Implementing RAG presents a challenge, especially when it comes to effectively parsing and understanding tables in unstructured documents. This is particularly difficult with scanned documents or documents in image format. There are at least three aspects of these challenges:
- The complexity of scanning documents or image documents, such as their diverse structures, the inclusion of non-text elements, and the combination of handwritten and printed content, presents challenges for accurately extracting table information automatically. Inaccurate parsing can damage the table structure, and using an incomplete table for embedding can not only fail to capture the table’s semantic information, but it can also easily corrupt the RAG results.
- How to extract table captions and effectively link them to their respective tables.
- How to design an index structure to effectively store the semantic information of the table.
This article begins by introducing the key technologies for managing tables in RAG. It then reviews some existing open-source solutions before proposing and implementing a new solution.
key Technologies
Table Parsing
The primary function of this module is to accurately extract the table structure from unstructured documents or images.
Additional features: It would be best to extract the corresponding table caption, and make it convenient for developers to associate the table caption with the table.
Based on my current understanding, there are several methods, as shown in Figure 1:
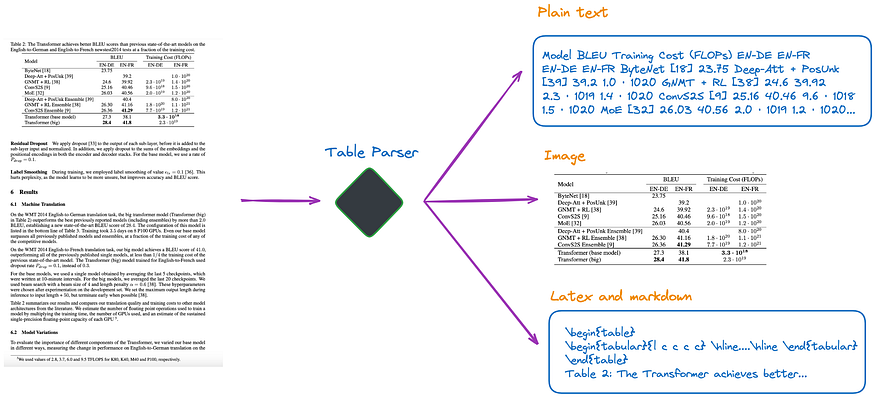
Figure 1: Table parser. Image by author.
(a). Utilize multimodal LLM, like GPT-4V, to identify tables and extract information from each PDF page.
- Input: PDF page in image format
- Output: Table in JSON or another format. If the multimodal LLM is unable to extract the table data, it should summarize the image and return the summary.
(b). Utilize professional table detection models, like Table Transformer, to discern the table structure.
- Input: PDF page as an image
- Output: Table as an image
(c). Use open-source frameworks, like unstructured and others, which also employ object detection models(unstructured’s table detection process is detailed in this article). These frameworks allow for comprehensive parsing of the entire document, and extraction of table-related content from the parsed results.
- Input: Documents in PDF or image format
- Output: Tables in plain text or HTML format, obtained from the parsing results of the entire document
(d). Use end-to-end models like Nougat, Donut, etc., to parse the whole document and extract table-related content. This approach doesn’t require an OCR model.
- Input: Documents in PDF or image format
- Output: Tables in LaTeX or JSON format, obtained from the parsing results of the entire document
It is worth mentioning that regardless of the method used to extract table information, the table caption should be included. This is because in most cases, the table caption is a brief description of the table by the document or paper author, which can largely summarize the entire table.
Among the four methods mentioned above, the method (d) allows for easy retrieval of the table caption. This is beneficial for developers as it allows them to associate the table caption with the table. This will be further explained in the following experiment.
Index Structure
According to the structure of the index, the solution can be roughly divided into the following categories:
(e). Only index tables in image format.
(f). Only index tables in plain text or JSON format.
(g). Only index tables in LaTeX format.
(h). Only index the summary of a table.
(i). Small-to-big or Document Summary Index structure, as shown in Figure 2.
- The content of the small chunk can be information from each row of a table or a summary of the table.
- The content of the big chunk can be a table in image format, plain text format, or LaTeX format.
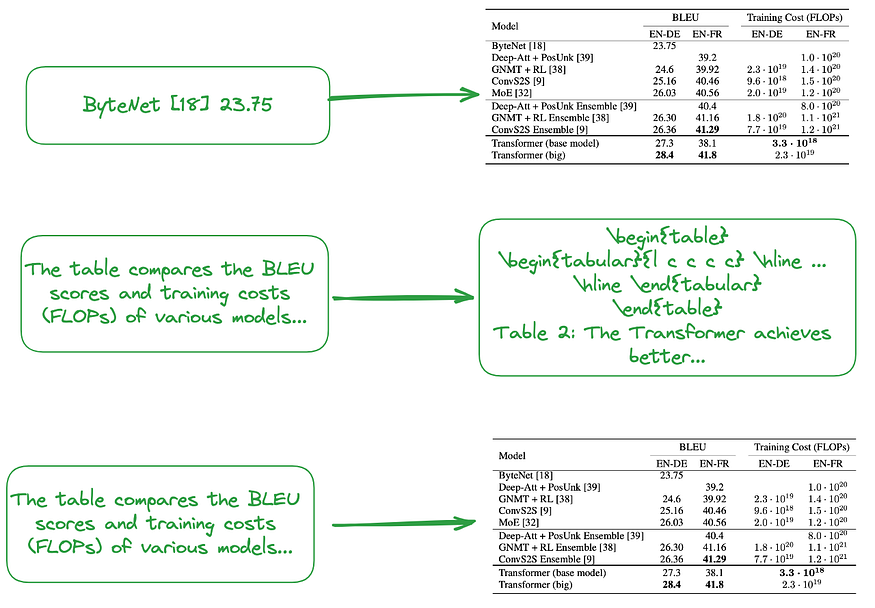
Figure 2: Structure of the small-to-big index (upper) and the document summary index (middle and lower). Image by author.
The table summary, as discussed above, is typically generated using LLM:
- Input: Table in image format, text format, or LaTeX format
- Output: Table summary
Algorithms that Don’t Require Table Parsing, Indexing, or RAG
Some algorithms don’t require table parsing.
(j). Send relevant images(PDF pages) and user’s query to VQA models (like DAN etc.) or multimodal LLM, and return the answer.
- Content to be indexed: Document in image format
- The content sent to VQA model or multimodal LLM: Query + corresponding pages in image form
(k). Send the relevant text format PDF page and the user’s query to LLM, then return the answer.
- Content to be indexed: Document in text format
- The content sent to LLM: Query + corresponding pages in text format
(l). Send relevant images (PDF pages), text chunks, and user’s query to multimodal LLM(like GPT-4V, etc.) , and return the answer directly.
- Content to be indexed: Document in image format and document chunks in text format
- The content sent to multimodal LLM: Query + corresponding image form of the document + corresponding text chunks
Additionally, below are some methods that do not require indexing, as shown in Figures 3 and 4:
Figure 3: Category (m). Image by author.
(m). First, apply one of the methods from categories (a) to (d), parse all the tables in the document into image form. Then directly send all table images, and the user’s query to a multimodal LLM(like GPT-4V, etc.) and return the answer.
- Content to be indexed: None
- The content sent to multimodal LLM: Query + all parsed tables(in image format)
Figure 4: Category (n). Image by author.
(n). Use the table in the image format extracted by (m), and then use an OCR model to recognize all the text in the table, then directly send all the text in the table and user’s query to LLM and return the answer directly.
- Content to be indexed: None
- The content sent to LLM: User’s query + all table content(in text format)
It’s worth noting that some methods don’t rely on the RAG process:
- The first method doesn’t use LLM, trains on a specific dataset, and enables models(such as BERT-like transformers) to better support table understanding tasks, such as TAPAS.
- The second method uses LLM, employs pre-training, fine-tuning methods or prompts, to enable LLM to perform table understanding tasks, like GPT4Table.
Existing Open Source Solutions
The previous section summarized and categorized key techniques for tables in RAG. Let’s explore some open-source solutions before proposing the solution that this article implements.
LlamaIndex proposed four approaches, with the first three using multimodal models.
- Retrieving relevant images (PDF pages) and sending them to GPT-4V to respond to queries.
- Regarding every PDF page as an image, let GPT-4V do the image reasoning for each page. Build Text Vector Store index for the image reasonings. Query the answer against the Image Reasoning Vectore Store.
- Using Table Transformer to crop the table information from the retrieved images and then sending these cropped images to GPT-4V for query responses.
- Applying OCR on cropped table images and send the data to GPT4/ GPT-3.5 to answer the query.
According to the classification of this article:
- The first method, similar to category (j) in this article, doesn’t require table parsing. However, the results show that even if the answer is in the images, it is unable to produce the correct answer.
- The second method involves table parsing and corresponds to category (a). The indexed content is either the table content or summary, based on the results returned by GPT-4V, which could correspond to category (f) or (h). The disadvantage of this method is that GPT-4V’s ability to identify tables and extract their content from images is unstable, particularly when the image includes a mix of tables, text, and other images, a common occurrence in PDF format.
- The third method, similar to category (m), doesn’t require indexing.
- The fourth method, similar to category (n), also doesn’t require indexing. Its results indicate that incorrect answers are produced due to an inability to extract table information from images.
Through testing, it was found that the third method yields the best overall effect. However, according to my tests, the third method struggles with detecting tables, let alone correctly merging the table title with the table.
Langchain has also proposed some solutions, the key technologies of Semi-structured RAG include:
- Table parsing uses unstructured, which is category (c).
- The indexing method is document summary index, which is category (i), small chunk content: table summary, big chunk content: raw table content(in text format).
As shown in Figure 5:
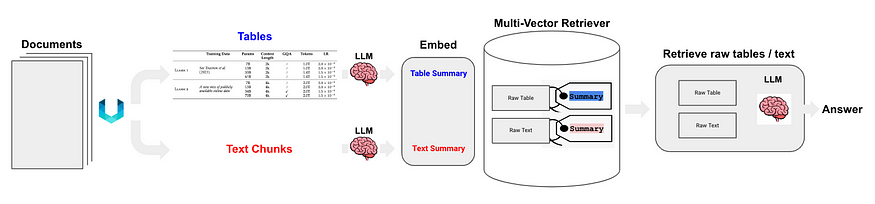
Figure 5: Langchain’s semi-structured RAG. Source: Semi-structured RAG
Semi-structured and Multi-modal RAG proposes three solutions, The architecture is depicted in Figure 6.
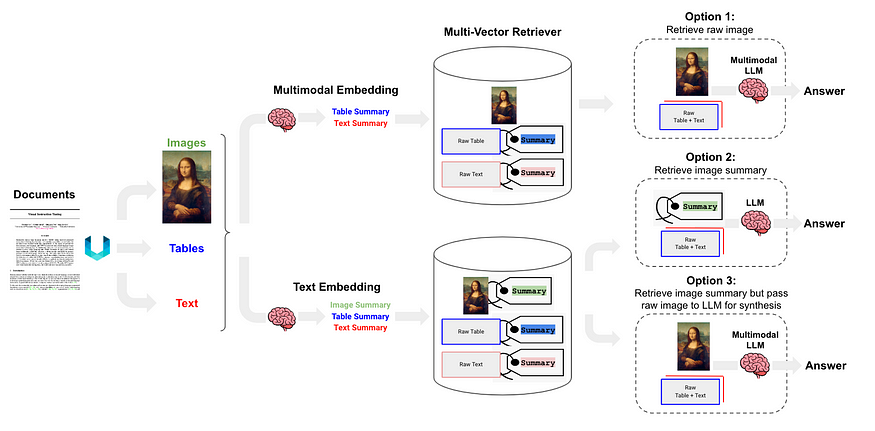
Figure 6: Langchain’s semi-structured and multi-modal RAG. Source: Semi-structured and Multi-modal RAG.
Option 1 is similar to category (l) of this article. It involves using multimodal embeddings (such as CLIP) to embed images and text, retrieving both using similarity search, and passing raw images and chunks to a multimodal LLM for answer synthesis.
Option 2 utilize a multimodal LLM, such as GPT-4V, LLaVA, or FUYU-8b, to generate text summaries from images. Then, embed and retrieve the text, and pass the text chunks to an LLM for answer synthesis.
- Table parsing uses unstructured, which is category (d).
- The index structure is document summary index(catogery (i)), small chunk content: table summary, big chunk content: table in text format
Option 3 use a multimodal LLM (such as GPT-4V, LLaVA, or FUYU-8b) to produce text summaries from images, then embed and retrieve image summaries with a reference to the raw image(catogery (i)), then pass raw images and text chunks to a multimodal LLM for answer synthesis.
Proposed Solution
This article has summarized, classified, and discussed key technologies and existing solutions. Based on this, we propose the following solution, illustrated in Figure 7. For simplicity, some RAG modules such as Re-ranking and query rewriting have been omitted.
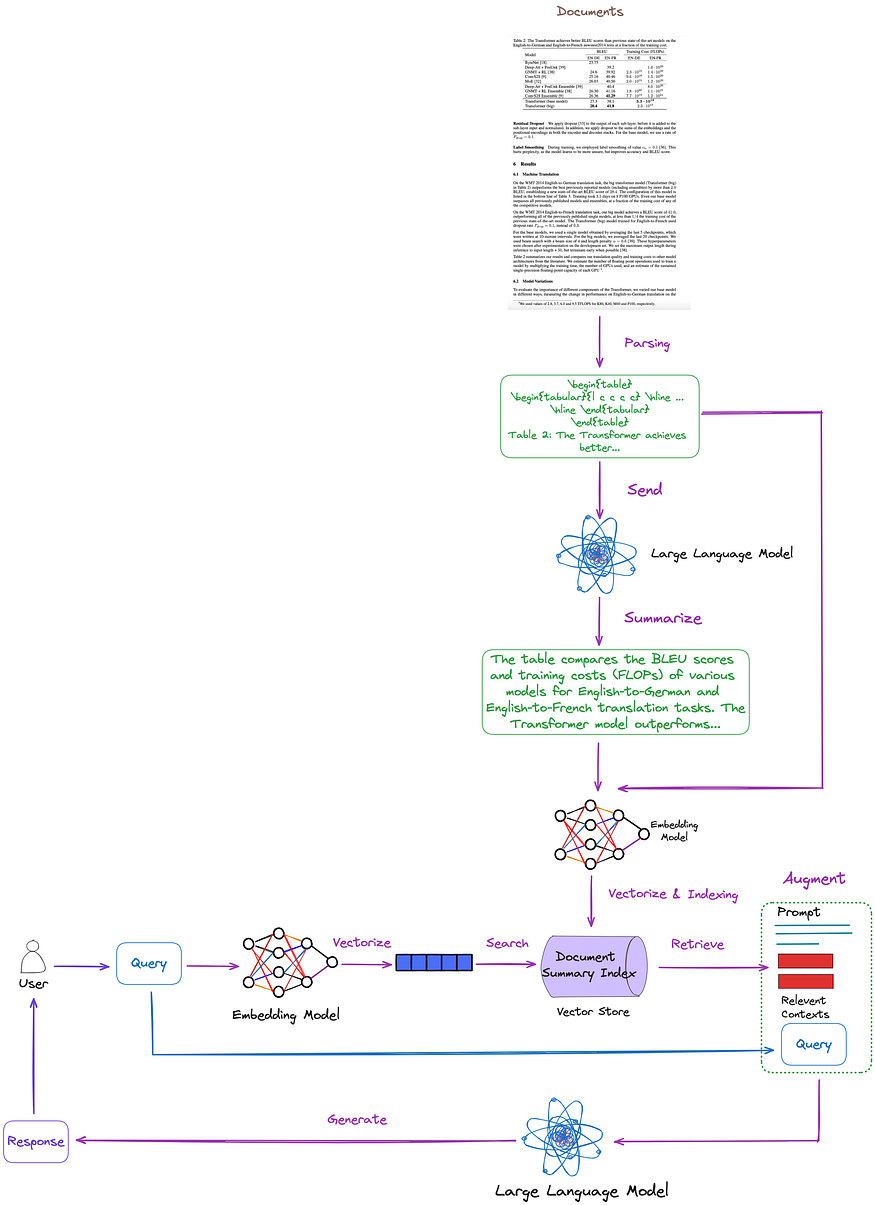
Figure 7: Proposed solution in this article. Image by author.
- Table parsing: Use Nougat(catogery (d)). According to my tests, its table detection is more effective than unstructured(catogery (c)). Additionally, Nougat can extract table captions well, very convenient to associate with the table.
- Document summary index structure(catogery (i)): The content of the small chunk includes the table summary, the content of the big chunk includes the corresponding table in LaTeX format and and table caption in text format. We implement it using the multi-vector retriever.
- Table summary acquisition method: Send the table and table caption to LLM for summarization.
The advantage of this method is that it efficiently parses tables while comprehensively considering the relationship between table summaries and tables. It also eliminates the need for multimodal LLM, resulting in cost savings.
The principle of Nougat
Nougat is developed based on the Donut architecture. It recognizes text through the network implicitly, without requiring any OCR-related input or modules, as shown in Figure 8.
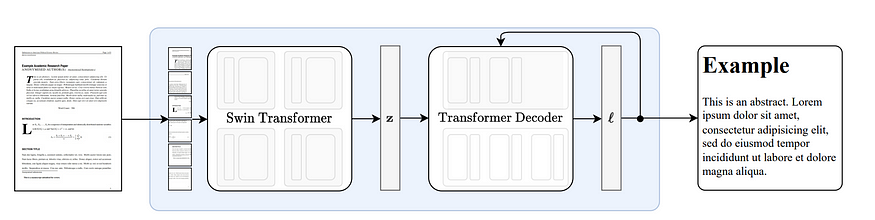
Figure 8: End-to-end architecture following Donut. The Swin Transformer encoder takes a document image and converts it into latent embeddings, which are subsequently converted to a sequence of tokens in a autoregressive manner. Source: Nougat: Neural Optical Understanding for Academic Documents.
Nougat’s ability to parse formulas is impressive. It also excels in parsing tables. Conveniently, it can associate table captions, as demonstrated in Figure 9:

Figure 9: The results of running Nougat, the result file is in Mathpix Markdown format (opened through vscode plugin), the table is in LaTeX format.
In my tests of over a dozen papers, I found that the table caption is always fixed on the line following the table. This consistency suggests it’s not accidental. Therefore, we are interested in understanding how Nougat achieves this effect.
Given that it’s an end-to-end model lacking intermediate results, it likely relies heavily on its training data.
According to the code for formatting training data, for table, the line immediately following **\end{table}** is **caption_parts**, which appears to be consistent with the format of the provided training data:
def format_element(
element: Element, keep_refs: bool = False, latex_env: bool = False
) -> List[str]:
"""
Formats a given Element into a list of formatted strings.
Args:
element (Element): The element to be formatted.
keep_refs (bool, optional): Whether to keep references in the formatting. Default is False.
latex_env (bool, optional): Whether to use LaTeX environment formatting. Default is False.
Returns:
List[str]: A list of formatted strings representing the formatted element.
"""
...
...
if isinstance(element, Table):
parts = [
"[TABLE%s]\n\\begin{table}\n"
% (str(uuid4())[:5] if element.id is None else ":" + str(element.id))
]
parts.extend(format_children(element, keep_refs, latex_env))
caption_parts = format_element(element.caption, keep_refs, latex_env)
remove_trailing_whitespace(caption_parts)
parts.append("\\end{table}\n")
if len(caption_parts) > 0:
parts.extend(caption_parts + ["\n"])
parts.append("[ENDTABLE]\n\n")
return parts
...
...
Pros and Cons of nougat
Advantages:
- Nougat can accurately parse parts that were challenging for previous parsing tools, such as formulas and tables, into LaTeX source code.
- The parsing result of Nougat is a semi-structured document similar to markdown.
- Easily obtain table captions and associate them with tables conveniently.
Disadvantages:
- The parsing speed of Nougat is slow, which could pose a challenge for large-scale deployment.
- As Nougat is trained on scientific papers, it excels with documents of similar structure. Its performance decreases with non-Latin text documents.
- The Nougat model only trains on one page of a scientific paper at a time, lacking knowledge of the other pages. This may result in some inconsistencies in the parsed content. Therefore, if the recognition effect is not good, consider dividing the PDF into separate pages and parsing them one by one.
- Parsing tables in two-column papers is not as effective as in single-column papers.
Code Implementation
First, install the relevant Python packages
pip install langchain
pip install chromadb
pip install nougat-ocr
After completing the installation, we can check the version of Python packages:
langchain 0.1.12
langchain-community 0.0.28
langchain-core 0.1.31
langchain-openai 0.0.8
langchain-text-splitters 0.0.1
chroma-hnswlib 0.7.3
chromadb 0.4.24
nougat-ocr 0.1.17
Set up the environment and import:
import os
os.environ["OPENAI_API_KEY"] = "YOUR_OPEN_AI_KEY"
import subprocess
import uuid
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import ChatPromptTemplate
from langchain_openai import ChatOpenAI
from langchain.retrievers.multi_vector import MultiVectorRetriever
from langchain.storage import InMemoryStore
from langchain_community.vectorstores import Chroma
from langchain_core.documents import Document
from langchain_openai import OpenAIEmbeddings
from langchain_core.runnables import RunnablePassthrough
Download the paper Attention Is All You Need to **YOUR_PDF_PATH**, run nougat to parse PDF file, and obtain tables in latex format and table captions in text format from the parsing results. The first execution will download the necessary model files.
def june_run_nougat(file_path, output_dir):
# Run Nougat and store results as Mathpix Markdown
cmd = ["nougat", file_path, "-o", output_dir, "-m", "0.1.0-base", "--no-skipping"]
res = subprocess.run(cmd)
if res.returncode != 0:
print("Error when running nougat.")
return res.returncode
else:
print("Operation Completed!")
return 0
def june_get_tables_from_mmd(mmd_path):
f = open(mmd_path)
lines = f.readlines()
res = []
tmp = []
flag = ""
for line in lines:
if line == "\\begin{table}\n":
flag = "BEGINTABLE"
elif line == "\\end{table}\n":
flag = "ENDTABLE"
if flag == "BEGINTABLE":
tmp.append(line)
elif flag == "ENDTABLE":
tmp.append(line)
flag = "CAPTION"
elif flag == "CAPTION":
tmp.append(line)
flag = "MARKDOWN"
print('-' * 100)
print(''.join(tmp))
res.append(''.join(tmp))
tmp = []
return res
file_path = "YOUR_PDF_PATH"
output_dir = "YOUR_OUTPUT_DIR_PATH"
if june_run_nougat(file_path, output_dir) == 1:
import sys
sys.exit(1)
mmd_path = output_dir + '/' + os.path.splitext(file_path)[0].split('/')[-1] + ".mmd"
tables = june_get_tables_from_mmd(mmd_path)
The function june_get_tables_from_mmd is used to extract all content from t begin{table} to end{table} , including the line following end{table}, from a mmd file shown in Figure 10.

Figure 10: The results of running Nougat, the result file is in Mathpix Markdown format (opened through vscode plugin), the table is in latex format. **The function of june_get_tables_from_mmd is to extract the table information in the red box**. Image by author.
It’s worth noting that no official document has been found to specify that the table caption must be placed below the table or that the table should start with begin{table} and end with end{table}. Therefore, june_get_tables_from_mmd is heuristic.
Here are the results of parsing the table in the PDF:
Operation Completed!
----------------------------------------------------------------------------------------------------
\begin{table}
\begin{tabular}{l c c c} \hline \hline Layer Type & Complexity per Layer & Sequential Operations & Maximum Path Length \\ \hline Self-Attention & \(O(n^{2}\cdot d)\) & \(O(1)\) & \(O(1)\) \\ Recurrent & \(O(n\cdot d^{2})\) & \(O(n)\) & \(O(n)\) \\ Convolutional & \(O(k\cdot n\cdot d^{2})\) & \(O(1)\) & \(O(log_{k}(n))\) \\ Self-Attention (restricted) & \(O(r\cdot n\cdot d)\) & \(O(1)\) & \(O(n/r)\) \\ \hline \hline \end{tabular}
\end{table}
Table 1: Maximum path lengths, per-layer complexity and minimum number of sequential operations for different layer types. \(n\) is the sequence length, \(d\) is the representation dimension, \(k\) is the kernel size of convolutions and \(r\) the size of the neighborhood in restricted self-attention.
----------------------------------------------------------------------------------------------------
\begin{table}
\begin{tabular}{l c c c c} \hline \hline \multirow{2}{*}{Model} & \multicolumn{2}{c}{BLEU} & \multicolumn{2}{c}{Training Cost (FLOPs)} \\ \cline{2-5} & EN-DE & EN-FR & EN-DE & EN-FR \\ \hline ByteNet [18] & 23.75 & & & \\ Deep-Att + PosUnk [39] & & 39.2 & & \(1.0\cdot 10^{20}\) \\ GNMT + RL [38] & 24.6 & 39.92 & \(2.3\cdot 10^{19}\) & \(1.4\cdot 10^{20}\) \\ ConvS2S [9] & 25.16 & 40.46 & \(9.6\cdot 10^{18}\) & \(1.5\cdot 10^{20}\) \\ MoE [32] & 26.03 & 40.56 & \(2.0\cdot 10^{19}\) & \(1.2\cdot 10^{20}\) \\ \hline Deep-Att + PosUnk Ensemble [39] & & 40.4 & & \(8.0\cdot 10^{20}\) \\ GNMT + RL Ensemble [38] & 26.30 & 41.16 & \(1.8\cdot 10^{20}\) & \(1.1\cdot 10^{21}\) \\ ConvS2S Ensemble [9] & 26.36 & **41.29** & \(7.7\cdot 10^{19}\) & \(1.2\cdot 10^{21}\) \\ \hline Transformer (base model) & 27.3 & 38.1 & & \(\mathbf{3.3\cdot 10^{18}}\) \\ Transformer (big) & **28.4** & **41.8** & & \(2.3\cdot 10^{19}\) \\ \hline \hline \end{tabular}
\end{table}
Table 2: The Transformer achieves better BLEU scores than previous state-of-the-art models on the English-to-German and English-to-French newstest2014 tests at a fraction of the training cost.
----------------------------------------------------------------------------------------------------
\begin{table}
\begin{tabular}{c|c c c c c c c c|c c c c} \hline \hline & \(N\) & \(d_{\text{model}}\) & \(d_{\text{ff}}\) & \(h\) & \(d_{k}\) & \(d_{v}\) & \(P_{drop}\) & \(\epsilon_{ls}\) & train steps & PPL & BLEU & params \\ \hline base & 6 & 512 & 2048 & 8 & 64 & 64 & 0.1 & 0.1 & 100K & 4.92 & 25.8 & 65 \\ \hline \multirow{4}{*}{(A)} & \multicolumn{1}{c}{} & & 1 & 512 & 512 & & & & 5.29 & 24.9 & \\ & & & & 4 & 128 & 128 & & & & 5.00 & 25.5 & \\ & & & & 16 & 32 & 32 & & & & 4.91 & 25.8 & \\ & & & & 32 & 16 & 16 & & & & 5.01 & 25.4 & \\ \hline (B) & \multicolumn{1}{c}{} & & \multicolumn{1}{c}{} & & 16 & & & & & 5.16 & 25.1 & 58 \\ & & & & & 32 & & & & & 5.01 & 25.4 & 60 \\ \hline \multirow{4}{*}{(C)} & 2 & \multicolumn{1}{c}{} & & & & & & & & 6.11 & 23.7 & 36 \\ & 4 & & & & & & & & 5.19 & 25.3 & 50 \\ & 8 & & & & & & & & 4.88 & 25.5 & 80 \\ & & 256 & & 32 & 32 & & & & 5.75 & 24.5 & 28 \\ & 1024 & & 128 & 128 & & & & 4.66 & 26.0 & 168 \\ & & 1024 & & & & & & 5.12 & 25.4 & 53 \\ & & 4096 & & & & & & 4.75 & 26.2 & 90 \\ \hline \multirow{4}{*}{(D)} & \multicolumn{1}{c}{} & & & & & 0.0 & & 5.77 & 24.6 & \\ & & & & & & 0.2 & & 4.95 & 25.5 & \\ & & & & & & & 0.0 & 4.67 & 25.3 & \\ & & & & & & & 0.2 & 5.47 & 25.7 & \\ \hline (E) & \multicolumn{1}{c}{} & \multicolumn{1}{c}{} & & \multicolumn{1}{c}{} & & & & & 4.92 & 25.7 & \\ \hline big & 6 & 1024 & 4096 & 16 & & 0.3 & 300K & **4.33** & **26.4** & 213 \\ \hline \hline \end{tabular}
\end{table}
Table 3: Variations on the Transformer architecture. Unlisted values are identical to those of the base model. All metrics are on the English-to-German translation development set, newstest2013. Listed perplexities are per-wordpiece, according to our byte-pair encoding, and should not be compared to per-word perplexities.
----------------------------------------------------------------------------------------------------
\begin{table}
\begin{tabular}{c|c|c} \hline
**Parser** & **Training** & **WSJ 23 F1** \\ \hline Vinyals \& Kaiser et al. (2014) [37] & WSJ only, discriminative & 88.3 \\ Petrov et al. (2006) [29] & WSJ only, discriminative & 90.4 \\ Zhu et al. (2013) [40] & WSJ only, discriminative & 90.4 \\ Dyer et al. (2016) [8] & WSJ only, discriminative & 91.7 \\ \hline Transformer (4 layers) & WSJ only, discriminative & 91.3 \\ \hline Zhu et al. (2013) [40] & semi-supervised & 91.3 \\ Huang \& Harper (2009) [14] & semi-supervised & 91.3 \\ McClosky et al. (2006) [26] & semi-supervised & 92.1 \\ Vinyals \& Kaiser el al. (2014) [37] & semi-supervised & 92.1 \\ \hline Transformer (4 layers) & semi-supervised & 92.7 \\ \hline Luong et al. (2015) [23] & multi-task & 93.0 \\ Dyer et al. (2016) [8] & generative & 93.3 \\ \hline \end{tabular}
\end{table}
Table 4: The Transformer generalizes well to English constituency parsing (Results are on Section 23 of WSJ)* [5] Kyunghyun Cho, Bart van Merrienboer, Caglar Gulcehre, Fethi Bougares, Holger Schwenk, and Yoshua Bengio. Learning phrase representations using rnn encoder-decoder for statistical machine translation. _CoRR_, abs/1406.1078, 2014.
Then use LLM to summarize the table:
# Prompt
prompt_text = """You are an assistant tasked with summarizing tables and text. \
Give a concise summary of the table or text. The table is formatted in LaTeX, and its caption is in plain text format: {element} """
prompt = ChatPromptTemplate.from_template(prompt_text)
# Summary chain
model = ChatOpenAI(temperature = 0, model = "gpt-3.5-turbo")
summarize_chain = {"element": lambda x: x} | prompt | model | StrOutputParser()
# Get table summaries
table_summaries = summarize_chain.batch(tables, {"max_concurrency": 5})
print(table_summaries)
The following are summaries of the four tables found in Attention Is All You Need, as shown in Figure 11:
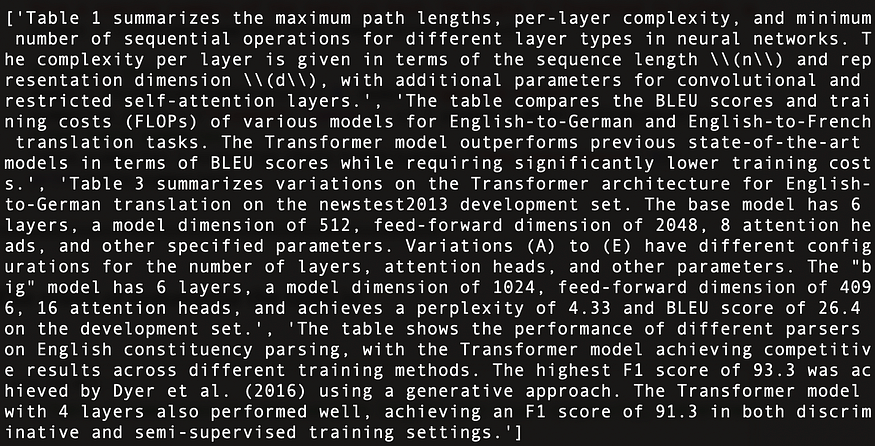
Figure 11: Table summaries of the four tables found in Attention Is All You Need.
Construct a document summary index structure using Multi-Vector Retriever.
# The vectorstore to use to index the child chunks
vectorstore = Chroma(collection_name = "summaries", embedding_function = OpenAIEmbeddings())
# The storage layer for the parent documents
store = InMemoryStore()
id_key = "doc_id"
# The retriever (empty to start)
retriever = MultiVectorRetriever(
vectorstore = vectorstore,
docstore = store,
id_key = id_key,
search_kwargs={"k": 1} # Solving Number of requested results 4 is greater than number of elements in index..., updating n_results = 1
)
# Add tables
table_ids = [str(uuid.uuid4()) for _ in tables]
summary_tables = [
Document(page_content = s, metadata = {id_key: table_ids[i]})
for i, s in enumerate(table_summaries)
]
retriever.vectorstore.add_documents(summary_tables)
retriever.docstore.mset(list(zip(table_ids, tables)))
Everything is ready, build a simple RAG pipeline, and perform queries:
# Prompt template
template = """Answer the question based only on the following context, which can include text and tables, there is a table in LaTeX format and a table caption in plain text format:
{context}
Question: {question}
"""
prompt = ChatPromptTemplate.from_template(template)
# LLM
model = ChatOpenAI(temperature = 0, model = "gpt-3.5-turbo")
# Simple RAG pipeline
chain = (
{"context": retriever, "question": RunnablePassthrough()}
| prompt
| model
| StrOutputParser()
)
print(chain.invoke("when layer type is Self-Attention, what is the Complexity per Layer?")) # Query about table 1
print(chain.invoke("Which parser performs worst for BLEU EN-DE")) # Query about table 2
print(chain.invoke("Which parser performs best for WSJ 23 F1")) # Query about table 4
The execution results are as follows, demonstrating that several questions have been answered accurately, as shown in Figure 12:

Figure 12: The results of the three queries. The first line corresponds to query table 1 in Attention Is All You Need, the second line pertains to table 2, and the third line refers to table 4.
The overall code is as follows:
import os
os.environ["OPENAI_API_KEY"] = "YOUR_OPEN_AI_KEY"
import subprocess
import uuid
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import ChatPromptTemplate
from langchain_openai import ChatOpenAI
from langchain.retrievers.multi_vector import MultiVectorRetriever
from langchain.storage import InMemoryStore
from langchain_community.vectorstores import Chroma
from langchain_core.documents import Document
from langchain_openai import OpenAIEmbeddings
from langchain_core.runnables import RunnablePassthrough
def june_run_nougat(file_path, output_dir):
# Run Nougat and store results as Mathpix Markdown
cmd = ["nougat", file_path, "-o", output_dir, "-m", "0.1.0-base", "--no-skipping"]
res = subprocess.run(cmd)
if res.returncode != 0:
print("Error when running nougat.")
return res.returncode
else:
print("Operation Completed!")
return 0
def june_get_tables_from_mmd(mmd_path):
f = open(mmd_path)
lines = f.readlines()
res = []
tmp = []
flag = ""
for line in lines:
if line == "\\begin{table}\n":
flag = "BEGINTABLE"
elif line == "\\end{table}\n":
flag = "ENDTABLE"
if flag == "BEGINTABLE":
tmp.append(line)
elif flag == "ENDTABLE":
tmp.append(line)
flag = "CAPTION"
elif flag == "CAPTION":
tmp.append(line)
flag = "MARKDOWN"
print('-' * 100)
print(''.join(tmp))
res.append(''.join(tmp))
tmp = []
return res
file_path = "YOUR_PDF_PATH"
output_dir = "YOUR_OUTPUT_DIR_PATH"
if june_run_nougat(file_path, output_dir) == 1:
import sys
sys.exit(1)
mmd_path = output_dir + '/' + os.path.splitext(file_path)[0].split('/')[-1] + ".mmd"
tables = june_get_tables_from_mmd(mmd_path)
# Prompt
prompt_text = """You are an assistant tasked with summarizing tables and text. \
Give a concise summary of the table or text. The table is formatted in LaTeX, and its caption is in plain text format: {element} """
prompt = ChatPromptTemplate.from_template(prompt_text)
# Summary chain
model = ChatOpenAI(temperature = 0, model = "gpt-3.5-turbo")
summarize_chain = {"element": lambda x: x} | prompt | model | StrOutputParser()
# Get table summaries
table_summaries = summarize_chain.batch(tables, {"max_concurrency": 5})
print(table_summaries)
# The vectorstore to use to index the child chunks
vectorstore = Chroma(collection_name = "summaries", embedding_function = OpenAIEmbeddings())
# The storage layer for the parent documents
store = InMemoryStore()
id_key = "doc_id"
# The retriever (empty to start)
retriever = MultiVectorRetriever(
vectorstore = vectorstore,
docstore = store,
id_key = id_key,
search_kwargs={"k": 1} # Solving Number of requested results 4 is greater than number of elements in index..., updating n_results = 1
)
# Add tables
table_ids = [str(uuid.uuid4()) for _ in tables]
summary_tables = [
Document(page_content = s, metadata = {id_key: table_ids[i]})
for i, s in enumerate(table_summaries)
]
retriever.vectorstore.add_documents(summary_tables)
retriever.docstore.mset(list(zip(table_ids, tables)))
# Prompt template
template = """Answer the question based only on the following context, which can include text and tables, there is a table in LaTeX format and a table caption in plain text format:
{context}
Question: {question}
"""
prompt = ChatPromptTemplate.from_template(template)
# LLM
model = ChatOpenAI(temperature = 0, model = "gpt-3.5-turbo")
# Simple RAG pipeline
chain = (
{"context": retriever, "question": RunnablePassthrough()}
| prompt
| model
| StrOutputParser()
)
print(chain.invoke("when layer type is Self-Attention, what is the Complexity per Layer?")) # Query about table 1
print(chain.invoke("Which parser performs worst for BLEU EN-DE")) # Query about table 2
print(chain.invoke("Which parser performs best for WSJ 23 F1")) # Query about table 4
Conclusion
This article discusses key technologies and existing solutions for table processing in the RAG process, and proposes a solution with its implementation.
We use nougat to parse tables in this article. However, if a faster and more effective parsing tool is available, we would consider replacing nougat. Our attitude to tools is to have the right idea first, and then find tools to implement it, rather than depending on a certain tool.
In this article, we input all table content into the LLM. However, in real scenarios, we should account for situations where the table exceeds the LLM context length. We could potentially resolve this by using an effective chunking method.
If you’re interested in RAG technologies, feel free to check out my other articles.
And the latest AI-related content can be found in my newsletter.
Finally, if there are any mistakes or omissions in this article, or if you have any questions, feel free to point them out in the comment section.
Comments
Loading comments…