
Photo by Emile Perron on Unsplash
Web scraping has become an essential technique to gather large amounts of data from the internet. Whether it's for market research, sentiment analysis, or competitive intelligence, the ability to efficiently extract information from websites is a valuable skill. However, web scrapers often encounter a roadblock called an IP ban. Websites can identify and block the IP addresses they suspect of scraping, significantly hindering data collection efforts.
This article will guide you on what an IP ban is and how you can keep yourself safe from such bans so that you can efficiently scrape data from websites. You'll explore the tools and services that are crucial in bypassing such bans. More specifically, we'll be using a tool called the Scraping Browser --- a Playwright/Puppeteer/Selenium-compatible headful, GUI browser that comes with built-in advanced scraping technology right out of the box. But before jumping right into how to bypass a ban, it's first important to understand what an IP ban is.
What is an IP Ban?
An IP ban is a restriction that a website can impose to prevent a specific IP address from accessing its content. When you connect to the internet, your device is assigned an IP address, which is a unique identifier. Websites can detect this identifier. If a website's security systems determine that an IP address engages in suspicious or rule-breaking activities, such as excessively frequent requests often associated with web scraping, the website can block this IP address.
This block, or IP ban, means that any further attempts to access the website from the banned IP address will be denied. The website will not respond to requests, and the user behind the IP address will be unable to view or interact with the website's content.
In the context of web scraping, an IP ban can significantly disrupt your data collection efforts, as it prevents the scraper from accessing and extracting information from the site.
An IP ban is also a critical tool for websites to defend against Distributed Denial of Service (DDoS) attacks. In a DDoS attack, multiple systems flood the bandwidth or resources of a targeted website, aiming to overwhelm it with traffic and render it inaccessible to legitimate users. By identifying and blocking the IP addresses that are contributing to the attack, website administrators can reduce the impact of the assault.
However, for a regular user, there can be many reasons for getting their IP banned. Some reasons are discussed below.
Reasons to Receive an IP Ban
You already understand that an IP ban is a protective measure taken by website owners to ensure stability and security. Understanding the common reasons why you might get IP banned can help you find ways to bypass it. Here are some reasons why an IP might get banned:
- Suspicious Activity: If a website detects unusual behaviour from an IP address, such as attempting to access restricted areas or trying to breach security protocols, it may issue a ban. It is a defence mechanism against potential threats.
- Excessive Requests: Websites expect human users to visit a few pages in a minute, not hundreds. If an IP address makes an unusually high number of requests in a short time, it's often seen as a bot or scraper, which can lead to an IP ban. This behaviour can overload a website's servers, causing slowdowns or crashes, so websites quickly block such IPs.
- Throttling/Rate Limiting: Some websites have set limits on how many requests an IP can make in a given timeframe. This is known as rate limiting or throttling. If an IP exceeds this limit, it can trigger an automatic ban. This is often a temporary measure, but repeated offences can lead to a permanent ban.
- Violating Terms of Service: Many websites have terms of service that explicitly forbid automated data collection or other specific behaviours. If your activities on a site violate these terms, the website may enforce an IP ban as a consequence.
- Association with Malicious Activity: If an IP address is associated with hacking, spamming, or other malicious activities, websites may preemptively ban it to protect their users and infrastructure.
- DDoS Protection: As mentioned earlier, to protect against DDoS attacks, websites may ban IPs that are part of the attack vector. This is a reactive measure to ensure the site remains available to other users.
Now that you have a clear idea of what an IP ban is and the common reasons for getting banned, let's move forward and understand how you can bypass an IP ban and scrape websites effectively.
How to Bypass the IP Ban
There are many potential solutions available to bypass an IP ban. However, not all the solutions are equally effective. One common workaround is to use proxy servers. However, if you are not rotating the proxies regularly or if you are not using residential proxies, the chances of getting blocked are still high. And mimicking human-like behaviour with your web scraping script could also be a tough task.
To simplify the process, we can use ready-made tools that come with block-bypassing technology right out of the box. Bright Data's Scraping Browser is one such tool that can simplify your scraping process immensely. In the next section, we'll take a look into how the Scraping Browser helps effectively bypass IP bans while making for a streamlined and scalable scraping process.
What is the Scraping Browser?
Bright Data's Scraping Browser is an all-in-one solution that merges the ease of an automated, authentic browser experience with the robust capabilities of Bright Data's unlocker infrastructure and its advanced proxy management services. This tool is designed to seamlessly integrate with popular automation frameworks like Puppeteer, Playwright, and Selenium APIs, providing a comprehensive toolset for effective data scraping.
Scraping Browser --- Build Unblockable Scrapers with Puppeteer, Playwright, and Selenium *Integrate Bright Data's browser with your scraping scripts to outsmart bot-detection software and avoid website...*brightdata.com
The Scraping Browser comes in-built with Bright Data's powerful unlocker infrastructure which allows it to imitate real user behaviour very closely by copying details like browser plugins, font types, browser versions, cookies, and various technical fingerprints that websites use to identify users. It sets up necessary browser settings like headers and cookies to make sure your scraping activities don't get flagged as suspicious.

Bright Data' Scraping Browser
It also mimics the characteristics of different devices connected to a system, such as screen resolutions and mouse movements, to prevent detection. The browser handles the technical aspects of web communication, ensuring that your scraping requests look legitimate by managing details like HTTP headers and upgrading connection protocols to match those of typical browsers.
💡 From CAPTCHA-solving to User-agent generation to cookie management and fingerprint emulation, the unlocker infrastructure can bypass even the most sophisticated anti-scraping measures, ensuring a smooth and uninterrupted scraping process. Learn more here.
The browser can also solve various types of CAPTCHAs. Bright Data updates and maintains this CAPTCHA-solving functionality as a managed service, so you don't have to keep adjusting your scraping scripts to deal with new security measures websites might use to block scraping.
In addition to that, the Scraping Browser also makes use of Bright Data's premium proxy network which offers four different types of proxy services --- datacenter, residential, ISP, and mobile, allowing you to pick and rotate your IPs depending on your use case.
Now, with all that said, let's move on and discuss how to use the Scraping Browser to bypass IP bans.
How to Use the Scraping Browser
Getting started with the Scraping Browser is pretty straightforward. It integrates well with Playwright, Puppeteer or Selenium script, which allows you to get started quickly with your existing scraping scripts.
To demonstrate this, we'll be using Node.js and Puppeteer. We'll scrape a specific product page from Amazon and extract information like the name, price, rating, and top reviews. The reason for choosing Amazon is because Amazon imposes a lot of anti-scraping and security measures to protect the website (and thus, we are likely to run into IP bans).
To begin with, you first need to sign up for a Bright Data account. Visit the official website and click on "Start free trial." You can also choose to sign up with Google. The free trial gives you a $5 credit, which you can use to test out the products.
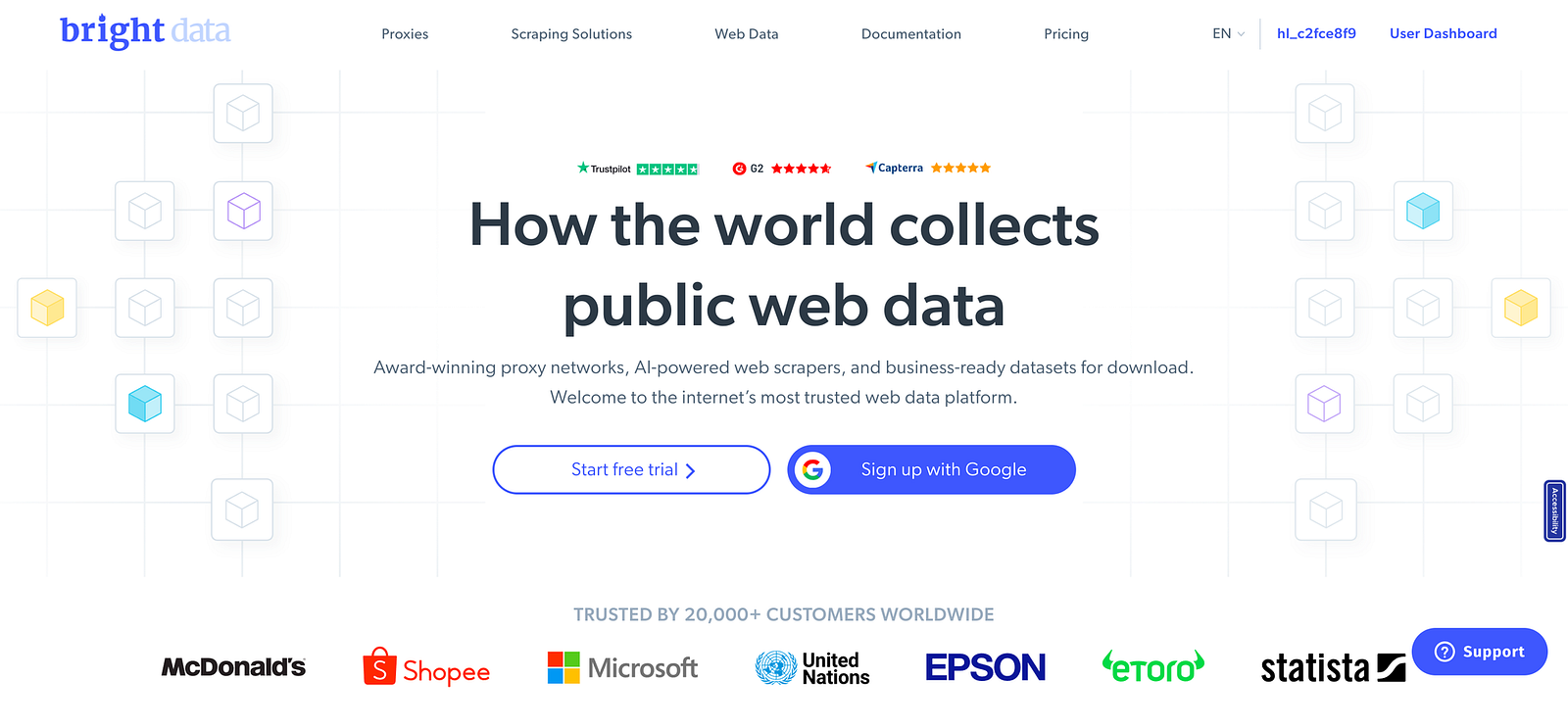
Once you are signed in and redirected to the Bright Data dashboard, click on the "Proxies and Scraping Infra" button. Once there, click on the "Add" button available on the right and select Scraping Browser from the dropdown.
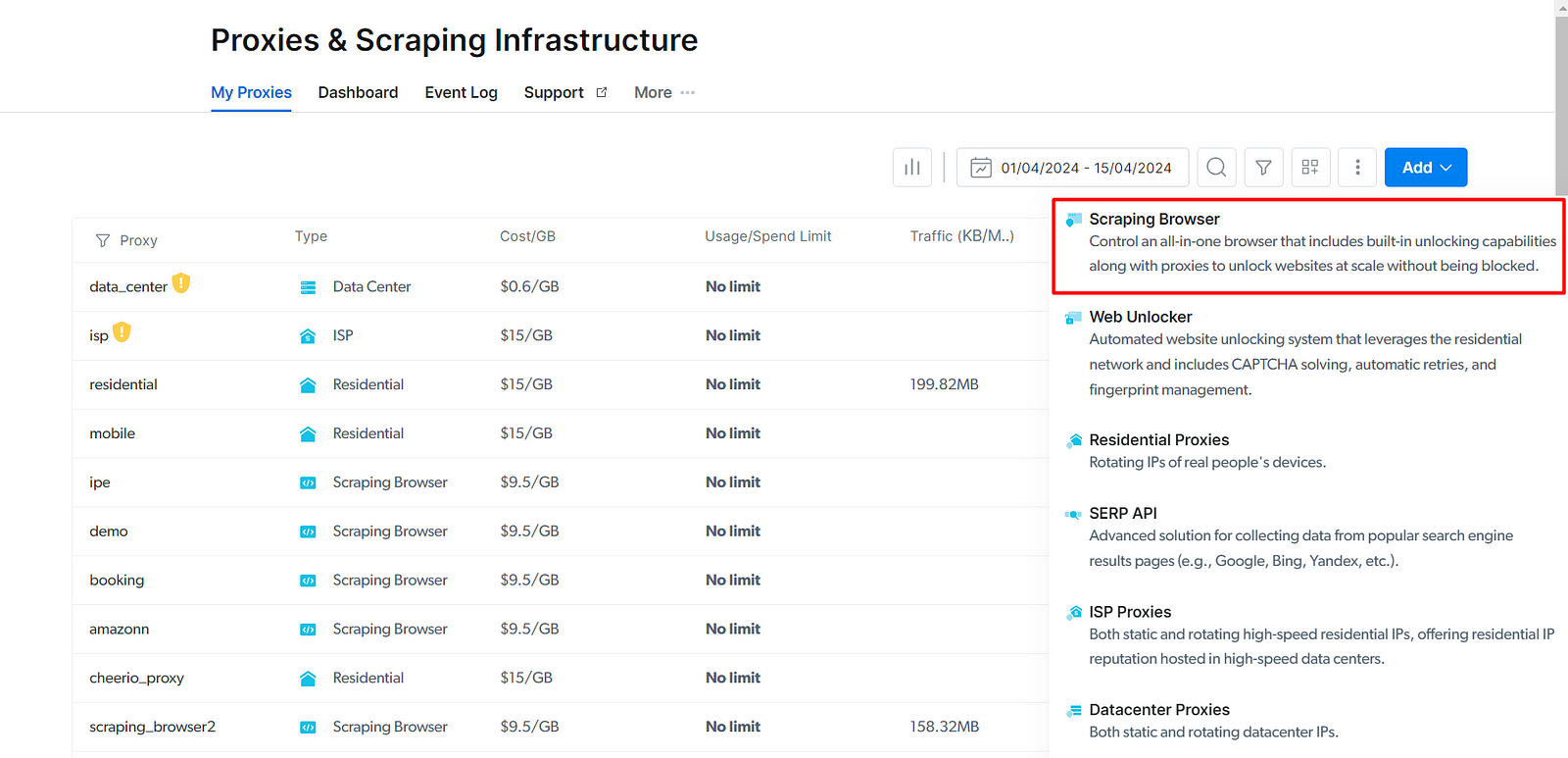
In the next screen, you can provide the name of the browser. After giving a name, click on the "Add" button. Once the browser is added, it'll provide you with the access parameters required for connecting Puppeteer or any other tool you want to use.

You'll require the host, username, and password. Keep this information safe, and now, let's discuss some code.
The code shown below is a simple example of how the scraping browser can be integrated with Puppeteer to scrape product details from Amazon. The code here showcases how a product's details, including the title, price, rating, total number of reviews, and top reviews, can be scraped from Amazon.
import puppeteer from "puppeteer";
import dotenv from "dotenv";
dotenv.config();
const SBR_URL = `wss"//${process.env.BD_USERNAME}:${process.env.BD_PASSWORD}@${process.env.BD_HOST}`;
async function scrapeProduct(url) {
const browser = await puppeteer.launch({
browserWSEndpoint: SBR_URL,
});
try {
console.log("Connected to browser...");
const page = await browser.newPage();
await page.goto(url);
// Selectors based on the Amazon product page layout
const productTitleSelector = "#productTitle";
const priceSelector = "#corePrice_desktop .a-price .a-offscreen";
const ratingSelector = ".a-icon-star-small";
const totalReviewSelector = "#acrCustomerReviewText";
const reviewContentSelector = "#cm-cr-dp-review-list";
// Extract data from the page
const [productTitle, price, rating, totalReviews, reviewContent] =
await Promise.all([
page.$eval(productTitleSelector, (el) => el.innerText.trim()),
page
.$eval(priceSelector, (el) => el.innerText.trim())
.catch(() => "Price not available"),
page
.$eval(ratingSelector, (el) => el.innerText.trim())
.catch(() => "Rating not available"),
page
.$eval(totalReviewSelector, (el) => el.innerText.trim())
.catch(() => "Review not available"),
page
.$eval(reviewContentSelector, (el) => {
const reviews = Array.from(
el.querySelectorAll(".a-section.review")
);
return reviews.map((review) => {
return {
reviewTitle: review
.querySelector(".review-title span:nth-child(3)")
.innerText.trim(),
reviewRating: review
.querySelector(".a-icon-alt")
.innerText.trim(),
reviewText: review
.querySelector(".review-text")
.innerText.trim(),
};
});
})
.catch(() => "Review content not available"),
]);
console.log(`Title: ${productTitle}`);
console.log(`Price: ${price}`);
console.log(`Rating: ${rating}`);
console.log(`Total Reviews: ${totalReviews}`);
console.log(`Review Content: ${JSON.stringify(reviewContent, null, 2)}`);
await browser.close();
} catch (error) {
console.error("Error scraping the product", error);
await browser.close();
}
}
scrapeProduct("https://www.amazon.com/dp/B0B92489PD/"); // Or any other product URL you want to scrape
The code is pretty straightforward, and there is nothing much to explain. The scrapeProduct() function is the main function of the program. The function starts by launching a new Puppeteer browser instance. Once the browser is launched, a new page is opened, and the function navigates to the provided URL. In this case, the product page is this one.

The scapeProduct() function then defines several CSS selectors corresponding to different elements on the Amazon product page, such as the product title, price, rating, total reviews, and review content. The function uses the [$eval](https://pptr.dev/api/puppeteer.page._eval) method to extract the text content of these elements. The $eval method runs a function in the page context that can interact with the DOM. In this case, it's used to get the innerText of the selected elements and trim any extra whitespace. A default message is returned if any of these operations fail.
For the review content, the function extracts an array of review objects, each with a title, rating, and text. This is done by selecting all review elements, converting the NodeList to an array, and mapping each review element to an object.
All these operations are performed concurrently using Promise.all, which waits for all the promises to resolve and returns an array with the results. Once all the promises are resolved, the function logs the results in the console.
The only configuration required to connect it with the scraping browser is passing the WSS link to the browserWSEndpoint option for the Puppeteer browser instance, like this:
const browser = await puppeteer.launch({
browserWSEndpoint: SBR_URL,
});
This WS link(SBR_URL variable in this case) combines the username, password, and host provided by the Bright Data dashboard. The structure of the link is like this:
const SBR_URL = wss"//YOUR_USERNAME:YOUR_PASSWORD@$YOUR_HOST;
The browserWSEndpoint option connects Puppeteer to an existing browser instance instead of launching a new one. The URL we provided specifies the scraping browser that should be used for Puppeteer to work.
And that's it. Now, if you try to run the command node app.js from the terminal, you'll be able to see a result similar to the image below printed in your console.
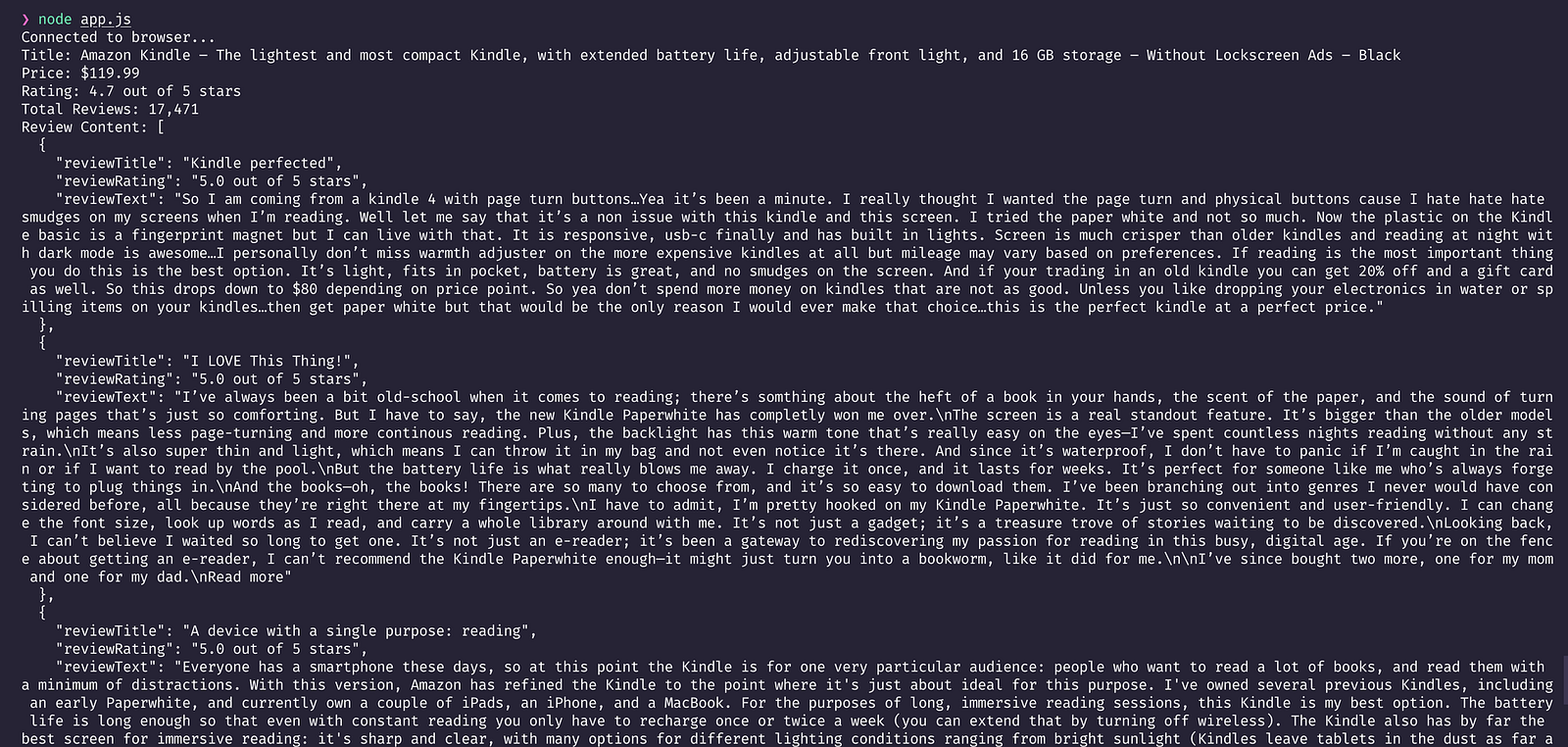
Scraping Amazon Product Details
Setting up the Scraping Browser is this simple. And with this simple configuration, you are ready to bypass IP bans. Earlier on, we looked into some of the features that the Scraping Browser provides right out of the box. With its unlocker technology and automated proxy management, you can easily manage CAPTCHAs, browser fingerprinting, automatic retries, headers selection, cookies, JavaScript rendering, and more, which helps in having a near-foolproof solution when it comes to IP bans.
Conclusion
Being able to scrape a webpage efficiently is crucial. An IP ban can be a critical issue in your workflow if it is not properly managed. With its built-in advanced features and technologies, the Scraping Browser lets you perform all the necessary scraping tasks without the tension of getting blocked, and is a managed service, meaning that you don't need to update your scraping script in case the website updates its anti-bot mechanisms; that's taken care of on Bright Data's end. Also, the Scraping Browser integrates well with existing scripts written in Selenium, Playwright or Puppeteer.
Scraping Browser --- Build Unblockable Scrapers with Puppeteer, Playwright, and Selenium *Integrate Bright Data's browser with your scraping scripts to outsmart bot-detection software and avoid website...*brightdata.com
Bright Data also ensures it follows all the rules for data protection, including Europe's General Data Protection Regulation (GDPR) and the California Consumer Privacy Act (CCPA). This means you're significantly less likely to land in legal hot water when it comes to a website and data privacy laws.
Whether you're scraping data for yourself or for your business, the Scraping Browser lets you gather web data in an uninterrupted manner, at scale. It helps you pull out important information while keeping the data private and intact. Plus, you get a $5 credit when you sign up. You can use this credit to test out the features of the Scraping Browser and upgrade only when you are confident.
Comments
Loading comments…