Do you want to delete or clean up a versioning-enabled -S3-bucket? Though it looks empty, S3 is not allowing you to do so, and you start to realize that there is no easy way to do it. Then continue to read further.
Table of contents
-
Context: problem statement
-
Presentation and discussion of the available options:
-
2.1. Option 1: utilizing the “empty” bucket option
-
2.2. Option 2: employing S3 LifeCycle(LC) Polices
-
2.3. Option 3: programmatic leveraging multithreading, concurrency, and parallelism
-
-
Test results, discussions, and fine-tuning of Option 3
-
Conclusion
-
Souce code
-
References
1. Context
You are stuck in a situation where you have to delete an AWS S3 bucket with objects in the order of 30/50/100 million or more, and the bucket has versioning enabled.

How does S3 bucket versioning affect?
For the versioning enabled S3 bucket, when you delete an object, it’s a soft delete but not a hard delete[source]. S3 will add a delete marker file(0KB), but the actual object (and its old versions, if any) will stay under the hood. You can’t see them with the default view. To see the hidden objects, toggle the button ‘Show versions’ as in the picture below.
Toggle button to show the non-current versions:
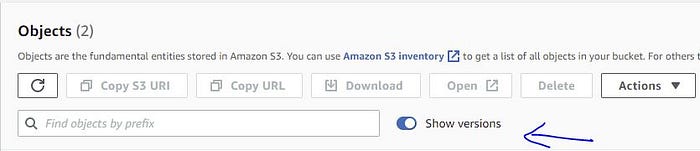
Does the object’s deletion cost you in S3?
No, and Yes.
Calling a deletion API will not cost you, but one must get the objects first to delete them. The price for the GET requests would add the cost to the solution.
Fetching 1000 objects would cost you around 0.005$ (may vary a bit depending on the region)
Example: GET of one million objects will cost you 5$ (1000 times * 0.005$)
2. Available solutions
Here are some of the solutions available depending on the size of the data and the time window you want to clean up the bucket.
2.1 Option 1: utilizing the "empty" bucket option
On the landing page of S3, you can select the bucket and use the “Empty” button as highlighted in the below picture.
How to empty the S3 bucket with the “Empty” button:
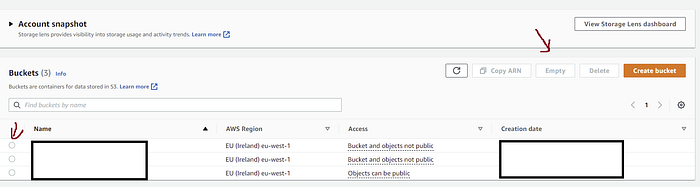
This method will eventually do the job but will happen in the steps(batches) of 1000 objects at a time.
Cost: 0.005$/1000 object fetched.
Optimal assumptions:
- If S3 takes 0.5 sec (n/w round trip)to fetch 1000 objects and 0.5 sec (n/w round trip)to delete them, then it would be 1 sec to delete the 1000 objects. In this case, it would take 16.7 min to empty 1 Million objects.
- If it takes 2 sec to delete 1000 objects, then we are talking about 30 min/Million. You can do the math for your use case.
Also, if there are any configured session timeouts, it can be further complicated.
Note: If you close the browser or session timeouts, the deletion process will stop.
2.2 Option 2: using S3 LifeCycle(LC) policies
This option is the most recommendable if it serves your use case. Here, one can configure the LC rules on the S3 bucket and outsource the deletion job to S3.
There is a lot of good documentation and tutorials on this topic already.
Advantages:
- It’s easy to configure, clean and straightforward.
- It can also delete millions and billions for free without any further effort.
Limitation:
- This deletion is an asynchronous process; all the eligible objects would be deleted in the background every night, but there is no SLA you can rely on. For example, 20 Million objects may take 2 or 3 or 4 days, but we cannot say the exact completion time. But S3 will not charge for storing expired objects (still, it doesn’t help in this use case). Also, this behavior depends on factors like — the AWS region where the data is located and the load on the region at that particular time on S3. There is no way to accelerate this process(as of Feb-2022).
Here is a post that would give you insights into LCs with actual values.
Note: It’s also important to configure the LC to remove the delete-markers on versioning-enabled buckets. Else, delete-markers will stay back → bucket cannot be deleted.
2.3 Option 3: leveraging multithreading, concurrency, and parallelism
In this option, we try to reach the maximum limits offered by the S3 to delete objects at full throttle.
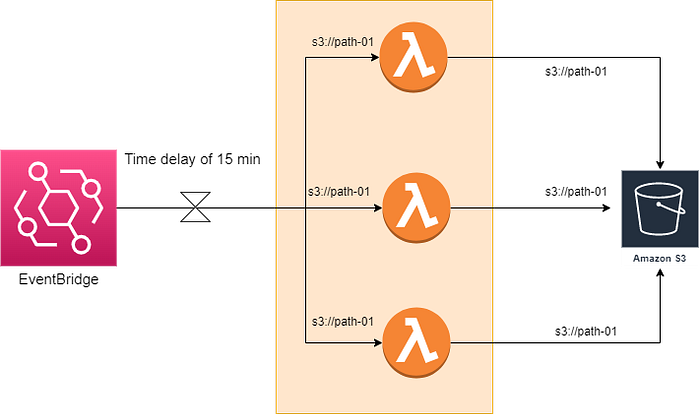
The architecture of option 3
First, let’s understand the S3 limits offered in this context are:
S3 allows up to 3500 write requests on each prefix in the S3 buckets with DELETE API
You can send 3,500 PUT/COPY/POST/DELETE or 5,500 GET/HEAD requests per second per prefix in an Amazon S3 bucket. There are no limits to the number of prefixes that you can have in your bucket (source).
- DeleteObjects API supports a maximum of 1000 keys at a time — this would count as one write request
- With S3 API supports a maximum of 1000 keys in GET API with pagination — this would count as one read request
With these values, it’s clear that the best case would be trying to achieve 3500 DELETE requests per prefix.
One way of achieving this would be using Lambda for the computing and EventBridge(EB) rules for the scheduling.
The complete solution looks as below:
-
Create a Lambda service role that has read and delete permission on the respective S3 bucket.
-
Write a Lambda function(GitHub link) with the following features:
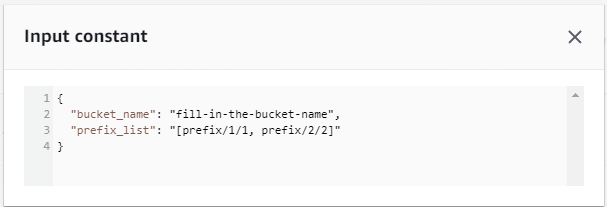
- It takes bucket_name and prefixes_list as input
- Each prefix will create a sub-process
- Using the boto3 S3 client and using pagination, get 1000 object versions in a single GET request
- Using batch delete API, delete 1000 at a time
- and repeat it till the objects in the prefix are empty
- Create and schedule the EB rule to call the above Lambda three times in the same rule with input as bucket_name and prefixes_list for every 15/16 minutes.
EventBridge to trigger Lambda with the time interval of 16 min:
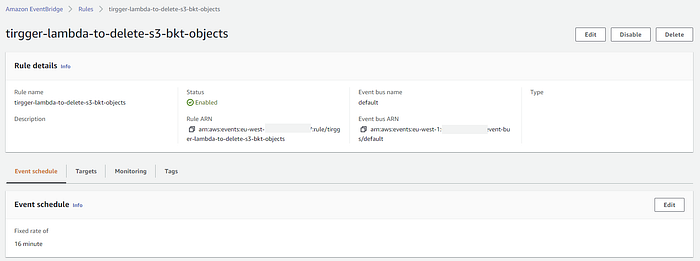
EventBridge to trigger the same Lambda three times:
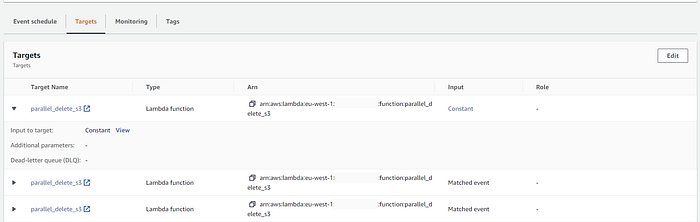
Input JSON to trigger Lambda:
3. Discussion on the solution configurations:
Why create a sub-process for each prefix?
This is to take advantage of the vCPUs offered by Lambda. Thereby deletion would happen in parallel rather than in a serial way.
Why fetch only 1000 object-version?
A GET request supports a max of 1000 at a time, while pagination and batch delete only support up to 1000 at a time. Here, we are deleting 1000 objects (considering each version as an object) in a prefix at a time.
Why call Lambda three times with a single with an EB rule?
Since S3 supports up to 3500 deletes on a prefix, if we invoke the same Lambda three times with an EB rule, we are taking advantage of Lambda concurrency and achieving the rate of 3000 deletes. Currently, the EB rule supports up to five target invocations, but we go with three to stay within the throttling limits of S3.
Why schedule for every 15/16 minutes in EB rule?
This would automate the repeated invocations for every 15/16 min.
As Lambda’s maximum execution time is 15min, it would automatically stop execution after 15min**.** Therefore an option is to automate the triggering of the Lambda in a loop until all the objects are entirely deleted. Scheduling every 16min is to ensure that there would not be more than three concurrent invocations at any given time in order not to overwhelm S3(to avoid throttling exceptions).
How much should the timeout value be for the Lambda function?
Set it to the maximum allowed value, i.e., 15 min.
How many vCPUs should be configured for Lambda?
The only way to increase/decrease the CPUs is to increase/decrease the memory setting. One can set memory between 128–10240 MB, and Lambda will allocate a vCPUs proposal to the set memory.
Set the memory to the maximum allowed value, i.e., 10240 MB thereby, the allocated vCPUs would be six[Ref].
How many S3 prefixes be used to invoke S3 Lambda from EB?
Since Lambda only supports a maximum of six vCPUs, it would be ideal to utilize six prefixes.
The idea is to create six threads in the Lambda for the six input prefixes.
Testing the solution
Test 01: Using six cores of Lambda and with six prefixes in the test S3 bucket
Objects in the bucket are varied from 0.1Million to 0.4Million, with six prefixes in the bucket, six Lambda vCPU cores, concurrently as six.
It is noticed that S3 throttling errors are observed during tests. Though S3 says it supports 3,500 PUT/COPY/POST/DELETE or 5,500 GET/HEAD requests per second per prefix in an Amazon S3 bucket, throttling errors are observed.
S3 throttling errors:

The errors would slow down the process. To avoid this, sleep time was set between each delete operation.
Test 01 results:

With the fine-tuning of the sleep time, a deletion rate of 0.49ms/Object was achieved. With this, we can calculate the total deletion time for the bigger bucket sizes with the above-obtained values.
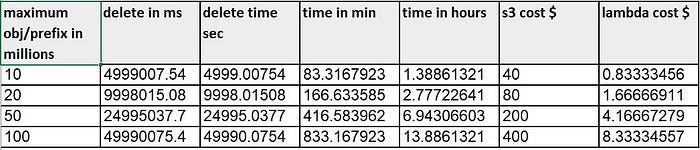
Time and money for various S3 bucket sizes
Test results:
For 10 million/prefix with the programmatic solution would take about 1.3Hours and cost around 41$
Test 02: Effectiveness of the concurrency
Tests are conducted to evaluate the effectiveness of concurrency with objects/prefix and Lambda cores(vCPUs) as constant and varying concurrency in the Lambda.
Objects/prefix as 12000
VCPUs of Lambda as 6
Time and concurrency:
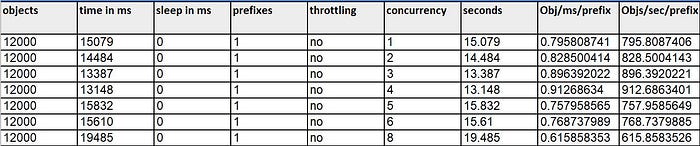
Graph with concurrency(x-axis) vs time in seconds(y-axis):
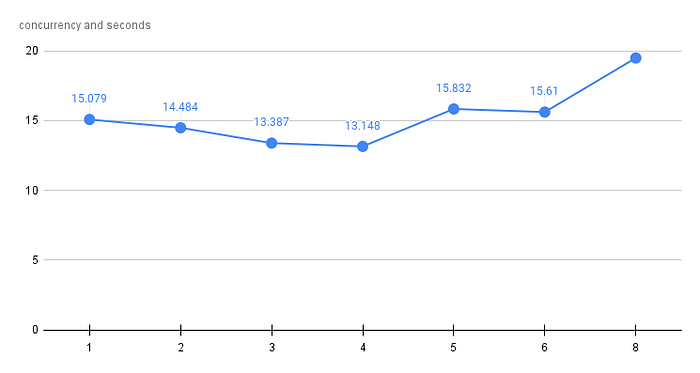
Test observations:
Here we can observe that deletion time decreased as we increased the concurrency up to value four. Theoretically, it should decrease till value six, but after value four, there could have been empty deletes that might have been sent. After value six, the value jumped because Lambda supports a max of six cores hence there were more threads than available cores, so there would be a waiting time for the thread executions. This explains the sharp jump.
4. Conclusion
This article discusses three options to delete the versioning-enabled S3 bucket objects. Option 1 is for a simple bucket, which has objects in the order of a few thousand. Option 2 is free of cost, efficient, and simple when deletion time is not restrictive. Option 3 is the custom programmatic way of doing things with the AWS services: Lambda and EventBridge. It will incur costs proportional to the number of objects to be deleted in the S3 bucket. And there we have it. I hope you have found this useful. Thank you for reading.
5. Source Code
The source code used in the option 3 experiments is uploaded to GitHub.
https://github.com/Kirity/lambda-parallel-deletion-of-S3-buecket
6. References
https://docs.aws.amazon.com/AmazonS3/latest/userguide/DeletingObjectVersions.html [About deleting object versions from a versioning-enabled bucket]
https://aws.amazon.com/s3/pricing/ [AWS S3 pricing tables]
https://docs.aws.amazon.com/AmazonS3/latest/userguide/object-lifecycle-mgmt.html[Managing S3 object lifecycle policies]
https://cloud.netapp.com/blog/aws-cvo-blg-s3-lifecycle-rules-using-bucket-lifecycle-configurations [Tutorial regarding the configuration of S3 life cycle policies]
https://aws.plainenglish.io/how-to-easily-delete-an-s3-bucket-with-millions-of-files-in-it-ad5cec3529b9 [A post with a real-world scenario to delete huge data with s3 life cycle policies]
https://docs.aws.amazon.com/AmazonS3/latest/userguide/optimizing-performance.html [AWS docs about the limits of s3 delete]
https://aws.amazon.com/premiumsupport/knowledge-center/s3-request-limit-avoid-throttling/ [How to increase the s3 throttling limits]
Comments
Loading comments…