
In modern web and mobile application development, monolithic general-purpose backend APIs quickly grow too bulky and complex to deal with multiple ways to consume data on the frontend. Any band-aid solutions only muddy the separation of concerns between the frontend and backend components, and make codebases less maintainable and scalable.
To overcome these challenges, the Backends-for-Frontends (BFF) pattern has emerged as a popular solution...but there are many moving parts to a well-designed BFF, and devs frequently keep finding themselves reinventing the wheel for said parts.
So let's fix that! In this article, we'll explore five dev tools that need to be in your back pocket while building Backends-for-Frontends, how each alleviates specific pain points, and why you need them. Let's get right to it!
1. WunderGraph - The BFF Framework
WunderGraph is a free and open-source (Apache 2.0 license) Backend-for-Frontend framework, allowing you to declaratively turn your data dependencies - microservices, databases, and 3rd party APIs - into a secure, unified, and extensible API exposed over JSON-RPC.
What does this mean? When you're building web apps, a common problem is managing data dependencies. Your apps become data-heavy as they grow because of the need to compose or stitch together:
a. many different APIs (GraphQL/OpenAPI REST),
b. databases (SQL, NoSQL, or just via an ORM like Prisma),
c. and auth providers (Auth0, GitHub, etc.),
All of which can be written in different languages, designed using different architectures, and give out data in different formats (many legacy services use XML, for example, not JSON).
There's no standard for managing all of this. Sure, the Backend-for-Frontend (BFF) pattern helps, with one "backend" per frontend that acts as a reverse proxy, but there's no standard way to actually build these BFFs, either. Nothing that doesn't involve manually building and bringing together several layers and cross-cutting concerns.
This is where WunderGraph can help.
How WunderGraph Works
WunderGraph is an open-source, opinionated, full-stack dev tool that's essentially a BFF framework, supporting Next.js, Remix, Nuxt, SvelteKit, Astro, Expo, and more, so you can build the BFF you want instead of wasting time reinventing the wheel and gluing together boilerplate.
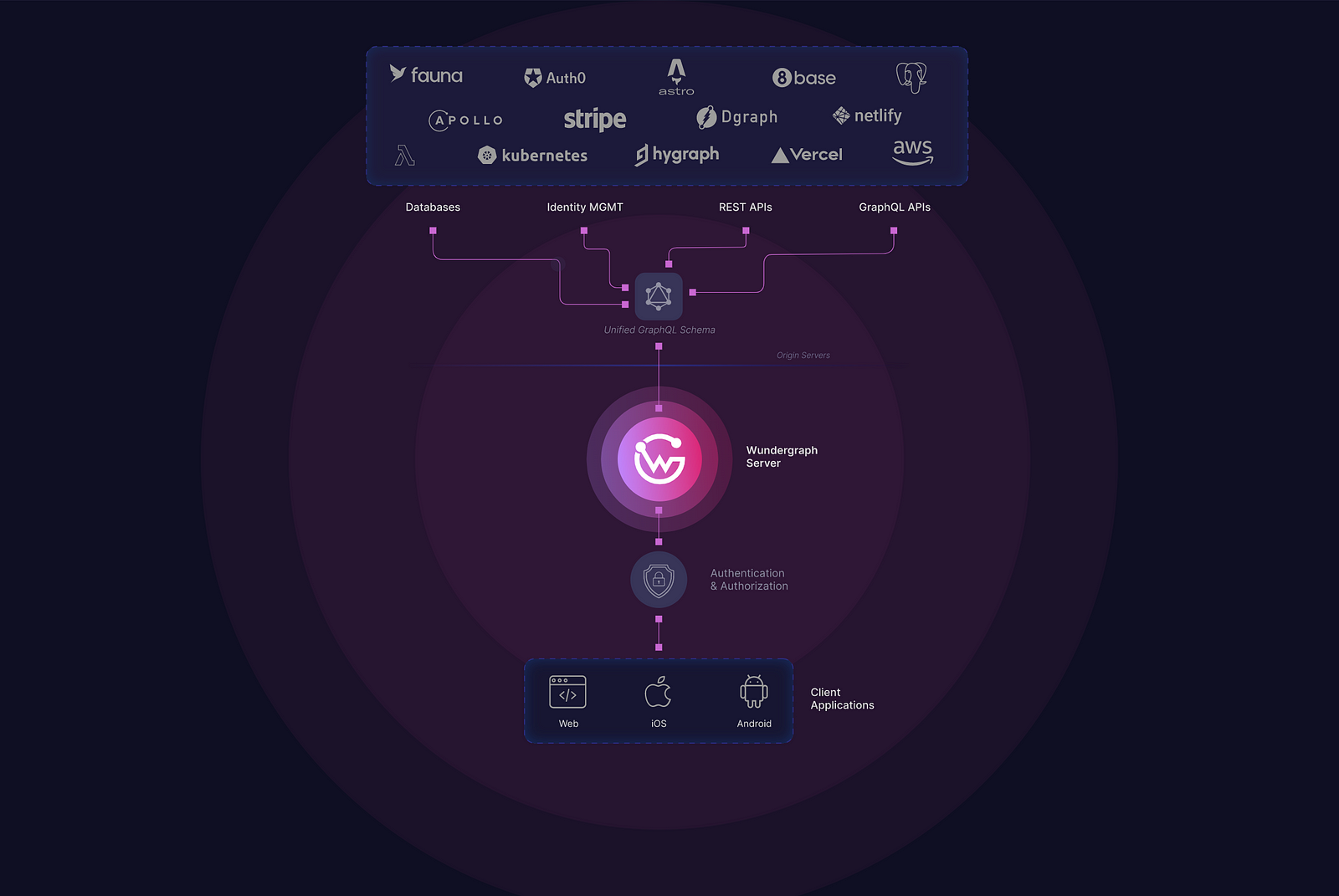
WunderGraph lets you define data and authentication dependencies (underlying SQL and NoSQL databases, GraphQL or OpenAPI REST APIs, gRPC, Apollo Federations, OIDC and non OIDC compatible auth providers etc), which may be third-party services, authentication, or wholly internal services that are not even exposed to the outside internet.
It then composes these APIs - aggregating and abstracting them into a namespaced virtual graph - and then you get data out of them using GraphQL or TypeScript operations, process and transform them as required, and access them from the frontend via typesafe data fetching hooks (if using a React-based framework) or just by calling the JSON-RPC endpoints.
Why use WunderGraph?
WunderGraph blurs the lines between API Gateways and the BFF pattern, and makes composition of APIs and datasources like using a package manager like NPM, but for data dependencies, to make life easier for all developers, no matter which area they work in:
- Frontend and backend being decoupled means frontend developers can develop against mocked or partial APIs, leading to rapid development and a faster time to market. Your WunderGraph BFF adds an additional layer of security here since this decoupling - together with the fact that GraphQL is being used only in development, not production - means that any consumer-facing experience in your design doesn't have to directly mirror internal services.
- You can effectively compose and stitch together data from various sources without worrying about how they are implemented, or doing Cross API data joins in the frontend/downstream microservices.
- WunderGraph serves data as JSON over RPC; at no point do you need to expose a public GraphQL endpoint. So caching, security, etc. are not a problem.
To get started with WunderGraph for building BFFs, check here.
The easiest way to build Backends for Frontends (BFFs)
2. Istio - Service Mesh for your Microservices
Istio is an open-source service mesh that makes managing, securing, and shaping all traffic and communication between your microservices - and adding observability, too - possible, without ever writing code for any of this - no matter how your distributed architecture is deployed.
In a microservices architecture, traffic can flow in two directions: north-south and east-west. North-south traffic refers to traffic that flows in and out of the cluster, such as traffic between the frontend and backend services. East-west traffic refers to traffic that flows between services within the cluster.
While API Gateways handle the north-south traffic between the backend cluster and the frontend client(s), abstracting away implementation detail, service meshes like Istio are built specifically for east-west traffic to give more manageable and secure communication between the services within a backend cluster.
Why use Istio?
- Route and shape traffic between microservices, with added load balancing and service discovery. This means you can use Istio to implement A/B testing, canary releases, and other deployment strategies without requiring any changes to underlying microservices themselves.
- Provide security, role-based access control, and encryption across backend services, ensuring that sensitive data is properly obfuscated and that the requests being made to any microservice within the cluster are from a valid source (authentication) and one that is allowed to make that request (authorization).
- Add observability - distributed tracing, logging, and metrics across all components of a service, etc. As a service mesh, Istio is privy to all traffic within a cluster anyway, so using it for any and all logging needs is a no-brainer.
- Make testing microservices in isolation easier. The distributed, interconnected nature of these systems makes it challenging to reproduce and diagnose issues. Istio intercepts ALL inter-service traffic by default, making it a great vector for injecting faults, delays, and other conditions into the communication between services to simulate different scenarios and test how the system responds.
- Add resilience - If an individual downstream component (say, a database) called by multiple microservices goes down, it can bring all of them down in turn. If those fail, in turn, the API gateways that use them stop working properly, and this propagates up the chain. Also, if one of these downstream components is running slowly, the response time of the entire backend cluster is equal to the speed of the slowest downstream call. Service meshes like Istio fix that with:
- Automatic retries until the call succeeds,
- Implementing a circuit breaker pattern means that after a few failed retry attempts, we don't attempt that call again for a while and risk congestion.
- Rate-limiting to ensure any of our microservices don't flood downstream calls.
In summary, Istio is a powerful platform for managing microservices-based applications. It provides traffic management, security, and observability capabilities, making it easier to deploy, manage, and secure microservices across different platforms and cloud environments.
3. AWS - Serverless Computing (API Gateways, Lambdas)
Serverless computing is a cloud computing model in which you can build and run applications without having to manage the underlying infrastructure. If you're using the multitude of services offered by Amazon's AWS, it'll take care of server management, scaling, and maintenance so that you can focus on writing your application code.
What does "serverless" mean?
- No infra provisioning or management on your part - The cloud provider can create resources as and when you need, and this is a managed service. You don't have to manage on-prem/bare metal servers/databases.
- Cattle, not pets - Servers aren't 'real' physical entities as far as you're concerned. They can be entirely discarded and rebuilt anew whenever needed, making easy iteration and experimentation possible.
- Auto scaling - Add more resources automatically if your traffic needs demand it.
- Highly available, fault-tolerant, secure - If one server goes down, there is no downtime. Another can immediately be spun up to replace it.
- Pay as you go i.e. pay for only what you consume - data, compute resources, processing time, etc. Particularly beneficial for smaller, less frequently used backend services that would otherwise require dedicated servers to run.
Why use serverless tech to build BFFs?
Because of those benefits, serverless tech stacks for your BFF layer (like in AWS) can help you move fast, scale up and down according to demand, and, with pay-as-you-go, potentially be far more cost-effective than building and hosting your own on-prem server, making them ideal for rapid, iterative BFF development and a faster time to market.
How do I start building a BFF with serverless tech?
Here's the TL;DR: Amazon API Gateway (routes requests from the frontend to the backend) + AWS Lambda (contains functions for your business logic, data transformations, or processing data from the backend) + DynamoDB (for storing data from downstream microservices).
The logical question now, of course, is how you collect data from your downstream microservices and put them into the DynamoDB layer to begin with. Here are some options:
- Using Webhoooks: Downstream services will push updates to your Lambda functions using Webhooks (as HTTP requests). The AWS Lambda Function URLs makes this easy - you won't need any extraneous API Gateways. Your Lambdas can include the BFF logic. This way, there's no need for an event-driven architecture.
- Using Event Consumers: But if an event-driven architecture makes more sense for your use case, and your microservices can actually publish events, use Amazon EventBridge to collect these pushed events and route them to Lambda functions according to a rule.
- Using Polling: But what if your downstream services can neither make HTTP requests nor publish events? In that case, you'll need to poll them manually. An AWS service that makes sense here is the EventBridge Scheduler. With it, you can create cron jobs to manually trigger Lambda functions that poll the APIs of your downstream microservices for data.
What remains is auth and observability, and the AWS suite includes solutions for them, too - Identity and Access Management (IAM), Web Application Firewall (WAF), Cognito, Cloudwatch, etc. Overall, serverless technologies (and the AWS platform in particular) provides a range of services and tools that make it an ideal choice for developing BFFs.
4. Clerk/Auth.js - Auth
The Backend-for-Frontend layer is ideal for handling auth, as negotiating authentication and authorization directly from the public frontend client (i.e., running in a browser) is risky. Auth solutions like Clerk and Auth.js make this even easier:
a. They're incredibly easy to integrate into any tech stack, with single sign on (SSO) support from providers like Google, FB, GitHub
b. They're incredibly customizable, providing customizable interfaces for login, registration, and account management.
Clerk offers a simple, secure, regularly-audited, best-practices way to add authentication to your application with drop-in components and pages. It is purpose-built for the JAMstack, supporting NextJS, Remix, RedwoodJS, Gatsby, React Native/Expo, with database integrations for Hasura, Supabase, Fauna, Firebase, and Grafbase.
Auth.js, just like Clerk, is used for authentication in web applications. It is an open-source authentication solution that was first developed for only Next.Js applications but now supports other frameworks like Svelte and SolidJS, with a staggering number of database integrations.

Clerk and Auth.JS support a wide range of authentication methods, including email and password, social logins (such as Google and Facebook), single sign-on (SSO), and multi-factor authentication (MFA). It also provides customizable user interfaces for login, registration, and account management.
No matter which one you use, here's the workflow:
- Whenever the frontend needs to authenticate or authorize a user, it calls an endpoint on the BFF, let's say, "/api/auth"
- The BFF uses OpenID Connect (OIDC) or another method to authenticate the user, generating ID, access, and refresh tokens.
- Tokens are cached, and an encrypted cookie is issued to the frontend that represents the current session of this user.
- Whenever the frontend needs to access data from downstream services, it passes the encrypted cookie to the BFF, which extracts the access token from its cache and calls the downstream APIs or microservices, including that token in the authorization header.
- Downstream services return a response to the BFF, and the BFF forwards it to the frontend.
Clerk and Auth.js can be easily integrated into your web application using their JavaScript API and React components. It also offers a flexible and customizable API that allows you to build custom authentication flows and integrate them with your backend APIs and services.
💡 If you're using WunderGraph, for example, it can integrate both Clerk and Auth.js in front of WunderGraph's API Server, and explicitly require authentication to do any querying, mutating, or updating at all. Check out this article to learn more.
5. Axiom, Grafana, Datadog - Performance Monitoring, Analytics, and Logging
Adding observability to your BFF is important for understanding and troubleshooting issues in your application, and for making informed decisions on optimization and scaling.
You don't have to roll your own solution for this - use tools like Axiom, Grafana, and Datadog to identify + diagnose issues with your BFF, by tracking metrics such as response time, error rates, and resource usage, and receive alerts if any of these metrics exceed defined thresholds.
Axiom is a data management and analytics platform that enables organizations to gather, manage, and analyze large volumes of data from various sources. The platform is designed to provide users with a comprehensive view of their data, allowing them to make better-informed business decisions.
Grafana is an open-source analytics and visualization platform that allows you to monitor and analyze data from various sources, including databases, cloud services, and IoT devices. Grafana can help you create interactive, real-time dashboards and alerts for your applications and infrastructure.
Datadog is a cloud-based monitoring and analytics platform that provides visibility into the performance of applications, infrastructure, and logs. The platform is designed to collect, process, and analyze large volumes of data in real-time, and provides insights and visualizations to help users troubleshoot issues, optimize performance, and improve overall efficiency.
These services can even visualize collected data for you, setting up dashboards to monitor metrics in real-time, and letting you quickly identify concerning trends.
💡 They can even integrate with serverless and cloud platforms like AWS and Azure, if your BFF is using serverless tech, as mentioned before.
Bonus Pick - NextJS/Remix!
Surprised? Don't be! These are primarily frameworks for fullstack development, yes, but they can also be used as BFF's by definition.
How? These frameworks provide the necessary infrastructure and features to create a dedicated backend application (this is usually a NodeJS layer) per frontend, tightly coupled with it, managed by the frontend team itself, and deployed together with the frontend - aka, the ideal definition of a BFF.
For NextJS this takes the form of API routes, and for Remix, it's the Loader pattern. Both can serve as great choices for a BFF layer if your project or app already has a mature backend coded in PHP, Ruby, Elixir, etc. (i.e., anything not JavaScript).
Wrapping Up
In conclusion, the Backends-for-Frontends (BFF) pattern makes developing complex, modern, multiplatform web applications easier, but a common pain point for developers is time wasted reinventing the wheel, implementing ad hoc solutions for a BFFs various parts, and coding and gluing together boilerplate.
Hopefully, the five tools discussed in this article will help you streamline your development, boost developer velocity, and let you provide the best user experience regardless of the platforms you're supporting.
While tools like Istio (service meshes for microservices orchestration), AWS (for building serverless BFF patterns), and Clerk/Auth.js (for auth) help you address individual pain points for building BFFs, WunderGraph serves as an all-in-one BFF framework, much like Next.js is for React development in general.
Comments
Loading comments…