Enterprises have diverse data dependencies - internal microservices with specialized data domains, legacy systems with proprietary data formats, and third-party APIs and SaaS applications with their unique data models and endpoints.
TL;DR: different (and often legacy) technologies that need to be brought together, somehow.
Federated GraphQL has emerged as the go-to solution for such composition in the enterprise sphere, and the Router (or, Gateway) in Federation acts as the linchpin that binds all these disparate data sources together, making them accessible through a single, cohesive API, while still ensuring adaptability. It is, in fact, key to how Federated GraphQL allows for scalable and modular architectures.
Today, we'll look at WunderGraph Cosmo's high-performance, open-source, Federation V1/V2 compatible Router. We'll cover what it does, why it's so important to the Cosmo stack, how you can host it yourself, and even customize and extend it with Go code of your own.
WunderGraph Cosmo - A Primer
WunderGraph Cosmo is a fully open source (Apache 2.0 License) platform to build, manage, and collaborate on federated graphs at scale. It's a drop-in replacement for Apollo GraphOS/Studio, and is an all-in-one solution that contains a schema registry that can check for breaking changes and composition errors, a blazingly fast Federation V1/V2 compatible Router, and an analytics/distributed tracing platform for federated GraphQL.
GitHub - wundergraph/cosmo: The open-source alternative to Apollo GraphOS. Building, maintaining... *The open-source alternative to Apollo GraphOS. Building, maintaining, and collaborating on GraphQL Federation at Scale...*github.com
The Cosmo stack is opinionated, and optimized for maximum efficiency and performance. It includes:
- the Studio (GUI web interface) and the
wgc(command-line tool) for managing the platform as a whole - schemas, users, and projects - and accessing analytics/traces. - the Router as the component that actually implements GraphQL Federation, routing requests and aggregating responses.
- the Control Plane, the heart of the platform, providing the core APIs that both the Studio/CLI and the Router consume.
For hosting, you can run the entire platform on-prem on any Kubernetes service (AWS, Azure, Google for production, and Minikube for local dev), or use the managed Cosmo Cloud for all stateful components while you host the stateless router yourself.
The Cosmo Router
The Cosmo Router (which you can find in the Cosmo monorepo) is an open source (Apache 2.0 license) alternative to the Apollo Gateway or Router. It is a HTTP server written in Golang that is the central entry point for your federated GraphQL architectures, and is responsible for routing queries to the correct microservice/subgraph, aggregating their responses, and sending it back to the client in one cohesive format. You can even customize it with pure Go code of your own.
The Router is compatible with Apollo Federation v1 and v2, as well as Open Federation, an open-source specification for federated GraphQL.
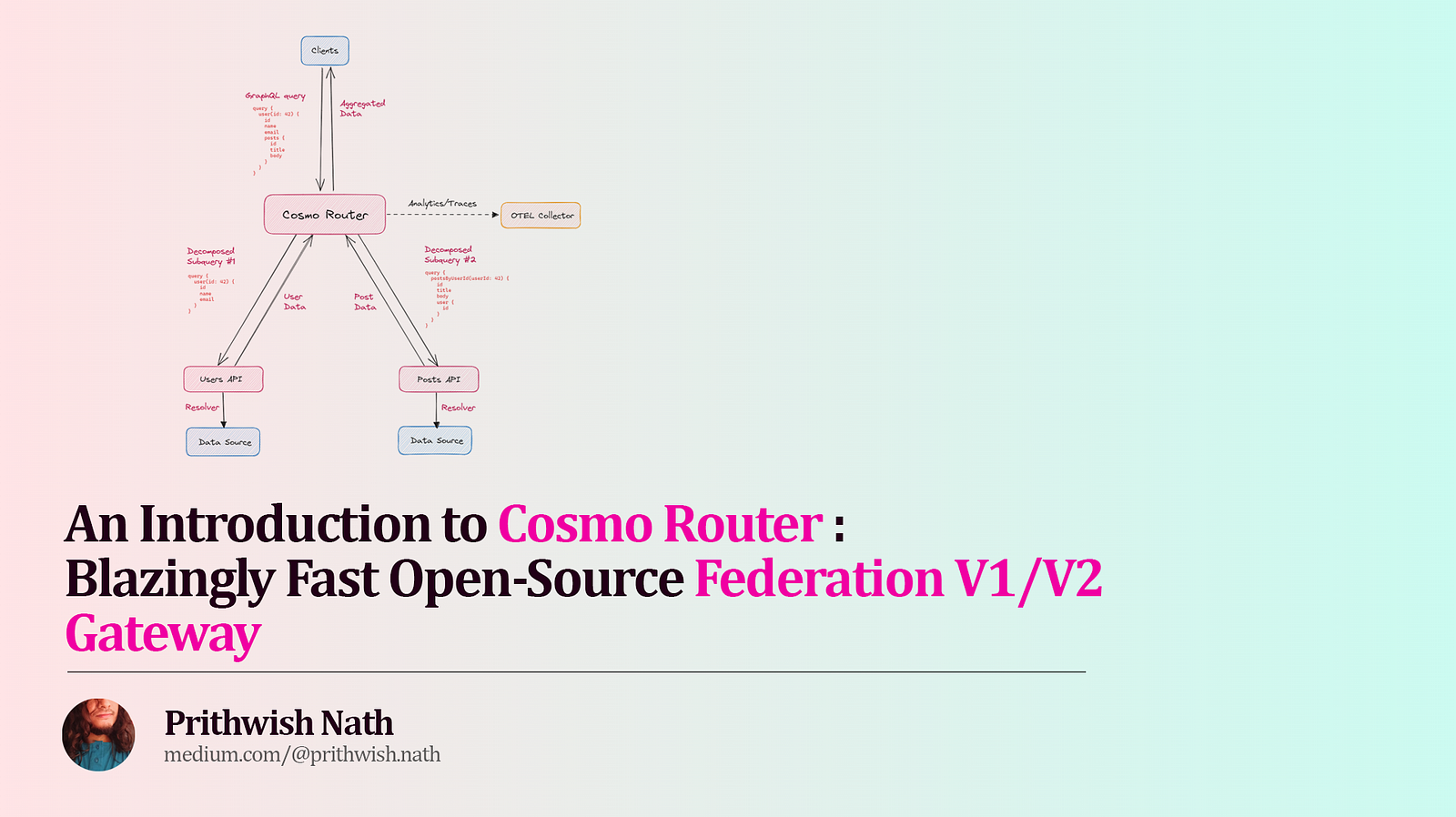
1. How it works
Clients make GraphQL requests to the Router's endpoint, and it intelligently routes these requests to services that can resolve them. Here's what happens when the Router receives a client request.
- Before anything, it needs access to the Federated graph's schema, which includes the types, fields, and metadata of each subgraph schema, along with their endpoints. This is periodically fetched from a high-availability CDN to make sure the Router has the latest config.
- It uses this configuration to generate an optimized Query Plan - cached across requests to minimize work done - to determine how best to decompose the client query into multiple subqueries, which subqueries can be run in parallel and which must proceed sequentially, and how to merge their responses.
- The Router then uses the Query Plan to perform the required decomposition into multiple subqueries, and executes them. Each subquery corresponds to a microservice/subgraph that can fulfill a portion of the overall request.
- Finally, the Router collates the partial result from each of these subqueries, combines, and assembles them into a cohesive response that matches the structure of the original client query - sending back this assembled response to the client.
The Router makes it so this process is completely opaque to the client. As far as the latter is concerned, the Router was the only endpoint queried for the data, and the federated schema was the only API in play.
2. Performance
The Cosmo Router is powered by graphql-go-tools, a highly mature and optimized GraphQL engine (MIT License) that is the fastest and most reliable implementation for Federation V1. The Cosmo Router builds on it with its own optimizations.
GitHub - wundergraph/graphql-go-tools: Tools to write high performance GraphQL applications using...
Plus, Go itself is designed for performance, having a small memory footprint and fast execution speed, and compiles to machine code directly (as opposed to something like NodeJS, which depends on the JavaScript V8 engine and has some overhead).
Let's take a look at two ways the Cosmo Router gets big performance gains.
Batching
When you request data that involves nested relationships across different services (and thus remote joins), say, a User and their Posts, the naïve implementation makes one separate query to resolve the posts field for each User's Posts.
query {
allUsers {
id
name
posts {
id
title
content
}
}
}
Why is this inefficient? Well, how many times are you actually hitting data sources?
- You fetch all Users in one query (that's 1 query, to the Users service).
- For each user, you make a separate query to retrieve their Posts (that's an additional N queries to the Posts service, where N is the number of Users).
So, if you have 100 users, that's 1 + 100 = 101 calls made. This is the infamous N+1 problem. With GraphQL, we've moved it to the server rather than the client, but it exists regardless, and can slow data fetching to a crawl as the number of Users grows, or if you have further nested data.
The Cosmo Router uses a customized DataLoader pattern (if you're not familiar with the base implementation, see Lee Byron's video here.) to solve this, out of the box. Instead of making separate requests for each User, the Router analyzes the client query ahead of execution to determine which join keys would be required to resolve the remote Posts relationship, and modifies the first subquery (fetching all Users) to also extract those - in this case, our join key would be author_id's.
TL;DR: Instead of...
SELECT _ FROM Posts WHERE author_id = 1;
SELECT _ FROM Posts WHERE author_id = 2;
-- ...
SELECT * FROM Posts WHERE author_id = N;
DataLoader lets you do...
SELECT * FROM Posts WHERE author_id IN (1, 2, ...N);
How efficient is this new method? Let's see how many queries you're making now:
- As usual, you fetch all Users (that's 1 query).
- Cosmo Router now batches the Posts retrieval for all 10 users into a single query (that's 1 more query).
So, in total, you're now only making 1 + 1 = 2 queries to fetch all the required data, regardless of the number of Users. A significant improvement to the naïve N+1 approach.
Cosmo's DataLoader is a specialized implementation that does far more than this. In GraphQL servers, the default behavior is to resolve fields **depth-first ** - like going through a list of items one by one, exhaustively resolving each item before moving to the next. Cosmo's DataLoader 3.0 pattern instead splits the traditional resolver process into two distinct steps:
- Breadth-First Data Loading: In the first step, the system walks through the query plan breadth-first. This means it identifies all the data needed from the subgraphs across the fields, loads them, and then merges the results collated from these subgraphs into a single JSON object.
- Depth-First Response Generation: After merging the data into a single JSON object, the second step involves walking through this merged JSON object depth-first - constructing a response JSON for the client, according to the structure of the GraphQL Query received from it. This step essentially assembles the final response that will be sent back to the client.
Instead of drilling down into each branch to its deepest level before moving on, Cosmo's approach gathers data from sibling fields concurrently. This means that as we traverse the query, it collects data from multiple items (siblings) at the same level in the tree structure simultaneously.
Since we are processing sibling fields together, we can automatically batch together the requests for these fields. This batching reduces the number of individual requests made to fetch data, leading to significantly improved efficiency and performance in GraphQL query resolution over the vanilla DataLoader implementation, and is specifically optimized for resolving deeply nested relationships - leading to massive performance gains.
Ludicrous Mode
When multiple identical requests (asking for the same data) are "in-flight" simultaneously (being processed simultaneously), the Cosmo Router intelligently sends only one request to the origin server, and shares the result with all other active requests.
Cosmo calls this the 'Ludicrous Mode' for the Router, and when enabled, it eliminates redundant requests for the same data, optimizing network traffic and reducing the load on the origin server.
While Ludicrous Mode is very situational, and of course doesn't eliminate the need for processing each client request individually, it is particularly valuable when dealing with frequently executed, read-only requests (e.g. resolving nested lists of entities).
3. 'Stateless'
Because the Router itself doesn't store any session-specific data between requests, each request it handles is independent. Multiple instances of the Router can thus be provisioned according to your requirements, and building your federated GraphQL architecture with the Cosmo Router means you'll be able to scale horizontally to handle large numbers of incoming, concurrent requests - a common requirement in enterprise environments.
The predictability gained here is crucial for maintaining (and debugging) a reliable system. Also, being stateless makes your unified API resilient. If one hosted instance of the Router fails, another can seamlessly take over because there's no session state that needs to be preserved.
The statelessness of the Router is by design, and it ensures scalability and flexibility in the architecture. Each of the actual services (which contains the resolver functions for specific types and fields) is responsible for managing its own state, instead. This allows your services to be developed and scaled independently.
4. Customization
You can extend the functionality of the Cosmo Router by creating custom modules, written in Go.
To create a custom module, you need to implement one or more of these predefined interfaces:
- core.RouterMiddlewareHandler - A custom middleware function that will be called for every single client request that goes through the Router. For example, you could create middleware that logs incoming GraphQL requests and responses, add or modify headers in the request or response, cache the results of frequently executed queries, validate incoming GraphQL requests and reject invalid queries/mutations before they reach the GraphQL Engine, and more.
- **core.EnginePreOriginHandler ** - A custom handler that runs before a request is forwarded to a subgraph, called for every subgraph request. You could use it for logging (for debugging/auditing) or header manipulation (for custom auth, security, etc.)
- **core.EnginePostOriginHandler ** - A custom handler that runs after a request has been sent to a subgraph but before a response has been passed to the GraphQL Engine, called for every subgraph response. You could use this to cache the response (in-memory or Redis), or intercept and handle errors that occur in the subgraph response - logging errors, or formatting error responses consistently for the client.
- core.Provisioner - Implements a Module lifecycle hook that is executed when the module is being instantiated. Use it to prepare your module and validate the configuration. You can use this hook to configure internal state, or perform any pre-init tasks like resource allocation (establishing a database connection pool), or checking that all required configuration values are present and that they have valid formats and values (and raise exceptions if not).
- **core.Cleaner ** - Implements a Module lifecycle hook that is executed after the server is shutdown. The converse of core.Provisioner, it is used to deallocate resources, shut down connections gracefully, and perform any other necessary cleanup.
This approach offers a level of customizability similar to what xcaddy does for the Caddy server, eliminating the complexities associated with writing Rhai scripts to customize a precompiled binary, as is the case with the Apollo Router.
5. Analytics - OpenTelemetry, Prometheus, and RED Metrics
The Cosmo Router has been instrumented with OpenTelemetry - an open source observability framework that can collect, process, and export metrics, traces, and logs from applications and services. The Router pushes performance metrics to an OTEL Collector, giving you an end-to-end view of the path taken by your API traffic on a per-request level through your federated graph, along with the specific operation performed in the request.
You can even combine this with OTEL metrics pushed by your subgraphs, to have full control over optimizing your infrastructure. You can read more about instrumenting your individual services/subgraphs with OTEL here.
If you're using the all-in-one WunderGraph Cosmo platform, you can visualize this data and see exactly how a request progresses through different services in the Analytics tab of your Cosmo dashboard.
If you're only using the Cosmo Router, any backend compatible with the OpenTelemetry Protocol (OTLP) - Jaeger, DataDog, etc. - can import the metrics generated by the Cosmo Router, meaning you get centralized monitoring and analysis across your entire infrastructure, regardless of your monitoring stack.
With Cosmo's Router, you also get Prometheus metrics - the battle-tested, open-source (Apache License) service monitoring system - and R.E.D metrics, meaning you have a full metrics stack for fine-grained insights into router traffic, the error/success rates or the average request/response times/sizes of specific operations, and in general, everything you need to identify bottlenecks and optimize the performance of your system.
6. Forwarding client headers to subgraphs
When working in federated GraphQL architecture you'll often need to forward specific client headers to subgraphs. This may be because you need to pass contextual information like caching strategies, auth tokens, user preferences, or just device-specific information so your subgraphs can make decisions based on some client context.
The Cosmo router makes it easy to forward HTTP headers to subgraphs. By default, none are forwarded for security reasons. But you can modify the Router config file (config.yaml in the working directory of the Router) to add a headers root key, and customize it with Cosmo header rules according to your needs. These rules are applied in the order they appear in this YAML file.
config.yaml
headers:
all: # indicates that these Header rules apply to all subgraphs
request:
- op: "propagate" # Cosmo header rule
named: X-Test-Header # exact match
- op: "propagate"
matching: (?i)^X-Custom-.* # regex match (case insensitive)
The propagate header rule forwards all matching client request headers to subgraphs.
Once you have that key in place in this YAML file, the named nested key is used for an exact match of the header name (Remember that with the Golang http package, each word separated by a hyphen is capitalized. i.e., x-test-header will become X-Test-Header, and that's the one you have to use), and the matching nested key is used when you want to use Regex to match a header name.
And of course, if you want to set a default header rule that is applied even if one isn't set by the client, you can do so.
config.yaml
headers:
all:
request:
- op: "propagate"
named: "X-User-Id"
default: "123" # set a value manually if the client didn't provide one explicitly
Testing and Deployment
The Cosmo Router fetches the latest config of your federated architecture from the Cosmo platform or the CDN. For debugging and local dev, you might want to override that behavior and have it load a config from a local file, instead, like so:
docker run
-e ROUTER_CONFIG_PATH=/app/config.json
-v ./config.json:/app/config.json
- env-file ./.env router
Where config.json is your local test config file.
If you wanted to work locally with a copy of your production config instead, you could fetch it like so, before running the command above.
npx wgc router fetch production > config.json
Where production is the name of the federated graph whose router config you want to retrieve.
Similarly, if you wanted to generate a router config locally (without a connection to the Cosmo platform's Control Plane component) from your subgraphs, pipe that to a file, and use that instead with the docker command above,
npx wgc router compose -i config.json
Finally, the Cosmo Router is a Go application provided as a self-contained Docker container. You can initiate the router by executing a single Docker command.
docker run
- name cosmo-router
-e FEDERATED_GRAPH_NAME=<federated_graph_name>
-e GRAPH_API_TOKEN=<router_api_token>
-e LISTEN_ADDR=0.0.0.0:3002
- platform=linux/amd64
-p 3002:3002
ghcr.io/wundergraph/cosmo/router:latest
💡 You can generate a new GRAPH_API_TOKEN for a federated graph like so:
npx wgc federated-graph create-token <name>
As the router is stateless, you can deploy multiple instances. WunderGraph Cosmo recommends 3 instances, the box specs of each instance being 2 CPUs with 1 GB of RAM for low-medium traffic projects.
Where to go from here
For most people, the Apollo Router and Gateway will be perfectly fine for federated GraphQL architectures. However, for enterprise use cases, the blocker to adoption is that these two are under the Elastic V2 license, which is a restrictive license the OSI does not consider open source. Plus, enterprise use cases often have unique and strict requirements for data compliance, and vendor lock-in is a real dilemma.
That's why the blazingly fast, fully open-source, Federation V1/V2/Open Federation compatible Cosmo Router (and Cosmo as an alternative platform to Apollo GraphOS/Studio) makes perfect sense in these use cases.
To learn more, go check out their docs here. Also, the WunderGraph Discord can be found here, if you have questions or issues you want to discuss.
Comments
Loading comments…