
Web scraping is a technique to extract data from websites, and proxies are crucial in this process for ensuring seamless and uninterrupted data collection. Proxies act as intermediaries between the scraper and the target website, masking the scraper’s identity, thus helping to bypass website restrictions and avoid IP bans.
However, when it comes to proxies, many often opt for the do-it-yourself (DIY) approach, manually integrating proxies into their code. While such an approach may seem convenient on the surface, the DIY approach’s apparent benefits may not outweigh its problems and drawbacks.
This article will instead make the case for going with a professional off-the-shelf solution. We’ll look into the various challenges the DIY approach may encounter when scraping the web, and also compare the merits of the DIY approach and that of a fully-managed solution. Let’s dive in.
The Pitfalls of DIY Proxy Management
As mentioned earlier, proxies are crucial in the web scraping process for avoiding IP bans, ensuring anonymity, circumventing geolocation blocks and other anti-scraping measures. Opting for a DIY approach to proxies may seem appealing due to its cost-effectiveness and perceived quick resolution. However, if you’re trying to scale up your data collection process (which requires smooth and uninterrupted data collection), using the DIY approach is like applying a tissue to a situation that calls for a robust band-aid. In other words, it’s like addressing a critical need with a makeshift solution that may not adequately meet the demands of the task at hand.
Here are some of the challenges and drawbacks of the DIY approach:
- Websites use advanced defense mechanisms to detect and block automated scraping. These include CAPTCHAs, IP bans, timeouts, and geolocation restrictions. A DIY approach may not be robust enough to get around all of these restrictions and challenges, some of which require incorporating complex algorithms into your code and having to rely on third-party libraries.
- A diverse pool of IP addresses is necessary to prevent detection and bans which require infrastructure to support it. If you take the DIY approach, you’ll have to rely on external infrastructure which can become costly in terms of time and resources as your project grows in scale.
- Manual proxy management leads to more errors, requiring regular troubleshooting and taking time away from core business activities like actually collecting and analyzing the data.
- The DIY approach may encounter challenges in seamlessly scaling as the demands for data collection increase. As the volume of data to be scraped grows, DIY proxy solutions might face performance bottlenecks, causing delays and inefficiencies in the data retrieval process.
- Routine maintenance tasks of manual proxy management add significant overhead. These tasks, adjusting configurations, monitoring proxy health, and making manual adjustments, consume valuable time and resources without directly contributing to the advancement of the web scraping project.
Although the DIY approach may initially appear convenient, its drawbacks can significantly impact both time and resource costs, ultimately complicating and escalating the overall complexity and expenses associated with the web scraping process in the long term.
In the next section, we’ll compare and contrast a DIY or (in-house) approach and a professional off-the-shelf solution for proxy management.
Off-the-Shelf vs. In-House Solutions
Off-the-shelf proxy management refers to ready-made, commercially available solutions designed to facilitate the management of proxies for various applications and use cases. These pre-built proxy management solutions address the diverse needs of users without requiring extensive customization or in-house development.
In-house proxy management refers to the development/implementation of a custom, proprietary solution for managing proxies within your organization.
There are numerous reasons to choose one path over the other, so let’s examine them — side by side.
Cost vs. Time Considerations
1. Automation and Dynamic Adjustments:
Off-the-shelf solutions often come equipped with advanced automation features, allowing for the dynamic adjustment of proxies based on real-time needs. This level of automation significantly reduces the manual workload associated with proxy management, saves time, and enables a more efficient and responsive scraping process.

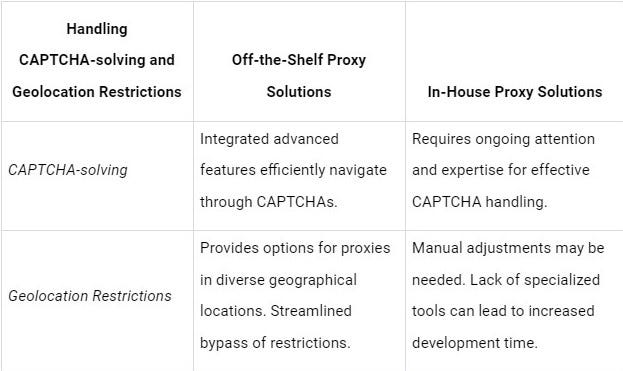
2. Handling CAPTCHA-solving and Geolocation Restrictions:
Dealing with CAPTCHA-solving and geolocation restrictions in an in-house proxy solution involves a complex process. Implementing effective strategies for CAPTCHA handling requires continuous updates and adaptation to evolving CAPTCHA mechanisms, demanding ongoing attention and expertise. Similarly, configuring proxies to address geolocation restrictions may involve manual adjustments and can be time-consuming. In contrast, Off-the-shelf proxy solutions often come integrated with advanced features to handle CAPTCHA-solving and geolocation restrictions seamlessly.
Long-Term Planning
1. Considerations for Longevity
Managing proxies in-house requires a comprehensive understanding of the dynamic proxy landscape and a commitment to continuous development. Without dedicated expertise and resources, the longevity of an in-house proxy solution may be susceptible to obsolescence and increased vulnerability. An off-the-shelf proxy solution entails leveraging a service provider’s expertise in proxy management, ensuring continuous updates, maintenance, and adaptation to evolving technological landscapes. This external support translates to a more sustainable and enduring solution.

2. Resources and Infrastructure
Managing proxies internally demands a substantial allocation of resources, including skilled personnel, time, and financial investments, all of which require ongoing dedication. In-house solutions may be constrained by budgetary limitations and the need for continuous updates. Opting for an off-the-shelf proxy solution means tapping into an established infrastructure provided by a specialized service. This not only minimizes the burden on internal resources but also ensures access to a scalable and well-maintained proxy network.

Apart from these key points of comparison, there are two other considerations worth bearing in mind when it comes to choosing between an in-house vs. an off-the-shelf solution:
- Ease of Implementation: Off-the-shelf solutions offer quick and straightforward implementation, catering to users without extensive technical expertise. In contrast, in-house solutions demand skilled developers, network administrators, and cybersecurity professionals for creation and maintenance.
- Ready-Made Features: Off-the-shelf solutions come with predefined features like IP rotation, user agent rotation, geolocation spoofing, and automated CAPTCHA solving to address common proxy management needs. In-house solutions require development to align with unique use cases, workflows, and security considerations, potentially offering customization benefits but introducing complexities in monitoring and maintenance.
As we can see, there are a significant number of advantages offered by off-the-shelf proxy solutions that do not have the significant drawbacks of the DIY approach. In general, the DIY approach may be perfectly fine for a one-off scraping task. But if data collection is crucial to your operation, and you need to collect data at scale smoothly and uninterruptedly, an off-the-shelf proxy solution without incurring significant additional infrastructural costs, then an off-the-shelf solution is the way to go.
In the next section, we’ll take a look at such a comprehensive solution for proxies when it comes to web scraping in the form of Bright Data’s Web Unlocker which takes care of all the challenges associated with manual proxy management.
Bright Data’s Web Unlocker: A Comprehensive Unblocking Solution for Web Scraping

As seen earlier, managing proxies manually can become a complex and time-consuming task that involves dealing with various obstacles such as CAPTCHAs, IP blacklisting, and geolocation restrictions. It also requires dynamic adjustments such as IP rotations, user agent management, and JavaScript rendering. Moreover, they can easily lead to additional infrastructural costs and scaling issues.
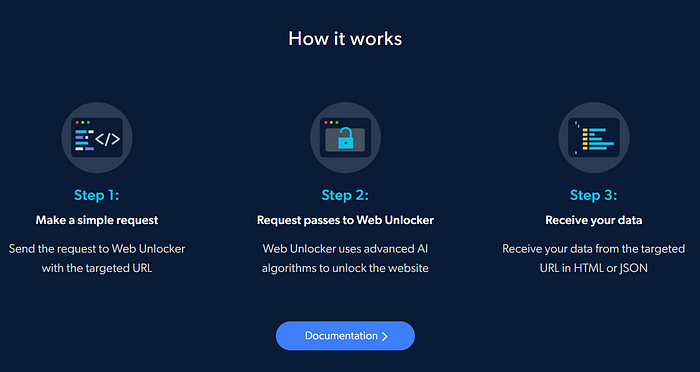
This is where a solution like the Web Unlocker comes in. The Web Unlocker is a proxy-unlocking solution designed to enable you to concentrate on your data collection, with Bright Data handling the entire proxy and unblocking infrastructure on your behalf, on their server end. Utilizing real-time monitoring, Web Unlocker actively addresses website blocking techniques through automated features such as browser fingerprinting, CAPTCHA solving, IP rotations, header customization, request retries, and more. This ensures seamless access to any site.
Web Unlocker automatically selects the best proxy network for your request, managing the infrastructure on your behalf, and prioritizing success, meaning that you no longer have to exhaust your IPs or set up intricate proxy waterfalls just to access essential web data.
This is an ideal solution for:
- Extracting data at scale from websites without encountering blocking issues
- Mimicking authentic user behavior to bypass sophisticated detection methods employed by certain websites
- Teams lacking an internally scalable unblocking infrastructure
- When opting to pay solely for successful requests
Learn more:
> Getting started with the Web Unlocker
In the next section, we’ll look into some of the features of the web unlocker and see how they enable a seamless scraping solution, and at the same time resolve all the challenges associated with DIY proxy management.
1. Environment Emulation Capabilities
One of the ways websites block your scraping attempts is by flagging and detecting you as a bot. Modern-day websites make use of browser/device fingerprints, analyzing various attributes of the user’s browser and device, such as screen resolution, installed fonts, and browser plugins, to create a unique fingerprint containing information about the configuration of a user’s browser as well as software/hardware environment. When there’s a mismatch between the usual information embedded in a request from a genuine user’s browser and the request coming from a scraping script, the website can detect you as a bot, and employ measures like CAPTCHAs and IP throttling.
Being able to emulate a genuine user’s behavior takes care of this problem at the root and this is where the web unlocker shines. It enables near-perfect emulation of browser fingerprint information including plugins, fonts, browser version, cookies, HTML5 canvas element or WebGL fingerprint, Web Audio API fingerprint, operating system, screen resolution, and more.
It automatically configures relevant header information (such as User-Agent strings), manages cookies according to the requirements of the target website, and can mimic all devices connected to any given system, including their corresponding drivers, mouse movements, screen resolution, and other device properties, achieving full device enumeration imitation.

When it comes to proxy management, it offers control at every level — Network, Protocol, Hardware/Operating Systems, and browsers. You can fine-tune IP rotations, HTTP headers, and User-agent generation, ensuring a seamless scraping process.
By providing precise control over web requests, it allows you to manage network routing, proxies, and configurations, customize protocols, and emulate hardware and operating systems for seamless integration with target environments. You can automate IP rotation, choosing between residential, data center, or mobile IP addresses depending on your use case.
💡Note: From CAPTCHA-solving to User-agent generation to cookie management and fingerprint emulation, the Web Unlocker can bypass even the most sophisticated anti-scraping measures. Learn more here.
2. Automatic CAPTCHA-Recognition and Solving
As mentioned in the previous section, one of the most foolproof ways to bypass CAPTCHAs is to prevent them from being generated in the first place. This can be done with the help of the web unlocker’s device/browser fingerprint emulation.
The web unlocker provides comprehensive user emulation, covering:
- Network-level features such as IP type, IP rotation, and TLS handshake
- Protocol-level functionalities, including manipulation of HTTP headers, generation of User-agents, and support for HTTP2
- Browser-level aspects like cookie management and emulation of browser fingerprints (e.g., fonts, audio, canvas/WebGL fingerprints, etc.)
- OS-level emulation, encompassing device enumeration, screen resolution, memory, CPU, etc.
But even if a CAPTCHA is generated, the web unlocker can easily solve it thanks to its advanced capabilities in CAPTCHA recognition and solving. The web unlocker comes equipped with a CAPTCHA Solver which can automatically detect the CAPTCHA strategy a target website is using, then solve it for you automatically, no third-party libraries required. It can solve reCAPTCHA, hCaptcha, px_captcha, SimpleCaptcha, and GeeTest CAPTCHA, and it stays updated automatically to consistently deal with websites that develop new ways to detect you.
3. AI-Driven Adaptability
The unlocker infrastructure uses AI behind the scenes to take care of the entire ever-changing flow of finding the best proxy network, customizing headers, fingerprinting, CAPTCHAs, and more. This allows it to dynamically re-calibrate settings, such as IP rotation, rate limits, and automatic retries (on a per-domain basis) to overcome access restrictions and improve resilience against connection issues or server-side variations.
This approach enables the system to stay on top of websites’ anti-scraping mechanisms, making strategic adjustments in real-time, and ensuring your scraping process remains uninterrupted.
4. Real Browser Integration
Bright Data’s Web Unlocker now scrapes dynamic JavaScript-based websites with accuracy and completeness by utilizing a real browser behind the scenes. It executes JavaScript, processes AJAX requests, and renders dynamic content in real-time for an accurate representation of dynamic elements. Bright Data’s Web Unlocker can simulate user interactions and events triggered by JavaScript to scrape dynamic website content.
Dynamic websites are websites that generate content and present information to users in real-time, often in response to user interactions or other data inputs. Unlike static websites, which display the same content to all users and don’t change unless manually updated, the main problem with dynamic websites is that the code and content are not automatically loaded when the user or scraper enters the site, and as a result, there’s virtually nothing to scrape. Dynamic websites usually retrieve their data from a database or external source, and they choose which data to retrieve due to the interactions or inputs of the user/scraper.
With the unlocker infrastructure, this is easily done as it scrapes dynamic JavaScript-based websites with accuracy and completeness by utilizing a real browser behind the scenes. It executes JavaScript, processes AJAX requests, and renders dynamic content in real time for an accurate representation of dynamic elements. It can also simulate user interactions and events triggered by JavaScript to scrape dynamic website content.
Conclusion
Proxies are the key to bypassing restrictions and avoiding IP bans and ensuring a seamless web scraping process. While proxies offer anonymity and make scraping easier, independently monitoring them can be tricky, requiring a lot of adjustments — IP rotations, User-agent and header manipulations, randomized delays, and retries, as well as handling JavaScript rendering.
Moreover, this approach necessitates the acquisition and maintenance of extensive infrastructure, troubleshooting errors, and losing valuable time and resources in routine maintenance tasks that do not directly contribute to the core business objectives.
In this article, we have made a case for adopting an off-the-shelf proxy management solution, especially for enterprise-grade scraping projects that require data collection at scale.
We looked at how a comprehensive and managed off-the-shelf solution such as Bright Data’s Web Unlocker, offers a more effective alternative. With features like environment emulation, automated IP rotation, dynamic adjustments, and more, it ensures you have a foolproof solution for seamless data collection without getting blocked.
The unlocker infrastructure is available with Bright Data’s other products like the Web Scraper IDE and the Scraping Browser and also comes with a free trial, so you can experience its power for yourself and check it out to see if it suits your web scraping needs.
Comments
Loading comments…