Introduction
BERT, or Bidirectional Encoder Representations from Transformers, is a powerful language model developed by Google. It has been widely used in natural language processing tasks such as sentiment analysis, text classification, and named entity recognition. One of the key features of BERT is its ability to generate word embeddings, which are numerical representations of words that capture their meaning and relationships with other words.
Concept
Word embeddings are vector representations of words that capture their semantic meaning. They are used in natural language processing tasks to represent words as numerical values that can be fed into machine learning algorithms. BERT generates word embeddings by taking into account the context in which a word appears, making its embeddings more accurate and useful than traditional methods such as bag-of-words or TF-IDF.
Methods for Generating Word Embeddings using BERT
There are several methods for generating word embeddings using BERT, including:
Method 1: Using the Transformers Library
One of the easiest ways to generate word embeddings using BERT is to use the transformers library by Hugging Face. This library provides an easy-to-use interface for working with BERT and other transformer models.
Here are the steps to generate word embeddings using this method:
- Install the necessary libraries: To generate word embeddings using BERT, you will need to install the
transformerslibrary.
Python
!pip install transformers
- Load the BERT model: Once you have installed the necessary libraries, you can load a pre-trained BERT model using the
transformerslibrary. There are several versions of BERT available, so choose the one that best fits your needs.
from transformers import BertModel, BertTokenizer
model = BertModel.from_pretrained('bert-base-uncased')
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')

💡 Learn how to use the zip method to convert lists into dictionaries in Python:
How to Use the Zip Method to Convert Lists into Dictionaries
👉 To read more such acrticles, sign up for free on Differ.
3. Tokenize your text: Before you can generate word embeddings, you need to tokenize your text into individual words or subwords using the BERT tokenizer. This will convert your text into a format that can be fed into the BERT model.
text = "This is an example sentence."
tokens = tokenizer.tokenize(text)
print(tokens)
['this', 'is', 'an', 'example', 'sentence', '.']
- Convert tokens to input IDs: Once you have tokenized your text, you need to convert the tokens into input IDs, which are numerical representations of the tokens that can be fed into the BERT model.
input_ids = tokenizer.convert_tokens_to_ids(tokens)
print(input_ids)
[2023, 2003, 2019, 2742, 6251, 1012]
5. Generate word embeddings: Finally, you can generate word embeddings for each token by feeding the input IDs into the BERT model. The model will return a tensor containing the embeddings for each token in your text.
import torch
input_ids = torch.tensor(input_ids).unsqueeze(0)
with torch.no_grad():
outputs = model(input_ids)
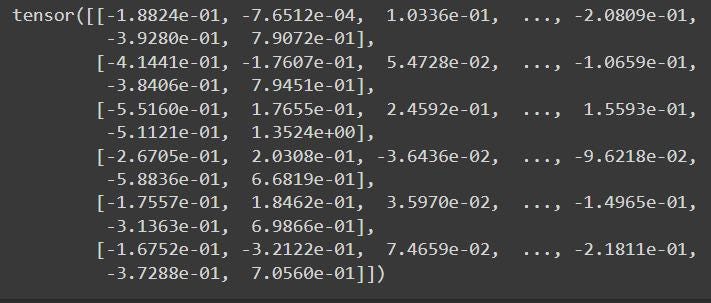
embeddings = outputs.last_hidden_state[0]
print(embeddings)
Method 2: Using TensorFlow
Another way to generate word embeddings using BERT is to use TensorFlow, a popular machine-learning framework. This method requires more setup than using the transformers library but gives you more control over the process.
Here are the steps to generate word embeddings using this method:
1. Install the necessary libraries: To generate word embeddings using BERT with TensorFlow, you will need to install TensorFlow and TensorFlow Hub.
Python
!pip install tensorflow tensorflow_hub
2. Load the BERT model: Once you have installed the necessary libraries, you can load a pre-trained BERT model from TensorFlow Hub.
Python
import tensorflow as tf
import tensorflow_hub as hub
bert_layer = hub.KerasLayer("https://tfhub.dev/tensorflow/bert_en_uncased_L-12_H-768_A-12/4", trainable=False)
3. Tokenize your text: Before you can generate word embeddings, you need to tokenize your text into individual words or subwords using the BERT tokenizer provided by TensorFlow Hub.
from bert.tokenization import FullTokenizer
vocab_file = bert_layer.resolved_object.vocab_file.asset_path.numpy()
do_lower_case = bert_layer.resolved_object.do_lower_case.numpy()
tokenizer = FullTokenizer(vocab_file, do_lower_case)text = "This is an example sentence."
tokens = tokenizer.tokenize(text)
print(tokens)
4. Convert tokens to input IDs: Once you have tokenized your text, you need to convert the tokens into input IDs, which are numerical representations of the tokens that can be fed into the BERT model.
input_ids = tokenizer.convert_tokens_to_ids(tokens)
print(input_ids)
5. Generate word embeddings: Finally, you can generate word embeddings for each token by feeding the input IDs into the BERT model. The model will return a tensor containing the embeddings for each token in your text.
input_ids = tf.expand_dims(input_ids, 0)
outputs = bert_layer(input_ids)
embeddings = outputs["sequence_output"][0]
print(embeddings)
Contextualized Word Embeddings with BERT
Here’s an example of how you can use BERT to generate contextualized word embeddings for a list of sentences:
1. Setup
import pandas as pd
import numpy as np
import torch
Next, we install the transformers package from Hugging Face which will give us a pytorch interface for working with BERT. We’ve selected the PyTorch interface because it strikes a nice balance between the high-level APIs (which are easy to use but don’t provide insight into how things work) and TensorFlow code (which contains lots of details but often sidetracks us into lessons about TensorFlow, when the purpose here is BERT).
!pip install transformers
Next :
from transformers import BertModel, BertTokenizer
model = BertModel.from_pretrained('bert-base-uncased',
output_hidden_states = True,)
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')

2. Create contextual embeddings
We have to put the input text into a specific format that BERT can read. Mainly we add the [CLS] to the beginning and [SEP] to the end of the input. Then we convert the tokenized BERT input to the tensor format.
def bert_text_preparation(text, tokenizer):
"""
Preprocesses text input in a way that BERT can interpret.
"""
marked_text = "[CLS] " + text + " [SEP]"
tokenized_text = tokenizer.tokenize(marked_text)
indexed_tokens = tokenizer.convert_tokens_to_ids(tokenized_text)
segments_ids = [1]*len(indexed_tokens)
# convert inputs to tensors
tokens_tensor = torch.tensor([indexed_tokens])
segments_tensor = torch.tensor([segments_ids])
return tokenized_text, tokens_tensor, segments_tensor
To obtain the actual BERT embeddings, we take preprocessed input text, which now is represented by tensors, and put it into our pre-trained BERT model.
Which vector works best as a contextualized embedding? it depends on the task. The original paper that proposed BERT examines six choices. we go with one of these choices that worked well in their experiments, which is the sum of the last four layers of the model.
def get_bert_embeddings(tokens_tensor, segments_tensor, model):
"""
Obtains BERT embeddings for tokens, in context of the given sentence.
"""
# gradient calculation id disabled
with torch.no_grad():
# obtain hidden states
outputs = model(tokens_tensor, segments_tensor)
hidden_states = outputs[2]
# concatenate the tensors for all layers
# use "stack" to create new dimension in tensor
token_embeddings = torch.stack(hidden_states, dim=0)
# remove dimension 1, the "batches"
token_embeddings = torch.squeeze(token_embeddings, dim=1)
# swap dimensions 0 and 1 so we can loop over tokens
token_embeddings = token_embeddings.permute(1,0,2)
# intialized list to store embeddings
token_vecs_sum = []
# "token_embeddings" is a [Y x 12 x 768] tensor
# where Y is the number of tokens in the sentence
# loop over tokens in sentence
for token in token_embeddings:
# "token" is a [12 x 768] tensor
# sum the vectors from the last four layers
sum_vec = torch.sum(token[-4:], dim=0)
token_vecs_sum.append(sum_vec)
return token_vecs_sum
Now we can create contextual embeddings for a set of contexts.
sentences = ["bank",
"he eventually sold the shares back to the bank at a premium.",
"the bank strongly resisted cutting interest rates.",
"the bank will supply and buy back foreign currency.",
"the bank is pressing us for repayment of the loan.",
"the bank left its lending rates unchanged.",
"the river flowed over the bank.",
"tall, luxuriant plants grew along the river bank.",
"his soldiers were arrayed along the river bank.",
"wild flowers adorned the river bank.",
"two fox cubs romped playfully on the river bank.",
"the jewels were kept in a bank vault.",
"you can stow your jewellery away in the bank.",
"most of the money was in storage in bank vaults.",
"the diamonds are shut away in a bank vault somewhere.",
"thieves broke into the bank vault.",
"can I bank on your support?",
"you can bank on him to hand you a reasonable bill for your services.",
"don't bank on your friends to help you out of trouble.",
"you can bank on me when you need money.",
"i bank on your help."
]
Python
from collections import OrderedDict
context_embeddings = []
context_tokens = []
for sentence in sentences:
tokenized_text, tokens_tensor, segments_tensors = bert_text_preparation(sentence, tokenizer)
list_token_embeddings = get_bert_embeddings(tokens_tensor, segments_tensors, model)
# make ordered dictionary to keep track of the position of each word
tokens = OrderedDict()
# loop over tokens in sensitive sentence
for token in tokenized_text[1:-1]:
# keep track of position of word and whether it occurs multiple times
if token in tokens:
tokens[token] += 1
else:
tokens[token] = 1
# compute the position of the current token
token_indices = [i for i, t in enumerate(tokenized_text) if t == token]
current_index = token_indices[tokens[token]-1]
# get the corresponding embedding
token_vec = list_token_embeddings[current_index]
# save values
context_tokens.append(token)
context_embeddings.append(token_vec)
3. Compare Results
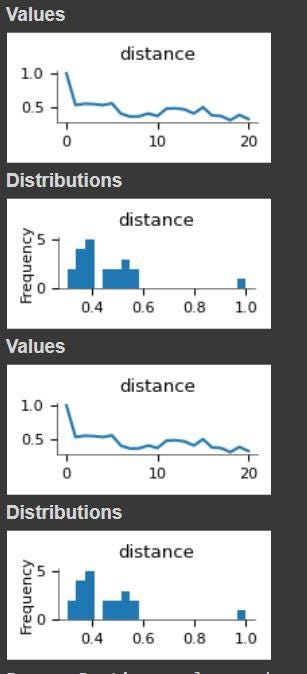
Now that we have the contextual embeddings for the word “record”, we can calculate its similarity with its polysemous siblings and the static embedding.
from scipy.spatial.distance import cosine
# embeddings for the word 'record'
token = 'bank'
indices = [i for i, t in enumerate(context_tokens) if t == token]
token_embeddings = [context_embeddings[i] for i in indices]
# compare 'record' with different contexts
list_of_distances = []
for sentence_1, embed1 in zip(sentences, token_embeddings):
for sentence_2, embed2 in zip(sentences, token_embeddings):
cos_dist = 1 - cosine(embed1, embed2)
list_of_distances.append([sentence_1, sentence_2, cos_dist])
distances_df = pd.DataFrame(list_of_distances, columns=['sentence_1', 'sentence_2', 'distance'])
distances_df[distances_df.sentence_1 == "bank"]
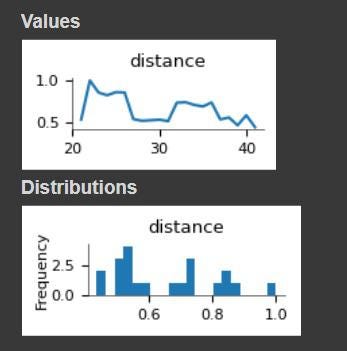
distances_df[distances_df.sentence_1 == "he eventually sold the shares back to the bank at a premium."]
Advantages
Contextualized embeddings: BERT generates word embeddings that take into account the context in which a word appears, making its embeddings more accurate and useful than traditional methods such as bag-of-words or TF-IDF.
Transfer learning: BERT is a pre-trained model that can be fine-tuned for specific natural language processing tasks, allowing you to leverage the knowledge it has learned from large amounts of text data to improve the performance of your models.
State-of-the-art performance: BERT has achieved state-of-the-art performance on a wide range of natural language processing tasks, making it a powerful tool for generating high-quality word embeddings.
Disadvantages
Computational cost: BERT is a large and complex model that requires significant computational resources to generate word embeddings, making it less suitable for use on low-power devices or in real-time applications.
Limited interpretability: The word embeddings generated by BERT are high-dimensional vectors that can be difficult to interpret and understand, making it challenging to explain the behavior of models that use these embeddings.
Differentiators
The main differentiator of BERT compared to other methods for generating word embeddings is its ability to generate contextualized embeddings that take into account the context in which a word appears. This allows BERT to capture subtle differences in meaning and usage that other methods may miss.
Future Scope
The field of natural language processing is rapidly evolving, and new techniques and models are being developed all the time. Future developments will likely continue to improve the accuracy and usefulness of word embeddings generated by BERT and other models. Additionally, there is ongoing research into making BERT and other large language models more efficient and interpretable, which could further expand their applicability and usefulness.
Applications
Word embeddings generated by BERT can be used in a wide range of natural language processing tasks, including:
Sentiment analysis: By representing text as numerical values using word embeddings, machine learning algorithms can be trained to automatically classify the sentiment of text as positive, negative, or neutral.
Text classification: Word embeddings can be used to represent text documents as numerical values, allowing machine learning algorithms to automatically classify them into different categories or topics.
Named entity recognition: By using word embeddings to represent text, machine learning algorithms can be trained to automatically identify and extract named entities such as people, organizations, and locations from text.
Conclusion
Generating word embeddings using BERT is a powerful way to represent words as numerical values that capture their meaning and relationships with other words. There are several methods for generating word embeddings using BERT, including using the transformers library or TensorFlow. By following the steps outlined above, you can easily generate word embeddings for your text data and use them in natural language processing tasks.
Comments
Loading comments…