Introduction
When I was new in the Node.js world, I was wondering know how many requests can actually handle my Node.js application in production (as a real-world app). Or how many server instances do I need to handle a specific amount of traffic.
Last year I read something very interesting for me in an article from a unicorn company PicsArt. They handle 40K requests per second having Node.js (mostly) for the backend.
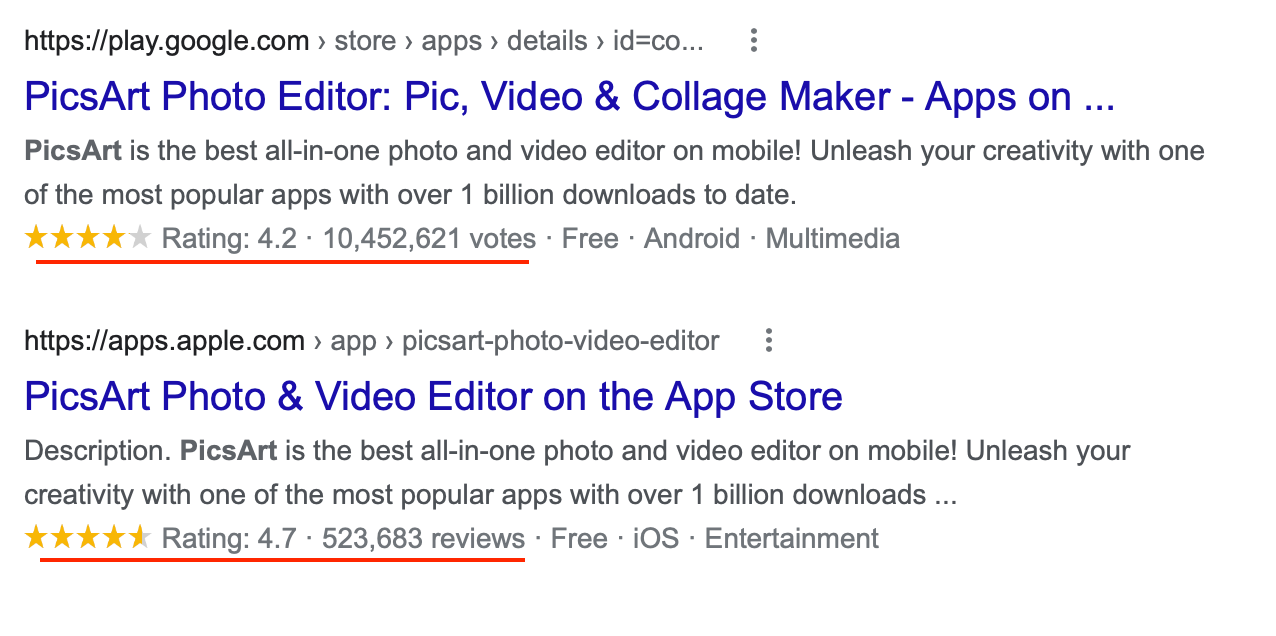
Well, 40K rps is really huge, and also depends on some other factors besides the backend server. But at this moment let’s forget about those factors and only think about the backend hardware and software, about Node.js particularly.
Research
Fastify benchmark
There’s a benchmark made by Fastify creators, it shows that express.js can handle ~15K requests per second, and the vanilla HTTP module can handle 70K rps.

I tried it with a Macbook Pro 15" 2015 and got almost the same result. Even 15K rps result by express.js sounds really great. But the benchmarks are usually made on a tiny API handler, which is far from a real-world API. So, what makes the API “real-world”? The data, the data transmission, and the interaction between components. To have a real-world API we have to create a handler that communicates with DB or other services.
My Experiment
These results aren’t so important. In most cases, proven frameworks like express(15K) are better, because, really, you are not going to handle 100K reqs per sec with a single instance. So, I installed express.js for my benchmarks and created a small API handler with various types of operations, and did load tests
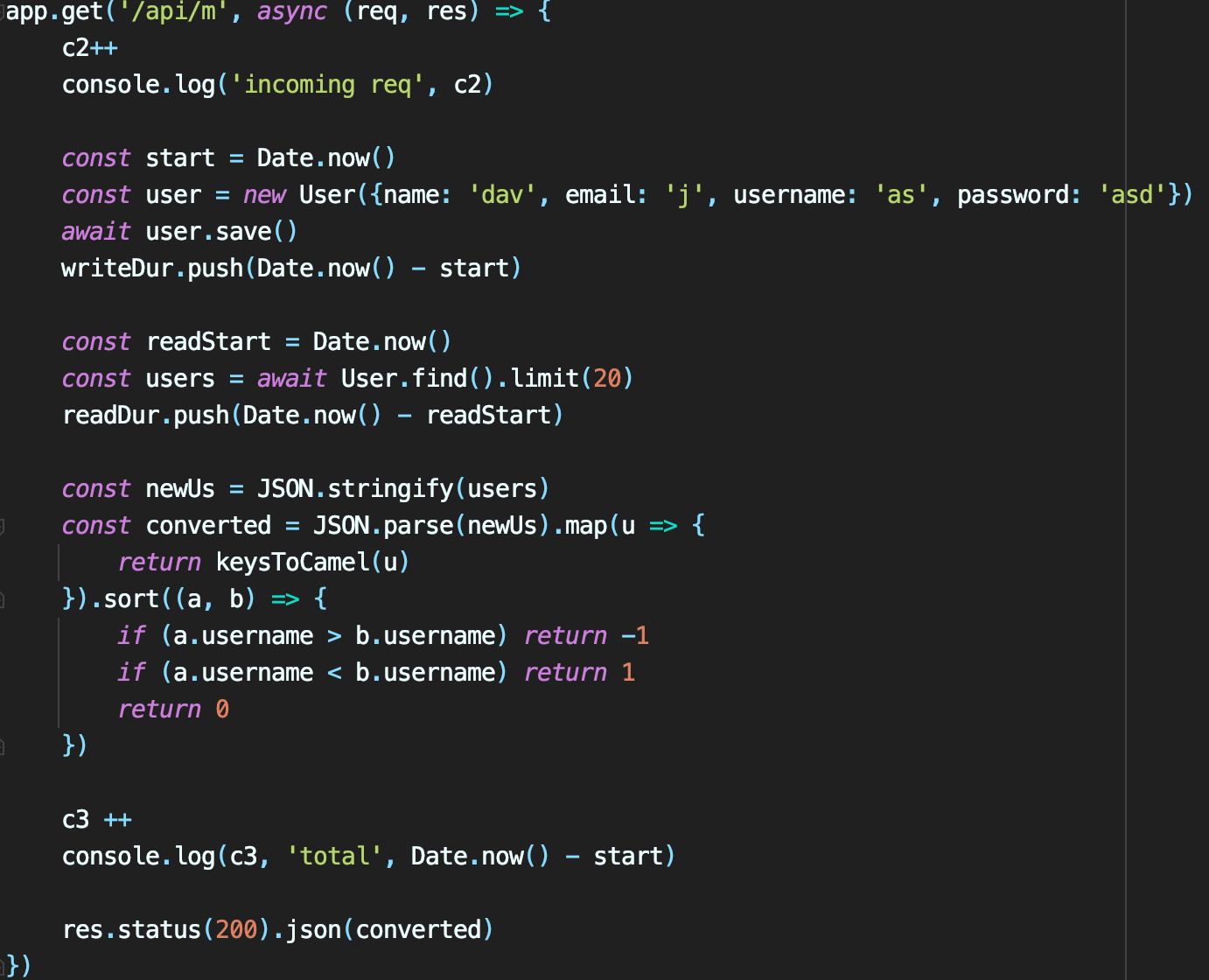 Api handler for the load tests
Api handler for the load tests
- Write a new user in the database
- Fetch 20 users from the database
- Stringify/Parse the array of 20 users
- Recursively convert to camelCase the 20 user objects
- Sort the array of 20 users
- Also some light computations and stdout (Date.now, console.log — they consume computation resources too)
The response size was around 12KB, each user object looked like this
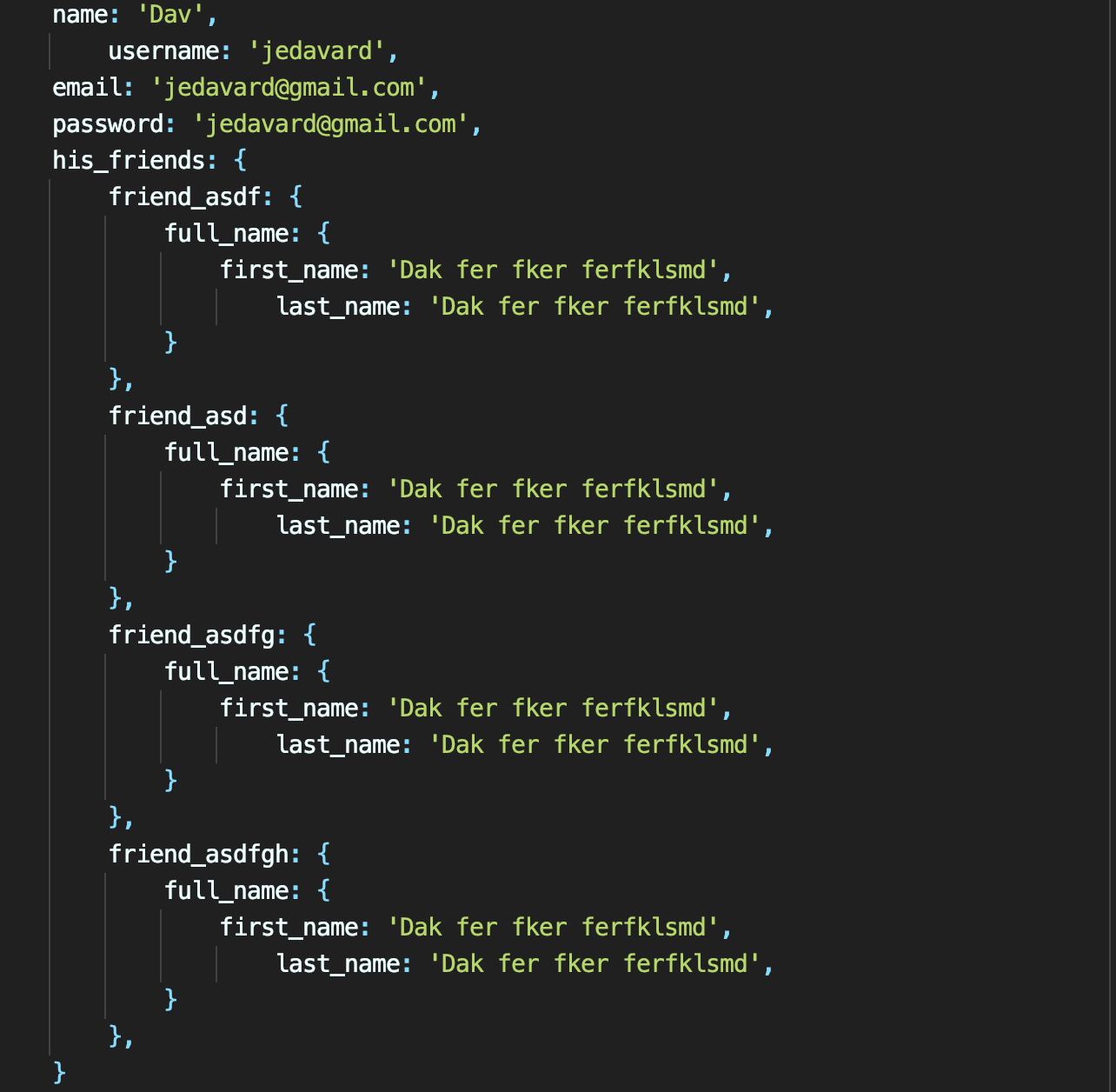 User object, 609 bytes of data
User object, 609 bytes of data
Node.js in Heroku with AWS RDS
I deployed the application in Heroku on $25/month hardware. Then I sent requests as much as I can do without increasing the average latency. So, my Node.js instance was capable to handle 31K requests in 60 seconds, which means an average of 515 requests per second.
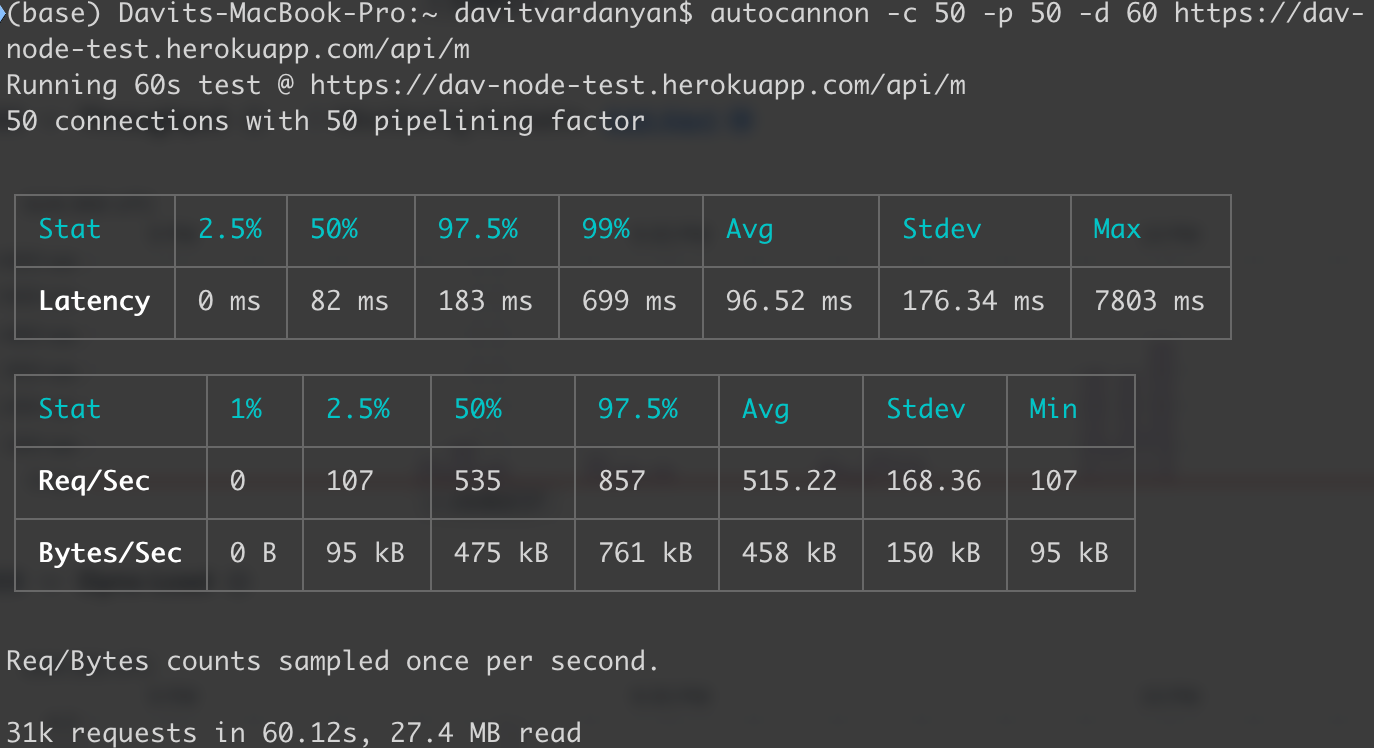 Node.js benchmark
Node.js benchmark
Django in Heroku with AWS RDS
Then, I asked what happens if I try the same with a technology that is not single-threaded. I created the exact same conditions for the Django app with an equivalent handler and deployed it to the same server. The results were a bit worse than in Node.js, I could reach up to 23K requests in 60 seconds, so, 389 requests per second.
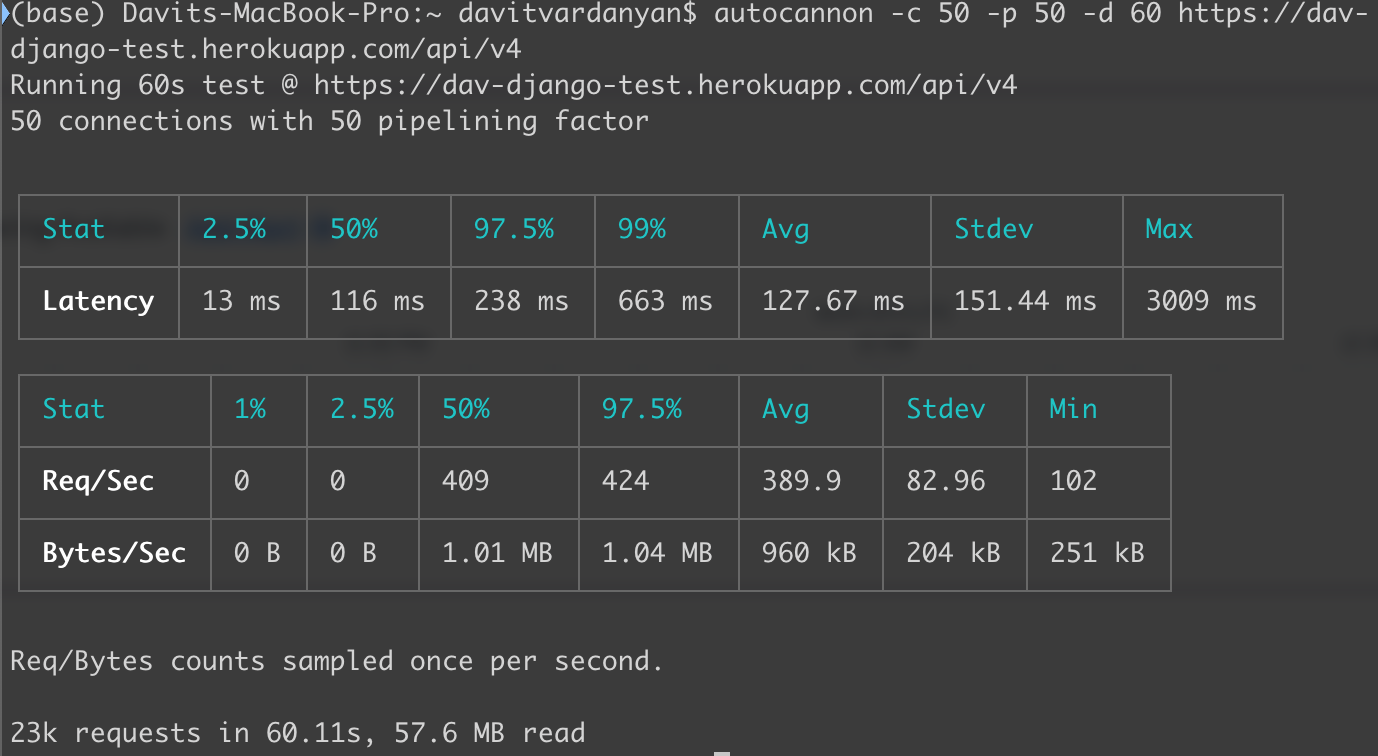 Django benchmark
Django benchmark
Node.js(3 instances) on AWS EB with AWS RDS
Then, I asked, what if my Node.js application is a real production application, and it’s deployed in AWS, up and running for specific traffic. I selected Frankfurt (eu-central-1, it was the nearest for me, around 3000km 😁) region for both DB and backend server. I used 3 Node.js instances with AWS load balancing for that test. My 3 instances were able to handle 19K requests in 10 seconds, which means 1858 requests per second. Then, I load tested my app continuously, I could reach 1.5 million successful requests in 13 minutes, which is exciting😁
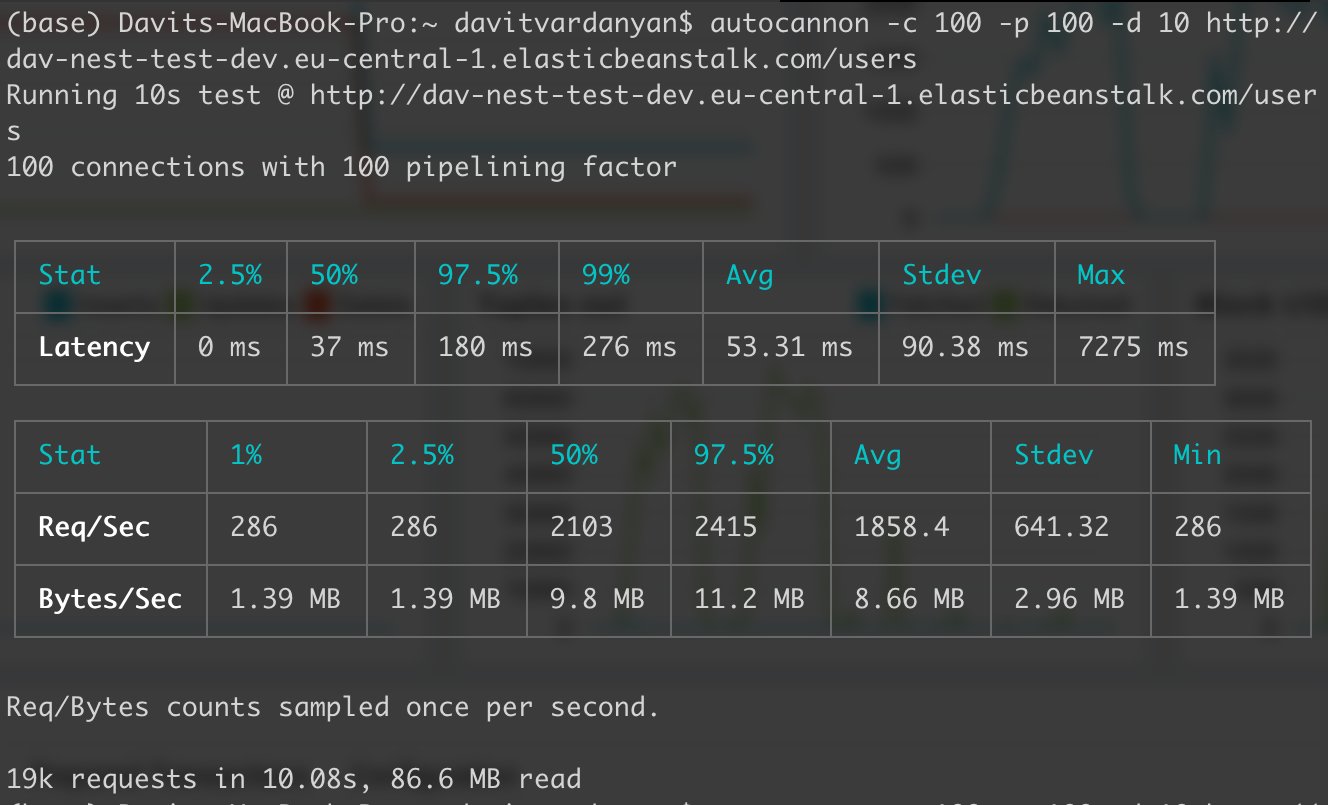 Node.js benchmark deployed on AWS EB
Node.js benchmark deployed on AWS EB
So, we handle 600rps with a single instance, what do we need for handling 40K requests per second? If the average API of our platform is let’s say twice**** bigger than in my test. So, I need 40.000/(600/2) = 133 instances over the world in different locations for a global scale unicorn app. Not a big deal😁
****it can be 3x bigger, but also it can use various caching techniques, event-based communication, etc to win more requests per second, so I think 2x bigger is the exact measure
I wanted to end this article with a useful list of some issues that you can face in the apps you work on or will work on.
Possible performance issues
There is an uncountable amount of factors that can slow down our API. I separated some performance-related parts that we can see in most web server-side apps.
-
The data size being stored or fetched from DB. Especially when we talk about relational DBs, it’s more important, because big data size mostly can mean complex queries or complex operations between the database management system and DB memory disk. However in all cases the more we have bytes, the more transmission time we need. We also should remember that saving files in DB is an antipattern, instead, we should consider using object storage. Ideally, our data size shouldn’t be more than tens of kilobytes, it’s usually ~1–20kb
-
The physical distance between the backend server and the DB server. More distance means more time for queries to be received by DB and sent back to our backend server. Consider an example, where we have two backend servers in Virginia, US, and Frankfurt, Germany, but we have a single DB server in Virginia, US. Our US user’s request will be routed to our US backend instance with a latency of ~10–40ms, and then 1–5ms will take the latency from backend(Virginia) to DB(Virginia). Not bad. Let’s see what would happen for a user from Germany, the “user’s device” — “backend server” latency will be 10–20ms, but for querying the data it would take 120–130ms. So if we have a single region app, ideally our data and our backend logic are neighbors. Or if we have a global scale app, we should be ready to do various complex engineering stuff to have a good performance
-
DB server hardware also has a big impact. If we have a small app, consider buying better hardware to suit our traffic, otherwise — “various complex engineering stuff” ☝️ 😁
-
DB configuration. Databases come with a default configuration to avoid their management being an additional headache. Depending on our scale we will be deal with it. One thing I want to mention is maximum connection count, it can be a bottleneck in our app or overwhelming for our DB server. It’s usually re-configured by DB client libs(ORMs, etc..). The other thing is connection timeout.
-
The number of DB calls. In a real-world API, we can have, like, tens of separate DB calls to finally get the job done, besides in that API we can also have service calls, and each of those services has its own “tens of DB calls”. An impressive example I met, was in a project I joined a long while ago, a banking monolith backend API. There was an API with 9s response time in the cloud dev environment. The service handler under this API had 300 lines of code where we could find around 30 DB calls and around 10 internal service calls. It usually happens when our approach is “code first” instead of “design first”. There are many solutions that help to avoid this depending on our business logic. For example, queues and other asynchronous measures can give us the possibility to handle some amount of DB calls in the “background”. In order to take advantage of this, we will need to break our big services into small services. Also, we can join queries in order to decrease the number of DB calls.
-
Hooks. In all popular ODM/ORMs, there is a feature called hooks/middlewares. Sometimes it’s really comfortable to let this feature take care of some logic. And sometimes, especially while working with bulk operations we can face a “hidden” bottleneck. ODM/ORM plugins need for computing resource too, means take time too (e.g. plugin for camelCase/pascal_case conversion). Hooks are really helpful but need to double-think what we write and where we write.
-
CPU-intensive tasks not only slow down the server but also make the end-user wait. In Node.js many CPU-intensive tasks rely on the thread pool. Although it doesn’t block the asynchronous IO, it makes the API be slower. For example, a user clicks to sign-up and waits for the thread pool to hash his/her password, and it takes, by the way, 100 and milliseconds.
-
Event loop bottlenecks. In Node.js the code execution relies on the event loop, so our code’s performance has a direct impact on the entire application (as it’s up and working on a single thread). For example, using JSON.parse/stringify can slow down our APIs. Nested loops and recursive functions are also dangerous. When ignoring how Node.js works, depending on the data size and app traffic we can run into a problem, and our application can be unavailable.
-
Bad infrastructure architecture. The possible problems in a large infrastructure aren’t just more than in monolith applications, they are different and sometimes they need complex architectural solutions. When our infrastructure contains many components, bad architecture can have a huge impact on our APIs, and our system will work in a resource-inefficient way, which means we will pay more for the same that we could have cheaper. So, while designing complex applications, we must think about the problems that a specific technology solves and be well-informed about the alternatives. We also need to think about perspectives, what happens if we have business requirement changes in two months, or in six months while making a feature, on every statement try to guess as much as we can. Think about the SLA. Think about the non-function requirements, what if the traffic goes up? Always be ready for unexpected high traffic, even there’s a theory that says we must be ready to handle 10x more traffic than we have.
-
Component scale/hardware/set-up. The components that we created in our infrastructure can slow down our entire platform. Let’s think that we use RabbitMQ. It has tons of configurations and options like any technology. And if we go with standards at the beginning, it’s ok. But, with time if we do more researches, if we go deeper into a specific component, we realize that we can improve our infrastructure a lot by doing some set-up review, or by doing refactor of the configuration or usage in our services. Also, we must scale up our components depending on the usage to do not create a bottleneck in the infrastructure.
Thanks for reading. And if you like performance-related articles, don’t forget to clap, it will help me to prepare more well-thought-out articles with deeper insights.
Comments
Loading comments…