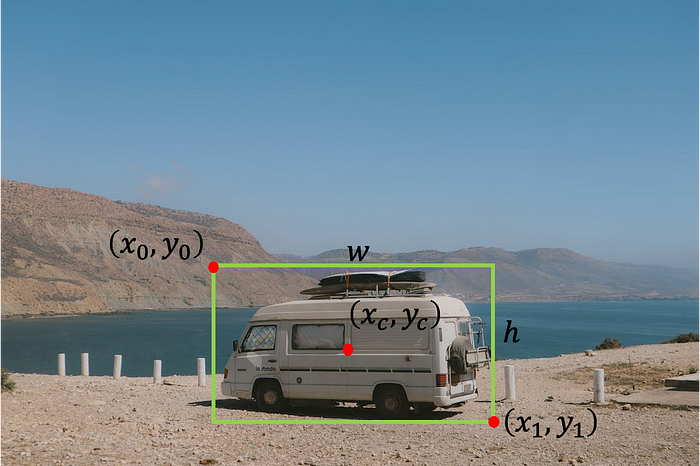
In the task of object detection, we want to find the location of an object in an image. We may search for one type of object (single-object detection, as in this tutorial) or for multiple objects (multi-object detection). Usually, we define the location of the object using a bounding box. There are several ways to represent a bounding box:
- The top-left point with width and height — [x0, y0, w, h], where x0 is the left side of the box, y0 is the top side of the box, w and h are the width and the height of the box, respectively.
- The top-left point and bottom-right point — [x0 ,y0 ,x1 ,y1], where x0 is the left side of the box, y0 is the top side of the box, x1 is the right side of the box, and y1 is the bottom side of the box.
- The center point with width and height — [xc, yc, w, h], where xc is the x coordinate of the center of the box, yc is the y coordinate of the center of the box, w and h are the width and the height of the box, respectively.
In this tutorial, we focus on finding the center of the fovea in medical eye images from the iChallenge-AMD competition.
Getting the Data
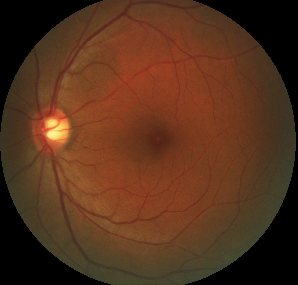
We are going to work with eye images of Age-related Macular degeneration (AMD) patients.
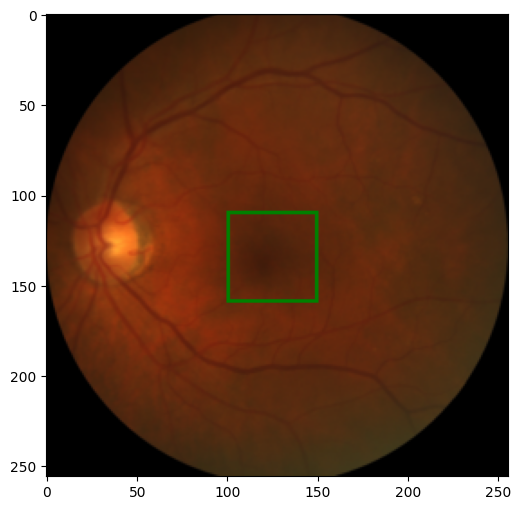
Eye image from the AMD dataset:
There are two main resources to get the data. The first one is the iChallenge-AMD website https://amd.grand-challenge.org/. You first need to sign up for the competition and then can download the data. The second way does not require signing up, and it is downloading from https://ai.baidu.com/broad/download. Here you need to download “[Training]Images and AMD labels” for the images and “[Training]Disc and fovea annotations” for the Excel file with the labels.
After downloading the data and extracting it, you should have a folder Training400 with the subfolders AMD (with 89 images) and Non-AMD (with 311 images) and an Excel file Fovea_location.xlsx that contains the center location of the fovea in each image.
Exploring the Data
Let’s start by loading the Excell file using Pandas
from pathlib import Path
import pandas as pd
path_to_parent_dir = Path('.')
path_to_labels_file = path_to_parent_dir / 'Training400' /'Fovea_location.xlsx'
labels_df = pd.read_excel(path_to_labels_file, index_col='ID')
print('Head')
print(labels_df.head()) # show the first 5 rows in the excell file
print('\nTail')
print(labels_df.tail()) # show the last 5 rows in the excell file
Printing results of the data frame:

We see that the table is composed of four columns:
- ID — which we use as an index for the data frame
- imgName — the name of the images. We notice that images with AMD start with A, while images without AMD start with N
- Fovea_X — the x coordinate of the centroid of the fovea in the image
- Fovea_Y — the y coordinate of the centroid of the fovea in the image
We can plot the centroids of the fovea in the images to understand the distribution of the fovea location.
%matplotlib inline # if using Jupyter notebook or Colab
import seaborn as sns
import matplotlib.pyplot as plt
plt.rcParams['figure.figsize'] = (10, 6)
amd_or_non_amd = ['AMD' if name.startswith('A') else 'Non-AMD' for name in labels_df.imgName]
sns.scatterplot(x='Fovea_X', y='Fovea_Y', hue=amd_or_non_amd, data=labels_df, alpha=0.7)
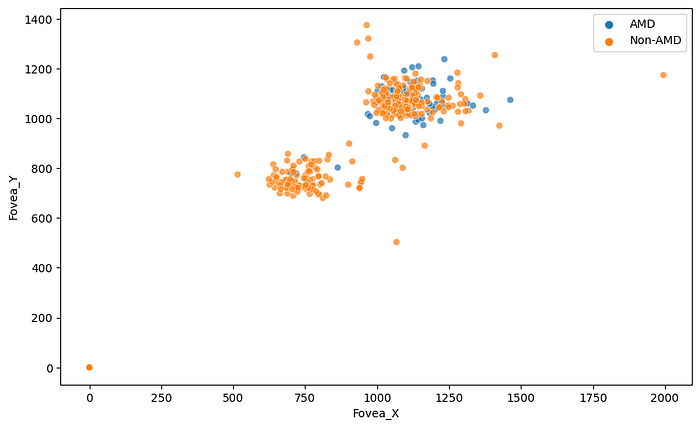
We can see two main groups of the fovea location, but the more important thing is that for some images, the label of the fovea centroid is (0, 0). It will be better to remove those images from the data frame.
labels_df = labels_df[(labels_df[['Fovea_X', 'Fovea_Y']] != 0).all(axis=1)]
amd_or_non_amd = ['AMD' if name.startswith('A') else 'Non-AMD' for name in labels_df.imgName]
Now we want to look at a random sample of images and mark the center of the fovea. For that, let’s define a function to load an image with its label and another function to draw a bounding box around the fovea according to the label.
import numpy as np
from PIL import Image, ImageDraw
def load_image_with_label(labels_df, id):
image_name = labels_df.loc[id, 'imgName']
data_type = 'AMD' if image_name.startswith('A') else 'Non-AMD'
image_path = path_to_parent_dir / 'Training400' / data_type / image_name
image = Image.open(image_path)
label = (labels_df.loc[id, 'Fovea_X'], labels_df.loc[id, 'Fovea_Y'])
return image, label
def show_image_with_bounding_box(image, label, w_h_bbox=(50, 50), thickness=2):
w, h = w_h_bbox
c_x , c_y = label
image = image.copy()
ImageDraw.Draw(image).rectangle(((c_x-w//2, c_y-h//2), (c_x+w//2, c_y+h//2)), outline='green', width=thickness)
plt.imshow(image)
We randomly sample six images and show them.
rng = np.random.default_rng(42) # create Generator object with seed 42
n_rows = 2 # number of rows in the image subplot
n_cols = 3 # # number of cols in the image subplot
indexes = rng.choice(labels_df.index, n_rows * n_cols)
for ii, id in enumerate(indexes, 1):
image, label = load_image_with_label(labels_df, id)
plt.subplot(n_rows, n_cols, ii)
show_image_with_bounding_box(image, label, (250, 250), 20)
plt.title(labels_df.loc[id, 'imgName'])
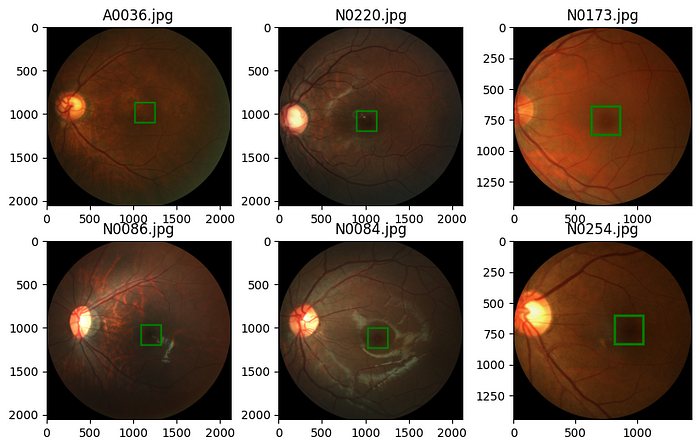
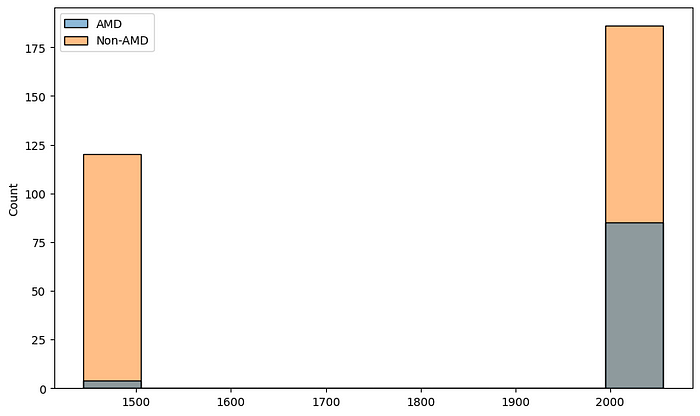
The first thing we need to pay attention to from the figure above is that the dimensions of the images are different for different images. We now want to understand the distribution of the image dimensions. For that, we collect the heights and widths of the images in our dataset.
heights = []
widths = []
for image_name, data_type in zip(labels_df['imgName'], amd_or_non_amd):
image_path = path_to_parent_dir / 'Training400' / data_type / image_name
h, w = Image.open(image_path).size
heights.append(h)
widths.append(w)
sns.histplot(x=heights, hue=amd_or_non_amd)
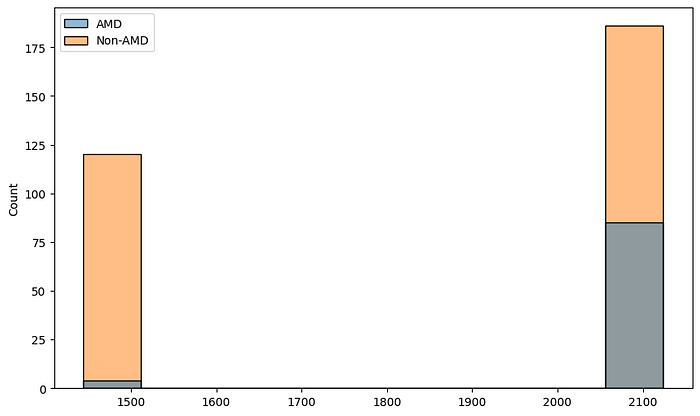
sns.histplot(x=widths, hue=amd_or_non_amd)
Data Augmentation and Transformation
Data augmentation is a very important step that lets us extend our dataset (especially when we have a small dataset, as in our case) and make the network more robust. We also want to apply some transformations to make the input to the network consistent (in our case, we need to resize the images so they have constant dimensions).
In addition to the augmentation and transformation of the images, we also need to take care of the labels. For example, if we vertically flip an image, the centroid of the fovea will get a new coordinate that we need to update. To update the labels together with the transformation of the image, we are going to write some transformation classes by ourselves.
import torch
import torchvision.transforms.functional as tf
class Resize:
'''Resize the image and convert the label
to the new shape of the image'''
def __init__(self, new_size=(256, 256)):
self.new_width = new_size[0]
self.new_height = new_size[1]
def __call__(self, image_label_sample):
image = image_label_sample[0]
label = image_label_sample[1]
c_x, c_y = label
original_width, original_height = image.size
image_new = tf.resize(image, (self.new_width, self.new_height))
c_x_new = c_x * self.new_width /original_width
c_y_new = c_y * self.new_height / original_height
return image_new, (c_x_new, c_y_new)
class RandomHorizontalFlip:
'''Horizontal flip the image with probability p.
Adjust the label accordingly'''
def __init__(self, p=0.5):
if not 0 <= p <= 1:
raise ValueError(f'Variable p is a probability, should be float between 0 to 1')
self.p = p # float between 0 to 1 represents the probability of flipping
def __call__(self, image_label_sample):
image = image_label_sample[0]
label = image_label_sample[1]
w, h = image.size
c_x, c_y = label
if np.random.random() < self.p:
image = tf.hflip(image)
label = w - c_x, c_y
return image, label
class RandomVerticalFlip:
'''Vertically flip the image with probability p.
Adjust the label accordingly'''
def __init__(self, p=0.5):
if not 0 <= p <= 1:
raise ValueError(f'Variable p is a probability, should be float between 0 to 1')
self.p = p # float between 0 to 1 represents the probability of flipping
def __call__(self, image_label_sample):
image = image_label_sample[0]
label = image_label_sample[1]
w, h = image.size
c_x, c_y = label
if np.random.random() < self.p:
image = tf.vflip(image)
label = c_x, h - c_y
return image, label
class RandomTranslation:
'''Translate the image by randomaly amount inside a range of values.
Translate the label accordingly'''
def __init__(self, max_translation=(0.2, 0.2)):
if (not 0 <= max_translation[0] <= 1) or (not 0 <= max_translation[1] <= 1):
raise ValueError(f'Variable max_translation should be float between 0 to 1')
self.max_translation_x = max_translation[0]
self.max_translation_y = max_translation[1]
def __call__(self, image_label_sample):
image = image_label_sample[0]
label = image_label_sample[1]
w, h = image.size
c_x, c_y = label
x_translate = int(np.random.uniform(-self.max_translation_x, self.max_translation_x) * w)
y_translate = int(np.random.uniform(-self.max_translation_y, self.max_translation_y) * h)
image = tf.affine(image, translate=(x_translate, y_translate), angle=0, scale=1, shear=0)
label = c_x + x_translate, c_y + y_translate
return image, label
class ImageAdjustment:
'''Change the brightness and contrast of the image and apply Gamma correction.
No need to change the label.'''
def __init__(self, p=0.5, brightness_factor=0.8, contrast_factor=0.8, gamma_factor=0.4):
if not 0 <= p <= 1:
raise ValueError(f'Variable p is a probability, should be float between 0 to 1')
self.p = p
self.brightness_factor = brightness_factor
self.contrast_factor = contrast_factor
self.gamma_factor = gamma_factor
def __call__(self, image_label_sample):
image = image_label_sample[0]
label = image_label_sample[1]
if np.random.random() < self.p:
brightness_factor = 1 + np.random.uniform(-self.brightness_factor, self.brightness_factor)
image = tf.adjust_brightness(image, brightness_factor)
if np.random.random() < self.p:
contrast_factor = 1 + np.random.uniform(-self.brightness_factor, self.brightness_factor)
image = tf.adjust_contrast(image, contrast_factor)
if np.random.random() < self.p:
gamma_factor = 1 + np.random.uniform(-self.brightness_factor, self.brightness_factor)
image = tf.adjust_gamma(image, gamma_factor)
return image, label
class ToTensor:
'''Convert the image to a Pytorch tensor with
the channel as first dimenstion and values
between 0 to 1. Also convert the label to tensor
with values between 0 to 1'''
def __init__(self, scale_label=True):
self.scale_label = scale_label
def __call__(self, image_label_sample):
image = image_label_sample[0]
label = image_label_sample[1]
w, h = image.size
c_x, c_y = label
image = tf.to_tensor(image)
if self.scale_label:
label = c_x/w, c_y/h
label = torch.tensor(label, dtype=torch.float32)
return image, label
class ToPILImage:
'''Convert a tensor image to PIL Image.
Also convert the label to a tuple with
values with the image units'''
def __init__(self, unscale_label=True):
self.unscale_label = unscale_label
def __call__(self, image_label_sample):
image = image_label_sample[0]
label = image_label_sample[1].tolist()
image = tf.to_pil_image(image)
w, h = image.size
if self.unscale_label:
c_x, c_y = label
label = c_x*w, c_y*h
return image, label
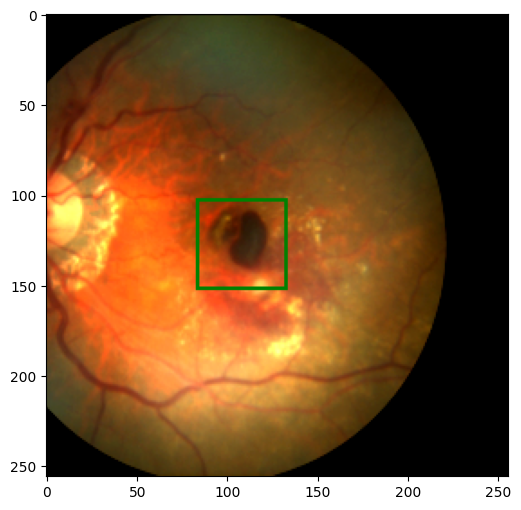
Let’s try our new transformation. We create objects for each transformation class and concatenate them using Compose from torchvision. Then we apply the full transformation on an image with its label.
from torchvision.transforms import Compose
image, label = load_image_with_label(labels_df, 1)
transformation = Compose([Resize(), RandomHorizontalFlip(), RandomVerticalFlip(), RandomTranslation(), ImageAdjustment(), ToTensor()])
new_image, new_label = transformation((image, label))
print(f'new_im type {new_image.dtype}, shape = {new_image.shape}')
print(f'{new_label=}')
# new_im type torch.float32, shape = torch.Size([3, 256, 256]
# new_label=tensor([0.6231, 0.3447])
We got the results as expected. We also want to transform the new tensor into a PIL image and convert the label back to the image coordinate, so we can show it using our show method.
new_image, new_label = ToPILImage()((new_image, new_label))
show_image_with_bounding_box(new_image, new_label)
Making the Dataset and DataLoader
To load the data into our model, we need first to build a custom Dataset class (which is a subclass of PyTorch Dataset class). For that, we need to implement three methods:
__init__()- to construct and initialize a Dataset object__getitem__()- that handles the way we can get an image and label from the whole dataset by index__len__()- that returns the length of the dataset we have
import torch
from torch.utils.data import Dataset, DataLoader
device = 'cuda' if torch.cuda.is_available() else 'cpu'
class AMDDataset(Dataset):
def __init__(self, data_path, labels_df, transformation):
self.data_path = Path(data_path)
self.labels_df = labels_df.reset_index(drop=True)
self.transformation = transformation
def __getitem__(self, index):
image_name = self.labels_df.loc[index, 'imgName']
image_path = self.data_path / ('AMD' if image_name.startswith('A') else 'Non-AMD') / image_name
image = Image.open(image_path)
label = self.labels_df.loc[index, ['Fovea_X','Fovea_Y']].values.astype(float)
image, label = self.transformation((image, label))
return image.to(device), label.to(device)
def __len__(self):
return len(self.labels_df)
Before we actually create our Dataset objects, we need to split the data into a train set and validation set. We use scikit-learn to split the labels_df into a train data frame and validation one.
from sklearn.model_selection import train_test_split
labels_df_train, labels_df_val = train_test_split(labels_df, test_size=0.2, shuffle=True, random_state=42)
train_transformation = Compose([Resize(), RandomHorizontalFlip(), RandomVerticalFlip(), RandomTranslation(), ImageAdjustment(), ToTensor()])
val_transformation = Compose([Resize(), ToTensor()])
train_dataset = AMDDataset('Training400', labels_df_train, train_transformation)
val_dataset = AMDDataset('Training400', labels_df_val, val_transformation)
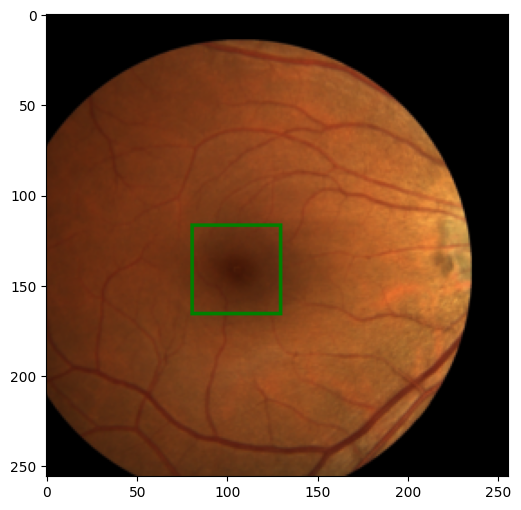
We can check our dataset objects by showing a sample of images.
image, label = train_dataset[0]
show_image_with_bounding_box(*(ToPILImage()((image, label))))
image, label = val_dataset[0]
show_image_with_bounding_box(*(ToPILImage()((image, label))))
The next step is to define a DataLoaders, one for the training dataset and one for the validation dataset.
train_dataloader = DataLoader(train_dataset, batch_size=8)
val_dataloader = DataLoader(val_dataset, batch_size=16)
We don’t have to shuffle in the DataLoader since we already shuffle the data when we split it into training and validation datasets. Let’s now look at a batch to see that the results are as expected.
image_batch, labels_batch = next(iter(train_dataloader))
print(image_batch.shape, image_batch.dtype)
print(labels_batch, labels_batch.dtype)
# torch.Size([8, 3, 256, 256]) torch.float32
# tensor([[0.4965, 0.3782],
# [0.6202, 0.6245],
# [0.5637, 0.4887],
# [0.5114, 0.4908],
# [0.3087, 0.4657],
# [0.5330, 0.5309],
# [0.6800, 0.6544],
# [0.5828, 0.4034]], device='cuda:0') torch.float32
Building the Model
We want to build a model that gets a resized RGB image and returns two values for the x and y coordinates. We are going to use residual blocks in a similar way to ResNet using a skip connection. We start by defining the basic res-block
from torch.nn.modules.batchnorm import BatchNorm2d
import torch.nn as nn
class ResBlock(nn.Module):
def __init__(self, in_channels, out_channels):
super().__init__()
self.base1 = nn.Sequential(
nn.Conv2d(in_channels, in_channels, kernel_size=3, padding='same'),
nn.BatchNorm2d(in_channels),
nn.ReLU(True)
)
self.base2 = nn.Sequential(
nn.Conv2d(in_channels, out_channels, kernel_size=3, padding='same'),
nn.BatchNorm2d(out_channels),
nn.ReLU(True)
)
def forward(self, x):
x = self.base1(x) + x
x = self.base2(x)
return x
This block has two steps. First, it uses a convolution layer followed by batch normalization and ReLU. Then we add the original input to the result and apply the second step, which again consists of a convolution layer followed by batch normalization and ReLU, but this time we change the number of filters. Now we are ready to build the model.
class FoveaNet(nn.Module):
def __init__(self, in_channels, first_output_channels):
super().__init__()
self.model = nn.Sequential(
ResBlock(in_channels, first_output_channels),
nn.MaxPool2d(2),
ResBlock(first_output_channels, 2 * first_output_channels),
nn.MaxPool2d(2),
ResBlock(2 * first_output_channels, 4 * first_output_channels),
nn.MaxPool2d(2),
ResBlock(4 * first_output_channels, 8 * first_output_channels),
nn.MaxPool2d(2),
nn.Conv2d(8 * first_output_channels, 16 * first_output_channels, kernel_size=3),
nn.MaxPool2d(2),
nn.Flatten(),
nn.Linear(7 * 7 * 16 * first_output_channels, 2)
)
def forward(self, x):
return self.model(x)
We can better see our model using torchinfo package
! pip install torchinfo -q # install torchinfo
from torchinfo import summary
net = FoveaNet(3, 16)
summary(model=net,
input_size=(8, 3, 256, 256), # (batch_size, color_channels, height, width)
col_names=["input_size", "output_size", "num_params"],
col_width=20,
row_settings=["var_names"]
)

Loss and Optimizer
We start by defining the loss function using the smooth L1 loss. In general, this loss behaves like L2 when the absolute difference is less than 1, and like L1 otherwise.
loss_func = nn.SmoothL1Loss()
For the optimizer, we are going to use Adam.
optimizer = torch.optim.Adam(net.parameters(), lr=1e-4)
As a performance metric, we utilize the Intersection over Union metric (IoU). This metric calculates the ratio between the intersection of two bounding boxes and their union.
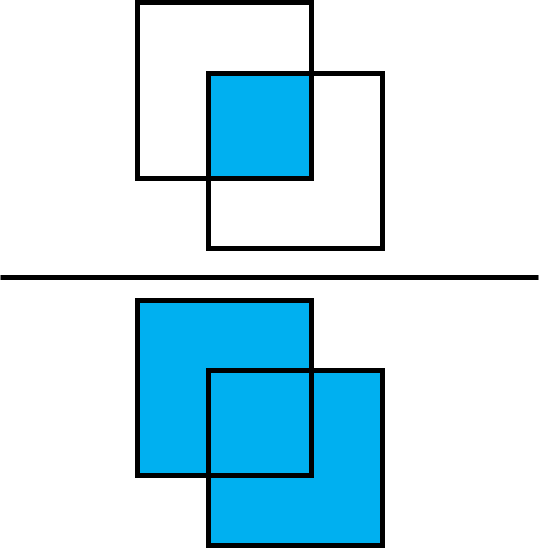
First, we need to define a function that gets centroids as input and returns the bounding box of the form [x0, y0, x1, y1] as output
def centroid_to_bbox(centroids, w=50/256, h=50/256):
x0_y0 = centroids - torch.tensor([w/2, h/2]).to(device)
x1_y1 = centroids + torch.tensor([w/2, h/2]).to(device)
return torch.cat([x0_y0, x1_y1], dim=1)
and a function to compute the IoU for a batch of labels
from torchvision.ops import box_iou
def iou_batch(output_labels, target_labels):
output_bbox = centroid_to_bbox(output_labels)
target_bbox = centroid_to_bbox(target_labels)
return torch.trace(box_iou(output_bbox, target_bbox)).item()
Next, we define a loss function for a batch
def batch_loss(loss_func, output, target, optimizer=None):
loss = loss_func(output, target)
with torch.no_grad():
iou_metric = iou_batch(output, target)
if optimizer is not None:
optimizer.zero_grad()
loss.backward()
optimizer.step()
return loss.item(), iou_metric
Training the Model
In this step, we are going to train our model to find the fovea. We start by defining a helper function to make a training step, which means going over all the data in a Dataloader, getting the loss (and updating the weights in the training case) using our previous function batch_loss, and track the loss and IoU metric.
def train_val_step(dataloader, model, loss_func, optimizer=None):
if optimizer is not None:
model.train()
else:
model.eval()
running_loss = 0
running_iou = 0
for image_batch, label_batch in dataloader:
output_labels = model(image_batch)
loss_value, iou_metric_value = batch_loss(loss_func, output_labels, label_batch, optimizer)
running_loss += loss_value
running_iou += iou_metric_value
return running_loss/len(dataloader.dataset), running_iou/len(dataloader.dataset)
Now we have all we need to perform the training. We define two dictionaries to track the loss and IoU metric for the training and validation after each epoch. We also save the weights of the model that give the best result.
num_epoch = 100
loss_tracking = {'train': [], 'val': []}
iou_tracking = {'train': [], 'val': []}
best_loss = float('inf')
model = FoveaNet(3, 16).to(device)
loss_func = nn.SmoothL1Loss(reduction="sum")
optimizer = torch.optim.Adam(model.parameters(), lr=5e-5)
for epoch in range(num_epoch):
print(f'Epoch {epoch+1}/{num_epoch}')
training_loss, trainig_iou = train_val_step(train_dataloader, model, loss_func, optimizer)
loss_tracking['train'].append(training_loss)
iou_tracking['train'].append(trainig_iou)
with torch.inference_mode():
val_loss, val_iou = train_val_step(val_dataloader, model, loss_func, None)
loss_tracking['val'].append(val_loss)
iou_tracking['val'].append(val_iou)
if val_loss < best_loss:
print('Saving best model')
torch.save(model.state_dict(), 'best_model.pt')
best_loss = val_loss
print(f'Training loss: {training_loss:.6}, IoU: {trainig_iou:.2}')
print(f'Validation loss: {val_loss:.6}, IoU: {val_iou:.2}')
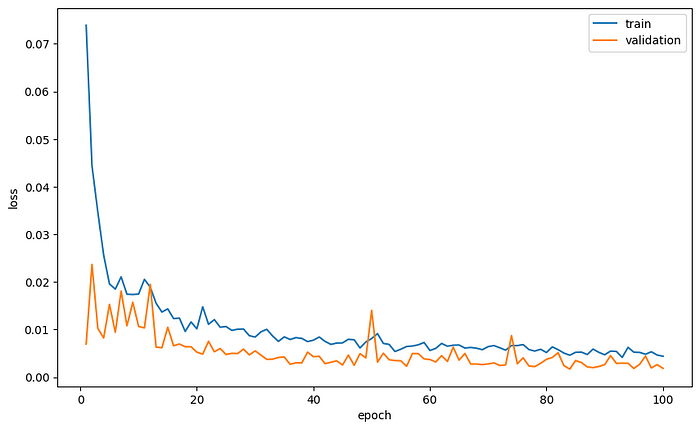
Let’s plot the average loss per epoch and the average IoU as a function of the epochs.
plt.plot(range(1, num_epoch+1), loss_tracking['train'], label='train')
plt.plot(range(1, num_epoch+1), loss_tracking['val'], label='validation')
plt.xlabel('epoch')
plt.ylabel('loss')
plt.legend()
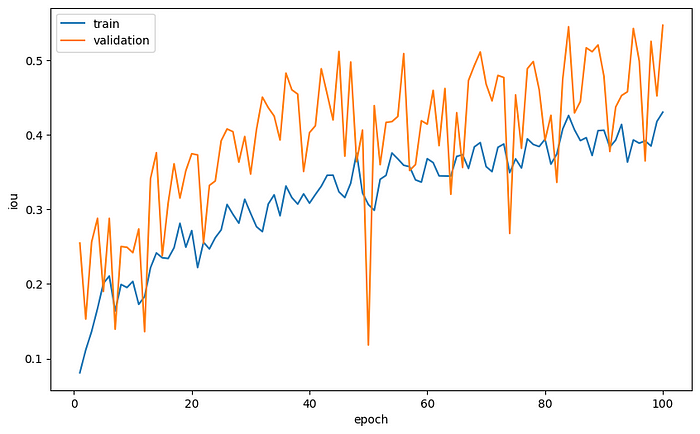
plt.plot(range(1, num_epoch+1), iou_tracking['train'], label='train')
plt.plot(range(1, num_epoch+1), iou_tracking['val'], label='validation')
plt.xlabel('epoch')
plt.ylabel('iou')
plt.legend()
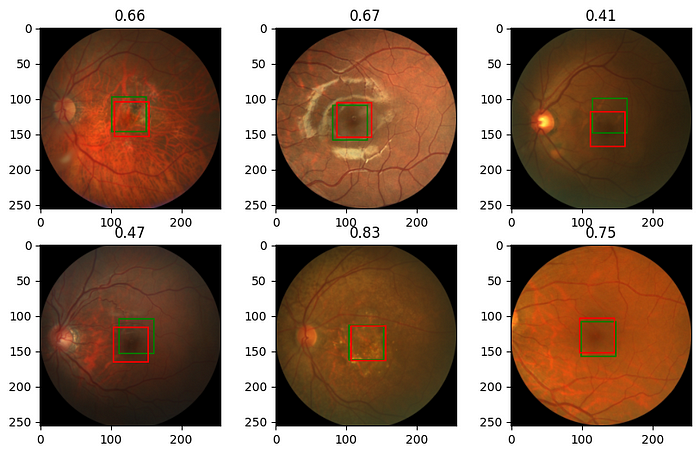
Finally, we want to look at some images and see how much the prediction of the model is close to the real coordinates of the fovea. For that, we define a new function based on our previous function, show_image_with_bounding_box, but this time we draw the bounding box for the prediction (in green) as well as for the target (in red).
def show_image_with_2_bounding_box(image, label, target_label, w_h_bbox=(50, 50), thickness=2):
w, h = w_h_bbox
c_x , c_y = label
c_x_target , c_y_target = target_label
image = image.copy()
ImageDraw.Draw(image).rectangle(((c_x-w//2, c_y-h//2), (c_x+w//2, c_y+h//2)), outline='green', width=thickness)
ImageDraw.Draw(image).rectangle(((c_x_target-w//2, c_y_target-h//2), (c_x_target+w//2, c_y_target+h//2)), outline='red', width=thickness)
plt.imshow(image)
and now we load the best model we got and make prediction on a sample of images and look at the results
model.load_state_dict(torch.load('best_model.pt'))
model.eval()
rng = np.random.default_rng(0) # create Generator object with seed 0
n_rows = 2 # number of rows in the image subplot
n_cols = 3 # # number of cols in the image subplot
indexes = rng.choice(range(len(val_dataset)), n_rows * n_cols, replace=False)
for ii, id in enumerate(indexes, 1):
image, label = val_dataset[id]
output = model(image.unsqueeze(0))
iou = iou_batch(output, label.unsqueeze(0))
_, label = ToPILImage()((image, label))
image, output = ToPILImage()((image, output.squeeze()))
plt.subplot(n_rows, n_cols, ii)
show_image_with_2_bounding_box(image, output, label)
plt.title(f'{iou:.2f}')
Conclusion
In this tutorial, we went over all the main steps needed to build a network for a single object detection task. We started by exploring the data, cleaning and arranging it, then built data augmentation functions and Dataset and DataLoader objects, and finally built and trained the model. We got relatively good results, and you are welcome to try and improve the performance by changing the model's learning parameters and architecture.
Comments
Loading comments…