentioned before, you can start gathering data in real time with a single API call. The only details you need to specify are the "URL" parameter along with the authentication token. However, you can also include custom headers, targets, or additional characters if the URL contains non-ASCII characters. All you have to do is supply the request parameters in a valid JSON format. To ensure the highest success rates, all requests are automatically routed through the above-mentioned premium proxy network.
No matter your use case, Nimble offers a streamlined, zero-infrastructure solution for extracting publicly available web data, accurately, uninterrupted, at scale, and in minutes - not weeks.
It also comes with several flexible pricing plans, including a pay-per-success model where only successful requests are billed. To use Nimble's Web API, you'll first need to sign up for an account; you can do so by registering for free here.
Learn more: Nimble API - Collect Data From Any Website. Effortlessly.
3. ScrapingBee
ScrapingBee has a simple API that requires minimal coding knowledge to get started. The API is well-documented, and there are code snippets available in various programming languages to help users get started quickly. If you are looking for a reliable and efficient web scraping tool, ScrapingBee is a great option to consider.
ScrapingBee also comes with tutorials for developers to use it with their preferred programming language:
Some key features of the ScrapingBee API:
- Browser rendering: ScrapingBee uses a headless browser to render JavaScript and dynamic content, ensuring that you can scrape websites that heavily rely on JavaScript for their content and get all the data you need. You can learn more about how ScrapingBee handles JavaScript here.
- Proxy management: ScrapingBee handles proxy management for you, rotating IPs and managing blocks so you can focus on your scraping tasks. A wide range of premium proxies is provided, and you get to choose a proxy country from a list of given countries, minimizing your chances of getting blocked. ScrapingBee also provides the infrastructure for using your own proxies if you want.
- Fast and scalable: ScrapingBee can handle large volumes of scraping requests quickly and efficiently. It uses a distributed infrastructure that allows for horizontal scaling, ensuring that users can handle high-traffic websites.
- CAPTCHA solving: ScrapingBee uses Machine Learning algorithms and image recognition technology to solve Captchas automatically. However, while this approach can be faster and cheaper than manual solutions, it may not work in all situations. ScrapingBee also partners with third-party services to provide manual Captcha-solving solutions.
- Easy integration: ScrapingBee provides APIs for a variety of programming languages, including Python, Node.js, and PHP, as well as integrations with popular tools like Scrapy, Beautiful Soup, and Selenium.
However, being a no-code solution, ScrapingBee is quite limited when it comes to more advanced customization options. For example, in comparison to some other items on this list, users may not be able to scrape specific data types or implement complex data extraction rules with ScrapingBee.
That said, ScrapingBee is certainly worth considering if you're just looking to get started with an easy-to-use, affordable and user-friendly API that still offers a decent number of features to collect data from the web at scale. It sports some fantastic documentation including detailed tutorials with code samples to help ease you in. They also have a dedicated tech support team to answer your queries.
4. ParseHub
ParseHub is a user-friendly and adaptable web scraping tool that allows easy access to both static and dynamic online data. One of the biggest advantages of ParseHub is its simple point-and-click interface, which does not require any coding skills:
- Open a website of your choice, and start selecting the data you want to extract. It's that simple.
- Once specific elements have been selected, export the data as JSON/CSV, or set an interval for scraping these elements.
ParseHub is available as a desktop app that can be launched directly on targeted websites, which makes it an ideal choice for users who want to extract data without coding.
Here are some additional features:
- ParseHub offers an API that automates the data extraction process. With every request sent to the ParseHub server, users can fetch the latest data, ensuring that the data received is fresh and accurate. Additionally, the API can be integrated with other apps/services for maximum efficiency.
- The IP rotation feature allows users to overcome geo-location blocks and makes it more difficult for websites to detect or block scraping requests.
- ParseHub uses regular expressions to clean text and HTML before downloading data, which ensures that the data is well-organized and accurate.
- ParseHub supports infinitely scrolling pages and the ability to extract data behind a login.
ParseHub is an excellent choice for those who want to extract data quickly and easily, without having to write any code. However, it may not be the best option for more sensitive websites that require complex solutions to overcome blocks. In such cases, the uptime of the scraping operation may be limited.
5. ZenScrape
ZenScrape's API is designed to be easy to use, even for developers who are new to web scraping. The API provides a simple RESTful interface that allows developers to extract data from any website without having to write complex code.
The API uses advanced algorithms and techniques to extract data from websites with a high degree of accuracy, with API response times as low as 50 milliseconds. It can handle dynamic content, such as JavaScript-generated pages, and extract data from websites that use CAPTCHAs or other anti-scraping techniques like IP blacklisting, and other anti-bot measures
Here are some key features of ZenScrape's Web Scraping API:
- Robust data processing features (such as data cleaning, deduplication, and normalization) at scale.
- SDKs for several programming languages, including Python, Ruby, and Node.js, which makes it easy for developers to integrate the API into their existing workflows.
- Enables users to choose their proxy location to show geotargeted content and utilize a huge IP pool.
- Provides a request builder that converts requests into production-ready code snippets.
- Endless use cases, including web crawling, price data scraping, marketing data scraping, review scraping, hiring data scraping, and real estate data scraping.
In addition to these features, ZenScrape also comes with a generous free plan that offers 1,000 API requests per month for free. However, the free plan comes with limited features and does not include advanced features such as data processing.
Nonetheless, its ease of use, flexible pricing and support for a large number of programming languages make ZenScrape a pretty good choice for developers looking for an easy way to extract web data.
6. Apify
Apify is a cloud-based web scraping tool that offers a unique approach to online data extraction. Instead of using a pre-built interface, Apify lets you write your own code using popular open-source libraries like Scrapy, Selenium, Playwright, Puppeteer, or Apify's own Crawlee. Once the code is written, you can host it on Apify's cloud and schedule it to run as and when needed.
In addition to its flexible coding approach, Apify also offers the following features:
- Powerful storage system: Apify provides a storage system where you can collect scraped data in various formats, such as JSON, CSV, or XML files.
- Dashboard monitoring: Apify's dashboard allows you to monitor the entire scraping process, giving you control over what is executed and the ability to quickly identify any possible errors.
- Flexibility: You can run jobs written in any language, as long as they can be packaged as Docker containers. Additionally, every scraping script or "Apify Actor" you deploy on Apify can be published and monetized, or kept free and open-source, depending on your preferences.
- Built-in integrations: Apify provides built-in integrations with popular platforms like Slack, Zapier, Google Drive, and GitHub, making it easy to send notifications, save results to cloud storage, or manage bugs and issues whenever your data extraction script fails.
While Apify's flexibility is a huge plus, its downside is that it requires coding expertise. This might be a deal-breaker for some users who don't have programming skills on their team. However, if you're looking for a powerful web scraping tool that offers maximum control and flexibility, Apify is definitely worth considering.
7. Scraper API

ScraperAPI provides a robust web scraping API that effectively handles the common challenges of large-scale data extraction, allowing users to focus on the data itself rather than infrastructure. It's an ideal web scraping tool for developers and businesses seeking to extract data from various online sources, including e-commerce sites, search engine results pages (SERPs), and social media. The API is designed to simplify web scraping by managing proxies, headless browsers, and CAPTCHA challenges, making it a powerful proxy API for web scraping.
Key features of ScraperAPI include:
- Intelligent Proxy Rotation: ScraperAPI leverages a vast pool of rotating IPs (including residential, datacenter, and mobile proxies) to prevent IP blocking and ensure high success rates, even for websites with sophisticated anti-bot measures. This is crucial for maintaining consistent data flow when scraping Amazon for product data, for instance.
- JavaScript Rendering: It seamlessly handles dynamic content and JavaScript-heavy websites by utilizing a built-in headless browser. This feature ensures that all data, even that loaded asynchronously, is accurately captured.
- CAPTCHA Bypass: ScraperAPI incorporates advanced CAPTCHA-solving mechanisms, automatically bypassing various CAPTCHA types, which saves significant time and effort in complex web data extraction scenarios.
- Geotargeting: Users can easily target specific geographic locations, allowing for the collection of localized data, which is essential for competitive analysis, market research, and localized SERP monitoring.
- Scalable and Reliable: Designed for large-volume scraping, ScraperAPI ensures high performance and reliability, retrying failed requests with fresh IPs and automatically throttling requests to avoid detection.
- Developer-Friendly API: With well-documented APIs and code snippets in popular languages like Python, Node.js, and PHP, integrating ScraperAPI into existing workflows is straightforward. It also offers dedicated features like Async Scraper Service for handling millions of requests concurrently and Structured Data for specific domains like Amazon and Google.
ScraperAPI allows you to focus on analyzing the extracted insights, making it a valuable web scraping solution for anyone needing reliable and efficient access to public web data at scale. It offers flexible pricing plans, including a free trial to get started.
Our Recommendations
To summarize, web scraping is essential for data analysis across industries and domains, but conventional techniques are just not going to cut it in the modern web. In this post, we've examined 5 advanced web scraping APIs and tools that make large-scale data extraction easier for businesses and developers.
Here's the TL;DR:
- Nimble's Web API stands out as the best all-around end-to-end data collection solution because it is fully managed, has AI-powered data parsing and structuring to help create end-to-end data pipelines, and, being just a REST API in the cloud, can be used to automate data collection with zero maintenance or infrastructural costs. Its powerful fingerprint engine and proxy infrastructure also help bypass major website blocks and throttling.
- ScrapingBee, while not providing the same level of customization as Nimble, abstracts the difficult task of managing a large number of headless Chrome instances behind an easy-to-use API service with a feature-limited free version. It can work well for large-scale projects involving consistent, well-structured sites which require horizontal scaling, but doesn't fare as well for advanced web scraping challenges.
- ParseHub, with its simple point-and-click interface, is great for non-technical users.
While all of the solutions listed here excel in different areas, the API or tool you choose will be determined by your specific use case and needs. I hope this article will help you in that regard.
Comments
Loading comments…