Lambda functions are a very handy tool to build serverless infinitely scalable architecture. They are not without limitations though. A maximum run time is 15 minutes and previously they could rely only on a limited number of dependencies as all of them must fit into 50 Mb zipped folder. This is good, but often not enough especially if you need some OS-wide dependencies. On Re:Invent 2020 Amazon announced that now any compliant OS image can be used as a lambda function. This gives an enormous boost to the applications that lambdas can now fill. In this little project I will create a lambda function from a custom Docker image, that would have been impossible before, as it relies on massive external code too big to be zipped for a lambda layer. My purpose is to build a file conversion service that will be triggered by files uploaded to S3 and convert them from an ugly file format, that no one likes, into a beautiful file format that everyone can enjoy.

Let’s start from motivation. I like electronic books, they have zero weight, I can take hundreds with me and carry them anywhere. For some irrational reason (or because of lack of good readers) I sincerely despise epub format. Unfortunately, some books I can find only in epub. For example my go-to hiking guidebooks from Rother (why, Rother , why?). Normally I buy them and convert using online converters to pdf. My tool of choice being zamzar.com . With that said, one day I thought, that it might be a cool idea to have my own converter. Maybe also for other file formats, my own zamzar. Given sporadic use pattern — of course it should be lambda-based. To trigger our lambda we will use create-events coming from an S3 bucket, where we will upload epub files. Converted files will be uploaded to another bucket. Here is our simple architecture:
Architecture of a simple serverless file conversion service based on S3 and lambda function. Image by the author:
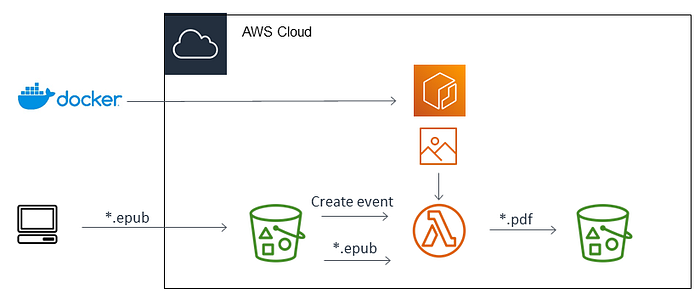
Let’s start with our conversion function. Epub is a zipped folder of xhtml files and images (try to unzip an epub file and see what is inside). For conversion between various markdown formats such as xhtml there is a very powerful utility called pandoc . Pandoc can be packed into a Lambda layer and there are even such layers, which influenced my design greatly . There is a catch though. Pandoc cannot convert files to pdf. For pdf conversion it relies on a system installation of pdflatex or an alternative Latex-powered pdf engine. And together with pandoc it will not fit in a lambda layer. So this makes a good case to try practical use of docker image based lambda function. All we will need is some base image, pandoc, some Latex installation and AWS lambda runtime to provide interaction with requests. Sounds relatively simple. If you read this article some time after middle of 2022 — TL;DR for you : use images based on Amazon linux 2022, where both pandoc and texlive are available as announced by AWS.
As this version was not yet made widely available, my path was a bit trickier. We start with the base image of lambci/lambda-base-2. I strongly recommend it as it is closest to the version of Amazon Linux used in lambdas in terms of permissions. My attempts with Ubuntu were plagued with permission errors. In the created Ubuntu-based image during local testing everything worked, but loaded to lambda it was crashing, because during pdf generation latex was trying to write some temporary files outside of the only write-permitted folder /tmp. It is just not worth it. So a proper base image is highly recommended. To have pandoc on it, we need to compile it from the source code. A good guidance can be found for example in that article. Too bad, to compile pandoc from its haskell source code we first need to compile the haskell compiler (GHC) itself. We first install a GHC version, available from package manager, but it will be too outdated, so we will have to install a newer version from the source code (for which the old version will be a dependency). It all works only in a proper combination of GHC, haskell package manager (cabal) and pandoc versions, here is what worked for me : GHC- 8.4.4, cabal 2.2.0.0, pandoc — 2.7.2
Building that part of Docker image takes 10–20 minutes due to compilation. Do not forget to increase memory allocation for the docker desktop where you build the image as well as for the future lambda function. I set it to 3008 Mb. Once we have a binary of pandoc compiled we will copy it in a specific folder of a fresh base-image. Doing such multistage build allows us to make the final image more compact as it will not have traces of installing haskell compiler and other stuff (final image is about 5 Gb vs 9 Gb). Once we are done with pandoc installations we need to take care of the lambda function itself and runtime interface client (RIC). I will create my function in Python and use awslambdaric package to take care of RIC. We will also need some Python dependencies such as boto3 to work with S3. We will also install lambda runtime interface emulator to allow local testing of image when it is not run on AWS but on our local machine. All the dependencies are installed locally to the task folder and will be copied from the first stage image to our final image.
RUN cd /var/task &&\
mkdir build &&\
cd build &&\
curl -LO https://dl.fedoraproject.org/pub/epel/epel-release-latest-7.noarch.rpm &&\
rpm -i epel-release-${EPEL_VERSION}.noarch.rpm &&\
yum install ghc -y &&\
curl -LO https://downloads.haskell.org/~ghc/${GHC_VERSION}/ghc-${GHC_VERSION}-x86_64-centos70-linux.tar.xz &&\
tar xf ghc-${GHC_VERSION}-x86_64-centos70-linux.tar.xz && \
rm ghc-${GHC_VERSION}-x86_64-centos70-linux.tar.xz && \
cd ghc* &&\
./configure --prefix=/usr/local &&\
make install && \
cd .. &&\
curl -LO https://downloads.haskell.org/cabal/cabal-install-2.2.0.0/cabal-install-2.2.0.0-x86_64-unknown-linux.tar.gz &&\
tar xf cabal-install-2.2.0.0-x86_64-unknown-linux.tar.gz &&\
mv cabal /usr/local/bin &&\
cabal update &&\
cabal sandbox init --sandbox . &&\
cabal install --disable-documentation --force-reinstalls pandoc-2.7.2 -fembed_data_files &&\
mkdir -p ${TARGET_DIR}bin &&\
cp bin/pandoc ${TARGET_DIR}bin && \
pip3 install requests --target ${FUNCTION_DIR} &&\
pip3 install boto3 --target ${FUNCTION_DIR} &&\
pip3 install --target ${FUNCTION_DIR} awslambdaric &&\
mkdir -p ${FUNCTION_DIR}/.aws-lambda-rie &&\
curl -Lo ${FUNCTION_DIR}/.aws-lambda-rie/aws-lambda-rie https://github.com/aws/aws-lambda-runtime-interface-emulator/releases/latest/download/aws-lambda-rie &&\
chmod +x ${FUNCTION_DIR}/.aws-lambda-rie/aws-lambda-rie
With the freshly fetched base image for Latex installation I do the following. I installed the base configuration of texlive and some packages. I found these packages to be the absolute minimum to deal with epub books I had on hand. One thing I forgot to mention is that Rother publishes German-language guidebooks. For those who don’t know, German is one of those beautiful European languages where a word could look kinda like this:
An example of an extended-Latin word, iykwim. Now reader can estimate my age within ±3 years:

In other words, we need to make sure that unicode is well supported. The best way of doing that is to use a more modern pdf engine ( i.e. we need LuaLatex and its dependencies).
FROM lambci/lambda-base-2:build as latex-image
ARG FUNCTION_DIR
ARG TARGET_DIR
# The TeXLive installer needs md5 and wget.
RUN yum -y update && \
yum -y install perl-Digest-MD5 && \
yum -y install wget
RUN mkdir /var/src
WORKDIR /var/src
# Copy in the build image dependencies
COPY --from=pandoc-image ${FUNCTION_DIR} ${FUNCTION_DIR}
COPY --from=pandoc-image ${TARGET_DIR} ${TARGET_DIR}
COPY app/* ${FUNCTION_DIR}
# Download TeXLive installer.
ADD http://mirror.ctan.org/systems/texlive/tlnet/install-tl-unx.tar.gz /var/src/
# Minimal TeXLive configuration profile.
COPY texlive.profile /var/src/
# Intstall base TeXLive system.
RUN tar xf install*.tar.gz
RUN cd install-tl-* && \
./install-tl --profile /var/src/texlive.profile --location http://ctan.mirror.norbert-ruehl.de/systems/texlive/tlnet
ENV PATH=/var/task/texlive/2021/bin/x86_64-linux/:$PATH
# Install extra packages.
RUN tlmgr install scheme-basic &&\
tlmgr install xcolor\
booktabs\
etoolbox \
footnotehyper\
lualatex-math\
unicode-math\
latexmk
RUN mkdir -p /var/task/texlive/2021/tlpkg/TeXLive/Digest/ && \
mkdir -p /var/task/texlive/2021/tlpkg/TeXLive/auto/Digest/MD5/ && \
cp /usr/lib64/perl5/vendor_perl/Digest/MD5.pm \
/var/task/texlive/2021/tlpkg/TeXLive/Digest/ && \
cp /usr/lib64/perl5/vendor_perl/auto/Digest/MD5/MD5.so \
/var/task/texlive/2021/tlpkg/TeXLive/auto/Digest/MD5 &&\
cp ${FUNCTION_DIR}/.aws-lambda-rie/aws-lambda-rie /usr/local/bin/aws-lambda-rie
ENV PATH=/var/task/texlive/2021/bin/x86_64-linux/:$PATH
ENV PERL5LIB=/var/task/texlive/2021/tlpkg/TeXLive/
WORKDIR /var/task
ENTRYPOINT [ "/var/task/ric.sh" ]
CMD [ "handler.lambda_handler" ]
As for the lambda function itself I do the following. The lambda will receive an event from S3 bucket when a new file is created. It will get the location and file name from the event. The file will be downloaded ( you only have write permission in /tmp folder) pandoc will execute conversion and lambda will upload the file to another bucket and clean up temporary files. Using two buckets is essential otherwise your lambda will put itself into an infinite loop with never ending create-events.
A practical note. I found that many epub files will have problems if directly converted to pdf (missing spacing values and other minor things causing latex to crash). Those very same files had no problems if they were first converted to another markdown format, say docx, and then from docx to pdf ( there is a reason I hate epub!). So eventually I decided to do intermediate conversion for all files. So here is my lambda event handler function.
try:
import json
import sys
import requests
import boto3
import os
import uuid
from urllib.parse import unquote_plus
from shutil import copy
print("All imports ok ...")
except Exception as e:
print("Error Imports : {} ".format(e))
s3_client = boto3.client('s3')
def lambda_handler(event, context):
for record in event['Records']:
bucket = record['s3']['bucket']['name']
# local test with lambda runtime with dummy test evet without S3 interaction
if bucket =='test':
copy('./testbook.epub', '/tmp/testbook.epub')
os.system('pandoc /tmp/testbook.epub -o /tmp/testbook.pdf --pdf-engine=lualatex')
valid_path_test = os.path.exists('/tmp/testbook.pdf')
if valid_path_test:
print ('test conversion succeded!')
os.remove('/tmp/testbook.epub')
os.remove('/tmp/testbook.pdf')
else:
print('test conversion failed!')
os.remove('/tmp/testbook.epub')
# actual conversion with S3 interaction
else:
key = unquote_plus(record['s3']['object']['key'])
tmpkey = key.replace('/', '')
download_path = '/tmp/{}{}'.format(uuid.uuid4(), tmpkey)
print(download_path)
conversion_path = '/tmp/converted-{}'.format(tmpkey) + '.docx'
upload_path = '/tmp/converted-{}'.format(tmpkey) + '.pdf'
s3_client.download_file(bucket, key, download_path)
print('download succeded!')
os.system('pandoc ' + download_path + ' -o ' + conversion_path)
os.system('pandoc '+conversion_path+' -o '+upload_path+' --pdf-engine=lualatex')
valid_path_test = os.path.exists(upload_path)
if valid_path_test:
print('conversion succeeded')
try:
s3_client.upload_file(upload_path, '{}-converted'.format(bucket), key + '.pdf')
except Exception as e:
print("Error uploading : {} ".format(e))
os.remove(download_path)
os.remove(upload_path)
os.remove(conversion_path)
else:
print('conversion failed')
os.remove(download_path)
With all of that done, all we need is to have a folder with the docker file, the handler function, a shell script to emulate lambda runtime for local testing (checks if lambda runtime if present if not uses emulator), a couple of test epub files and we are all set. I took test epubs from Gutenberg project. where some classic books can be found. The shell script to emulate runtime in case of local testing is quite simple.
#!/bin/sh
if [ -z "${AWS_LAMBDA_RUNTIME_API}" ]; then
exec /usr/local/bin/aws-lambda-rie /usr/bin/python3.7 -m awslambdaric $@
else
exec /usr/bin/python3.7 -m awslambdaric $@
fi
Now we need to build the docker image with:
_$ docker build -t pandoc-lambda ._
Maybe login to test, if we want to $ docker run -it -- entrypoint sh pandoc-lambda
Maybe test with a test message, run Docker with exposing ports:
$ docker run -p 9000:8080 pandoc-lambda
Then send a test event (I use curl from my WSL Ubuntu on my local machine).
curl -XPOST "http://localhost:9000/2015-03-31/functions/function/invocations" -d '{ "Records": [ { "s3": { "bucket": { "name": "test" }, "object": { "key": "testbook.epub" } } } ] }'
Once we are sure that the tests work locally we need to allow docker access to our Elastic Container Registry through AWS CLI
$ aws ecr get-login-password | docker login --username AWS --password-stdin 12-digit-id.ecr.your-aws-region.amazonaws.com
Then we label our image as latest:
$ docker tag your-image-name:latest 12-digit-id.dkr.ecr.your-aws-region.amazonaws.com/your-image-name:latest
And push it to AWS Elastic Container Registry
$ docker push 12-digit-id.dkr.ecr.your-aws-region.amazonaws/your-image-name:latest
Then we create a new lambda function. In its settings we give it maximum memory allocation of 3008 Mb (or it may suffer on larger files, cause out of memory crashes etc) and also maximum timeout time of 15 minutes (default value of several seconds will be way too short). In S3 bucket we configure create event and make our lambda its target. We choose our lambda to be an image function and create a role for it, that allows accessing our source and results S3 buckets. We will need to attach the following policy to our basic lambda execution role (assuming our source bucket is called source-bucket-name and results bucket is source-bucket-name-converted. Those buckets must exist prior to the function invocation.
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "VisualEditor0",
"Effect": "Allow",
"Action": [
"s3:GetObject",
"logs:CreateLogStream",
"logs:CreateLogGroup",
"logs:PutLogEvents"
],
"Resource": [
"arn:aws:logs:*:*:*",
"arn:aws:s3:::source-bucket-name/*"
]
},
{
"Sid": "VisualEditor1",
"Effect": "Allow",
"Action": "s3:PutObject",
"Resource": "arn:aws:s3:::source-bucket-name-converted/*"
}
]
}
Now if I upload an epub file to my bucket I soon get a converted one in the results bucket. As pandoc is highly capable in converting various file formats, this can be a starting point to create an app that accepts multiple formats and can return converted files in many output forms, depending on the user request. As it will require some front-end development I will not touch it in this article, but feel free to experiment yourself. I leave all materials used in this little project available on Github for anyone who wants to try and expand.
Comments
Loading comments…