
An estimated 40% of websites today use Cloudflare's anti-bot protection system. This makes sense, as websites want to use secure defenses to protect their data and user privacy and shield themselves from malicious attacks. Cloudflare is very effective at detecting and blocking bots which has led to its widespread adoption by websites in recent years.
However, let's say you have legitimate data collection and web scraping needs. In that case, Cloudflare's anti-bot protection system can act as a significant hindrance in letting you scrape and collect the data you need, especially if you want to do it in a seamless manner, at scale.
Bypassing Cloudflare's protection system can be difficult but it's not impossible. In this article, we'll look at how Cloudflare's anti-bot system works when it comes to web scraping and then look at the Scraping Browser (a headful, fully GUI browser that is 100% compatible with Puppeteer/Playwright/Selenium APIs) as a solution that helps bypass these challenges so that you can collect the data you need in an uninterrupted manner.
How Cloudflare Blocks Web Scraping Attempts: Understanding the Mechanisms
Cloudflare is a leading provider of cybersecurity and web performance solutions, and offers strong and effective measures to counter web scraping attempts. This is to prevent unscrupulous scraping attempts and to address concerns about data misuse, copyright infringement, and server overload.
Unfortunately, as somewhat collateral damage, it also affects legitimate data collection efforts. Cloudflare's anti-bot protection system effectively detects and blocks bots engaged in scraping activities by employing a range of sophisticated techniques. Let's look into some of these so that we have a better understanding of them.
- Rate Limiting: Cloudflare can implement rate-limiting rules to restrict the number of requests a client (such as a bot) can make within a specific timeframe. This prevents bots from overwhelming the server with a barrage of requests, as legitimate users typically don't generate requests at such a high rate.
- Challenge-based Mechanisms: Cloudflare can present challenges to incoming requests, such as CAPTCHAs or JavaScript challenges, to verify if the client is a human user or a bot. This extra step can deter automated scraping bots that are unable to solve these challenges accurately.
- IP Reputation and Blacklisting: Cloudflare maintains IP reputation databases and can block or challenge traffic from IPs known for malicious activities, including scraping. This helps in identifying and mitigating known bad actors attempting to scrape data.
- Browser Integrity Check: Cloudflare can perform browser integrity checks (often through browser fingerprints) to ensure that incoming requests are from genuine web browsers and not automated scripts or bots pretending to be browsers. This helps in differentiating between legitimate user traffic and scraping attempts.
- User-Agent Filtering: Cloudflare can filter incoming requests based on the User-Agent header, which contains information about the client making the request (e.g., browser type, version). By blocking or challenging requests from suspicious or known bot User-Agents, Cloudflare can mitigate scraping attempts.
- JavaScript Challenges: Cloudflare can serve JavaScript challenges that require the client to execute JavaScript code to prove its legitimacy. Bots often struggle with executing JavaScript, so this method can effectively block automated scraping attempts.
These measures make web scraping attempts very difficult, as there are not just one but a multitude of factors you need to take into consideration. The general approach involves using proxies or headless browsers like Selenium or Puppeteer but those approaches are not 100% foolproof and come with their own drawbacks such as having to rely on third-party services and additional infrastructure.
Moreover, free or datacenter proxies, which are generally used, may not work very well against Cloudflare's protection and get easily blocked.
In the next section, we'll take a look at how to bypass all of these challenges at once with Bright Data's Scraping Browser, a headful, fully GUI browser that:
- Comes with block-bypassing technology right out of the box.
- Ensures ethical compliance with major data protection laws.
- Can be easily integrated with existing Puppeteer/Playwright/Selenium scripts.
Let's dive in.
The Scraping Browser: A Comprehensive and Scalable Solution for Bypassing Cloudflare Protection
The Scraping Browser is a headful, fully GUI browser that is fully compatible with Puppeteer/Playwright/Selenium APIs, and by incorporating Bright Data's powerful unlocker infrastructure and proxy network, it rotates IP addresses, avoids detection, and gracefully sails through CAPTCHAs without breaking a sweat.
When it comes to the above-mentioned challenges, the presence of the unlocker infrastructure takes care of them right out of the gate. This is because of its in-built powerful unlocker infrastructure and proxy network, which means it arrives with block-bypassing technology right out of the box, no additional measures are needed on your part.
Learn more about the Scraping Browser's capabilities:
Scraping Browser --- Build Unblockable Scrapers with Puppeteer, Playwright, and Selenium *Integrate Bright Data's browser with your scraping scripts to outsmart bot-detection software and avoid website...*brightdata.com
The unlocker technology automatically configures relevant header information (such as User-Agent strings) and manages cookies according to the requirements of the target website so that you can avoid getting detected and blocked as a "crawler" or a bot. It also ensures perfect browser/device fingerprint emulation, which helps bypass Cloudflare's browser integrity checks.
Meanwhile, Bright Data's proxy management services allow you to automate IP rotation between four different kinds of proxy services, including ethically sourced residential proxies which are extremely useful in bypassing throttling or rate limits.
💡Note: From CAPTCHA-solving to User-agent generation to cookie management and fingerprint emulation, Bright Data's unlocker infrastructure can bypass even the most sophisticated anti-scraping measures. Learn more here.
Bright Data's unlocker infrastructure is a managed service, meaning that you don't have to worry about updating your code to keep up with a website's ever-changing CAPTCHA-generation mechanisms. Bright Data takes care of all of that for you, handling the updates and maintenance on their end.
All this ensures that the Scraping Browser easily overcomes the challenges we mentioned earlier. In addition to that, it is highly scalable, allowing you to scale unlimited sessions using a simple browser API, saving infrastructure costs. This is particularly beneficial when you need to open as many Scraping Browsers as you need without an expansive in-house infrastructure.

What's more, the browser's API is fully compatible with your existing Puppeteer/Playwright scripts, making integration a cinch, and migration a cakewalk.
With all that said, let's now dive into setting up the Scraping Browser and scrape a website that makes use of Cloudflare's protection and see how it fares.
Scraping Nike with the Scraping Browser
Cloudflare is heavily used by many popular websites for performance, security, and DDoS protection. One such website that relies on Cloudflare for its security is Nike. To demonstrate how the Scraping Browser can bypass Cloudflare's protection with ease, we'll be scraping product details from the Nike website. For this part, Puppeteer with Node.js will be used. However, you are free to use other tools like Playwright or Selenium.
Setting up the Scraping Browser
To use the Scraping Browser, you'll first need to create an account at Bright Data. You can sign up for free, and you'll also get a $5 credit to test out the products.
To sign up, go to Bright Data's website, and click on "Start free trial." You can also choose to sign up with Google.
After signing up, click on the "Proxies and Scraping Infra" button from the dashboard. Once the new page opens, click on the "Add" button available on the right-hand side, and select "Scraping Browser" from the dropdown.
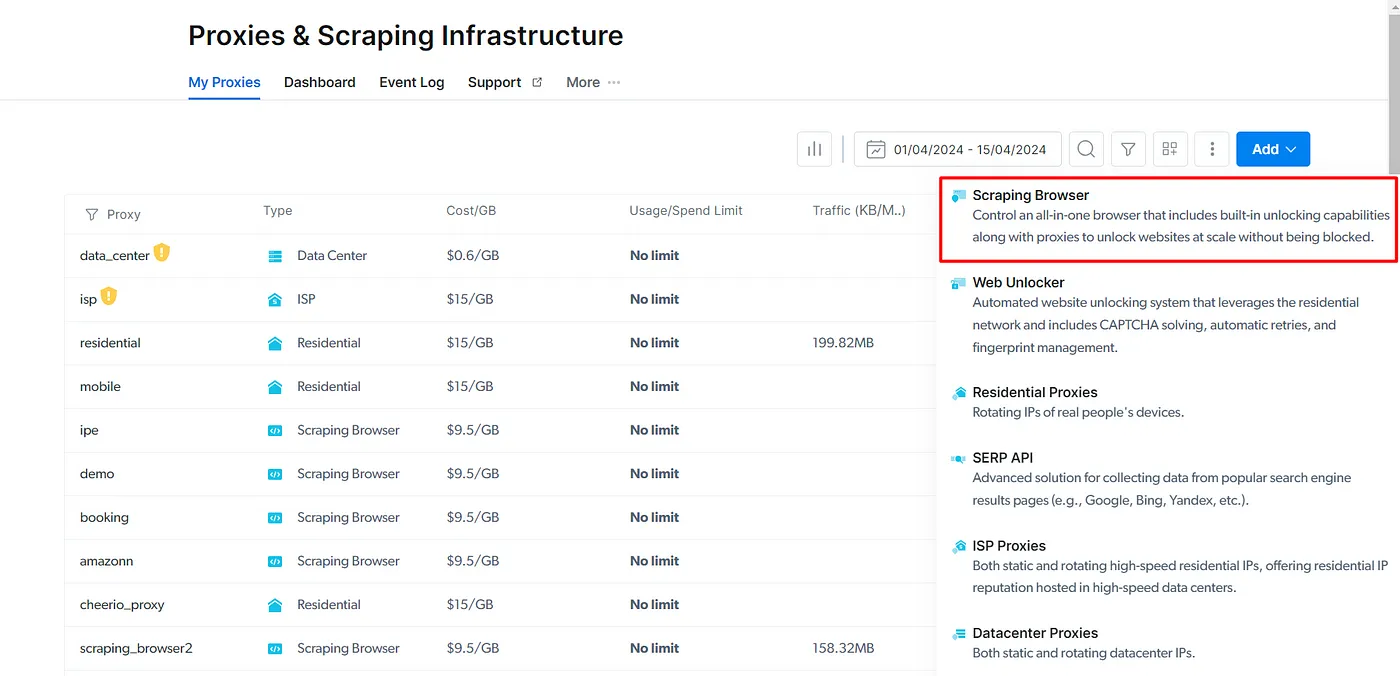
On this page, give your browser a name, and click on the "Add" button. After you click the button, you'll be redirected to the browser details page. This page will give you access to the required parameters for connecting Puppeteer or similar tools.
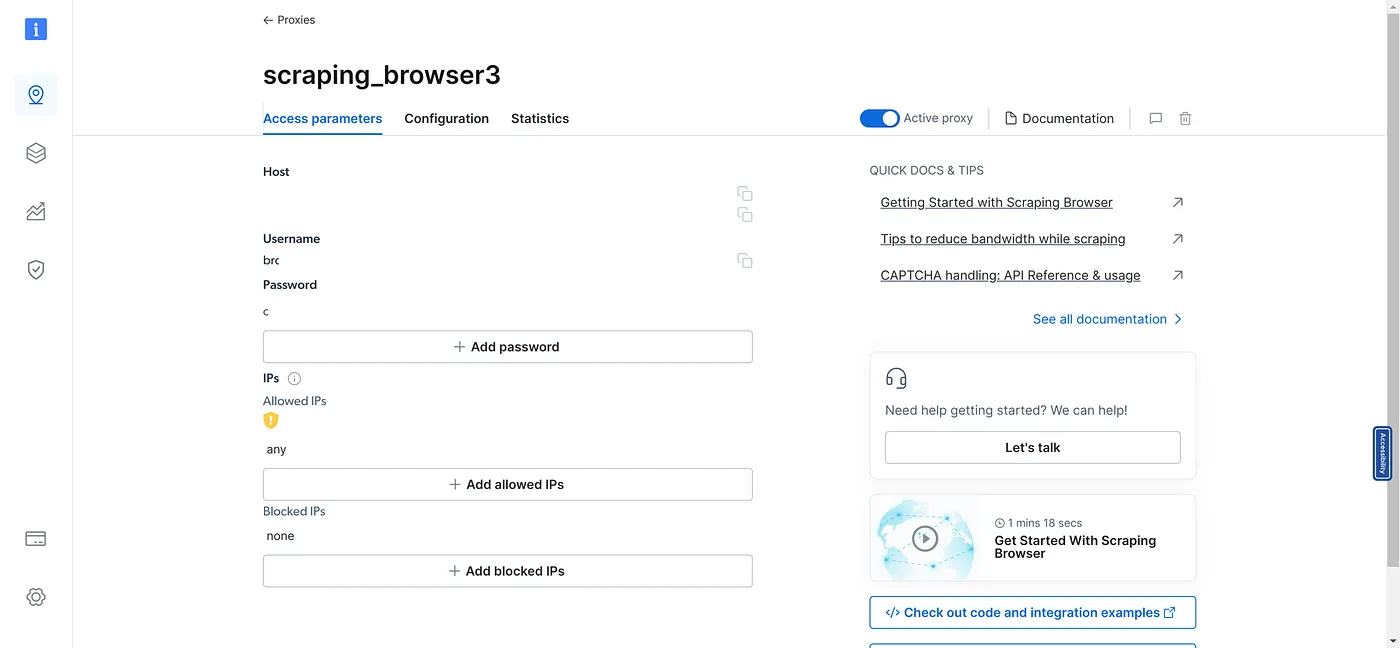
Copy the username, host, and password, and save it in a safe place for now.
The Code
Integrating the scraping browser for bypassing Cloudflare is pretty simple. To do so, first, initialize an empty folder with npm by running npm init -y. This will initialize the folder, as well as create a new package.json file. Now, install two dependencies:
- Puppeteer: It is a tool to control Chrome or Chromium over the DevTools protocol.
- Dotenv: It loads environment variables from a .env file into process.env.
To install the packages, simply run the following command:
npm i puppeteer dotenv
Once the installation is complete, create a new file called .env in the folder, and paste the keys you copied earlier from the Bright Data dashboard. The ENV file should look like this:
BD_HOST=YOUR_HOST
BD_USERNAME=YOUR_USERNAME
BD_PASSWORD=YOUR_PASSWORD
Now create a new file called main.js and paste the following code to it:
import puppeteer from "puppeteer";
import dotenv from "dotenv";
dotenv.config();
const SBR_URL = `wss"//${process.env.BD_USERNAME}:${process.env.BD_PASSWORD}@${process.env.BD_HOST}`;
async function scrapeProducts(url) {
const browser = await puppeteer.launch({
browserWSEndpoint: SBR_URL,
});
try {
console.log("Connected to browser...");
const page = await browser.newPage();
await page.goto(url);
const products = await page.evaluate(() => {
const items = Array.from(
document.querySelectorAll(".product-grid**card")
);
return items.map((item) => {
const title = item.querySelector(".product-card**title")?.innerText;
const link = item.querySelector(".product-card**link-overlay")?.href;
const imageUrl = item.querySelector(".product-card**hero-image")?.src;
const price = item.querySelector(".product-price")?.innerText;
return { title, link, imageUrl, price };
});
});
console.log(products);
await browser.close();
} catch (error) {
console.error("Error scraping the product", error);
await browser.close();
}
}
scrapeProducts("https://www.nike.com/w/usa-10ciy");
The code here is straightforward. A function called scrapeProducts() is defined which scrapes the product listing from a website, Nike in this case. For Puppeteer to connect with the scraping browser, you'll need a WebSockets connection. The WebSocket link, assigned to the variable SBR_URL, is constructed using the username, password, and host details obtained from the Bright Data dashboard. The link is formatted as follows:
const SBR_URL = wss://YOUR_USERNAME:YOUR_PASSWORD@YOUR_HOST;
The function begins by launching a new Puppeteer browser instance with the puppeteer.launch() method. The browserWSEndpoint option is set to SBR_URL to use the scraping browser. Once the browser is launched, a new page is opened with browser.newPage(), and the browser navigates to the provided URL with page.goto(url).
The page.evaluate() method is then used to run JavaScript within the context of the page. This method returns a Promise that resolves to the return value of the page function. In this case, the page function selects all elements with the class .product-grid__card, converts the NodeList to an array, and maps over each item to extract the product details.
The product details are logged to the console and the browser is closed with browser.close(). If any errors occur during this process, they are caught with a try/catch block, and logged to the console.
The code here visits this URL and scrapes the products from the page.
At this point, if you weren't using the Scraping Browser (with its in-built unlocker mechanism and proxy network), you'd likely run into Cloudflare's anti-bot mechanism which would generate a CAPTCHA or any other IP blocking mechanism that we discussed above. The Scraping Browser allows us to seamlessly bypass this.
Now, running the script using node main.js will give you the output of the results in the console.
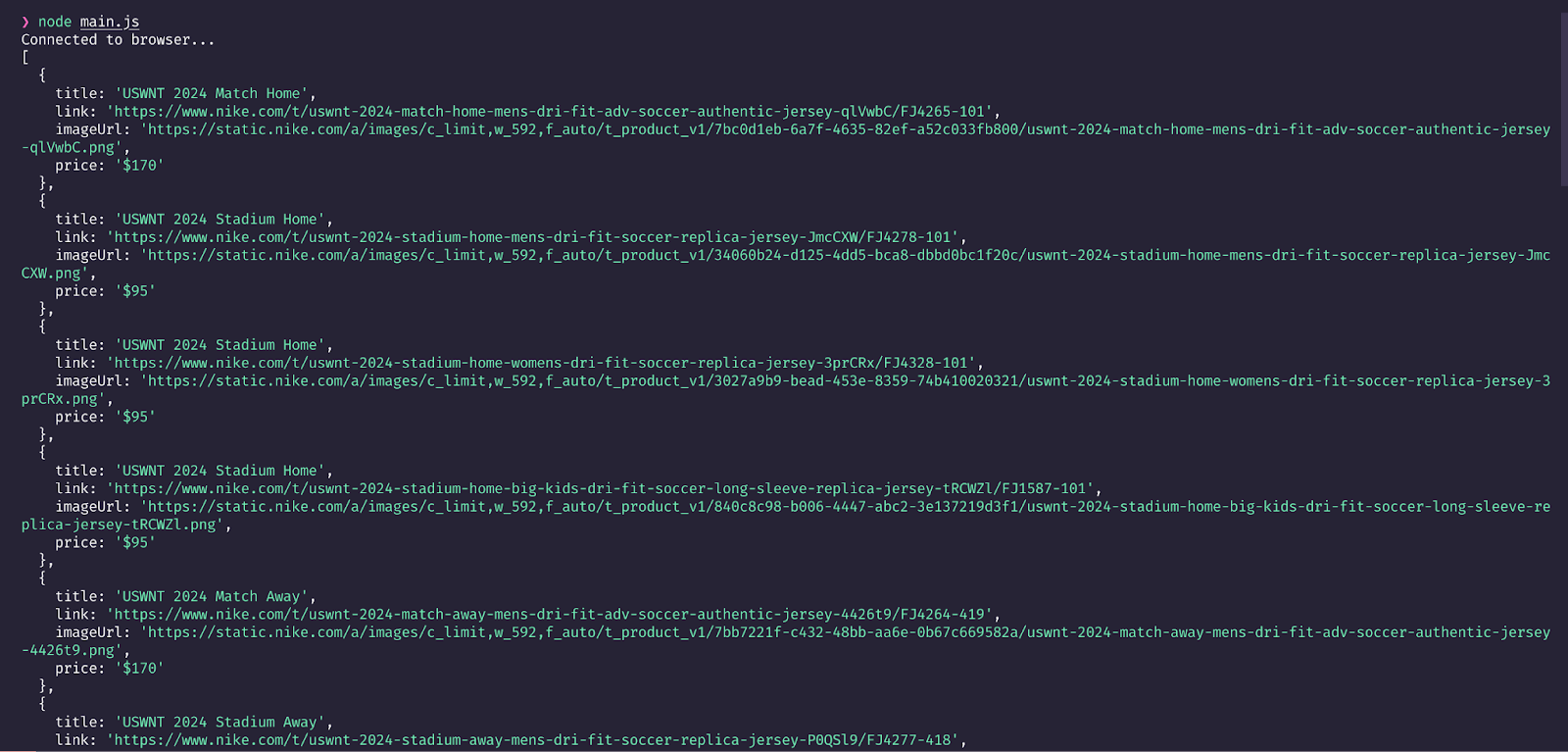
As you can see from the screenshot shown above, our script visits the website provided, and scrapes details like the title of the item, link, image URL, and price. It creates an array of objects and prints them.
Setting up the Scraping Browser is straightforward. With just a few basic steps, you're up and ready to get around Cloudflare's anti-bot system. Earlier, we explored several built-in features of the Scraping Browser. Thanks to its unlocker technology and automatic proxy management, you can bypass Cloudflare's protection and collect this data in an uninterrupted manner, at scale.
Conclusion
With cybersecurity and data protection becoming increasingly important, expect more websites to take up Cloudflare's services in the coming years. This is a good thing, as websites do need to ensure that the data on there is well-protected from dangerous attacks.
However, as we've seen, this can also pose significant challenges to legitimate web scraping attempts. In this article, we looked at the measures Cloudflare makes use of as part of its anti-bot detection technology and how a tool like the Scraping Browser can help bypass them all at once, without having to invest separately to take care of each and every mechanism used by Cloudflare.
Moreover, the Scraping Browser's unlocker infrastructure is not just effective against Cloudflare but also other anti-scraping measures used by websites in general. It comes with a free trial so I'd suggest checking it out to see if it fits your use case.
Scraping Browser --- Build Unblockable Scrapers with Puppeteer, Playwright, and Selenium *Integrate Bright Data's browser with your scraping scripts to outsmart bot-detection software and avoid website...*brightdata.com
Whether you're a business or a developer looking for a reliable, efficient, and ethically compliant web scraping solution, the Scraping Browser is the tool you need for data extraction at scale, with zero-to-low infra.
Comments
Loading comments…