
As a freelance developer, I tend to hop from one Angular project to another. I have worked with teams of various sizes and levels of experience with the framework.
Quite frequently, I encounter a big block of imperative code inside a subscribecallback. I have always considered this to be a bad practice. Angular embraces RxJS and the reactive programming paradigm. As Angular developers, we really should be doing the same. This article will be very opinionated, so comments or questions are more than welcome.
What is the subscribe callback in Angular?
An Observable is the main tool provided by the RxJS library whose Angular uses extensively. As with a regular JavaScript Promise, the goal of an Observable is to handle asynchronous events.
The key difference between an Observable and a Promise is that Observables are lazy. You can declare how your data should be handled once received, but you will then need to explicitly subscribe to trigger the asynchronous call. In other words, making the call and handling the results are separated operations. Whereas with a Promise, when you call the then function, you are actually doing both operations at once. It triggers the call and handles the result.
Coming back to the main topic of the article, if you are writing a lot of logic inside the subscribe callback, you are using an Observable as if it was a Promise. Thus, you are not making an optimal use of RxJS or Angular features.
Imperative vs Reactive
As I usually do with those articles, I built an elementary application using the two different approaches. It is a simple weather application. You just type the name of a city and then get the weather for the next couple of days in that location. Here is how it looks:
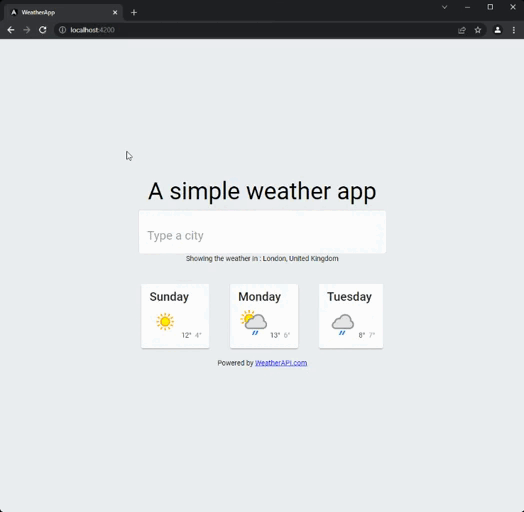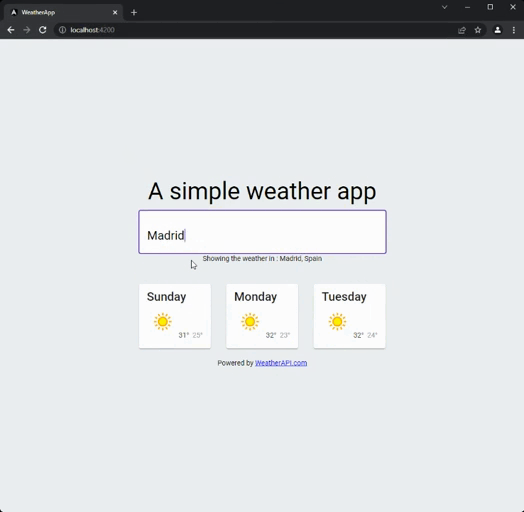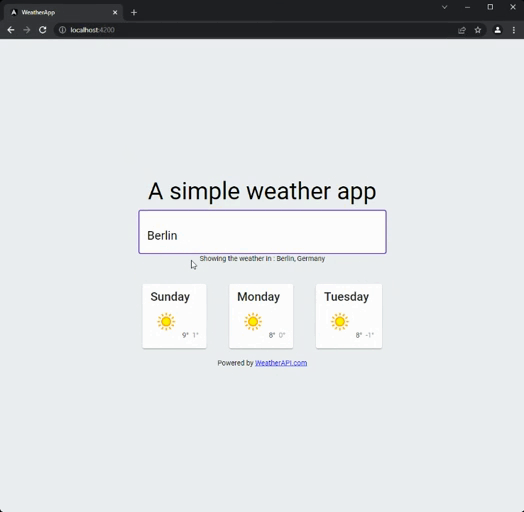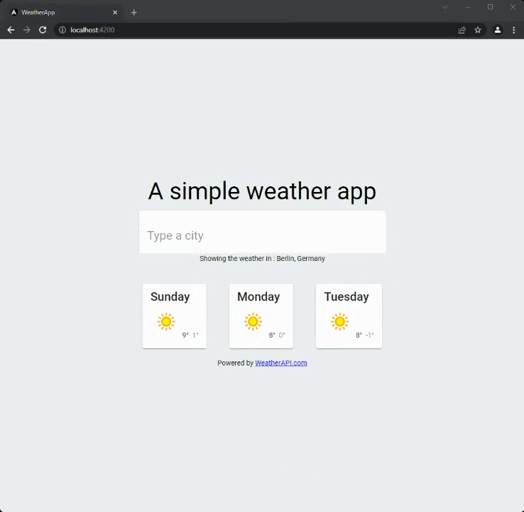
I used the weather API to get the weather data. The code is available on my GitHub with an imperative and a reactive branch, so you can compare.
Reason #1: you are not using RxJS operators as much as you could
To illustrate this first reason, let's have a look at the way I handled the API call in both versions of the application.
For the imperative version of the application, I simply subscribed to both endpoints, processed and stored the data into component properties that I then displayed on the page. Everything gets triggered each time the input changes on the template.
For the reactive version, it is better to start the process from an Observable instead of a callback method. For that reason, I used the ViewChild decorator to get the Observable from the HTML element. I then do the same type of processing as previously but this time, everything is stored in the Observable instead of an object.
In my opinion, there are some advantages to using the reactive instead of the imperative approach here.
It increases readability.
A sequence of operators is pretty straightforward to read and understand (given that you know the most common RxJS operators). A bloc of imperative code will always require you to dive into it to attempt to understand what was the goal of the bloc. Moreover, you have to add some code to push the subscription to a list for unsubscribing later, making the code heavier. The nested subscribe is also something that increases complexity. Just by looking at it, try to imagine how it would be with three nested subscribes, each one having a specific error management bloc.
It makes **testing **and **debugging **easier.
With the imperative approach, you have to use component properties. In this example, I only use those variables inside that function. But sometimes, once you have this variable created, you can be tempted to use it elsewhere in the component. It is very convenient, on the developer side, compared to the reactive approach. But it comes with a price. Each time you are using component properties in a function, this function is no longer pure, and you are creating a side effect. Side effects can lead to more complex debugging because you never know exactly where the change happened. Pure functions are just easier to test in general.
It comes with advanced features, built-in.
Debouncing, caching, and much more. There is a lot that is already built in the RxJS library. It would honestly be a shame to try to reimplement some of those features manually just because you decided not to declare an Observable.
Reason #2: You cannot use the async pipe
With the imperative approach, we are using the component variables to display the data on the template.
With the reactive approach, we are directly using the Observable with the async pipe on the template.
The async pipe is a feature provided by Angular to handle asynchronous data in the Angular template. It has two main advantages compared to sending data directly through component properties.
It will handle unsubscription for you.
Any time you subscribe to an Observable, you need to unsubscribe. You should never forget to do so. Otherwise, your code would leak, leading to unexpected behavior. It is not really difficult to follow that rule. However, it will take some specific code to do so.
It works well with OnPush change detection.
The async pipe will trigger change detection when a new value is emitted, even with the OnPush strategy enabled. You would have to do it manually when you are using subscribe. The OnPush stategy is great for the performance of Angular applications. Its use alone is enough of an argument to always consider the use of the async pipe.
About error management
Some people in the comments have rightfully pointed the fact that my example would be more realistic if I handled the possible errors with the two approaches.
Here is the outcome if my API key is wrong:
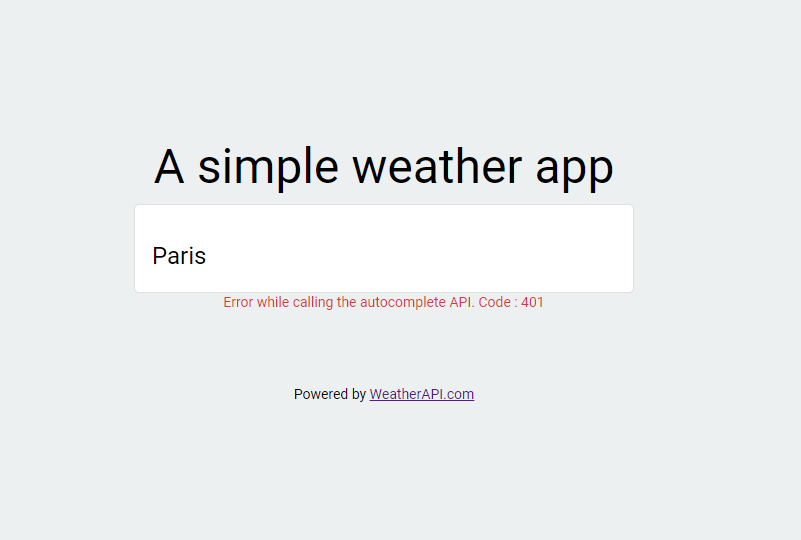
Here is the code with the imperative approach:
For the reactive approach, the code gets more complex:
Before commenting on both approaches and comparing them, let's explain how I implemented error management in both cases.
For the imperative approach, it was very straightforward. We can simply use the error callback right after the next callback from earlier. The code gets a bit more dense, but besides that, nothing too complex to mention.
For the reactive approach, it is trickier. First, we need to set up a third observable to display the errors. Then, we use the catchError that will catch errors and allow us to handle them. It is important to note that this operator is linked right after the HTTP request. This allows the main Observable to stay alive. Thus, if the user types something else, the error can go away and the request can be tried again.
It is true that the simplicity of error handling with the imperative approach works in its favor. However, let's note that error management with the reactive approach could be made a lot cleaner with the use of a dedicated “handleError” function.
Final comments
With this type of article, it is always important to repeat that both approaches work. Regarding my example, there is not an approach that is clearly superior to the other. While it is true that Angular embraces RxJS and the reactive paradigm, the framework has a steep learning curve. So if you feel more comfortable writing your first applications using subscribe because it is similar to using a promise, fine. After reading this article, maybe you will acknowledge some benefits of reactive programming and try it for yourself at some point.
Related article: The Ultimate Answer To The Very Common Angular Question: subscribe() vs | async Pipe
The full project on my GitHub: GitHub - aurelien-leloup/weather-app: A simple weather app made to demonstrate imperative vs…
Comments
Loading comments…