
Image generated with DreamStudio
Glassdoor and LinkedIn are two of the leading global platforms for career exploration. While both offer job listings, Glassdoor sets itself apart by providing insightful company details and employee reviews. This is essential for job seekers because they can understand the company's culture, work-life balance, compensation, and even the interview experience.
Conversely, company details and reviews are a goldmine for companies and human resources teams looking to manage their reputation or apply strategies to increase their rating. They can use the feedback to identify areas for improvement, address employee concerns, and ultimately attract top talent. Additionally, positive reviews can be a powerful employer branding tool, showcasing a company's perks.
For data-driven decision-making, companies require large volumes of reviews and company details. This huge amount of data can be obtained by scraping Glassdoor, which can easily become a complex task since it requires not only excellent skills in automation with headless browsers such as Selenium and Playwright but also extensive knowledge of web scraping libraries like Beautiful Soup and Scrapy.
Scraping Glassdoor can be much less complicated with Bright Data's Scraping Browser, which not only comes with a vast network of high-quality proxies from 195 countries ensuring uninterrupted data extraction but also uses a powerful unblocking infrastructure to overcome anti-scraping measures applied by most websites, including Glassdoor.
In this piece, we'll delve into the importance of Glassdoor data, such as reviews, job listings, and company details. We'll look at the several existing limitations for acquiring this data and present the solution through Python and seamless integration with Bright Data's Scraping Browser.
Scraping Browser - Build Unblockable Scaprers with Puppeteer, Playwright, and Selenium *Integrate Bright Data's browser with your scraping scripts to outsmart bot-detection software and avoid website...*brightdata.com
Use Cases of Glassdoor Data for Recruiters and Companies
Glassdoor is the ultimate platform to analyze a company's work environment, salary expectations, benefits, work-life balance, and more. This information can be acquired from the company details section, showing the organization's size, sector, and revenue. Employees also leave genuine reviews, which can provide a deeper understanding of the company.
Let's take a look at the main use cases of Glassdoor data for organizations, teams of recruiters, entrepreneurs, and job seekers.
For Companies
- Company culture: Startups or companies that strive to retain employees, can analyze employee reviews across different organizations, and gain insights into what kind of company culture and work environment employees are most comfortable in.
- Competitiveness: Salary information, company reviews and interviews allow organizations to understand what competitors are offering, allowing them to tailor their own recruiting strategy.
- Satisfaction: Scraping reviews can help companies gain insights into employee satisfaction and identify areas of improvement.
For Recruiters:
- Find the best candidates: By scraping reviews and salary information, recruiters can find qualified candidates that match their requirements and salary expectations, as well as understand the candidate's seniority and skills.
- Redefine interviews: By understanding the pros and cons and overall feedback of employees in the companies they've worked for, recruiters can conduct tailored interviews and reduce the hours of the hiring process.
For Entrepreneurs:
- Build AI platforms: Creators can use the Glassdoor data, to make AI-driven platforms, that allow companies and hiring teams to easily find work environments, salaries, and work-life balance tailored to their interests.
- Pave the way for job seekers: Entrepreneurs can think of solutions to ease the way of finding the dream job through Glassdoor data. The data extracted from reviews, company details, and job listings can be cleaned and fine-tuned to match a job seeker's curriculum.
For Job Seekers:
- Salary expectation: Scraping salary data can help job seekers get a clearer picture of what they can expect to earn for a specific position and location.
- Company research: Reviews and company details provide valuable insights about work culture, benefits, and work-life balance, allowing job seekers to make informed decisions before applying.
The use cases mentioned are just some examples, the actual value of Glassdoor data goes far beyond, and it all depends on what the company or individual is looking to tackle. We are mainly looking at certain data such as jobs, company details, and reviews. But before diving into the tutorial itself, let's first get familiar with the challenges you might face while scraping Glassdoor.
Challenges in Scraping Glassdoor
We examined several applications of Glassdoor data, particularly focusing on job listings, company information, and employee reviews. However, this data can be technically complex to obtain, expensive, or not 100% reliable. Here are some of the constraints associated with web scraping Glassdoor:
- IP Blocks and Rate Limits: Glassdoor implements IP blocks and rate limits to prevent excessive requests and protect its platform from abuse. This limitation can disrupt data collection and require strategies for rotating IP addresses and managing request frequency.
- Captchas and Anti-Scraping Measures: Glassdoor may implement Captcha challenges or make use of dynamic loading of content to deter scrapers. Captchas require human verification and can be a significant obstacle for automated scraping scripts.
- Geographical Restrictions: Access can be restricted to certain data based on geographical regions or countries. This can limit the scope of data collection, particularly if your scraping efforts are focused on specific areas.
- In-house Infrastructure: Handling and storing large volumes of scraped data is a resource-intensive task, requiring you to invest in additional infrastructure to store, process, and manage the data efficiently. Establishing and maintaining this in-house infrastructure can be costly and time-consuming.
With the constraints mentioned above, using a web scraping stack such as Puppeteer, Playwright, Beautiful Soup, and Scrapy, may not be enough since:
- You're still likely to run into Captchas and other sophisticated anti-scraping measures like browser fingerprinting that can bring the scraping process to a screeching halt.
- You'll have to take care of proxy management such as rotating proxies to get around Captchas and this will require reliance on third-party libraries.
- Developing and maintaining such complex browser-based scrapers is a difficult, resource-intensive task because of so many overlapping concerns to take care of.
This is precisely where Bright Data's Scraping Browser can come in handy. In the following section, you will see how to extract valuable information from Glassdoor, even if you're not a tech expert and want to avoid raising flags
How Scraping Browser and Premium Proxies Help in Scraping Glassdoor

Bright Data's Scraping Browser
Bright Data's Scraping Browser is a GUI browser, also known as headful browser. This type of browser is less likely to be detected by anti-bot software and provides seamless integration with headless browsers such as Puppeteer and Playwright.
The Scraping Browser is powered by a vast proxy network consisting of over 72 million IPs spread across 195 countries. This extensive reach from Bright Data ensures you can access and scrape Glassdoor data effectively and without interruptions. The combination of these proxies and the in-built web unlocker infrastructure, make this solution far superior to headless browsers.
To sum up, the following factors set it apart:
- Bypass Georestrictions: With over 72 million residential IPs, you can bypass geo-restrictions and scrape listings from almost anywhere in the world.
- Reliability: The proxy network boasts 99.9% uptime, minimizing disruptions during your scraping process.
- Seamless Integration: The Scraping Browser API integrates easily with popular headless browsers like Playwright and Puppeteer, streamlining your web scraping workflow.
- Ethical Standards: They prioritize ethical data collection practices, ensuring you comply with Glassdoor's terms of service.
By using the previous advantages as a reference, we can list the reasons why using Bright Data's Scraping Browser powered by its proxies is the most suitable tool for scraping Glassdoor:
- Residential proxies act as intermediaries between your machine and the target website, hiding the true IP address carrying the web scraping.
- For a smooth web scraping experience, Bright Data's proxies rotate in order to maintain the data extraction healthy and without interruptions.
- Accessing job listings from different countries often proves challenging due to geolocation-based restrictions. This limitation restricts businesses from analyzing markets globally. Bright Data's residential proxies help circumvent this by allowing scrapers to appear as if they were real users browsing from actual geographical locations.
- Brighter Data's Scraping Browser comes with a built-in website unblocker that bypasses anti-bot measures (including Cloudflare) implemented by complex websites like Glassdoor.
Check out the official documentation to learn more about the Scraping Browser:
Introduction - Bright Data Docs Learn about Bright Data's Scraping Browser solutionbrightdata.com
Now that we've covered the importance of Bright Data's Scraping Browser and its proxies for scraping Glassdoor listing data, it's time to implement the code.
How to Scrape Glassdoor Data with Python and the Scraping Browser: The Code
We'll dive into two code examples that share a core structure. While the first targets job listings and their data, the second focuses on reviews from a specific company. In this case, we'll leverage Playwright, a headless browser, along with Bright Data's Scraping Browser and its proxies. We'll tackle job listings from the United States while appearing to be located in Portugal.
To do this, we need to broadly take the following steps:
- Create an account on Bright Data and head to the dashboard to activate the scraping browser.
- Install Python dependencies such as Playwright and Beautiful Soup and create a .env file to store the API credentials.
- Build a Python script incorporating the API parameters and obtain the outputs for the job listings.
- Build a Python script incorporating the API parameters and obtain reviews from one single company
Let's dive in.
You can start by signing up for Bright Data and starting your free trial (to do this, click on either 'Start free trial' or 'Sign up with Google' - the process is free, and you won't be charged for this).
Bright Data's free trial
Once you're logged in, go to Proxies & Scraping Infrastructure and select the Scraping Browser you want to use.
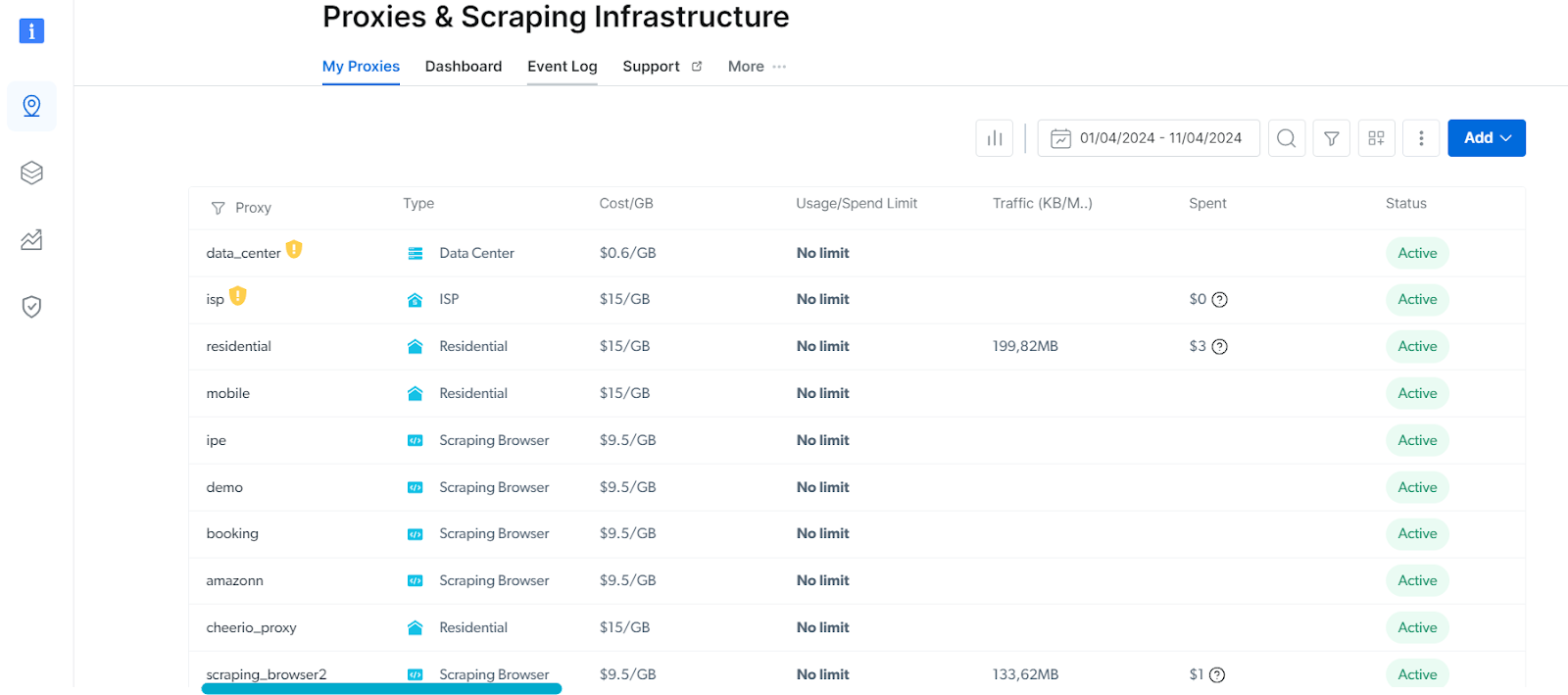
Bright Data's proxies dashboard
Once selected, you will be able to access the access parameters and activate the proxy.
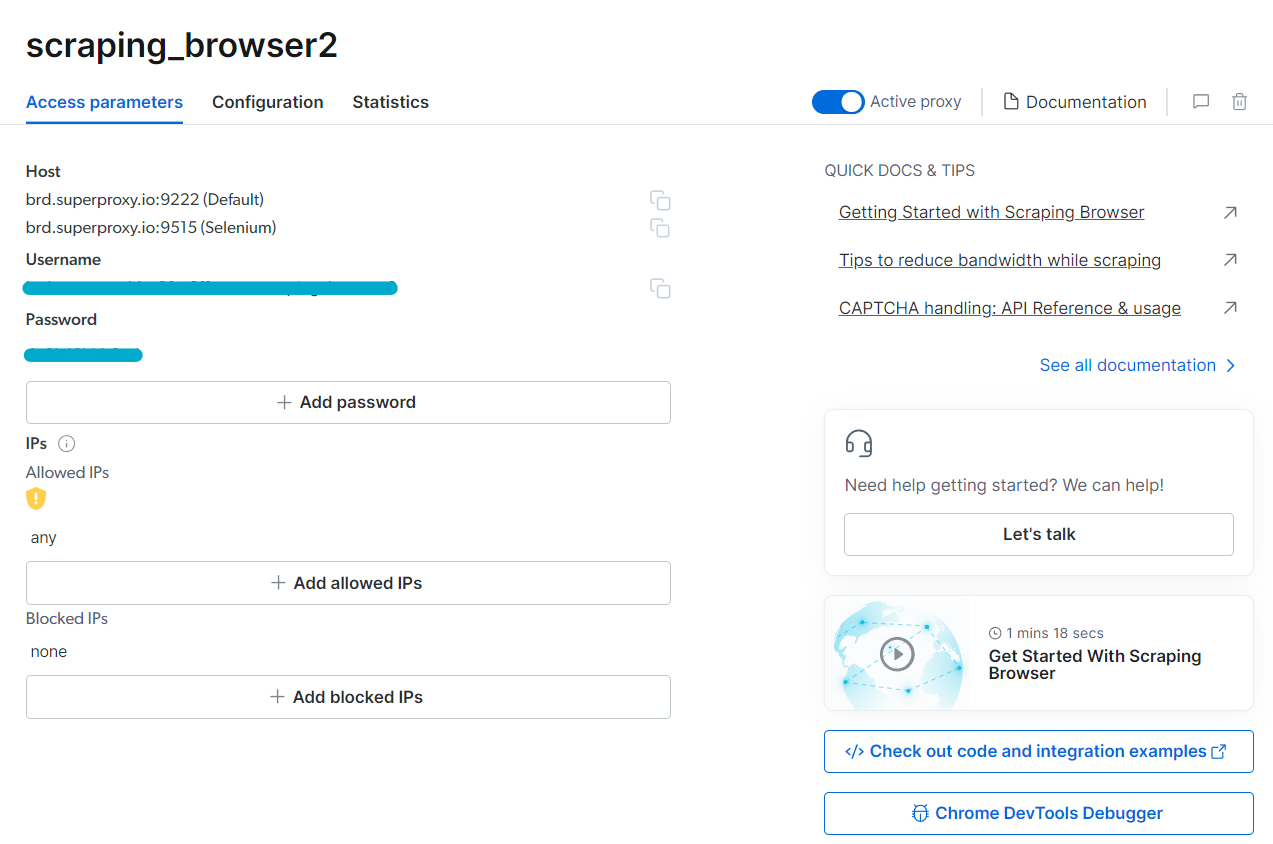
Bright Data's Scraping Browser parameters
The parameters shown will be utilized to set up our proxy with Playwright. But to avoid exposing the credentials, you can save them in a .env file (keys.env for instance).
HOST="<scraping_browser_proxy>"
USERNAME="<scraping_browser_username>"
PASSWORD="<scraping_browser_password>"
Before starting with the Python script, we need to install the following dependencies:
pip install beautifulsoup4 playwright python-dotenv requests
Now we need to install Playwright with this simple command:
playwright install
We're now ready to create our Python file, starting by calling the dependencies we've just installed.
import os
import asyncio
from dotenv import load_dotenv
from bs4 import BeautifulSoup
from playwright.async_api import async_playwright
load_dotenv("keys.env")
Let's separate the code into two modules. One will focus on extracting job listings from Glassdoor, while the other will specifically target reviews for a single company.
Job Listings Script
import os
import json
import asyncio
from dotenv import load_dotenv
from playwright.async_api import async_playwright
from bs4 import BeautifulSoup
load_dotenv("keys.env")
username = os.getenv("USERNAME")
host = os.getenv("HOST")
password = os.getenv("PASSWORD")
URL = "https://www.glassdoor.com/Job/california-us-jobs-SRCH_IL.0,13_IS2280.htm"
async def main(country):
auth = f"{username}-country-{country}:{password}"
browser_url = f"wss://{auth}@{host}"
async with async_playwright() as pw:
print('connecting')
browser = await pw.chromium.connect_over_cdp(browser_url)
print('connected')
page = await browser.new_page()
print('goto')
await page.goto(URL, timeout=120000)
print('done, evaluating')
# Extract section with the job listings
section = await page.inner_html('ul.JobsList_jobsList__lqjTr')
# create Beautiful Soup object
soup = BeautifulSoup(section, 'html.parser')
elements = soup.find_all(
'div',
class_='JobCard_jobCardContainer___hKKI')
for element in elements:
job_link = element.find(
'a',
class_="DiscoverMoreSeoLinks_link__q1tPX")
job_title = element.find(
'a',
class_="JobCard_jobTitle___7I6y")
job_salary = element.find(
'div',
class_="JobCard_salaryEstimate__arV5J")
job_location = element.find(
'div',
class_="JobCard_location__rCz3x")
job_company = element.find(
'span',
class_="EmployerProfile_compactEmployerName__LE242")
job_rating = element.find(
'div',
class_="EmployerProfile_ratingContainer__ul0Ef")
try:
results = {
'job_title': job_title.text,
'job_company': job_company.text,
'job_location': job_location.text,
'job_salary': job_salary.text,
'job_rating': job_rating.text,
'job_link': job_link.get('href')}
all_results.append(results)
except Exception as error:
print(error)
pass
with open("job_listing.json", "w") as outfile:
json.dump(all_results, outfile)
await browser.close()
if **name** == '**main**':
# dictionary of countries
countries = {'Portugal': 'pt'}
# create a coroutine object:
# k (key) is the name of the country and v(value) the code
for k, v in countries.items():
print("n", f"----- GEO-TARGETING {k.upper()} -----", "n")
print(v)
coro = main(v)
asyncio.run(coro)
At the beginning of the script, we import the packages and create the Scraping Browser variables we defined previously in the keys.env file. We also define our target URL which in this case is the Glassdoor page corresponding to jobs in California, US. Then we create a main function that takes the country as a string variable. This input allows for geolocation targeting.
The function and all the Playwright's objects are asynchronous to allow multiple requests to be made concurrently without waiting for each to be completed, preventing the application from stopping.
At the top of the function, we start by creating the browser URL, which takes the Scraping Browser variables. Then we instantiate the async_plawright() object as pw. We make our browser instance using the pw object and the function connect_over_cdp() with the browser URL as input. Finally, we use the browser object to create a Playwright page, that allows for task automation, such as opening the target URL.
async with async_playwright() as pw:
print('connecting')
browser = await pw.chromium.connect_over_cdp(browser_url)
print('connected')
page = await browser.new_page()
print('goto')
await page.goto(URL, timeout=120000)
print('done, evaluating')
Once at the page, we extract only a section of the overall HTML with the function .inner_html. We create a Beautiful Soup object to parse job cards inside the section we've just extracted. We can see below an example of the elements we're tackling within this section:
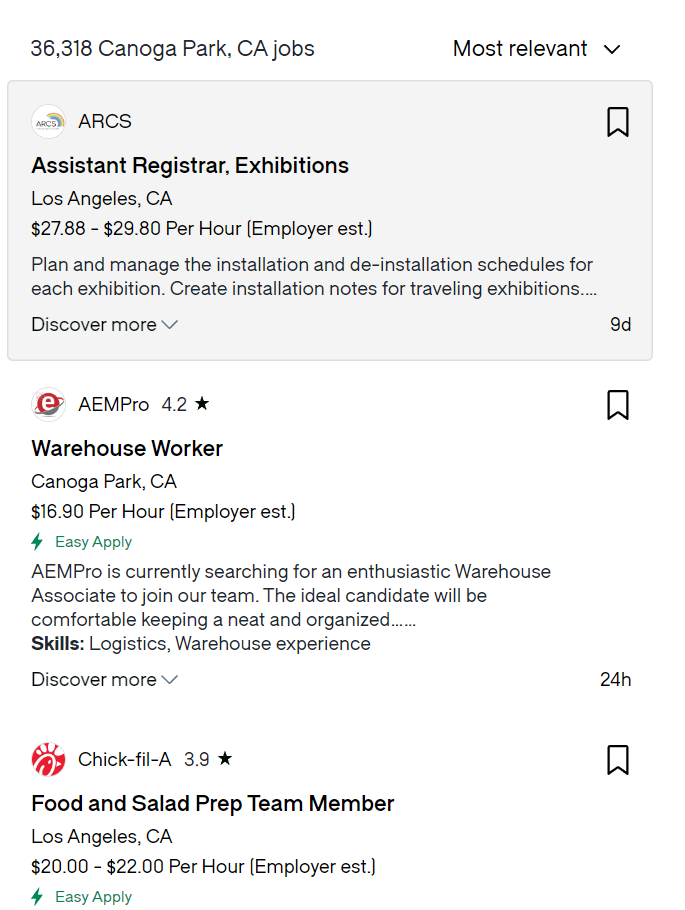
Job listing example at Glassdoor website
After getting all the job cards inside the page, we iterate over them and parse meaningful information such as the job title, the company, the salary, and the location, while saving all these variables in a dictionary. Below is the JSON output for California, US while geotargeting Portugal.
[
{
"job_title": "Admission Clerk I",
"job_company": "Tarzana Treatment Center",
"job_location": "Lancaster, CA",
"job_salary": "$24.00 - $26.00 Per Hour (Employer est.)",
"job_rating": "3.0",
"job_link": "https://www.glassdoor.com/Job/lancaster-ca-admissions-jobs-SRCH_IL.0,12_IC1146814_KO13,23.htm"
},
{
"job_title": "Manager Talent Acquisition - Remote",
"job_company": "Mercury Insurance Services, LLC",
"job_location": "Los Angeles, CA",
"job_salary": "$96K - $178K (Employer est.)",
"job_rating": "3.6",
"job_link": "https://www.glassdoor.com/Job/los-angeles-ca-corporate-recruiter-jobs-SRCH_IL.0,14_IC1146821_KO15,34.htm"
},
{
"job_title": "Remote Call Center Representative",
"job_company": "Shangri-La Construction",
"job_location": "Los Angeles, CA",
"job_salary": "$20.00 - $30.00 Per Hour (Employer est.)",
"job_rating": "4.6",
"job_link": "https://www.glassdoor.com/Job/los-angeles-ca-call-center-representative-jobs-SRCH_IL.0,14_IC1146821_KO15,41.htm"
},
{
"job_title": "Distribution Center Associate",
"job_company": "Fullscript",
"job_location": "Riverside, CA",
"job_salary": "$20.25 Per Hour (Employer est.)",
"job_rating": "4.0",
"job_link": "https://www.glassdoor.com/Job/riverside-ca-distribution-manager-jobs-SRCH_IL.0,12_IC1147138_KO13,33.htm"
},
{
"job_title": "Revenue Data Entry Clerk -Remote",
"job_company": "Reimagined Parking",
"job_location": "California",
"job_salary": "$16.75 Per Hour (Employer est.)",
"job_rating": "2.6",
"job_link": "https://www.glassdoor.com/Job/california-data-entry-jobs-SRCH_IL.0,10_IS2280_KO11,21.htm"
},
{
"job_title": "Assoc, Data Entry",
"job_company": "Oldcastle BuildingEnvelope, Inc.",
"job_location": "Fremont, CA",
"job_salary": "$22.00 - $25.00 Per Hour (Employer est.)",
"job_rating": "3.3",
"job_link": "https://www.glassdoor.com/Job/fremont-ca-data-entry-jobs-SRCH_IL.0,10_IC1147355_KO11,21.htm"
},
{
"job_title": "Data Entry Specialist",
"job_company": "DDG",
"job_location": "Berkeley, CA",
"job_salary": "$48K - $78K (Glassdoor est.)",
"job_rating": "3.9",
"job_link": "https://www.glassdoor.com/Job/berkeley-ca-data-entry-jobs-SRCH_IL.0,11_IC1147330_KO12,22.htm"
},
{
"job_title": "Customer Experience Associate",
"job_company": "Dr. Squatch",
"job_location": "Marina del Rey, CA",
"job_salary": "$70K - $80K (Employer est.)",
"job_rating": "3.6",
"job_link": "https://www.glassdoor.com/Job/marina-del-rey-ca-customer-relations-jobs-SRCH_IL.0,17_IC1146825_KO18,36.htm"
},
{
"job_title": "Appointment Clerk",
"job_company": "Kaiser Permanente",
"job_location": "Woodland Hills, CA",
"job_salary": "$26.82 - $29.71 Per Hour (Employer est.)",
"job_rating": "3.9",
"job_link": "https://www.glassdoor.com/Job/woodland-hills-ca-scheduler-jobs-SRCH_IL.0,17_IC1146915_KO18,27.htm"
},
{
"job_title": "Data Entry",
"job_company": "Apria Healthcare LLC",
"job_location": "Riverside, CA",
"job_salary": "$37K - $50K (Glassdoor est.)",
"job_rating": "2.8",
"job_link": "https://www.glassdoor.com/Job/riverside-ca-data-entry-jobs-SRCH_IL.0,12_IC1147138_KO13,23.htm"
},
{
"job_title": "Junior QA Engineer",
"job_company": "EPCVIP, Inc",
"job_location": "Calabasas, CA",
"job_salary": "$67K - $100K (Employer est.)",
"job_rating": "4.8",
"job_link": "https://www.glassdoor.com/Job/calabasas-ca-qa-engineer-jobs-SRCH_IL.0,12_IC1146757_KO13,24.htm"
},
{
"job_title": "Warehouse Associate - Monument Corridor",
"job_company": "DoorDash Essentials + Kitchens",
"job_location": "Concord, CA",
"job_salary": "$16.00 - $24.00 Per Hour (Employer est.)",
"job_rating": "3.7",
"job_link": "https://www.glassdoor.com/Job/concord-ca-warehouse-worker-jobs-SRCH_IL.0,10_IC1147340_KO11,27.htm"
},
{
"job_title": "DTC Data Entry Administrator",
"job_company": "Liberated Brands",
"job_location": "Costa Mesa, CA",
"job_salary": "$18.27 - $25.49 Per Hour (Employer est.)",
"job_rating": "3.8",
"job_link": "https://www.glassdoor.com/Job/costa-mesa-ca-data-entry-jobs-SRCH_IL.0,13_IC1146769_KO14,24.htm"
},
{
"job_title": "CK Data Entry Associate",
"job_company": "MARUKAI CORPORATION",
"job_location": "Torrance, CA",
"job_salary": "$18.00 - $25.00 Per Hour (Employer est.)",
"job_rating": "3.1",
"job_link": "https://www.glassdoor.com/Job/torrance-ca-data-entry-jobs-SRCH_IL.0,11_IC1146894_KO12,22.htm"
},
{
"job_title": "Senior Sourcer (Fixed Term)",
"job_company": "Snapchat",
"job_location": "Los Angeles, CA",
"job_salary": "$107K - $161K (Employer est.)",
"job_rating": "3.6",
"job_link": "https://www.glassdoor.com/Job/los-angeles-ca-sourcer-jobs-SRCH_IL.0,14_IC1146821_KO15,22.htm"
},
{
"job_title": "People & Culture Associate",
"job_company": "Morley Builders",
"job_location": "Santa Monica, CA",
"job_salary": "$72K - $78K (Employer est.)",
"job_rating": "3.9",
"job_link": "https://www.glassdoor.com/Job/santa-monica-ca-jobs-SRCH_IL.0,15_IC1146873.htm"
},
{
"job_title": "Associate Customer Success Manager",
"job_company": "Five9",
"job_location": "San Ramon, CA",
"job_salary": "$49K - $96K (Employer est.)",
"job_rating": "4.2",
"job_link": "https://www.glassdoor.com/Job/san-ramon-ca-customer-success-manager-jobs-SRCH_IL.0,12_IC1147410_KO13,37.htm"
},
{
"job_title": "Call Center Customer Service Representative",
"job_company": "Burrtec",
"job_location": "Fontana, CA",
"job_salary": "$21.00 - $22.50 Per Hour (Employer est.)",
"job_rating": "3.4",
"job_link": "https://www.glassdoor.com/Job/fontana-ca-customer-relations-jobs-SRCH_IL.0,10_IC1147081_KO11,29.htm"
},
{
"job_title": "Social Media Assistant",
"job_company": "REVOLVE",
"job_location": "Cerritos, CA",
"job_salary": "$19.00 - $22.00 Per Hour (Employer est.)",
"job_rating": "2.9",
"job_link": "https://www.glassdoor.com/Job/cerritos-ca-social-media-manager-jobs-SRCH_IL.0,11_IC1146763_KO12,32.htm"
},
{
"job_title": "Warehouse Sorter",
"job_company": "IKEA",
"job_location": "Lebec, CA",
"job_salary": "$19.19 Per Hour (Employer est.)",
"job_rating": "3.8",
"job_link": "https://www.glassdoor.com/Job/lebec-ca-warehouse-worker-jobs-SRCH_IL.0,8_IC1146576_KO9,25.htm"
}
]
We are now going to delve into the reviews script and its output. Note that the main difference between the two scripts starts at the .inner_html function because for the job listing we use one section, and for the reviews, we use another. The use of sections instead of the full HTML facilitates the parsing.
Reviews Script
import os
import json
import asyncio
from dotenv import load_dotenv
from playwright.async_api import async_playwright
from bs4 import BeautifulSoup
load_dotenv("keys.env")
username = os.getenv("USERNAME")
host = os.getenv("HOST")
password = os.getenv("PASSWORD")
URL = "https://www.glassdoor.com/Job/california-us-jobs-SRCH_IL.0,13_IS2280.htm"
async def main(country):
auth = f"{username}-country-{country}:{password}"
browser_url = f"wss://{auth}@{host}"
async with async_playwright() as pw:
print('connecting')
browser = await pw.chromium.connect_over_cdp(browser_url)
print('connected')
page = await browser.new_page()
print('goto')
await page.goto(URL, timeout=120000)
print('done, evaluating')
# Extract section with the job details
section = await page.inner_html(
'div.JobDetails_jobDetailsContainer__y9P3L')
# create Beautiful Soup object
soup = BeautifulSoup(section, 'html.parser')
job = soup.find('h1', class_="heading_Heading__BqX5J")
company = soup.find(
'a',
class_="EmployerProfile_profileContainer__VjVBX")
elements = soup.find_all(
'li',
class_='CompanyBenefitReview_sectionPaddingBottom__PZi8n')
reviews = [element.text for element in elements]
results = {
'job_title': job.text,
'job_company': company.text,
'company_reviews': reviews
}
print(results)
await browser.close()
if **name** == '**main**':
# dictionary of countries
countries = {'Portugal': 'pt'}
# create a coroutine object:
# k (key) is the name of the country and v(value) the code
for k, v in countries.items():
print("n", f"----- GEO-TARGETING {k.upper()} -----", "n")
print(v)
coro = main(v)
asyncio.run(coro)
The variables and code structure remain largely similar to the job listing script. However, our focus here shifts to extracting information from the first job on the list. For instance, in the image below you can see the "Assistant Registrar" position with the full description shown on the right:
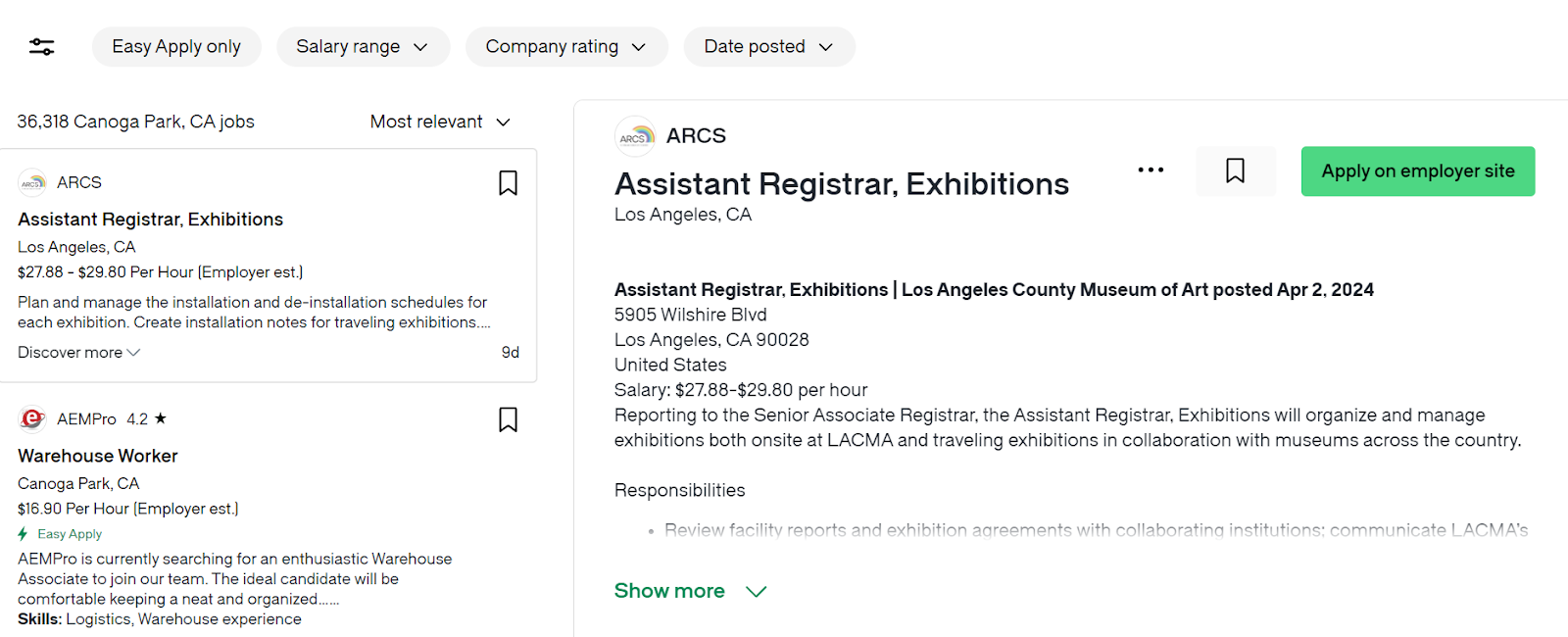
Job description at Glassdoor's website
Once again we use the Beautiful Soup library to create a parsing object to extract the job title, the company name, and the available company reviews on the page. This is an example of the output:
{
'job_title': 'Assoc, Data Entry',
'job_company': 'Oldcastle BuildingEnvelope, Inc.3.3',
'company_reviews': [
'Health Insurance(16 comments)"Blue cross blueshield, dental, and eye"',
'401K Plan(10 comments)"Matching up to five percent."',
'Vacation & Paid Time Off(9 comments)"Vacation balance is weak in this job market, three weeks is standard."'
]}
Conclusion
In this piece, we've looked at the importance of scraping Glassdoor, notably the use cases for companies, recruiters, creators, and job seekers. We've also addressed the different limitations that arise from crawling this website, such as the anti-bot measures, and IP blocking. We also saw how Bright Data's Scraping browser and its vast network of proxies were used seamlessly with the Playwright headless browser and Beautiful Soup to overcome the limitations.
The examples shown in this article present two possible ways of extracting job listings and reviews. In both scripts, we use the credentials of the Scraping Browser, and then we write a function to scrape a certain section of the full HTML.
Our results demonstrate that basic web scraping skills, familiarity with a headless browser like Playwright, and the ability to navigate HTML elements and classes using tools like Beautiful Soup or Scrapy will take your Glassdoor analysis to the next level. However, you will certainly run into anti-bot measures which will hinder your data collection efforts. To overcome such measures, you can use Bright Data's Scraping Browser. This tool also allows for targeted data collection based on geolocation thanks to its wide proxy network. Hence, it's always advisable to opt for an off-the-shelf scraping solution like the Scraping Browser for large-scale scraping projects.
Comments
Loading comments…