A Comprehensive Guide to Extracting Data from Google Jobs Listings Seamlessly While Bypassing IP Bans.
How to Scrape Data from Google Jobs Listings
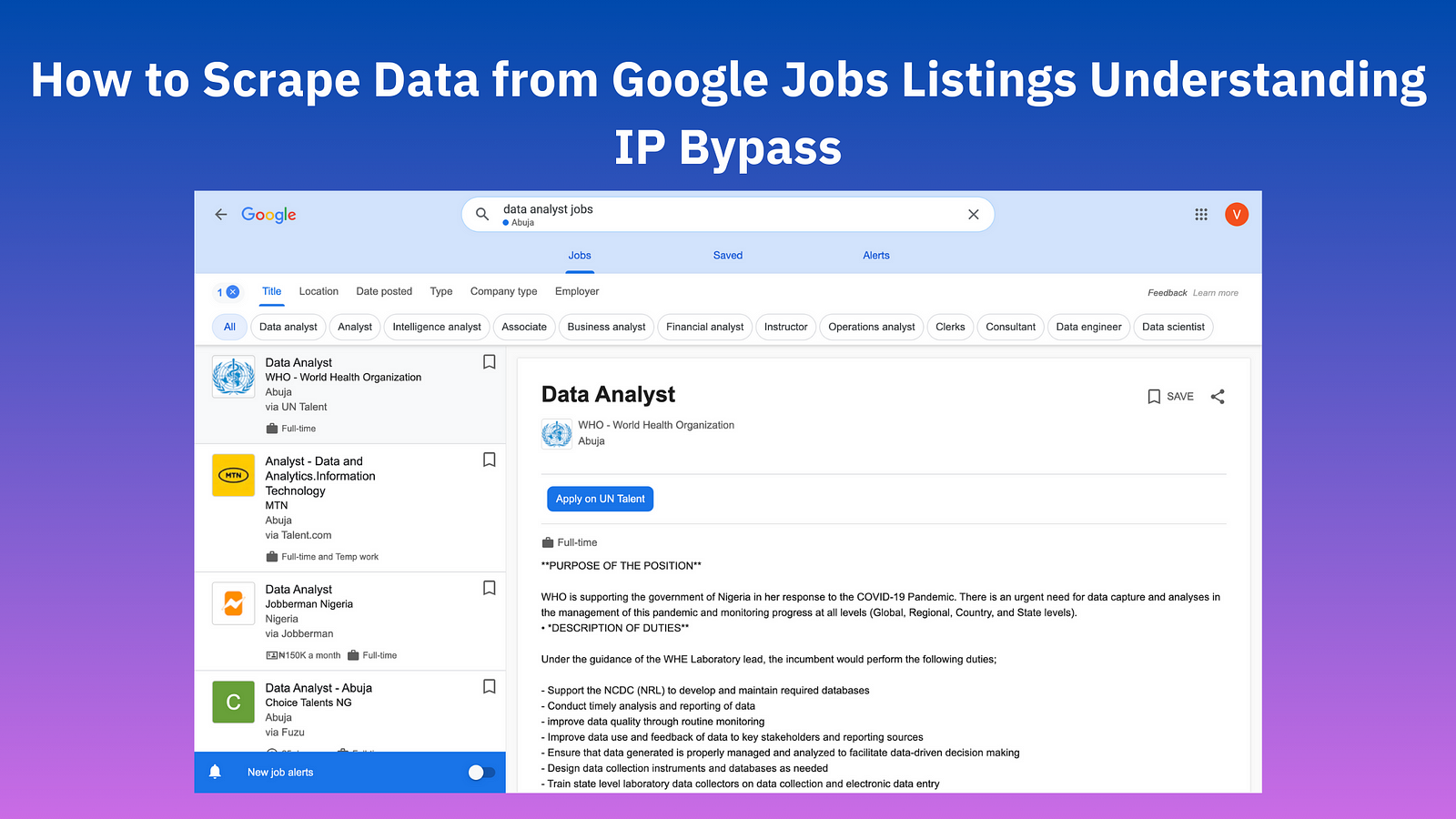
One of the most comprehensive sources of job listings is Google Jobs, a platform that aggregates job openings from various sources worldwide, making it an invaluable resource for anyone looking to navigate the job market or someone trying to build a job listing website. To get a list of job listings that fit your requirements, especially at scale, you will need to scrape Google jobs by just writing a script, doing this will save you the stress and effort. Instead of manually going through different pages, and looking for a job that fits your requirements, you can simply write a script stating your requirements and only get jobs with those requirements.
However, scraping Google job listings comes with some challenges. Websites like Google employ anti-scraping measures to prevent illegal data collection, a common measure is IP blocks. So in this article, we will walk through a step-by-step guide on how to scrape Google jobs listings and how to bypass IP blocks using the Scraping Browser - a Playwright/Puppeteer/Selenium-compatible headful, fully GUI browser that comes with advanced block-bypassing technology - which makes it easy to extract data from websites such as Google.
Understanding the Importance of IP Bypass in Web Scraping
Web scraping, a powerful tool for extracting data from websites, has become an essential skill for businesses and developers alike. However, when it comes to scraping data from Google Jobs, a platform that aggregates job listings from various sources, the task becomes significantly more complex due to the platform's robust anti-scraping mechanisms. These mechanisms are designed to protect Google's data from being scraped by bots, and they include IP blocks, CAPTCHAs, and advanced tracking techniques that can detect and block suspicious activities.
IP Blocks
One of the most common challenges faced by web scrapers is IP blocks. When a website detects unusual activity from a single IP address, such as an excessive number of requests in a short period, it may temporarily or permanently block that IP address. This is a common defense mechanism used by websites to prevent data scraping and protect their resources. For Google Jobs, which is a highly trafficked platform, scraping activities can easily trigger these IP blocks, making it difficult for scrapers to access the data they need.
Bypassing IP Blocks
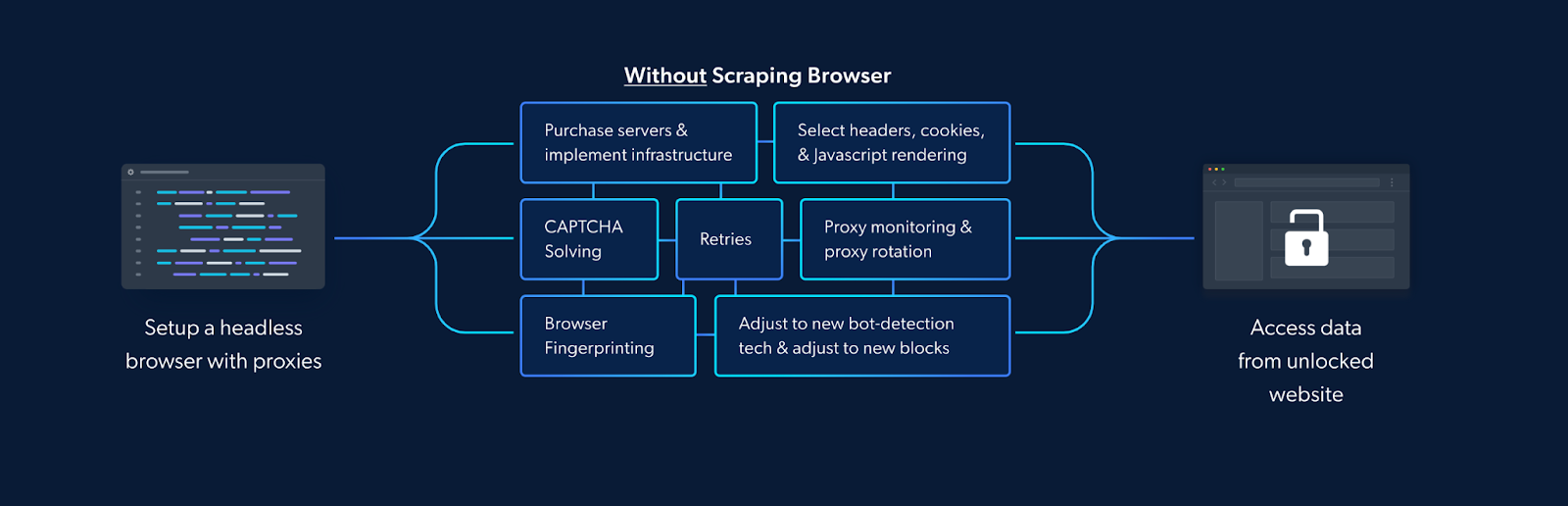
To bypass IP blocks, scrapers often use proxy servers (there are other methods for bypassing IP bans). A proxy server acts as an intermediary between the scraper and the target website, routing the scraper's requests through a different IP address. This can help avoid detection and IP blocks by making the scraping activities appear as if they are coming from multiple users rather than a single source. However, simply using a proxy server may not be enough. Scrapers must also implement IP rotation, which involves changing the IP address used for each request to the target website. But all of this can increase reliance on third-party services and add to your infrastructural costs.
In this article, we will introduce a comprehensive solution for web scraping that goes beyond traditional proxy providers. Bright Data's Scraping Browser is a robust tool that combines both unblocking and proxy management technologies in one integrated platform. Unlike standalone proxy providers, the Scraping Browser offers a foolproof solution that streamlines the scraping process by providing a complete package for efficient data extraction from Google Jobs Listings while ensuring IP bypass and data security.
With the Scraping Browser, you get a tool that:
- Comes with block-bypassing technology right out of the box.
- Ensures ethical compliance with major data protection laws.
- Can be easily integrated with existing Puppeteer/Playwright/Selenium scripts.
Let's look into some more details regarding how the Scraping Browser works and then we'll set it up and scrape Google Jobs listings.
Step-by-Step Guide for Scaping Data from Google Jobs Listings Using the Scraping Browser
Tools and Setup
The Scraping Browser comes with built-in IP bypassing technology. This is because the Scraping Browser makes use of Bright Data's powerful unlocker infrastructure and proxy network (which includes four different types of proxy services from over 195 countries) which means it arrives with block-bypassing technology right out of the box. This allows it to mimic real users' behavior and it makes sure your scraping efforts don't get flagged or noticed.
It eliminates the need for you to handle numerous third-party libraries that deal with tasks such as proxy and fingerprint management, IP rotation, automated retries, logging, or CAPTCHA solving internally. The Scraping Browser handles all these and more on Bright Data's server-side infrastructure. It's also fully compatible with Puppeteer/Playwright/Selenium APIs and several programming languages.
The Scraping Browser also comes with the convenience of a real fully GUI browser, meaning that it can parse all JavaScript and XHR requests on a page, giving you the dynamic data you need.
The unlocker technology automatically configures relevant header information (such as User-Agent strings) and manages cookies according to the requirements of the target website so that you can avoid getting detected and banned as a "crawler". Meanwhile, Bright Data's proxy management services allow you to automate IP rotation between four different kinds of proxy services.
💡Note: From IP Ban to CAPTCHA-solving to User-agent generation to cookie management and fingerprint emulation, Bright Data's unlocker infrastructure can bypass even the most sophisticated anti-scraping measures. Learn more here.
Bright Data's unlocker infrastructure Is a managed service, meaning that you don't have to worry about updating your code to keep up with a website's ever-changing CAPTCHA generation and IP blocking mechanisms. Bright Data takes care of all of that for you, handling the updates and maintenance on their end.
Scraping Browser - Build Unblockable Scrapers with Puppeteer, Playwright, and Selenium *Integrate Bright Data's browser with your scraping scripts to outsmart bot-detection software and avoid website...*brightdata.com
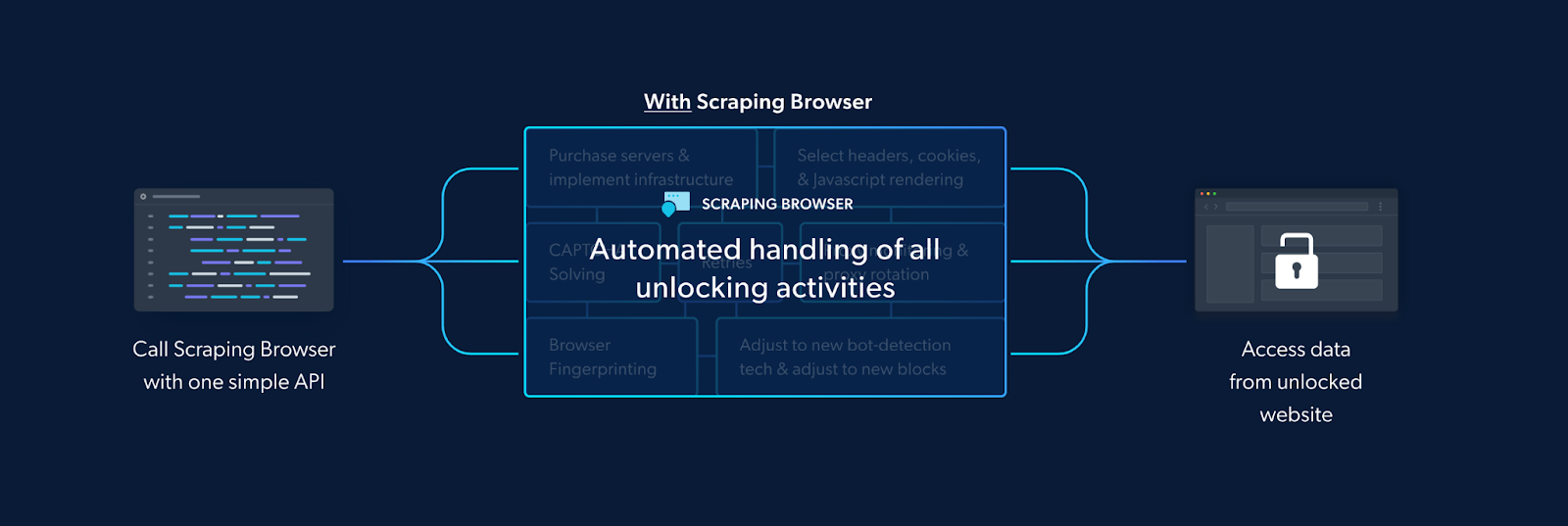
All these ensure that the Scraping Browser easily overcomes the challenges we mentioned earlier. In addition to that, it is highly scalable, allowing you to scale unlimited sessions using a simple browser API, saving infrastructure costs. This is particularly beneficial when you need to open as many Scraping Browsers as you need without an expansive in-house infrastructure.
With all that said, let's now dive into setting up the Scraping Browser and our Puppeteer script and scrape Google Jobs Listings.
Getting Started with the Scraping Browser
The goal here is to create a new proxy with a username and password, which will be required in our code. You can do that by following these steps:
- Signing up - go to Bright Data's homepage and click on "Start Free Trial". If you already have an account with Bright Data, you can just log in.
- You will be redirected to a welcome page once you sign in after entering your details and finishing the signup process. There, click on "View Proxy Products".
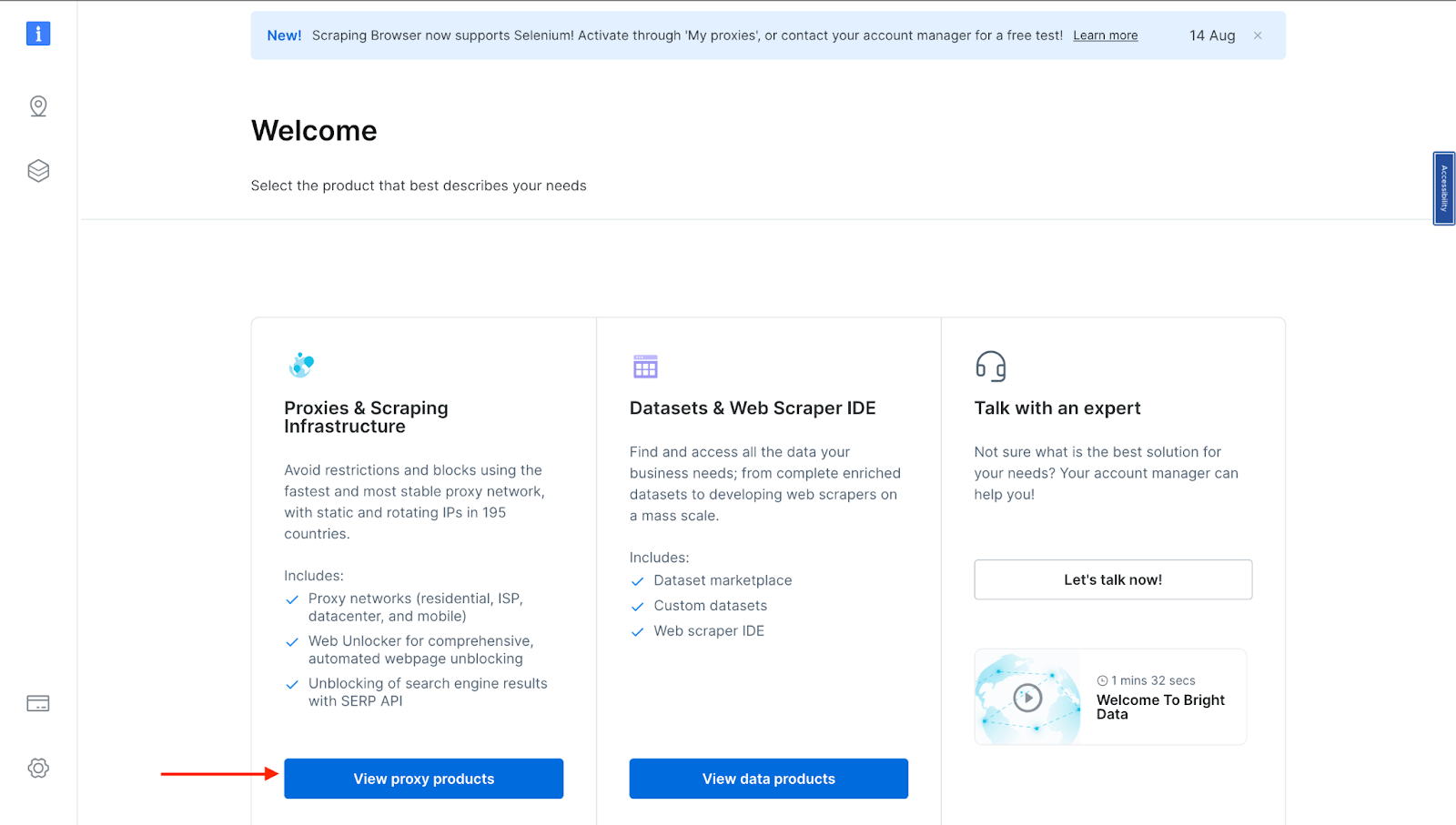
- You will be taken to the "Proxies & Scraping Infrastructure" page. Under "My proxies," click on "Get started" in the Scraping Browser card.
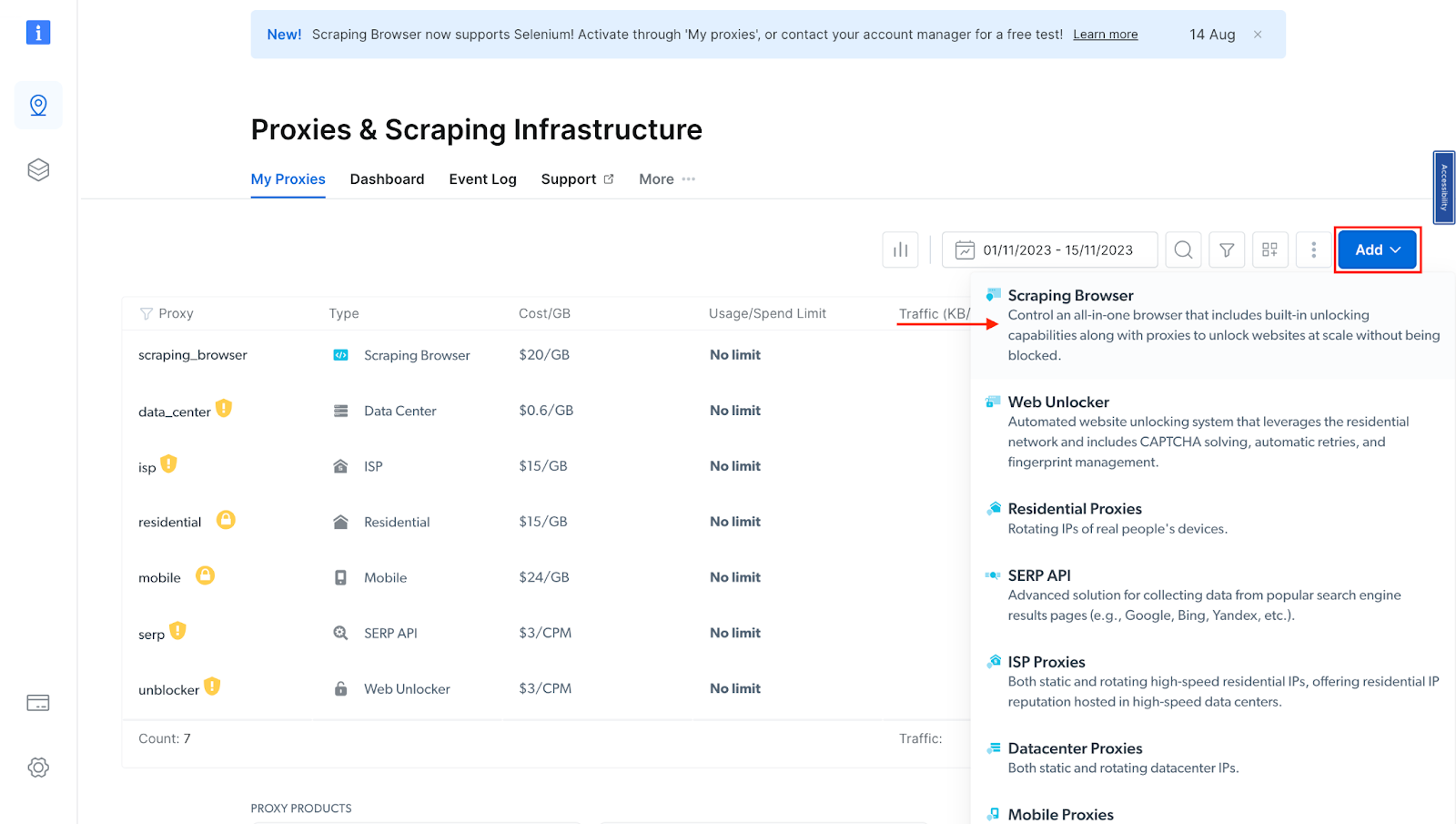
If you already have an active proxy, click "Add" and select "Scraping Browser."
- Next, you will be taken to the "Add new proxy solution" page, where you will be required to choose a name for your new scraping browser proxy zone. After that, click on "Add".
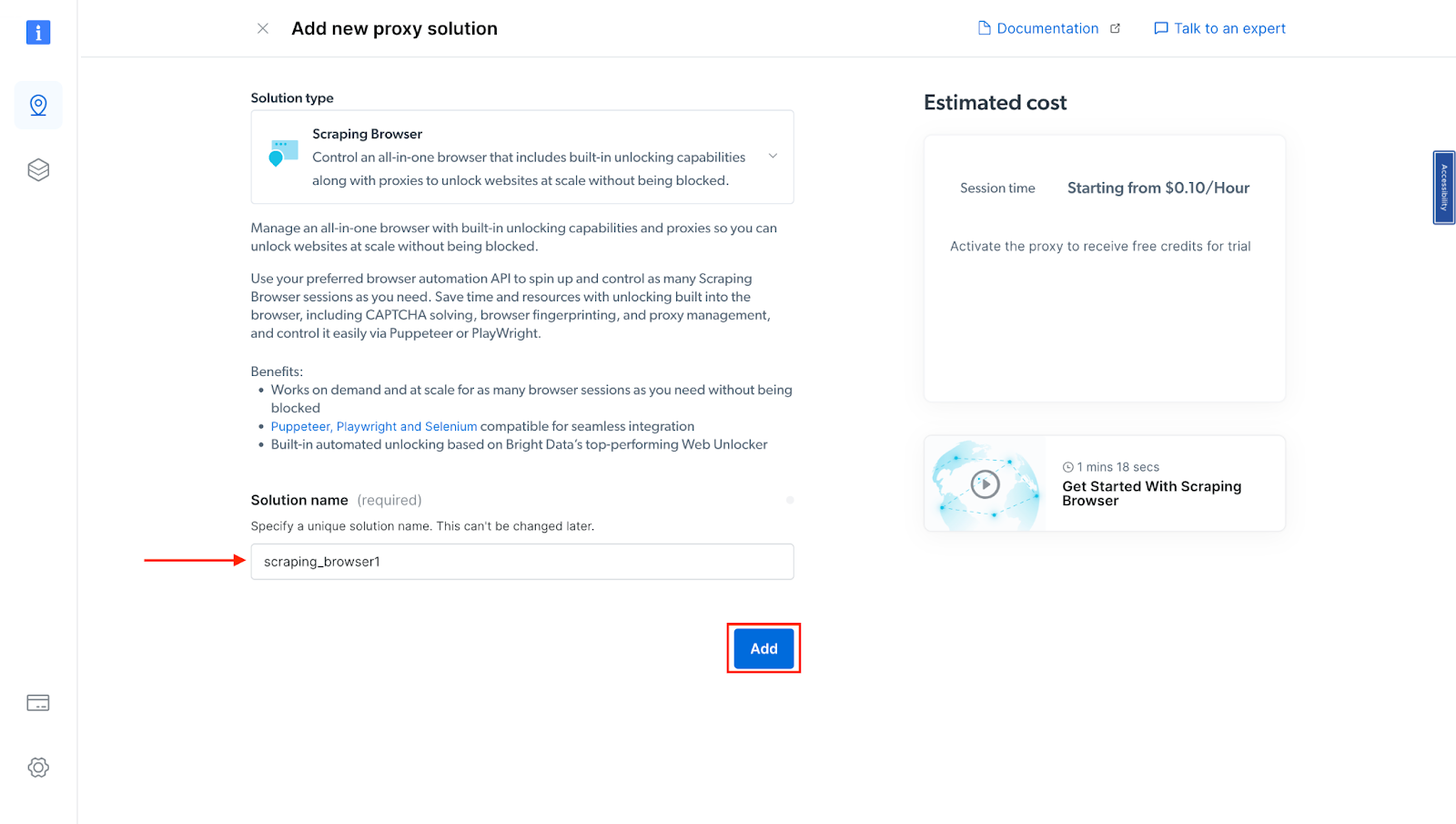
- At this point, if you haven't yet added a payment method, you'll be prompted to add one to verify your account. As a new user of Bright Data, you'll receive a $5 bonus credit to get you started.
NB: This is mainly for verification purposes, and you will not be charged at this point
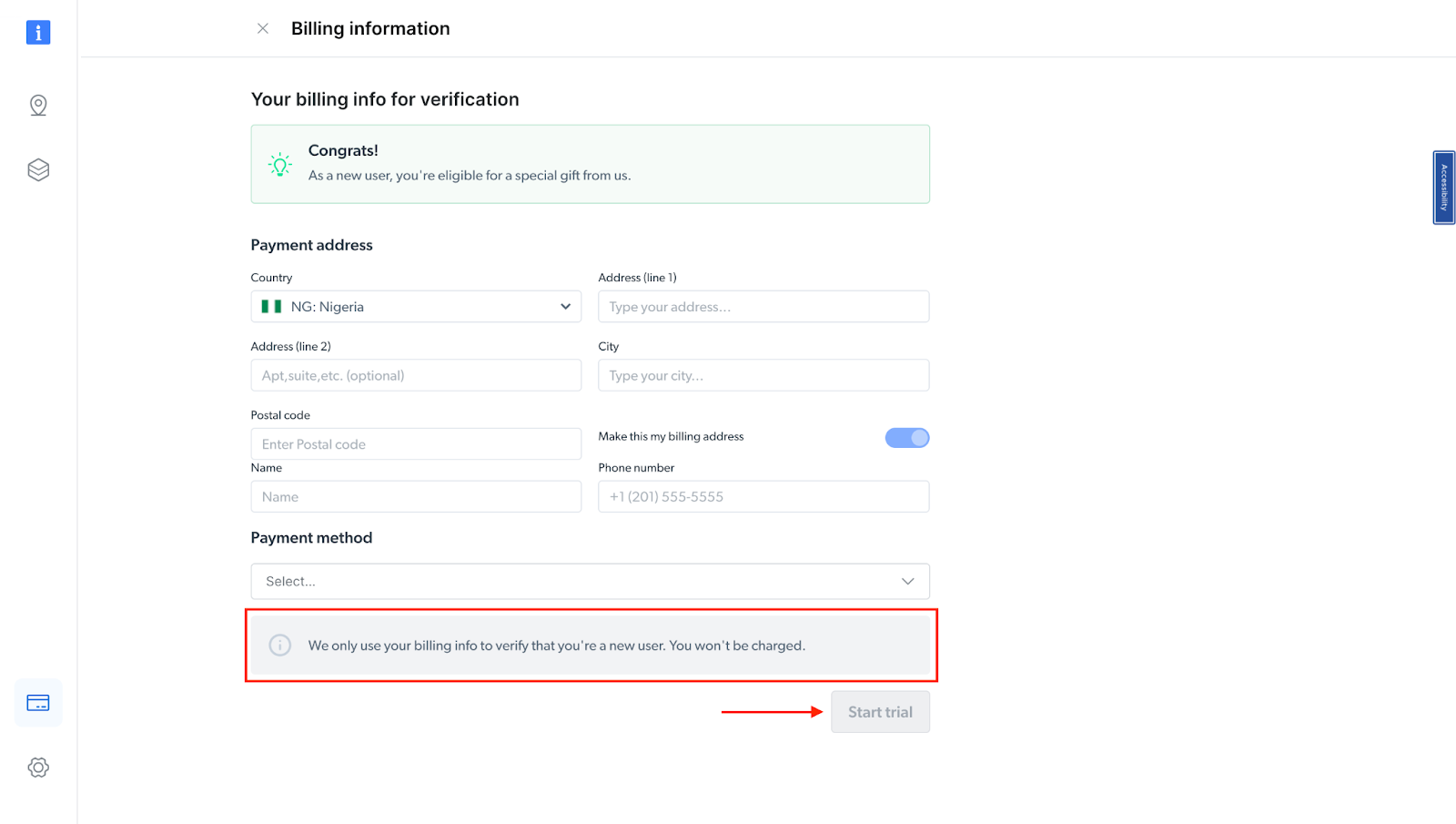
- After verifying your account, your proxy zone will be created.
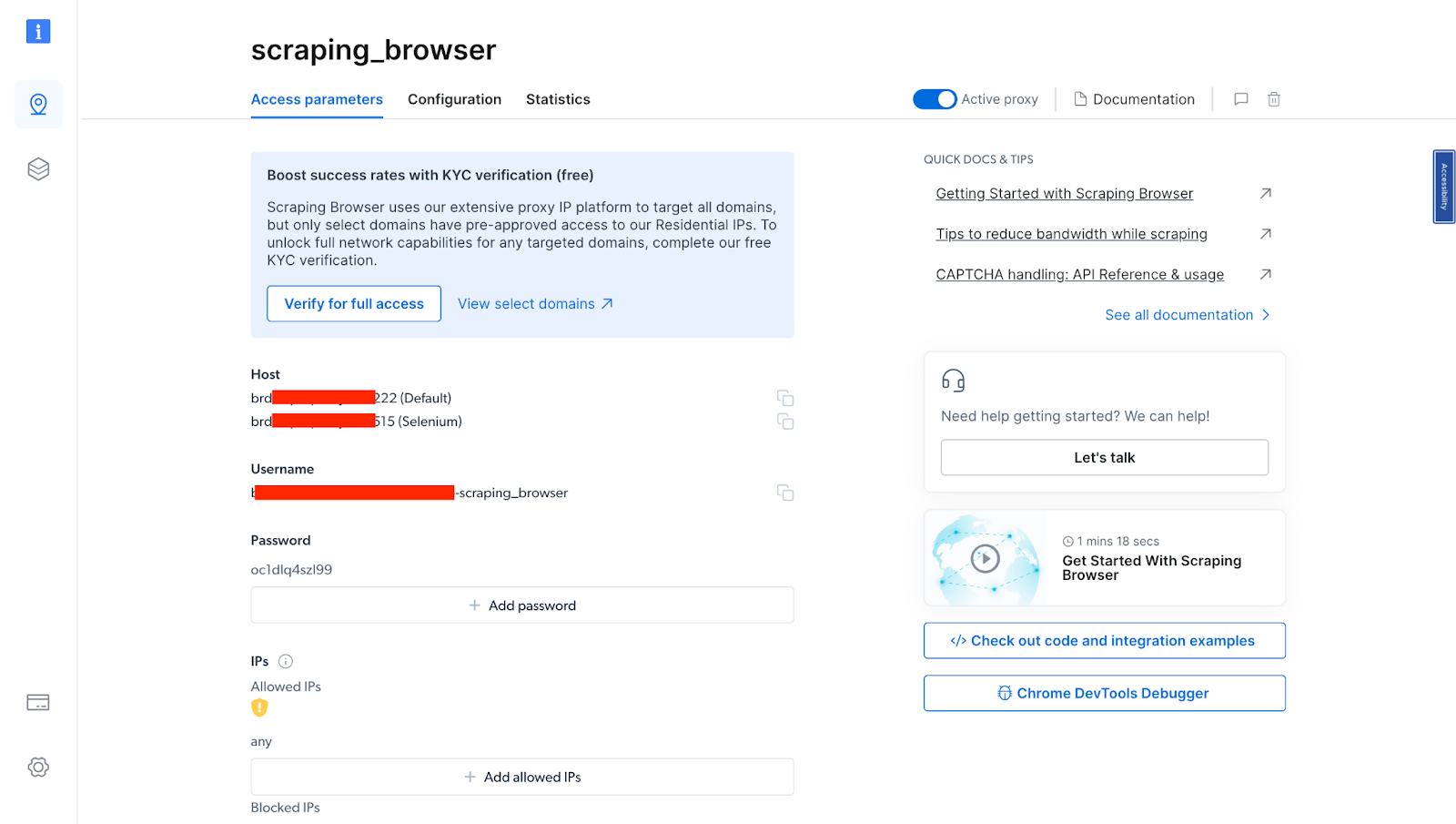
You will need these details in your code in the next section. So you either copy them down or leave the tab open.
Scraping Google Jobs Listings with the Scraping Browser
Before we start writing our Puppeteer script, it's important to understand the structure of the website we're scraping. For this example, we'll be scraping the Google Jobs Listings website. Google is a dynamic website with dynamic classes that uses JavaScript to load and display data, making it a great candidate for our Puppeteer script.
Node.js and Puppeteer: Installation and Configuration
To follow this tutorial, you must set up the necessary files/folders and install the required module before proceeding with the code.
- Installing Node.js: To check if you have Node.js already installed on your computer run the command below
node -v
If you don't have Node installed, you can download it here.
- After setting up Node.js, create a new folder for your project. You can do this by running the
mkdircommand followed by the folder name in your terminal/command prompt. Then navigate to the project folder using the cd command.
mkdir my-googlejobs-scraper cd my-googlejobs-scraper
- Initialize a new Node.js project in the folder by running the command
npm init.
npm init -y
- Next, install Puppeteer using the command below:
npm install puppeteer
- Install
json2csv(used to convert JSON response to a CSV file) using this command below
npm install json2csv
- Open the project folder using the code editor of your choice.
Now that you have set up your project, you can create your scraper.
Writing the Puppeteer Script
👉 Task: The task here is to write a script that will go to the Google Jobs Listings URL, and extract the lists of jobs from the URL. So, in this case, we want to get the Job title, location, and company name, so you will need to locate the element IDs that hold these pieces of information. Here is the process:
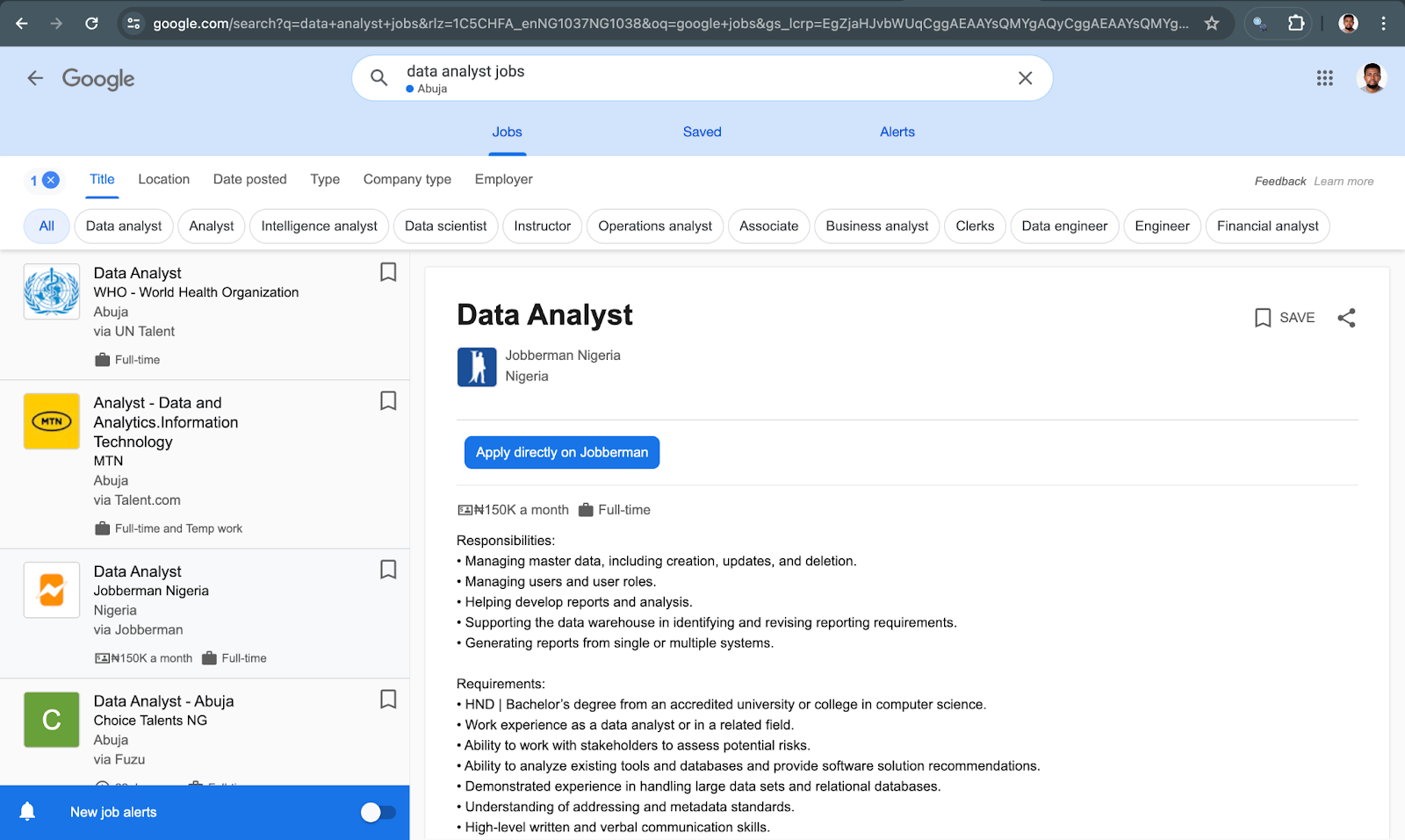
The next step is to inspect the page and get the ID of each element you want to gain access to. You can use the selectorgadget Chrome extension for that.

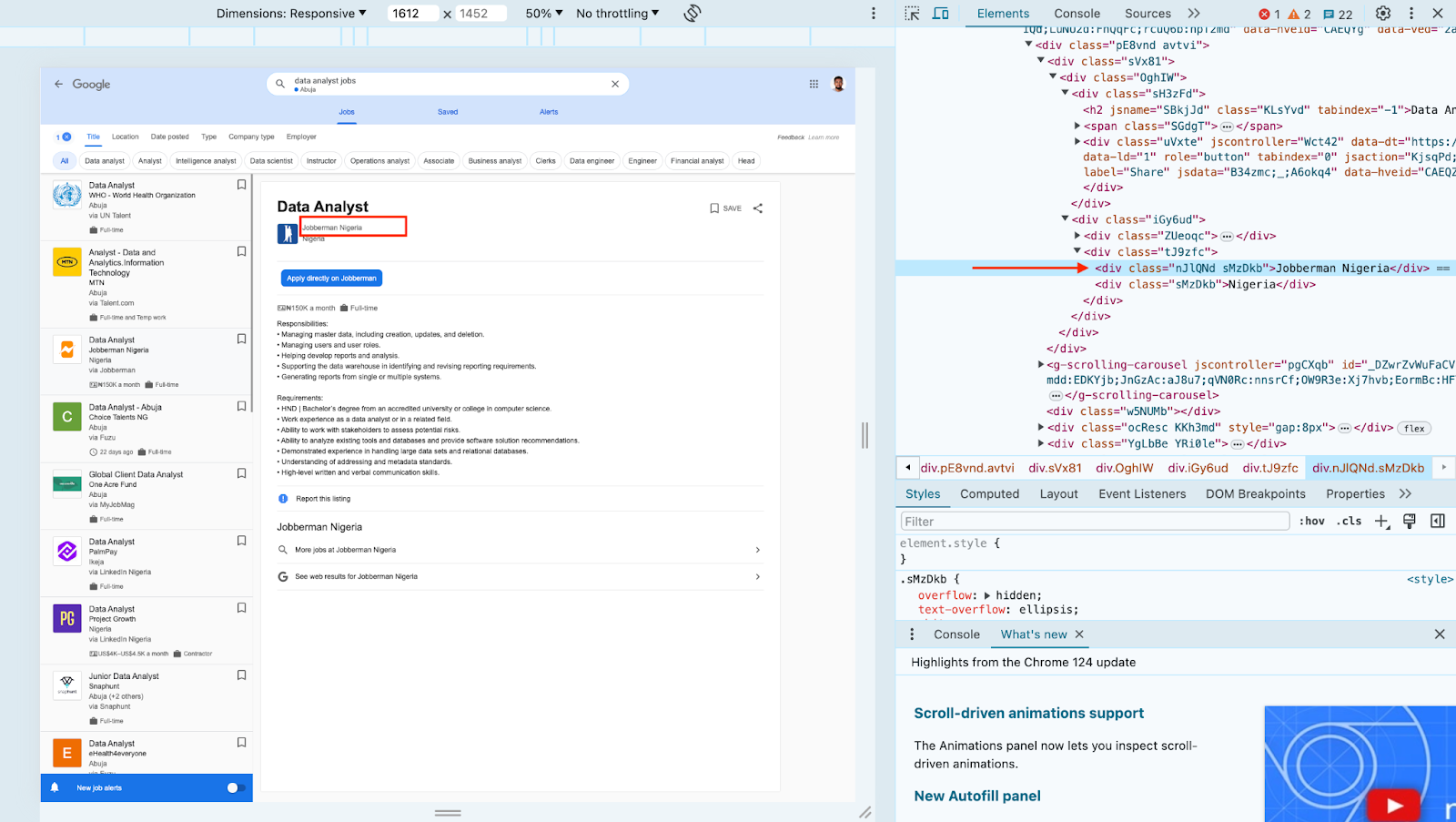

After identifying your element IDs, in your project folder create a script.js file. Inside the script proceed to implement the code to scrape the Jobs listings page.
const puppeteer = require("puppeteer");
const { Parser } = require("json2csv");
const fs = require("fs");
const auth = "<your username>:<your password>";
const SBR_URL = `wss://${auth}@zproxy.lum-superproxy.io:9222`;
(async () => {
const browser = await puppeteer.launch({
browserWSEndpoint: SBR_URL,
headless: false,
});
const page = await browser.newPage();
const url = await page.goto(
"https://www.google.com/search?q=data+analyst+jobs&rlz=1C5CHFA_enNG1037NG1038&oq=google+jobs&gs_lcrp=EgZjaHJvbWUqCggAEAAYsQMYgAQyCggAEAAYsQMYgAQyBwgBEAAYgAQyBwgCEAAYgAQyBwgDEAAYgAQyBwgEEAAYgAQyBwgFEAAYgAQyBwgGEAAYgAQyBwgHEAAYgAQyBwgIEAAYgAQyBwgJEAAYgATSAQg0NzA3ajBqN6gCALACAA&sourceid=chrome&ie=UTF-8&ibp=htl;jobs&sa=X&ved=2ahUKEwit--bdqNuFAxU6TkEAHfR5D3EQudcGKAF6BAgdEBY#fpstate=tldetail&htivrt=jobs&htilrad=-1.0&htidocid=w7hI9K9nZW2iHu9eAAAAAA%3D%3D"
);
await new Promise((r) => setTimeout(r, 20000));
await page.waitForFunction(() =>
document.querySelectorAll("div[data-share-url]")
);
const jobListings = await page.evaluate(() => {
const jobDivs = Array.from(
document.querySelectorAll("div[data-share-url]")
);
return jobDivs.map((div) => {
const jobTitleElement = div.querySelector(".KLsYvd");
const companyNameElement = div.querySelector(".nJlQNd.sMzDkb");
const jobLocation = div.querySelector(".tJ9zfc");
const jobTitle = jobTitleElement ? jobTitleElement.innerHTML : "N/A";
const companyName = companyNameElement
? companyNameElement.innerHTML
: "N/A";
const location = jobLocation
? jobLocation.getElementsByClassName("sMzDkb").item(1).innerHTML
: "N/A";
return { jobTitle, companyName, location };
});
});
console.log(jobListings);
// Autoscroll function
await page.evaluate(async () => {
await new Promise((resolve) => {
let totalHeight = 0;
const distance = 100;
const timer = setInterval(() => {
const scrollHeight = document.body.scrollHeight;
window.scrollBy(0, distance);
totalHeight += distance;
if (totalHeight >= scrollHeight) {
clearInterval(timer);
resolve();
}
}, 100);
});
});
// Convert JSON to CSV
const json2csvParser = new Parser();
const csv = json2csvParser.parse(jobListings);
// Save CSV to a file
fs.writeFile("jobListings.csv", csv, (err) => {
if (err) throw err;
console.log("The file has been saved!");
});
await browser.close();
})();
Here is a breakdown of what the script does:
- Imports necessary libraries: The script starts by importing the necessary libraries. It uses
Puppeteer,json2csv, andfsto interact with the file system. - Defines authentication details: It defines a constant auth which holds the username, password, and proxy host for the scraping browser. Replace
<your username>:<your password>with your own scraping browser details - Connects to the browser: The run function is defined as an asynchronous function. Inside this function, it connects to a browser instance using Puppeteer's connect method. The
browserWSEndpointoption is set to a WebSocket URL, which includes the authentication details and the address of the proxy service. - Browser and Page Setup:
const page = await browser.newPage(): After connecting to the browser, it opens a new page in the browser.page.setDefaultNavigationTimeout(2 * 60 * 1000);and a default navigation timeout of 2 minutes is set - Navigating to the Page: It navigates to a Google Jobs search page for data analyst jobs.
- Waiting for Content: Before scraping, it waits for a certain amount of time (20 seconds in this case) to ensure that the page has fully loaded, including any dynamically loaded content.
- Extracting Job Listings: It then uses
page.evaluate()to execute JavaScript within the context of the page. This function selects job listing elements (div[data-share-url]) and extracts details such as job title, company name, and location. - Autoscroll Function: It scrolls down the page by a specified distance (100 pixels in this case) until the total height scrolled is greater than or equal to the scroll height of the document. This triggers the loading of more job listings.
- Converting JSON to CSV: The Parser object from
json2csvis used to parse the JSON data into CSV format. - Saving to File: The
fs.writeFile()method is used to write the CSV data to a file. - Closes the browser: Finally, the script ensures that the browser is closed, even if an error occurs during the execution of the script.
Here is the output:

The extracted dataset in the image above provides a structured overview of job listings obtained from Google. Each row in the dataset represents information about a specific hotel, including:
- JobTitle: The role the company is hiring for.
- companyName: The name of the company hiring.
- Location: The city or area where the company is situated.
So depending on your needs, you can extract more data, handle more complex situations, or use more advanced techniques. This is just an example to show that with the right tools, the process of scraping can be easy and straightforward.
Conclusion
The ability to easily scrape data off Google Jobs Listings opens up a world of possibilities. With this data, individuals can keep track of job listings they are interested in and use the data to create a job board application that others can also benefit from.
This article explored how to scrape Google Job listings using the Scraping Browser tool from Bright Data. This tool simplifies the process by handling complexities such as dynamic content, cookies, and sessions, and bypassing anti-scraping measures.
It is designed to bypass IP bans, handle dynamic content, manage cookies and sessions effectively, and other anti-scraping measures. It provides a more efficient and straightforward way to scrape data from such websites, allowing you to get the data you want without getting banned or blocked.
If you're interested in learning more about how Bright Data's Scraping Browser can help you with your web scraping tasks, you can sign up for a free trial and explore what the Scraping Browser has to offer.
Comments
Loading comments…