
After digesting this article, you will come to understand that a portion of the latency within your application can be attributed to the manner in which you execute certain tasks. In the context of Node.js, the event loop is tasked with managing the execution of asynchronous operations, all within a single thread. Consequently, it is advisable to steer clear of the main thread when executing CPU-intensive logic, and this is the primary focus of the entire article. I recommend not only reading through it but also actively implementing the project to fully leverage the article’s insights.
Message queues are a vital part of modern serverless and microservices architectures. They facilitate asynchronous communication between services, enhancing an application’s performance, reliability, and scalability. One of their key advantages is the ability to handle time-consuming tasks separately, allowing various components of an application to operate independently for increased flexibility and scalability.
However, managing message queues can be challenging, especially when dealing with a high volume of messages in a distributed environment. This is where BullMQ, a Node.js library built on Redis, comes into play. BullMQ offers a fast and robust queue system that simplifies the management of message queues, making it an effective solution for addressing these challenges.
In the context of a practical scenario, consider a situation where a lecturer uploads result sheets to a school portal, and the application needs to process and email individual students. BullMQ enables seamless handling of this process without requiring the lecturer’s presence. By validating the result sheet format and acknowledging the upload, the BullMQ worker, if appropriately configured, can execute the tasks in a separate thread, ensuring the main thread remains unburdened.
In upcoming discussions, we will explore how to leverage BullMQ, Redis, and Node.js to implement such solutions efficiently.
Introduction to Node.js
Node.js is a JavaScript runtime environment that allows server-side scripting, offering non-blocking, event-driven capabilities for building scalable and efficient network applications.
Introduction to BullMQ and Redis
BullMQ docs defined BullMQ as a Node.js library that implements a fast and robust queue system built on top of Redis that helps in resolving many modern-age micro-services architectures.
Redis is an open-source, in-memory data store and caching system known for its speed and versatility, often used to store key-value data and support various data-intensive applications.
About the Project
In this tutorial, we will construct a basic queue using Bullmq, Redis, and Node.js. We’ll establish an endpoint that can receive both a username and a CSV file. While the application promptly responds to the user, it simultaneously initiates a background job responsible for performing the following tasks:
- Converting the CSV data into JSON format.
- Analyzing and organizing the content based on dates.
- Creating a unique key associated with the username and assigning the grouped data to the respective user.
- Generating a .json file containing the modified data.
Prerequisites
- Make sure you have Redis running on your machine
- Have Node.js installed on your machine
- Download Employment-indicators-Weekly
Setting up a Node Express.js Server
Run npm init --y
Add the following script to your package.json
{
"name": "bullmq",
"version": "1.0.0",
"description": "",
"main": "index.js",
"scripts": {
"start": "node './src/index.js'",
"test": "echo \"Error: no test specified\" && exit 1"
},
"keywords": [],
"author": "",
"license": "ISC",
"dependencies": {
"bullmq": "^4.11.1",
"csv-parse": "^5.5.0",
"express": "^4.18.2"
}
}
Now, run npm i
Please bear in mind that the directory and file structure I’ve employed here is purely a matter of preference. You have the flexibility to opt for an alternative structure that suits your needs.
Inside your main directory, create a srcdirectory.
In your src directory create an index.js file and add the code below:
const express = require("express");
const path = require("path");
const addJobToQueue = require("./bullmq/queue");
const app = express();
const PORT = 3001;
app.use(express.json());
const csvFilePath = path.join(__dirname, "./employment_indicators.csv");
app.post("/", async (req, res) => {
const { userName } = req.body;
const data = { jobName: "csvJob", userName, csvFilePath };
const job = await addJobToQueue(data);
return res.status(201).json({ jobId: job.id });
});
app.listen(PORT, async function onListen() {
console.log(`Server is up and running on port ${PORT}`);
});
This code initializes your fundamental Express server. We’ll retrieve the userName from the request body and hardcode the CSV data for the sake of simplicity and clarity in the application.
In BullMQ docs, we were told that BullMQ is based on 4 classes that together can be used to resolve many different problems. These classes are Queue, Worker, QueueEvents, and FlowProducer.
You may have observed that we imported the addJobToQueue function at this point, which brings us to our initial encounter with the Bullmq class, Queue.
Queue
Now, move the CSV file you downloaded into this src then inside the src create the bullmq/config.js directory and add the code below:
const CONNECTOR = {
host: "localhost",
port: 6379,
};
const DEFAULT_REMOVE_CONFIG = {
removeOnComplete: {
age: 3600,
},
removeOnFail: {
age: 24 * 3600,
},
};
module.exports = { CONNECTOR, DEFAULT_REMOVE_CONFIG };
We also create a function that can be used to add jobs to the queue from an endpoint handler. Now create bullmq/queue.js file and add the code below:
const { Queue } = require("bullmq");
const configModule = require("./config");
const setUpWorker = require("./worker");
const myQueue = new Queue("JOBS", {
connection: configModule.CONNECTOR,
});
myQueue.setMaxListeners(myQueue.getMaxListeners() + 100);
setUpWorker();
const addJobToQueue = (data) => {
return myQueue.add(data.jobName, data, configModule.DEFAULT_REMOVE_CONFIG);
};
module.exports = addJobToQueue;
You notice that we imported a function called setUpWorker right? That leads us to another two classes in Bullmq called Worker, and QueueEvents.
Worker and QueueEvents
Now create a bullmq/worker.js file and add the code below:
const { Worker } = require("bullmq");
const path = require("path");
const configModule = require("./config");
let worker;
const processorPath = path.join(__dirname, "processor.js");
const setUpWorker = () => {
worker = new Worker("JOBS", processorPath, {
connection: configModule.CONNECTOR,
autorun: true,
});
worker.on("active", (job) => {
console.debug(`Processing job with id ${job.id}`);
});
worker.on("completed", (job, returnValue) => {
console.debug(`Completed job with id ${job.id}`, returnValue);
});
worker.on("error", (failedReason) => {
console.error(`Job encountered an error`, failedReason);
});
};
module.exports = setUpWorker;
You may have observed how the worker and the queue share the same name and connection information, which is a requisite for the worker to commence job consumption from the queue. With the event listeners incorporated into our queue.js, we can now receive updates on the job statuses.
Additionally, you might have noticed this line of code:
const processorPath = path.join(__dirname, "processor.js");
This line refers to our processor, where we handle resource-intensive tasks like database operations or interactions with third-party APIs. The objective is to ensure that our workers execute these jobs in a separate thread.
By providing the file path as the second parameter to the worker, BullMQ will execute the function exported from the specified file within a dedicated thread. This approach guarantees that the main thread remains unburdened by the CPU-intensive workload handled by the processor.
Now create bullmq/processor.js file and add this code below:
const fs = require("fs");
const { parse } = require("csv-parse");
const { promisify } = require("util");
const sleep = promisify(setTimeout);
const fileName = "employment_indicators.json";
if (fs.existsSync(fileName)) {
fs.unlinkSync(fileName);
}
const jobProcessor = async (job) => {
await job.log(`Started processing job with id ${job.id}`);
// TODO: do your CPU intense logic here
await extractCSVData(job?.data);
await job.updateProgress(100);
return "DONE";
};
module.exports = jobProcessor;
const extractCSVData = async (jobData) => {
try {
let result = [];
await sleep(10000);
fs.createReadStream(jobData.csvFilePath)
.pipe(
parse({
columns: true,
})
)
.on("data", async (data) => {
result.push(data);
})
.on("error", async (error) => {
console.log(error, "????");
})
.on("end", () => {
result = result.reduce((acc, item) => {
const key = item.Week_end;
acc[key] = acc[key] || [];
acc[key].push(item);
return acc;
}, {});
const writeData = { [jobData.userName]: result };
fs.writeFileSync(fileName, JSON.stringify(writeData));
});
} catch (error) {
console.log(error);
}
};
Notice how we called our extractCSVData function in the jobProcessor. At this point, your file structure will look like this:
You can now start your server by running npm start
Then go ahead and make a postman call to the endpoint. Your postman should look like this:
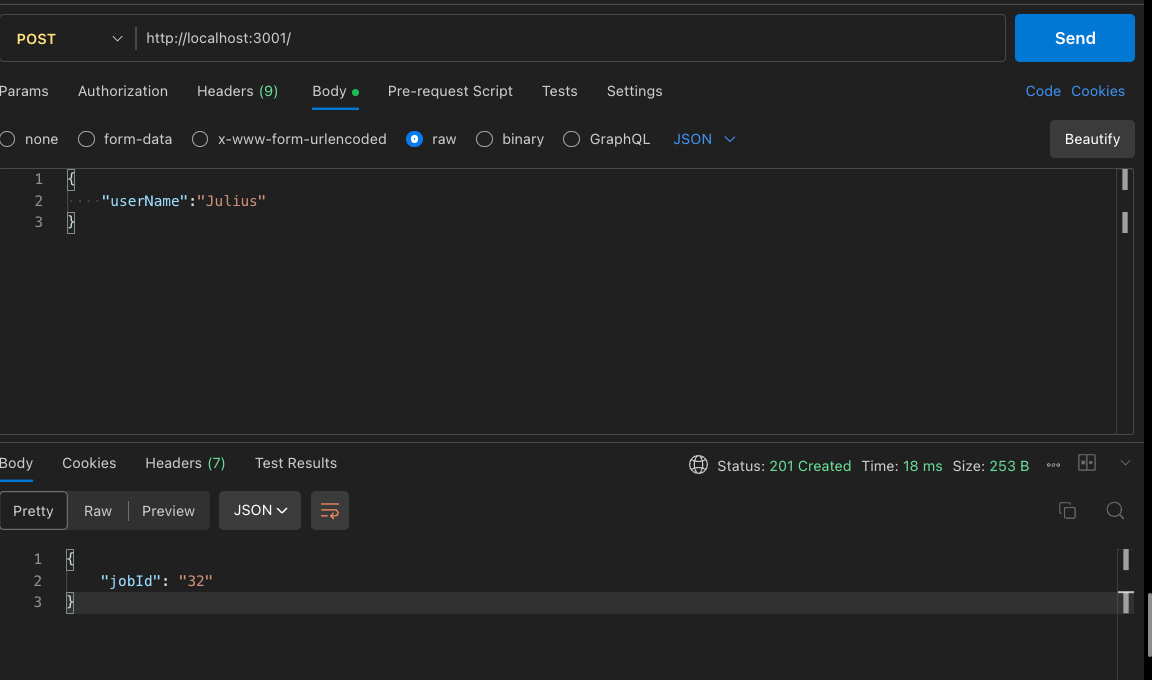
FlowProducer
The FlowProducer class allows to add jobs with dependencies between them in such a way that it is possible to build complex flows. Note: A flow is a tree-like structure of jobs that depend on each other. Whenever the children of a given parent are completed, the parent will be processed, being able to access the children’s result data. All Jobs can be in different queues, either children or parents.
You can access this project via the following link on GitHub
Conclusion
Just as Balázs Tápai rightly said, In an ExpressJS application, executing computationally intensive tasks on the main thread may lead to unresponsive or sluggish endpoints. Transitioning these tasks to a separate thread can effectively mitigate performance bottlenecks, and employing BullMQ can prove to be a valuable asset in this regard.
Comments
Loading comments…