
Photo by Towfiqu barbhuiya on Unsplash
In the rapidly evolving digital landscape, the extraction of valuable data from the internet has become a vital tool for businesses and researchers alike. Web scraping enables organizations to gather pertinent information, gain insights, and make informed decisions to stay competitive in their respective domains.
However, as data-driven approaches have grown in popularity, concerns about data privacy and ethical problems have also come to the forefront. Unethical scraping practices can not only damage your reputation but also lead to severe legal ramifications and damage your company's relationship with users and website owners.
However, striking a delicate balance between scraping data for legitimate reasons, and respecting the rights and privacy of data sources is a skill that is often overlooked.
In this article, we'll unravel the complex landscape of data privacy, underscoring the significance of adhering to ethical standards when accessing publicly available online data. Alongside that, we'll take a look at Bright Data's Scraping Browser, a Puppeteer/Playwright/Selenium-compatible advanced scraping solution that not only streamlines web scraping at scale, but also empowers you to do it responsibly, and while being legally compliant.
Let's dive in.
Understanding Ethical Concerns Regarding Web Scraping
In recent years, data privacy has become a hot-button issue, with several high-profile incidents raising public awareness about the misuse of personal information. As a result, governments worldwide have introduced stricter data protection laws, such as the General Data Protection Regulation (GDPR) in Europe and the California Consumer Privacy Act (CCPA) in the United States.
Web scraping, if not carried out responsibly, can inadvertently violate these regulations. Violating terms of service agreements or scraping copyrighted or personal data without consent may result in lawsuits, fines, and damaged reputations.
Here are some unethical scraping practices to be wary of:
- Aggressive Scraping: Extracting large amounts of data at excessive rates from the same IP, can overwhelm the web server with a large number of requests in a short period. Servers have limited resources to handle incoming requests, and aggressive scraping can lead to server overload, making the website slow or even unresponsive for legitimate users.
- Ignoring Robots.txt Directives: Disregarding the guidelines set forth in a website's robots.txt file, which serves as a standard for web crawlers. Ignoring these directives reveals a lack of respect for website owners' wishes regarding the scope and frequency of data extraction, potentially resulting in strained relationships and heightened security measures.
- Unauthorized Access: Scraping data from websites that explicitly forbid or limit access, contravening terms of service agreements. Such unauthorized scraping disregards the rules set by website administrators, raising ethical concerns and exposing the scraper to legal consequences for violating intellectual property rights and contractual obligations.
- Scraping Sensitive Information: Extracting personally identifiable information, financial data, or copyrighted content without obtaining proper consent or adhering to privacy regulations. Unethical scraping practices that involve harvesting sensitive data can lead to severe privacy breaches, damage to reputation, and potential legal actions.
- Web Scraping for Malicious Purposes: Using web scraping as a tool for engaging in unlawful activities, such as data theft, spamming, phishing, or disseminating misleading information. Malicious scraping undermines the trustworthiness of web data and can cause harm to individuals, businesses, and online communities.
- Unethically Procured Proxies: Proxies play a crucial role in web scraping as they allow users to route their requests through different IP addresses, providing anonymity, and enabling access to geographically restricted content. However, using unethically procured proxies can be detrimental to both the scraper and the data source, risking data security, and violation of laws, terms of service, and privacy regulations.
None of this means that it's illegal to scrape the web for data. It's worth remembering that as per the landmark ruling by the US Appeals Court in 2022, collecting publicly available data is perfectly legal and not in violation of the Computer Fraud and Abuse Act (CFAA).
However, in practice, the ethical and legal nature of web scraping can sometimes be a difficult question with no context-independent easy 'yes' or 'no' answer. This is why if data extraction is crucial to your project's operation, it may be worth going with a managed service that already takes care of these questions of ethical and legal compliance for you. This is exactly where Bright Data's Scraping Browser comes in.
Bright Data's Scraping Browser: An Ethically Compliant Low-Infra Solution
Bright Data's Scraping Browser is a headful, GUI browser that is fully compatible with Puppeteer/Playwright/Selenium APIs. It comes with sophisticated web unlocker technology right out of the box, allowing you to automate IP rotation (using Bright Data's powerful proxy network with its pool of ethically sourced residential and mobile IPs), automatically solve CAPTCHAs without requiring third-party libraries, and even get around bot detection measures like CloudFlare/HUMAN.
The Scraping Browser enables remote WebSocket connections (via the Chrome DevTools Protocol) from your local scraper to horizontally scaling headful, full-GUI browser instances hosted on Bright Data's own scalable infrastructure. This way, you reap the benefits of having as many parallel instances of full-fledged headful Chrome browsers as you want for your scraper, but without the need to set up and maintain any infrastructure for it.
For our purposes however, what is important is that the Scraping Browser makes use of Bright Data'srobust compliance system. The core of Bright Data's compliance system is built on three essential pillars --- deterrence, prevention, and enforcement. This three-tiered approach serves as the executive arm of Bright Data's commitment to maintaining a safe and ethical network. Let's take a look at how Bright Data ensures that your scraping operations remain ethically and legally compliant.
- Data Privacy Compliance: Bright Data is unwavering in its dedication to adhering to all relevant data protection laws, including Europe's General Data Protection Regulation (GDPR) and the California Consumer Privacy Act (CCPA) regulations, and making sure their approach to privacy fully comply with such regulations as well as industry best practices. Moreover, Bright Data is fully committed to respecting data subjects' rights and accommodating their requests to exercise control over their data.

- Transparency and Control for Website Owners: As part of its commitment to ethical data practices, Bright Data has developed innovative tools to maximize transparency and control for website owners. The Bright Data Webmaster Console and the collectors.txt file play a pivotal role in managing data interactions and defining specific site parameters.
- A KYC-first Approach: With a dedicated compliance officer and team, Bright Data performs ongoing log checks to ensure that traffic is consistent with the customer's declared use case. This ensures real-time compliance. To prevent any potential conflict of interest, the compliance department operates independently from the CEO. Every report of abuse is handled personally by the team, which includes researching, warning, and barring suspicious clients. You can learn more about Bright Data's KYC-first approach here.
- User Compliance Evaluation and Proxy Acquisition: As leaders in the IPPN market, Bright Data sets the highest standards of compliance in the proxy industry. All of Bright Data's Residential and Mobile IPs are acquired via full consent from its peers --- and they also have the right to opt out at any time. Every new Residential and Mobile IP customer undergoes a thorough vetting process and must be approved by a compliance officer. This rigorous onboarding procedure involves the submission of national identification and a signed compliance statement, among other identity verification techniques.
With all that said, let's now take a look at the Scraping Browser in action. We'll scrape the Hacker News front page using the Scraping Browser with Python.
Scraping the Hacker News Website Using the Scraping Browser and Python
Let us see a quick example to understand how easy it is to extract data from the Hacker News Website using the Scraping Browser. Let's try to retrieve the latest topics from the Hacker News website.
STEP 1: Sign up for a free trial on Bright Data Website if you don't have an existing account. Click on 'Start free trial' and enter your details.
STEP 2: Once you are logged in and see your Dashboard, go to 'View Proxy Products' and create a new Scraping Browser by following the steps listed here.
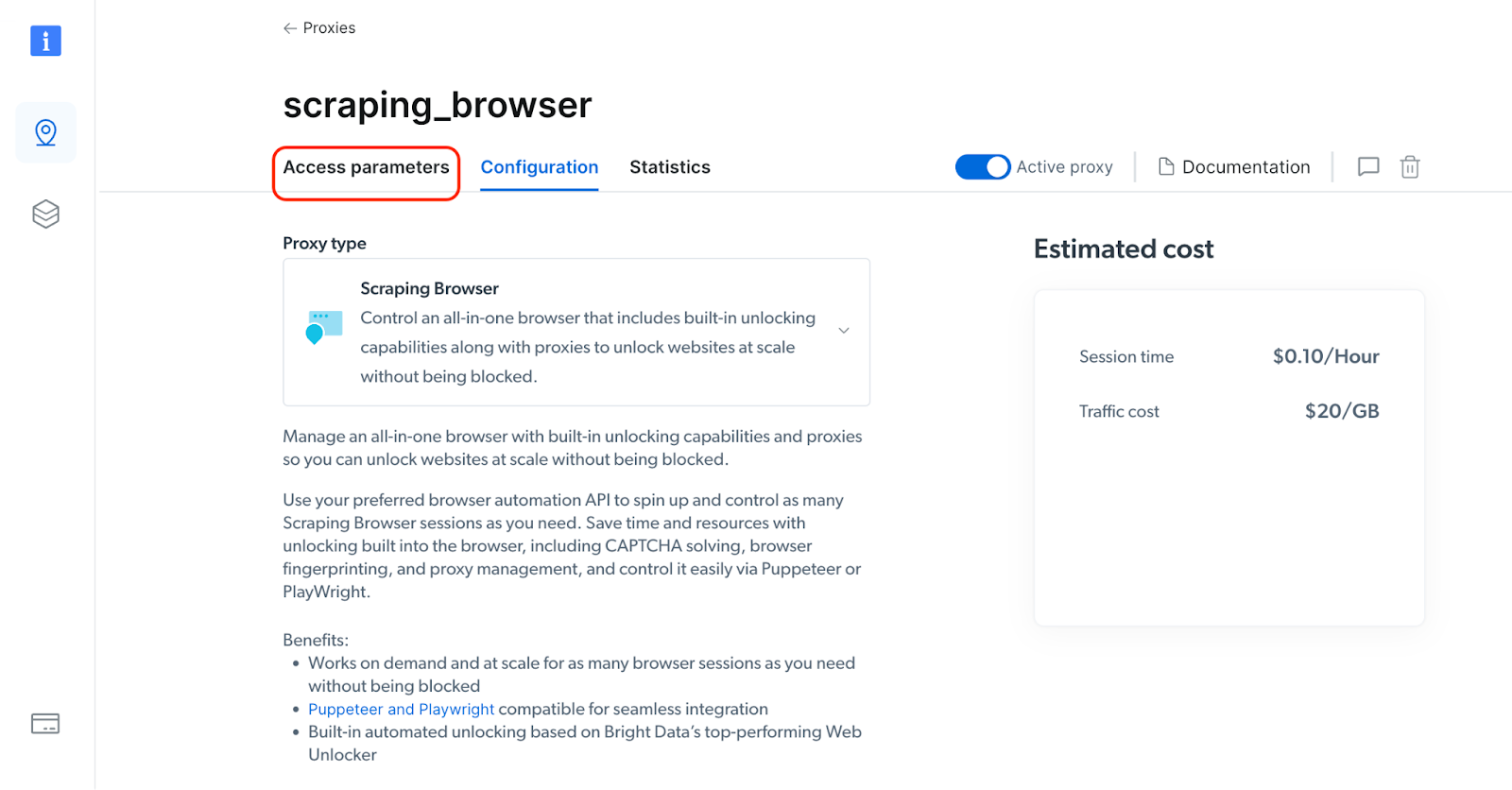
Inside the Scraping Browser configuration, navigate to 'Access Parameters' and note down the *Host URL*, *Username* and *Password*. You are going to configure these parameters in your Python script in a short while.
STEP 3: Once you have the Scraping Browser's details in hand, install the following Python packages in your project directory. Here, you will be using the Playwright API to perform web scraping asynchronously.
pip install asyncio
pip install playwright
STEP 4: Replace Bright Data's Scraping Browser configuration details in the below code.
import asyncio
from playwright.async_api import async_playwright
auth = '<provide username>:<provide password>'
host = '<provide host>'
browser_url = f'wss://{auth}@{host}'
async def fetch_topics():
topics = await read_hackernews()
print("The topics in the first page of HackerNews are ")
for topic in topics:
print(topic)
async def read_hackernews():
async with async_playwright() as playwright:
try:
# Connecting with the Scraping Browser
browser = await playwright.chromium.connect_over_cdp(browser_url)
page = await browser.new_page()
# Opens the Hackernews Website in the browser
await page.goto('https://news.ycombinator.com/')
await page.wait_for_timeout(5000)
# Parse the HTML tags where the topics are placed inside
data = await page.query_selector_all('tr.athing')
topics = []
for items in data:
item = await items.query_selector('td.title span.titleline a')
topics.append(await item.inner_text())
await browser.close()
return topics
except Exception as e:
print(e)
async def main():
await fetch_topics()
asyncio.run(main())
This is what happens in the Python script.
- Using CDP, it connects to an instance of the Scraping Browser running on Bright Data's servers, using a WebSocket connection, and your credentials (from your dashboard, in Step 2).
- Navigates to the Hacker News Website (https://news.ycombinator.com/) in the browser.
- Drills down the source code and reaches the necessary location ('
td.title span.titeline a') using thequery_selector()method. - Reads the topics and adds them to an array.
- Iterates the array and prints the latest topics from Hacker News.
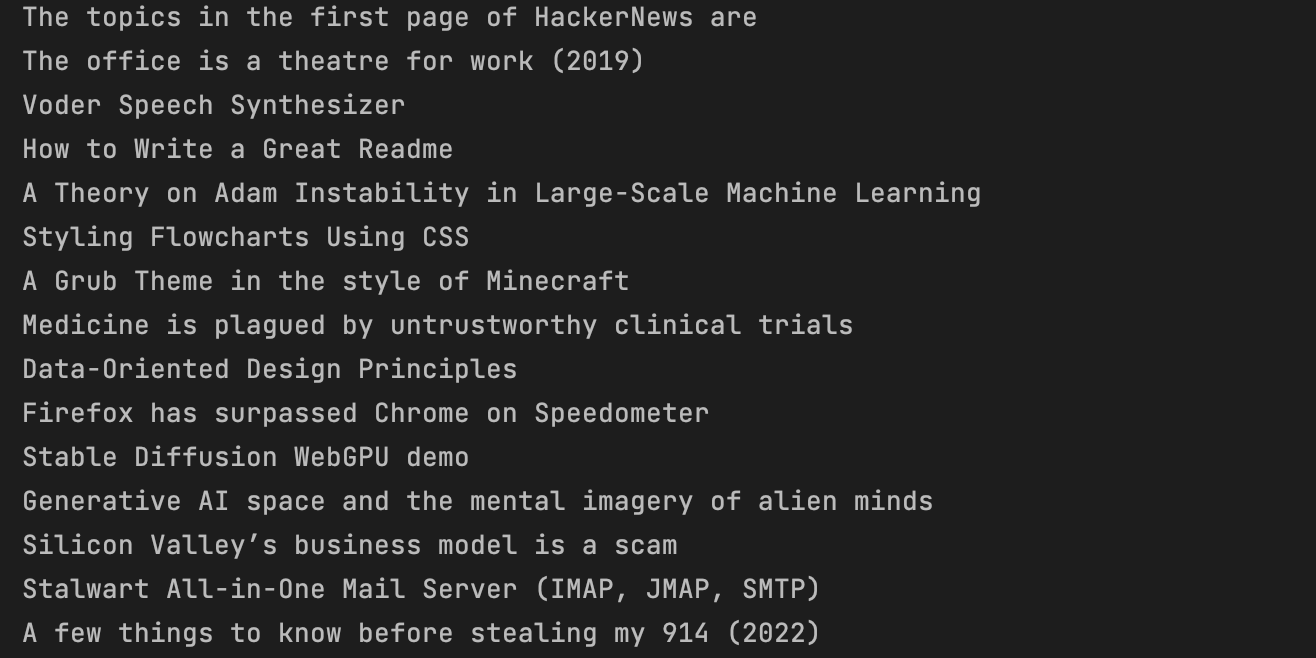
On executing the Python script, you will get an output similar to the below screenshot.
Conclusion
Embracing ethical web scraping practices is crucial for safeguarding privacy, maintaining positive relationships with data sources, and upholding a company's reputation.
Bright Data's commitment to data privacy compliance, transparency, and control for website owners, as well as a KYC-first approach, helps maintain a safe, legal and ethical foundation for web scraping operations. The company's dedication to using ethically acquired legitimate residential and mobile IPs further ensures that data requests originate from genuine locations and devices, avoiding any violations of website terms of service.
The example of extracting data from the Hacker News website demonstrated how the Scraping Browser could be seamlessly integrated into the web scraping process to gather relevant information responsibly.
By utilizing Bright Data's Scraping Browser, you can collect data uninterrupted and at scale, while also ensuring ethical and legal compliance with major data protection and privacy laws.
Comments
Loading comments…