Image Credit: Sidhik aliakbar, CC BY-SA 4.0, via Wikimedia Commons
{kind=link}
Web scraping, a technique that extracts data from websites, has become a powerful tool for businesses.
With its ability to swiftly gather information like product listings and prices, web scraping offers a competitive edge in the market. In this article, we'll delve into the process of web scraping using plain JavaScript and the challenges it poses.
But fear not, as we'll also introduce Bright Data's Scraping Browser - a game-changing solution that simplifies the scraping process and eliminates the hurdles along the way.
Challenges of Scraping with Vanilla JavaScript
If you want to scrape an E-commerce site with plain old vanilla JavaScript, you need to brace yourself for a journey filled with rate limiting, browser fingerprinting, CAPTCHAs, and other obstacles that will make the scraping process a time and resource drain.
Sure, you might start off with some basic steps: making HTTP requests, parsing HTML, and extracting the desired data. Or you can take it one step further, and install something like Puppeteer, which can instantiate a headless browser that you can control programmatically.
But trust me, the road ahead is paved with frustration. There are three very powerful "obstacles" that websites can use to block your scraping efforts (after all, they might not appreciate you skipping all the fun parts just to get to the data you need):
- Rate limiting: Websites don't appreciate being bombarded with requests, so they set limits to protect themselves. As an ambitious scraper, you'll soon find yourself blocked or greeted with snarky error messages like, "Slow down, cowboy!" In other words, if you're not careful, your IP address, or even your browser, might get soon banned from accessing the site you're so desperately trying to scrape.
- Browser fingerprinting: Websites can track your every move, leaving unique fingerprints that scream, "I'm not a regular user, I'm a bot!" Evading this digital fingerprinting can quickly become an exhausting cat-and-mouse game. Never heard of the term "browser fingerprinting"? No worries, check out this article to understand what it means.
- CAPTCHAs: Those annoying tests designed to distinguish humans from bots. As you squint at blurry images of traffic lights or storefronts, you'll realize that scraping can be a real-life obstacle course. Because how are you going to overcome them with just code? You'll have to spend extra time and effort to integrate proxies into your scraper, which also requires picking the right proxies for the right occasions as sometimes, plain old datacenter proxies may not cut it. Trust me, manually getting around CAPTCHAs is not as easy as it sounds.
In the end, while the idea of doing web scraping (either with vanilla JavaScript or simply by using a framework like Puppeteer) might sound simple enough, once you start using it in a real-world scenario, and the site you're scraping starts noticing you, you'll have to jump through a lot of hoops to get the data. There's a lot of logic you have to handle in code to get around these roadblocks before you even get to the actual scraping.
And here is where you start questioning if what you're trying to do is worthwhile at all.
However, there are options out there that help you work around these limitations, and one of those solutions is Bright Data's Scraping Browser.
So let's see what it would be like scraping a real E-commerce site using Bright Data's solutions instead of going through the painful experience of using vanilla JavaScript.
Scraping with Bright Data's Scraping Browser and Puppeteer
The Scraping Browser takes all the woes we mentioned earlier and tosses them out of the window. No more rate limiting, no more fingerprinting, and definitely no more CAPTCHAs.
I mean, yes, they're still there, but thanks to the Scraping Browser, you don't really have to worry about them.
With the Scraping Browser, you can say goodbye to the time-and-resource-consuming practice of manual web scraping. The platform seamlessly handles the technical aspects, allowing you to focus on extracting the data you need.
The Scraping Browser is a headful, fully GUI browser that is fully compatible with Puppeteer/Playwright/Selenium APIs, and by incorporating Bright Data's powerful unlocker infrastructure and proxy network, it comes with block bypassing technology right out of the box. It rotates IP addresses, avoids detection, and gracefully sails through CAPTCHAs without breaking a sweat.
Learn more about the features of the Scraping Browser: Scraping Browser - Automated Browser for Scraping
It's like having a personal assistant that takes care of all the dirty work for you. For a modest price, of course. That said, when you sign up, you can opt-in for a 5 USD credit gift, which is more than enough to test the Scraping browser and decide whether or not it's the right solution for you.
Implementing our scraper
To give you a taste of the magic, here's a functional code sample that showcases the power of Bright Data's Scraping Browser. With just a few lines of code, you can gather information from an E-commerce site, leaving behind the frustrations of scraping using vanilla JavaScript.
But first things first, if you haven't, sign up for Bright Data's platform (it's free) by clicking on 'Start free trial' and entering your details. You can create a new Scraping Browser by following the 'Quick start' section of their instructions here.
Now that you're ready, install Puppeteer like this:
npm i puppeteer-core
Yes, we're still using Puppeteer, but we'll also integrate it into the Scraping Browser to give it "superpowers."
Now, for our example, we're going to be scraping Amazon, the E-commerce site by definition. And in fact, we're going to look for the cheapest book about scraping in JavaScript (because, why not?).
The process should be the following:
- Go to www.amazon.es (that's my local Amazon).
- Find the search bar
- Enter the string "javascript web scraping books"
- Click on the Search button
- Review the list of results, and find the cheapest, non-free book.
Now, let's see how we turn those steps into actual JavaScript code.
Let's now create a single file, call it whatever you want, and write the following code into it:
const puppeteer = require("puppeteer-core");
const auth = "your-username:your-pwd";
// - Find the cheapest non-free book on the list and returns it
function findTheCheapestBook(books) {
let cheapest = null;
books.forEach((book) => {
if (cheapest == null) {
cheapest = book;
} else {
if (book.price != 0 && book.price < cheapest.price) {
cheapest = book;
}
}
});
return cheapest;
}
async function run() {
let browser;
try {
browser = await puppeteer.connect({
browserWSEndpoint: `wss://${auth}@brd.superproxy.io:9222`,
});
const page = await browser.newPage();
page.setDefaultNavigationTimeout(2 * 60 * 1000);
await page.goto("https://www.amazon.es");
await page.waitForSelector("#twotabsearchtextbox");
await page.type("#twotabsearchtextbox", "javascript web scraping books");
await page.click("#nav-search-submit-button");
await page.waitForSelector('div[data-component-type="s-search-result"]');
const myBooks = await page.evaluate(() => {
let results = document.querySelectorAll(
'div[data-component-type="s-search-result"]'
);
let books = [];
results.forEach((r) => {
let bookName = r.querySelector("span.a-size-base-plus").innerHTML;
let bookPrice = parseFloat(
r.querySelector("span.a-price-whole").innerHTML.replace(",", ".")
);
books.push({
name: bookName,
price: bookPrice,
});
});
return books;
});
let cheapest = findTheCheapestBook(myBooks);
console.log("The cheapest book you can get right now is: ");
console.log(cheapest);
} catch (e) {
console.error("run failed", e);
} finally {
await browser?.close();
}
}
run();
Now, there are several things to highlight here:
- The
runfunction is the one in charge of interacting with Bright Data's Scraping Browser. - Within this function, we're using Puppeteer, BUT, look at the
connectmethod call. We're passing abrowserWSEndpointattribute with the value we get from Bright Data's platform. This makes your Puppeteer instance connect to the remote browser instance running on Bright Data's servers, via Chrome DevTools Protocol. - We're then going through the steps I mentioned (visiting the URL, entering the search string, clicking the search button, etc).
- Inside the
evaluatemethod call, I'm sending a function to get evaluated on the browser (the reason why I get access to thedocumentobject). Inside that function, I'll capture the name and price of each book, and then I'll return the list. - Whatever gets returned from that evaluated function, gets serialized and sent to my script. It then gets returned by the
evaluatemethod. I use that returned data to call my functiongetTheCheapestBook. It is this function that will run through the list of books and find me the cheapest, non-free, book from the list of results.
If everything goes according to plan, the output for my script looks like this:

A note about debugging
If you're having difficulties getting exactly what you'd expect from your code, there is a way for you to debug your code while watching what the browser is doing with it.
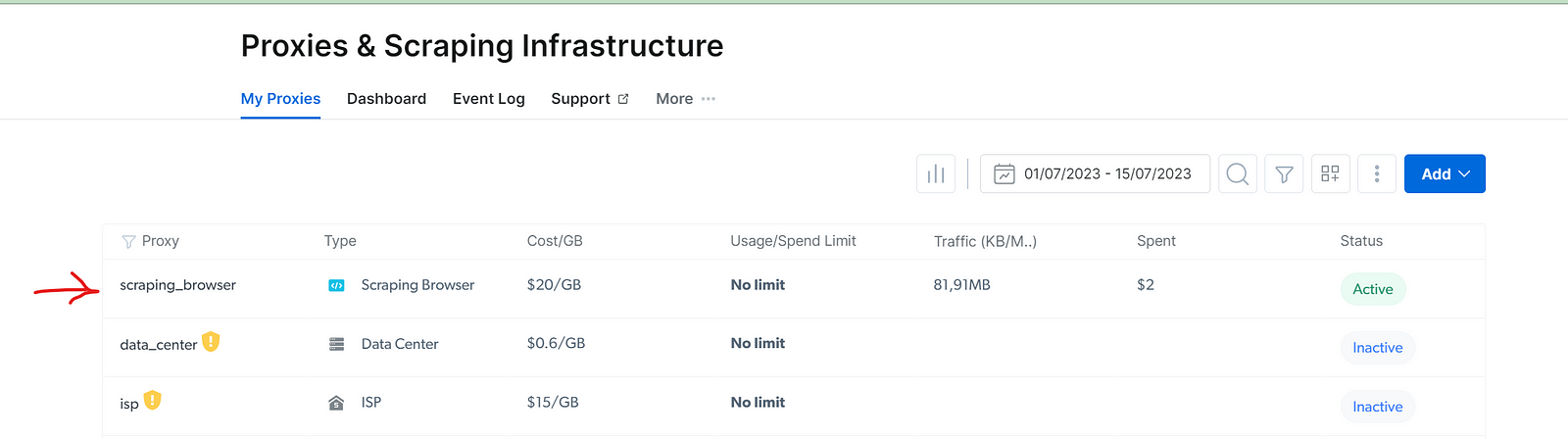
- Go to the list of proxies and select your Scraping Browser:
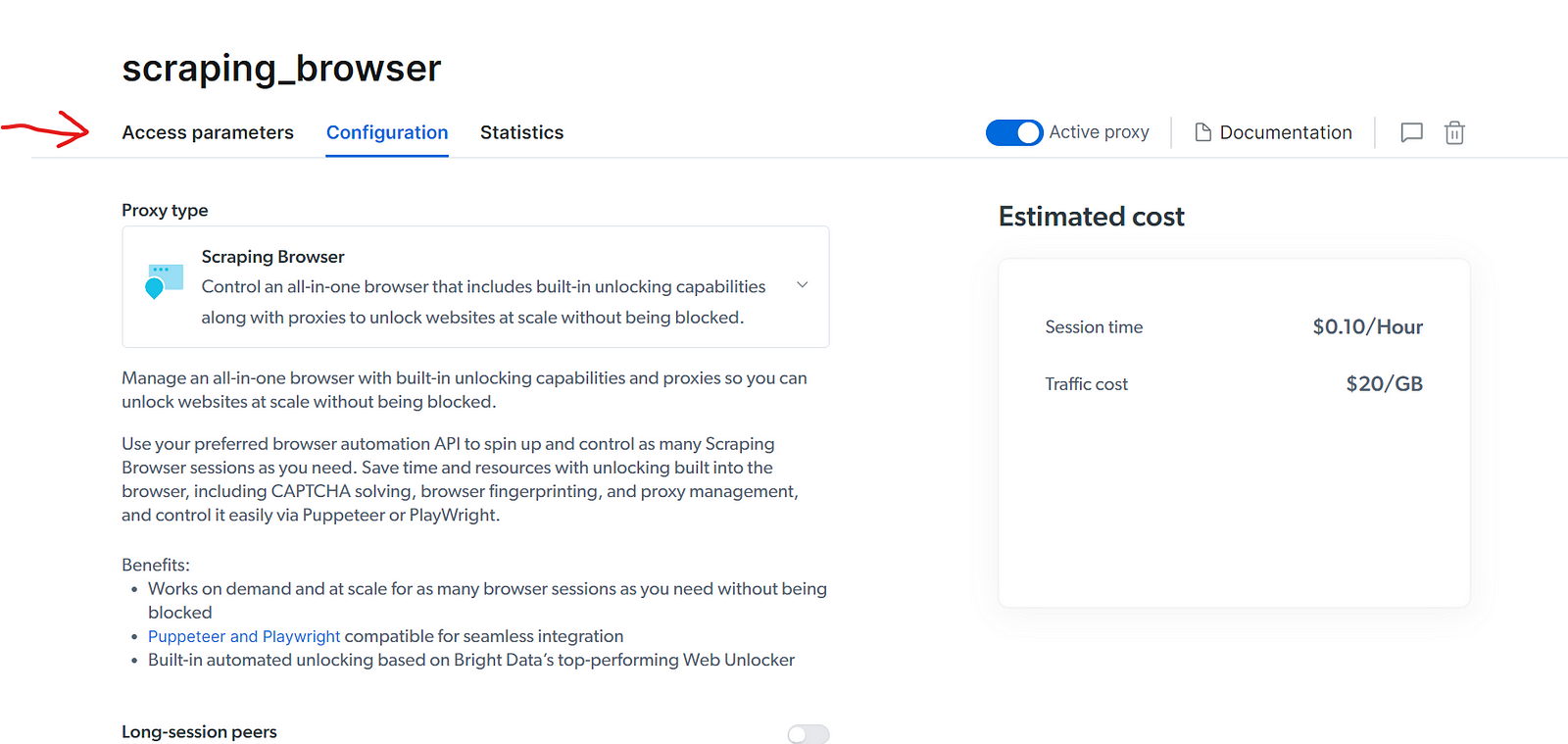
- Click on the "Access parameters" tab:
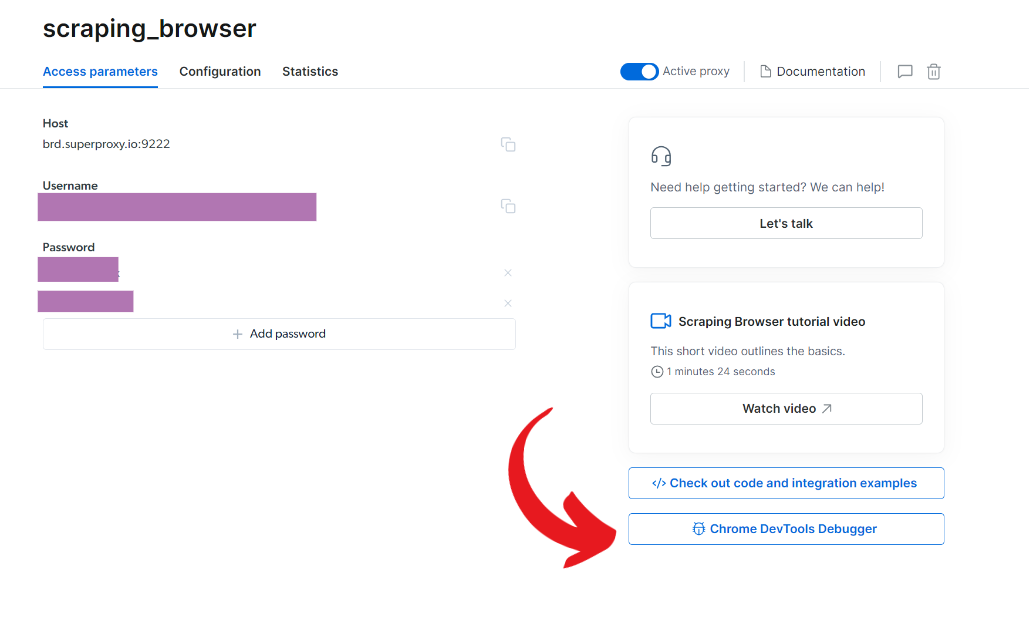
- Click on the "Chrome DevTools debugger" in the lower right corner of the screen:
- Select the instance you want to debug:
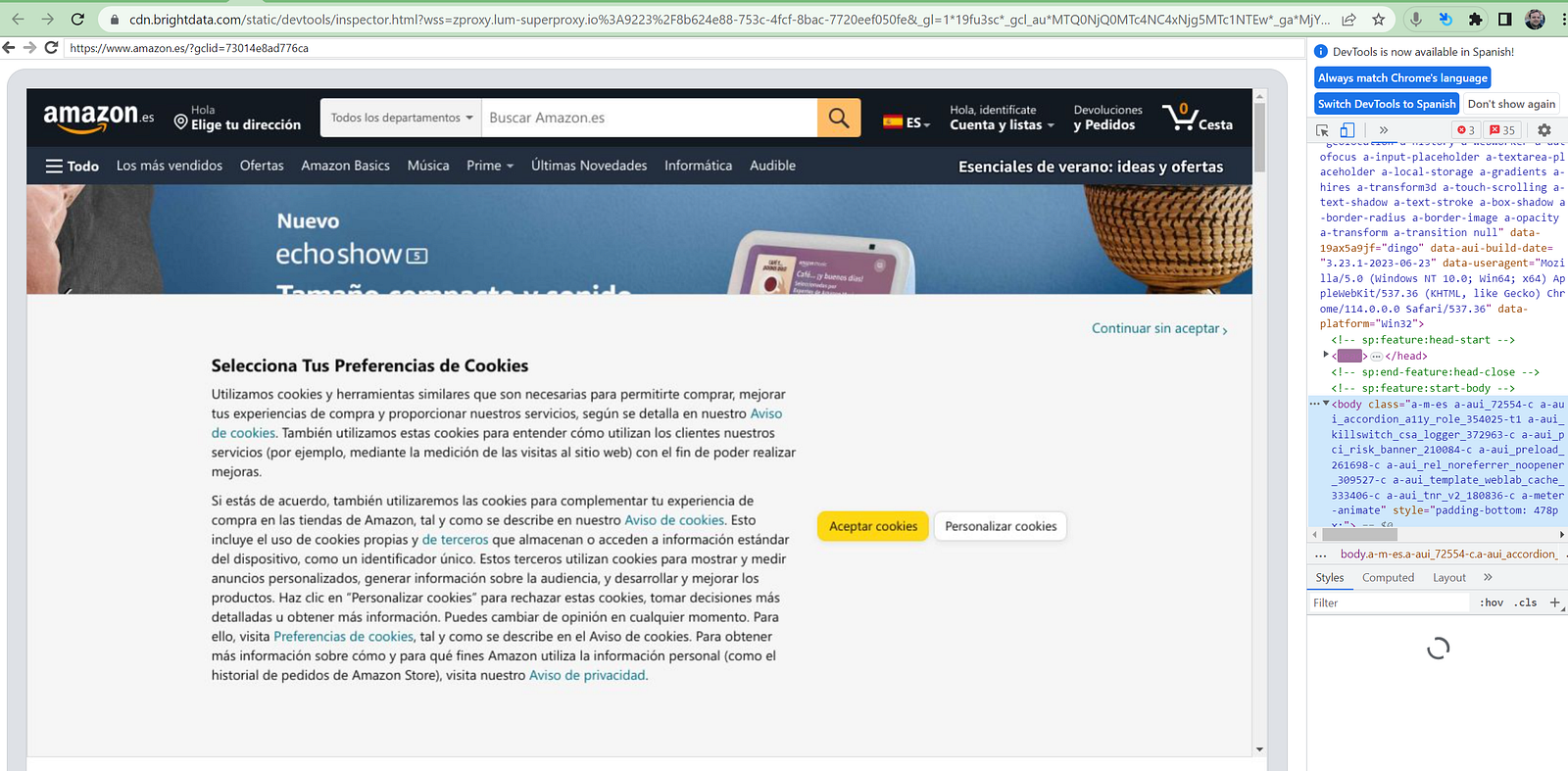
- And then watch how the remote browser does its thing based on your code:
What About the Problems We Mentioned Earlier?
What happened to making sure you don't send too many requests too soon to avoid being rate-limited? Or what about not wanting to get fingerprinted by the website?
Where did all those worries go and why didn't I tackle them in my code?
Simple! Because the Scraping Browser took care of all of them for me.
Actions such as solving CAPTCHAs, bypassing fingerprinting, avoiding getting rate-limited by automatically cycling through proxies, changing the user-agent string and more are already taken care of by Bright Data. Your code can remain clean and focused only on the information you want to get (in my case, the cheapest book about web scraping).
💡 From CAPTCHA-solving to
user-agentgeneration, to cookie management and fingerprint emulation, learn more about how Bright Data's unlocker infrastructure can bypass even the most sophisticated anti-scraping measures here.
In a world full of scraping headaches, Bright Data's Scraping Browser is a beacon of hope. It streamlines the web scraping process, sparing you from the manual labor and frustrations that come with using vanilla JavaScript to scrape the web. From automatically rotating proxies to getting around blocks and effortlessly handling CAPTCHAs, it has your back.
So, say "bye-bye" to sleepless nights spent battling web-scraping obstacles. And say "hello there!" to efficient data extraction at scale that requires zero-to-low infra on your part. With Bright Data's Scraping Browser, let your data extraction endeavors thrive like never before.
👉 Sign up today to start experiencing the full power of the Scraping Browser yourself
Happy scraping!
Comments
Loading comments…