
Photo by Alexander Shatov on Unsplash
Introduction
In today's fast-paced digital landscape, where gathering valuable data-driven insights has become imperative to grow your business, social media has emerged as a crucial platform --- the very heartbeat of our daily lives. Here, people willingly share their thoughts, opinions, and experiences, making social media a treasure trove of public data.
By scraping social media and extracting relevant data from platforms like Facebook, YouTube, Instagram, Twitter and more, you open up new possibilities for understanding behavior and market trends.
Here are a couple of scenarios where collecting information from a platform like YouTube can be helpful:
- Knowing customer opinions: Imagine your company has just launched an exciting new product and shared a captivating video showcasing its features on YouTube. By scraping YouTube comments, you can gain valuable insights into how users perceive and review your product.
- Influencer marketing: You can find your target audience by analyzing your niche's YouTube channels to advertise your product. This way, you can decide where to put your money.
Such data from YouTube can be extracted using Python with the help of the Playwright automation library. However, the conventional approach to web scraping encounters numerous obstacles, making it a messy and less feasible option for scaling the process in real-life scenarios.
In this article, we will first delve into some of the challenges that arise during the data scraping process when using a traditional approach. And then we will see how we can bypass these challenges and scrape data from YouTube in a seamless manner using Python along with Bright Data's Scraping Browser --- a Playwright/Puppeteer/Selenium-compatible headful, GUI browser that comes with built-in advanced scraping technology right out of the box.
By the end of this article, you will have the knowledge and tools to navigate the complexities of social media data extraction and leverage it to gain crucial insights for elevating your business strategies.
Obstacles to Scraping Social Media Sites
Typically, when gathering data from a website, you start by understanding the HTML structure of the website. Then you find the location of the needed information on the webpage. After that, you will begin writing the scripts in Python using common frameworks such as Selenium, Beautiful Soup or Playwright. The process doesn't stop. Even though social media platforms provide enormous amounts of data for businesses to plan their operations, specific blocking mechanisms are in place to prevent data exploitation. Some of these are:
- Blocking IP Address: Some platforms block your IP address when you quickly make multiple automated requests from the same IP address. The website may flag the IP address as harmful if it detects unusual traffic patterns.
- Rate Limiting: When the number of requests exceeds a certain threshold, the website rate limits the requests to prevent the abuse of their servers.
- Block Requests Based on Headers: Websites can block requests from specific sources based on headers like User-Agent and Referrer. If these headers seem suspicious or not legitimate, the website may take action to prevent the request.
- CAPTCHAs: Another common way to stop abnormal activities is to ask the user to solve a CAPTCHA before navigating to the website content. This step ensures that it is an actual human act, not an automated bot.
- Usage of Honeypots: Certain online platforms incorporate a sneaky component into their website's source code which is not visible to users, but web scrapers can interact with it. If your script comes across this trap, the website will become suspicious of the activity and impose restrictions on the web scraper.
You must take extra measures to address these barriers on your own. This can be a messy, difficult and resource-draining process, requiring you to invest in additional infrastructure for proxies and then implement additional logic in your code (which still might not be foolproof and in need of constant updates).
However, there is a solution that simplifies the task significantly making for a seamless data extraction process --- Bright Data's Scraping Browser.
Bright Data's Scraping Browser: A Scalable Solution
Bright Data's Scraping Browser, a headful GUI browser that is fully compatible with Puppeteer/Playwright/Selenium APIs, is a powerful and efficient tool simplifying data scraping projects. It comes built-in with Bright Data's powerful unlocker infrastructure and premium proxy network, allowing it to bypass the previously-mentioned obstacles right out of the box.
It adeptly handles website blocks, CAPTCHAs, fingerprints, and retries, functioning like a real user to avoid detection. Along with that, the Scraping Browser also offers many other features and benefits that makes web scraping more reliable and saves users time, money, and resources.
Learn more about the powerful functionalities of the Scraping Browser: Scraping Browser - Automated Browser for Scraping
Configuring the Scraping Browser
To use the Scraping Browser:
-
Sign up for a free trial on Bright Data's website. You can do so by clicking on "Start free trial" or "Start free with Google". You can proceed to the next step if you have an existing account.
-
From the dashboard, Navigate to the "Proxy and Scraping Infrastructure" section and Click on the "Add" button, then select "Scraping Browser" from the dropdown menu.
-
Enter a name of your choice in the form to create a new Scraping Browser.
💡 Note: You can also refer to the instructions in the documentation.
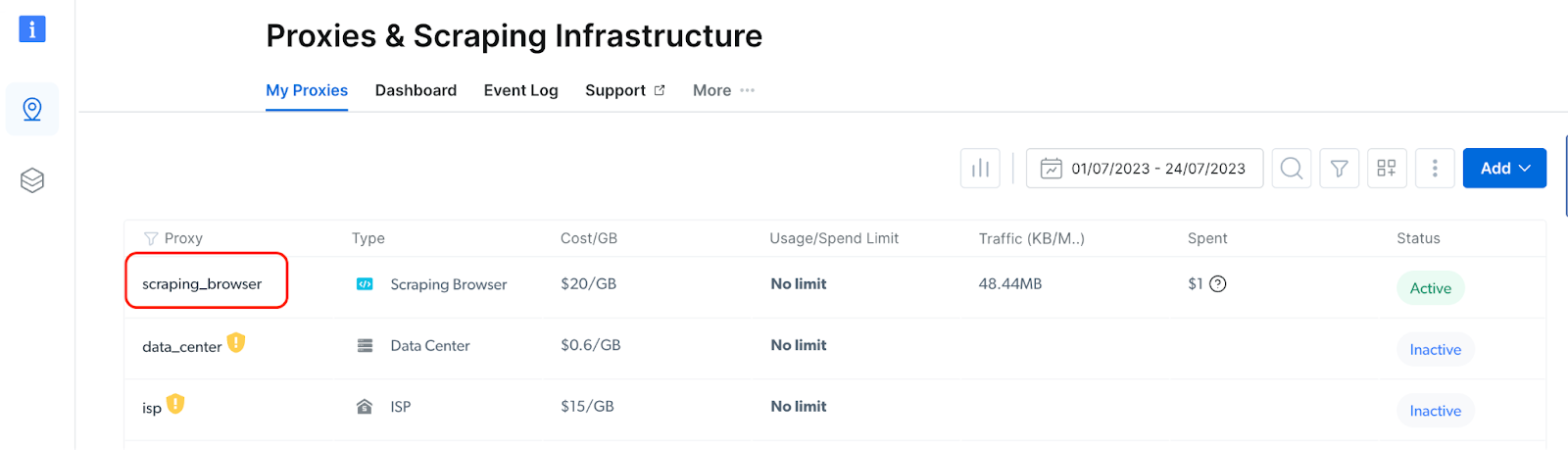
- After creating a new Scraping Browser instance, click on its name, and navigate to "Access Parameters" to access the hostname, username, and password information.
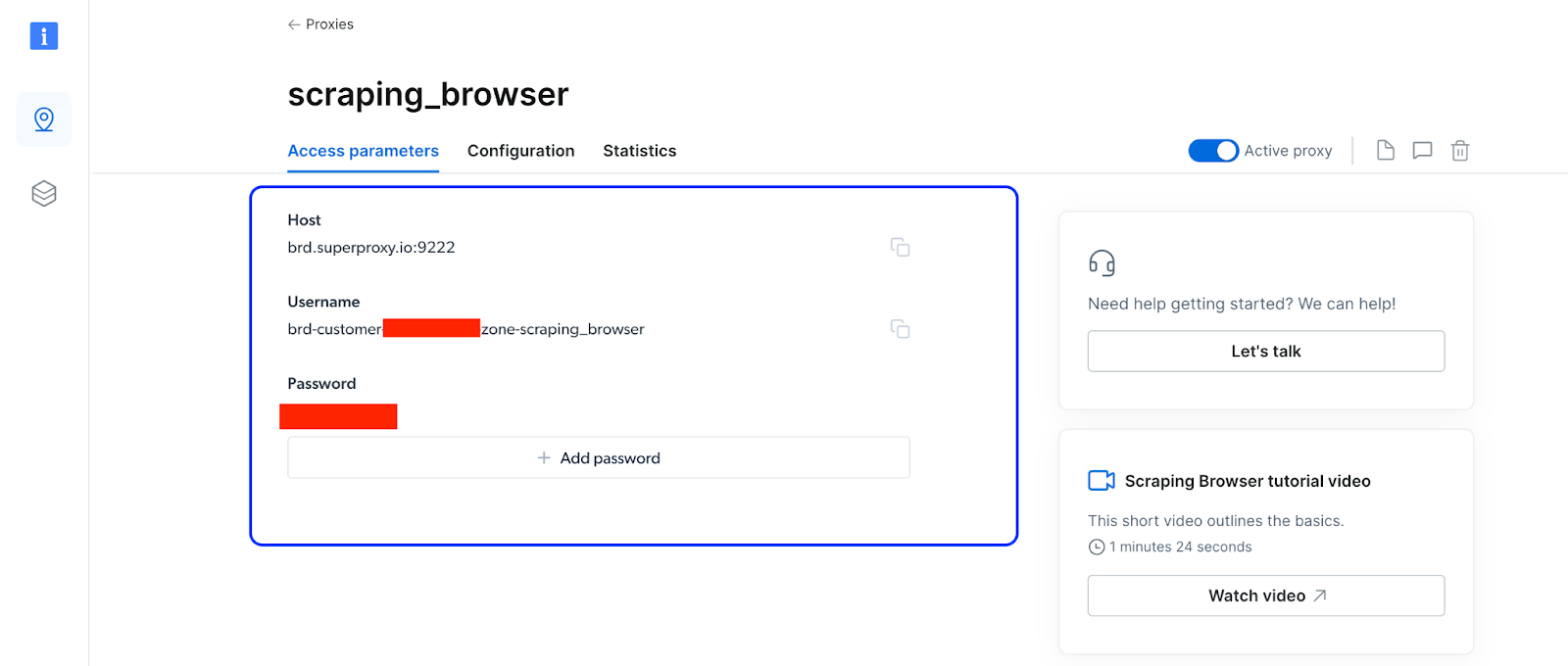
- You can use these parameters in the following Python script to access the Scraping Browser instance.
How to Analyze YouTube Comments and Gain Insights about a Product
Let us consider that you are working for a company and want to know how people perceive your product. You go ahead by scraping the comments of a YouTube video which specifically reviewed your product and analyze it to arrive at some metrics.
We'll look into a similar example here, and you are going to explore the review of the iPhone 14 to know people's opinions.
Prerequisites
- Please ensure that your computer already has Python installed.
- Install the necessary packages in your project folder. You'll use the Playwright Python Library and Pandas to get insights from the data. To make asynchronous requests, install the Asynchronous IO library. You will use NLTK and WordCloud Libraries to analyze the retrieved comments.
Extracting the YouTube Video Comments
- Start by extracting the comments of the iPhone 14 review video.
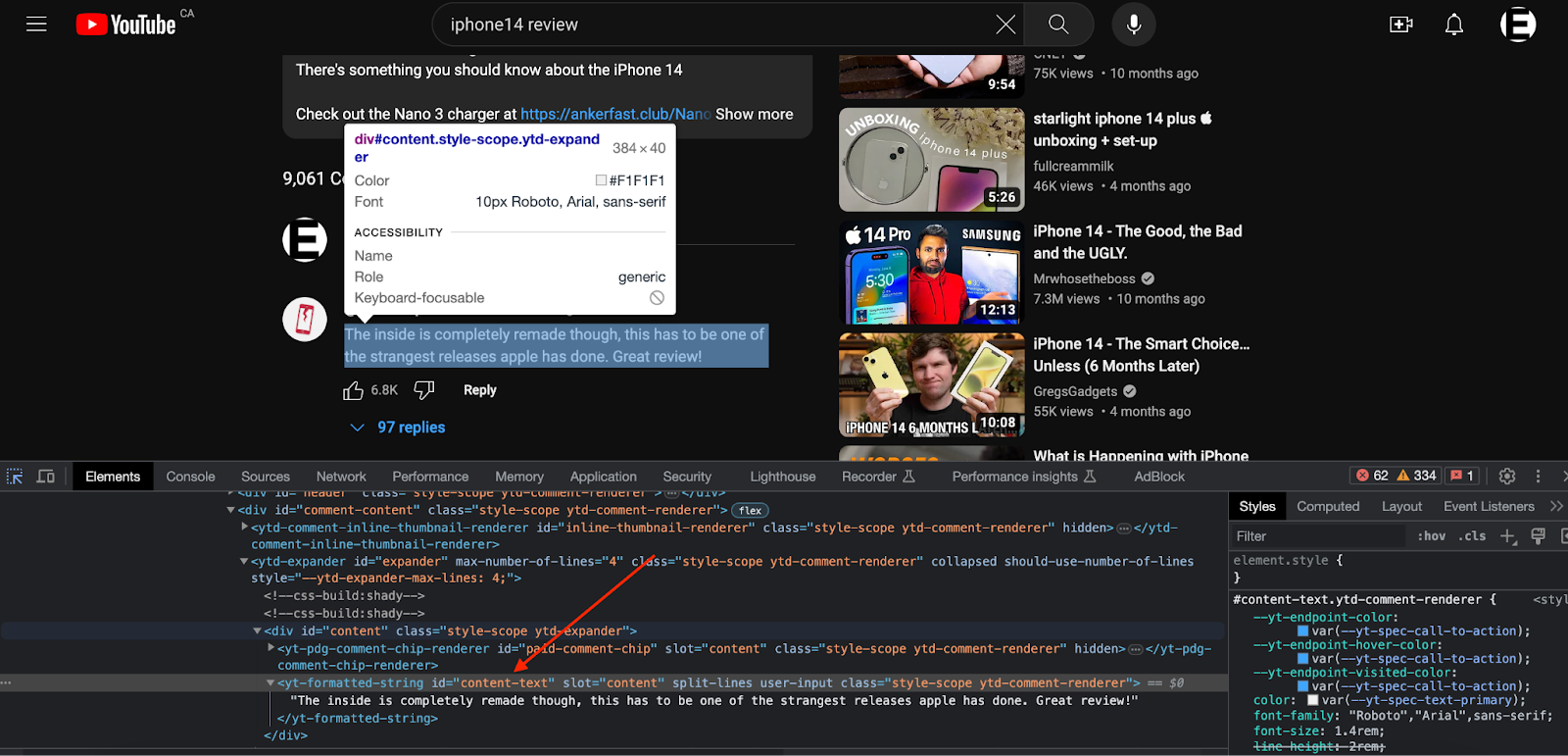
- Import the necessary Python libraries in your Python Script and create a
get_comments()method to get the video list from the webpage.
async def get_comments():
async with async_playwright() as playwright:
auth = '<provide username here>:<provide password here>'
host = '<provide host name here>'
browser_url = f'wss://{auth}@{host}'
# Connecting to the Scraping Browser
browser = await playwright.chromium.connect_over_cdp(browser_url)
page = await browser.new_page()
page.set_default_timeout(3*60*1000)
# Opens the Youtube Video Page in the browser
await page.goto('https://www.youtube.com/watch?v=v94jRN2FhGo&ab_channel=MarquesBrownlee')
for i in range(2):
await page.evaluate("window.scrollBy(0, 500)")
await page.wait_for_timeout(2000)
await page.wait_for_selector("ytd-comment-renderer")
# Parse the HTML tags to get the Comments and likes
data = await page.query_selector_all('ytd-comment-renderer#comment')
comments = []
for item in data:
comment_div = await item.query_selector('yt-formatted-string#content-text')
comment_likes = await item.query_selector('span#vote-count-middle')
comment = {
"Comments": await comment_div.inner_text(),
"Likes": await comment_likes.inner_text()
}
comments.append(comment)
comment_list = json.loads(json.dumps(comments))
#Storing into the CSV file
with open("youtube_videos.csv", 'w', newline='') as csvfile:
writer = csv.DictWriter(csvfile, fieldnames=comment_list[0].keys())
writer.writeheader()
for data in comment_list:
writer.writerow(data)
#Converting CSV to a data frame for further processing
df = pd.read_csv("youtube_comments.csv")
await browser.close()
return df
- The
get_comments()method then works as follows:
- Start by connecting to Bright Data's Scraping Browser by using the credentials.
- Create a new page pointing to the video from which you want to retrieve the comments.
- Wait for the page to load and Identify the HTML div which encloses all the comments of the video (ytd-comment-renderer#comment)
- Iterate through each comment, extracting the content and the corresponding number of likes.
- Store these details in the file "youtube_comments.csv" in your working folder.
- Transform that CSV file contents into Pandas Dataframe for further processing.
This method generates the CSV file that contains the comment data.

What do people think about the product?
We're almost through! You have extracted the data from the YouTube Video. Next, let's dig into the insights provided by the data.
First, we need to gauge the number of individuals with a positive outlook on the product. As such, you'll be conducting a sentiment analysis of the videos with the aid of the widely-used Natural Language Processing NLTK library.
nltk.download("stopwords", quiet=True)
nltk.download("vader_lexicon", quiet=True)
def transform_comments(df):
#clean the comments
df["Cleaned Comments"] = (
df["Comments"].str.strip().str.lower().str.replace(r"[^ws]+", "",regex=True).str.replace("n", " "))
stop_words = stopwords.words("english")
df["Cleaned Comments"] = df["Cleaned Comments"].apply(
lambda comment: " ".join([word for word in comment.split() if word not in stop_words]))
#analyse the sentiment of each comment and classify
df["Sentiment"] = df["Cleaned Comments"].apply(lambda comment: analyze_sentiment(comment))
#Create a bar graph to understand the sentiments of people
sentiment_counts = df.groupby('Sentiment').size().reset_index(name='Count')
plt.bar(sentiment_counts['Sentiment'], sentiment_counts['Count'],color=['red', 'blue', 'green'])
plt.grid(axis='y', linestyle=' - ', alpha=0.7)
plt.show()
def analyze_sentiment(text):
sentiment_analyzer = SentimentIntensityAnalyzer()
scores = sentiment_analyzer.polarity_scores(text)
sentiment_score = scores["compound"]
if sentiment_score <= -0.5:
sentiment = "Negative"
elif -0.5 < sentiment_score <= 0.5:
sentiment = "Neutral"
else:
sentiment = "Positive"
return sentiment
In the above code, you are cleaning the comments to eliminate any whitespace, special characters and newlines.
Then, you remove the common English stopwords, which don't contribute much to the sentiment analysis.
After that, the sentiment of each comment is calculated and added as a new column in the data frame.
Finally, you create a bar graph which visually classifies the comments as "Positive", "Negative" and "Neutral."
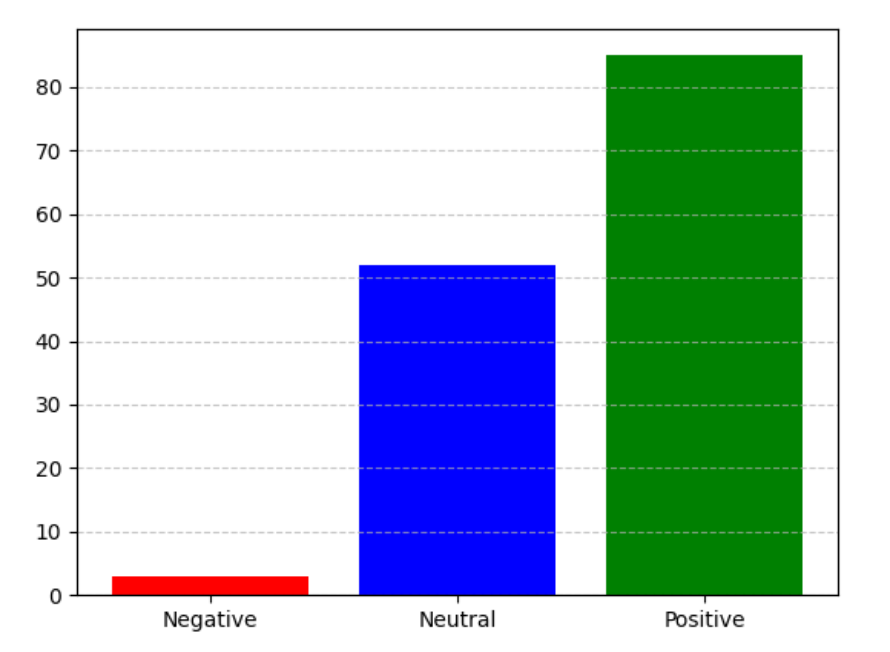
According to the sentiment analysis results, many individuals hold a positive view of the product.
Which features of the product do people find most appealing?
You're interested in discovering the aspects of the product talked about by people, which is the next intriguing piece of information you're searching for. A helpful way to achieve this is by creating a word cloud using comments. The word size in the word cloud represents the frequency of the word in the comments.
def generate_word_cloud(df):
comments = "n".join(df["Comments"].tolist())
wordcloud = WordCloud().generate(comments)
This code will create a word cloud from the YouTube Comment.

Looking into WordCloud, you can find the features talked about by people, apart from the common ones like iPhone, phone and Apple. People also spoke about display, model, camera, battery, and screen.
If you want to focus on more specific insights, you can utilize filters in the Pandas data frame based on exact keywords such as "Camera" or "Battery." By conducting a sentiment analysis and creating a word cloud from this data, you can uncover insights explicitly tailored to those features.
How Bright Data's Scraping Browser Handled the Obstacles
As you may have observed, I should have used additional techniques to overcome the challenges mentioned earlier. Instead, I leveraged Bright Data's Scraping Browser to act as my website browser. Surprisingly, the Scraping Browser took on all the problematic aspects of the job for me. It has several inherent features that can effortlessly eliminate obstacles on websites. Let us look into those benefits.
- Unlimited Browser Sessions: You can launch as many browser sessions as you need on the Bright Data network without any concerns about blocked requests. Furthermore, you have the flexibility to scale the extraction process by running multiple browser sessions simultaneously. This powerful tool empowers you to access the data you need hassle-free, without restrictions or interruptions.
- Leave Network Infrastructure Worries Behind: You can entirely rely on Bright Data's network infrastructure for all your data retrieval needs. Thereby, you can focus on the web scraping process without worrying about server allocation and maintenance issues.
- Proxy management: Thanks to its efficient built-in proxy management capabilities that makes use of four different types of IPs (including powerful residential IPs), the IP address is automatically switched up, ensuring that web scraping runs smoothly without any interruptions as it handles bot detection measures of websites, and avoids geolocation restrictions and rate-limiting.
- Robust Unlocker Mechanism: The Scraping Browser makes use of Bright Data's powerfulunlocker infrastructure to bypass even the most complex bot detection measures; from handling CAPTCHAs to device fingerprint emulation to managing header information and cookies, it takes care of it all.
💡 Learn more about how the unlocker infrastructure enables uninterrupted scraping at scale and bypasses even the most sophisticated anti-scraping measures here.
- Integration with Existing Libraries: Bright Data provides excellent integration support for existing Python libraries. With the Scraping Browser, configuring the browser connection is all you need to do without any modifications to the rest of your script.
Conclusion
Considering social media's growing importance in gathering information and customer insights, it's crucial for your business to extract public data accurately and efficiently at scale.
In this article, we focused on extracting and analyzing comments from a YouTube product review video to gain a deeper understanding of customer perceptions.
To streamline the data extraction process and overcome the inherent challenges associated with web scraping, we made use of Bright Data's Scraping Browser --- a powerful and efficient tool designed to tackle various obstacles such as CAPTCHAs and IP blocks faced during data retrieval. Moreover, its seamless integration with existing Python libraries like Playwright simplifies the setup process and enables smooth implementation within scripts.
By utilizing Bright Data's Scraping Browser in combination with Python, you can gather valuable information about customers, products, and the market, allowing your business to use data-driven strategies and informed decision-making in a scalable and cost-effective manner.
Sign up for a free trial of the Scraping Browser today to see for yourself what a difference it can make in your company's data gathering process.
Comments
Loading comments…