There are two ways to read & write files; 1. buffer 2. stream
General Concept of Buffer and Streaming
-
Buffer or Buffering and Streaming is often used for video player in Internet such as Youtube
-
Buffering is an action to collect the data to play the video
-
Streaming is transmitting the data from server to the viewer’s computer
Concept of Buffer and Streaming in Node.js
Buffer and Stream in Node.js are actually similar to the general concepts
-
When reading a file, Node.js allocates memory as much as the size of a file and saves the file data into the memory
-
Buffer indicates the memory where file data resides
Buffer
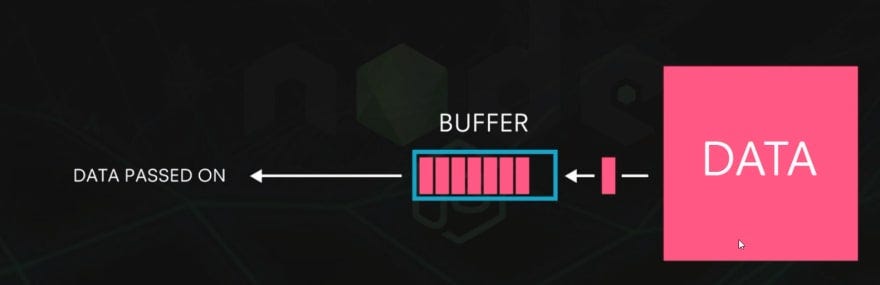
Node.js has a internal buffer object called Buffer
const buffer = Buffer.from("Change me to buffer");
console.log("from()", buffer);
// from() <Buffer 43 68 61 6e 67 65 20 6d 65 20 74 6f 20 62 75 66 66 65 72>
console.log("length", buffer.length);
// length 19
console.log("toString()", buffer.toString());
// toString() Change me to buffer
const array = [
Buffer.from("skip "),
Buffer.from("skip "),
Buffer.from("skipping "),
];
const buffer2 = Buffer.concat(array);
console.log("concat():", buffer2.toString());
// concat(): skip skip skipping
const buffer3 = Buffer.alloc(5);
console.log("alloc():", buffer3);
// alloc(): <Buffer 00 00 00 00 00>
**Buffer **object has many methods available
-
from(
) : Convert String to Buffer -
toString(
) : Convert Buffer to String -
concat(
- )
-
alloc(
) : Create empty buffer in given byte length
Problem of Buffer
-
readFile() buffer method is convenient but has a problem that you need to create 100MB buffer in a memory to read 100MB file
-
If you read 10 100MB files, then you allocate 1GB memory just to read 10 files
-
Especially, it becomes a big problem for a server, given that you do not know how many people are going to use (read file) concurrently
Stream

Node.js has a internal stream method called createReadStream
readme3.txt
I am tranferring in bytes by bytes called chunk
createReadStream.js
const fs = require("fs");
const readStream = fs.createReadStream("./readme3.txt", { highWaterMark: 16 });
const data = [];
readStream.on("data", (chunk) => {
data.push(chunk);
console.log("data :", chunk, chunk.length);
// data : <Buffer 49 20 61 6d 20 74 72 61 6e 73 66 65 72 72 69 6e> 16
// data : <Buffer 67 20 69 6e 20 62 79 74 65 73 20 62 79 20 62 79> 16
// data : <Buffer 74 65 73 20 63 61 6c 6c 65 64 20 63 68 75 6e 6b> 16
});
readStream.on("end", () => {
console.log("end :", Buffer.concat(data).toString());
// end : I am transferring in bytes by bytes called chunk
});
readStream.on("error", (err) => {
console.log("error :", err);
});
-
createReadStream() methods takes 2 parameters
-
In the first parameter, we specify the file path
-
The second parameter is an optional and highWaterMark option helps determining the size of buffers (By default, 64KB but in this case, 16 bytes)
-
readStream is used using event listeners such as **data , end , error **events
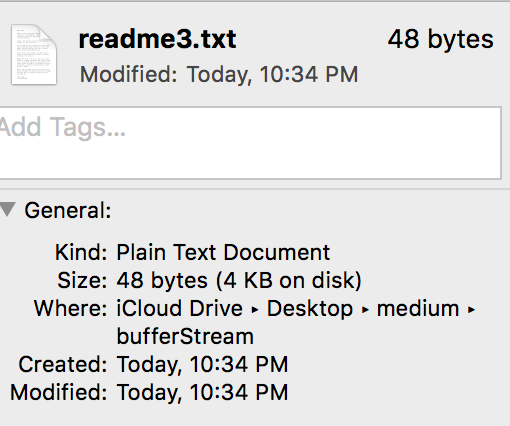
- Since file size is 48 bytes and we set data transferring capacity to 16 bytes (**highWaterMark **option), we can see that it completes the transmitting of the data in 3 times
Conclusion
Stream has following benefits over Buffer
-
continuous chunking of data ( it can arguably transmit any number of large files given infinite time) whereas Buffer has limitations in transferring large data
-
no need to wait for the entire resource to load whereas Buffer needs to do buffering (waiting)
Thank you
Comments
Loading comments…