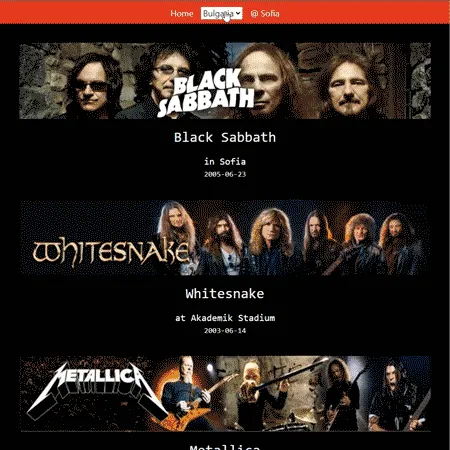
Bringing together two APIs for an app that shows the biggest concerts, historically, by country capital.
With React/Next.js, the fundamental problem you're solving is that of turning some notion of 'state' into DOM, with a focus on composability - using smaller things to build bigger things.
Congratulations, you've found the final boss of web dev: building reusable 'LEGO blocks' of components that can scale infinitely. If you weren't using React/Next.js for this battle from the very start, at some point you will inevitably end up re-implementing a much worse, ad-hoc 'React' of your own out of jQuery anyway - and be responsible for maintaining it.
But building composable UIs is only half the battle. The most scalable UI in the world would be nothing without datato display. Here, then, is the other half: working with APIs, databases, and microservices. If we're to go all-in on scalable, modular web apps, we cannot forget about composability in this problem space as well.
This is where WunderGraph - an open-source API developer platform - can help. Within the React mental model, you're already used to listing all your dependencies in the package.json file, and letting package managers do the rest when you npm install && npm start a project. WunderGraph lets you keep that intuition, and do the exact same thing with your data sources, too:
- Explicitly name the APIs, microservices, and databases you need, in a configuration-as-code format, and then,
- WunderGraph generates client-side code that gives you first-class typesafe access (via Next.js/React hooks) to all these data sources while working on the front-end.
In this tutorial, we'll get a little adventurous and bring together two disparate, very different APIs in a Next.js app, to show that with WunderGraph (and no other dependencies) running alongside your frontend as an independent server/API Gateway/BFF, you could essentially write front-end code against multiple REST, GraphQL, MySQL, Postgres, DBaaS like Fauna, MongoDB, etc, as if they were a singular monolith.
Before we start, though, let's quickly TL;DR a concept:
What Does "Composability" Even Mean for APIs?
Right now, your interactions with sources of data are entirely in code. You write code to make calls to an API endpoint or database (with credentials in your .env file) and then you write more code. This time, async boilerplate/glue to manage the returned data.
What's wrong with this picture?
The code itself is correct, what's "wrong" is that now you're coupling a dependency to your code, and not your config files. Sure, this weather API isn't an axios or react-dom (library/framework packages), but it is a dependency nonetheless and now, a third-party API that is only ever mirroring temporary data, has been committed to your repo, made part of your core business, and you will now support it for its entire lifetime.
Sticking with the Lego analogy: this is like gluing your sets together. Welcome to bloated, barely readable, barely maintainable codebases with hard constraints.
You'll be doing the above times tenon modern medium-to-large apps that are split into many microservices, with complex interactions, and separate teams for each who might step on each others' toes. That's not even counting all the JOINs you'll be doing across these multiple services/APIs to get the data you need.
So what could a scalable approach to API composability look like, without sacrificing developer experience?
- It needs to support various data without needing a separate client for each type, and we'll need to be able to explicitly define these data dependencies outside our app code - maybe in a config file.
- It should let us add more data sources as we need them, remove obsolete/dead sources from the dependency array, and auto-update the client to reflect these changes.
- It should allow us to stitch together data from multiple sources (APIs, databases, Apollo federations, microservices, etc.) so we can avoid having to do in-code JOINs on the frontend at all.
As it turns out, this is exactly what WunderGraph enables, with a combination of API Gateway and BFF architectures.
If you explicitly name your API dependencies in the WunderGraph config like on the right, here:
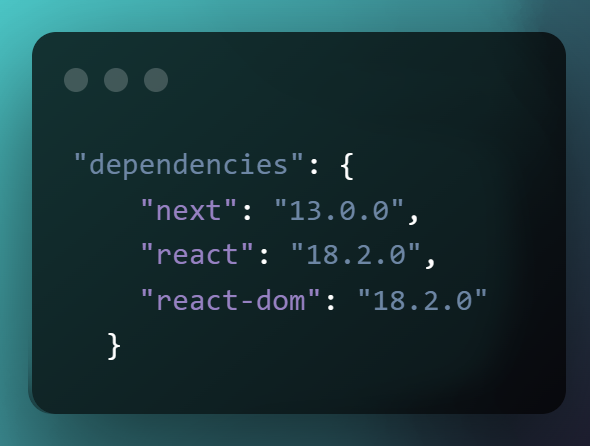
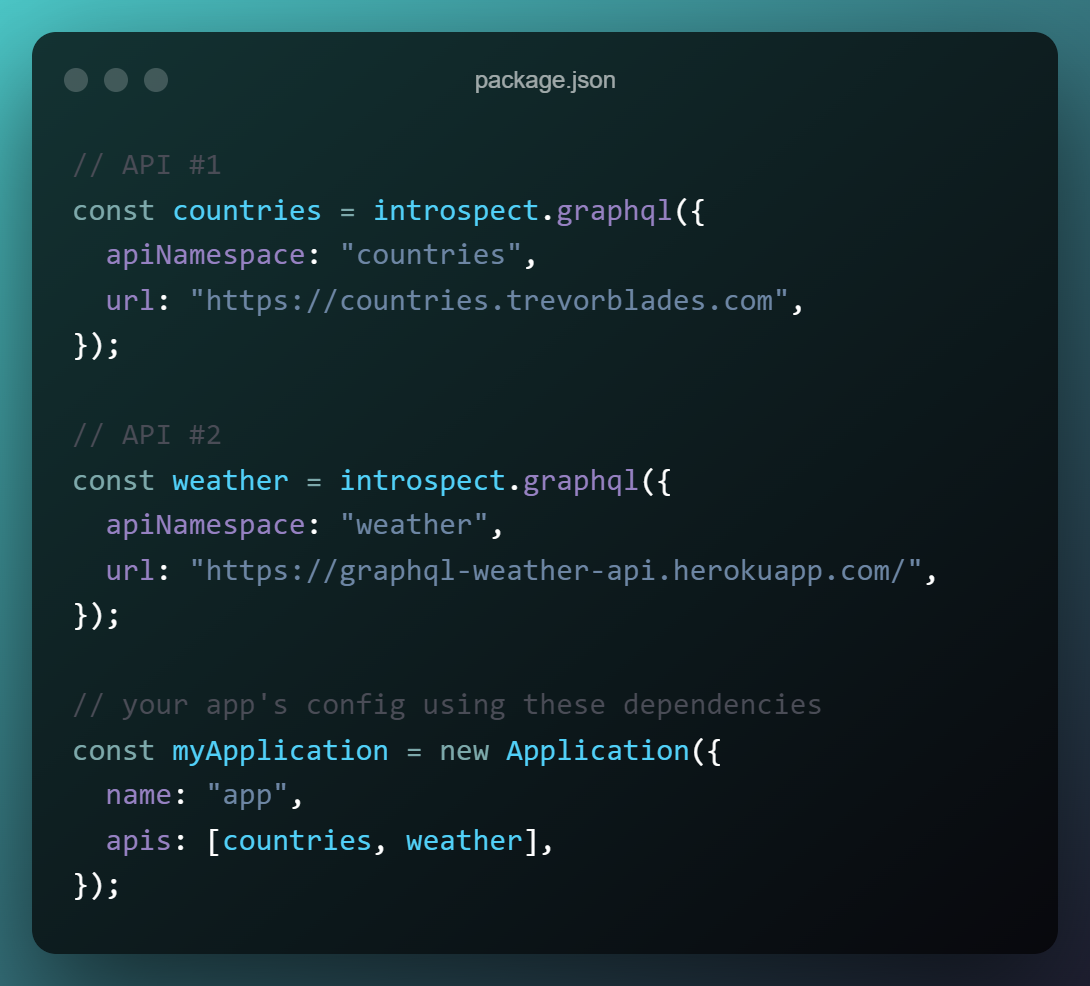
Conceptually, what's the difference? There are none; both are config files with a list of things your app needs. Sure, you're writing a little more code on the right, but that's just stuff React/Next.js does for you under the hood anyway on the left.
WunderGraph introspects and consolidates these data sources (and not merely the endpoints) into a namespaced virtual graph, and builds a schema out of it.
Now, you no longer care about:
- How differently your data dependencies work under the hood.
- Shipping any third-party clients on the frontend to support those different data sources.
- How your teams are supposed to communicate across domains.
Because now you already have all data dependencies as a canonical layer, a single source of truth - GraphQL.
As you might have guessed, next, it's just a matter of writing operations (GraphQL queries/mutations that WunderGraph gives you autocomplete in your IDE) to get the data you want out of this standardized data layer. These are compiled into a native client at build time, persisted, and exposed using JSON-RPC (HTTP).
All the DevEx wins of using GraphQL without actually having a public GraphQL endpoint, so none of its security/caching/bundle size concerns on the client side.
Finally, in your front-end code, you use this generated client's typesafe data-fetching hooks.
Clear, intuitive, and maintainable.
The end result? A Docker or NPM-like containerization/package manager paradigm, but for data sources. With all the benefits that come with it:
- APIs, databases, and microservices turned into modular, composable lego bricks, just like your UI components.
- No more code bloat for JOINs and filters on the frontend, vastly improved code readability, and no more race conditions when trying to do transactional processing over microservices.
- With the final "endpoint" being JSON-RPC over good old-fashioned HTTP, caching, permissions, authentication, and security - all become solved problems regardless of the kind of data source.
But why stick to theory? Let's dive right in!
An Adventure in Treating APIs Like LEGO
The power to compose and bring together data sources like you'd do libraries can lead you to very interesting places, with ideas that no run-of-the-mill public API could ever give you.
Say, for example, what if you wanted to find out what the biggest musical events - concerts, recitals, festivals, etc. - have historically been at a given country's capital?
There's literallyno API like this out there. You could build the first one. The world's your oyster!
Step 1: Deciding on Data
So the two APIs we'll use here are the Countries API and the MusicBrainz aggregator. Feel free to play around with Insomnia/Postman/Playgrounds and get a feel for what data you can reasonably query with these APIs. You'll probably find a ton of additional, creative use cases.
Step 2: Quick-starting a WunderGraph + Next.js App
When you're ready to move on, use the starter template in WunderGraph's repo for a Next.js app that uses the former as a BFF/API Gateway.
npx -y @wundergraph/wunderctl init - template nextjs-starter -o wg-concerts
This will create a new project directory named wg-concerts (or folder name of your choice), spin up both a WunderGraph (at localhost:9991), and a Next.js server(at localhost:3000), by harnessing the npm-run-all package; specifically using the run-p alias to run both in parallel.
Step 3: Concerts by Capital - Cross API Joins without code.
Here's the meat and potatoes of this guide. I've spoken at length about how cross-source data JOINs are a massive pain point when done in-code, and now, you'll see firsthand how WunderGraph simplifies them.
You can stitch together 2 API responses - in our case, getting the capital of a country, then using that informationtoquery for concerts that took place there - like so:
Imagine implementing this query in JavaScript. Truly, spooky season.🎃
- The
@internaldirective for args signifies that while this argument is technically an 'input', it will only be found internally within this query and need not be provided when we call this operation. - The
@exportdirective works hand-in-hand with@internal, and whatever you're exporting (or the alias - that's what the 'as' keyword is for) must have the same name and type as the arg you've marked as internal. _joinsignifies the actual JOIN operation:- As you can tell, the input (query) of this 2nd query uses the same arg we marked as internal at the top level of this GraphQL query.
- While optional, we're using the
@transformdirective (and then the 'get' field that points to the exact data structure we need) to alias the response of the 2nd query into 'concerts' because any additional query we join will of course add another complex, annoyingly nested structure and we want to simplify and make it as readable as possible. - We're also (optionally) including the
relationshipsfield for each concert - to getmbid(the MusicBrainz internal ID of the artist involved in that concert) here because we still want to query the Artist entity individually later (for banners, thumbnails, bios, and such. Again, optional).
Step 4: Getting Artist Details
Speaking of developer experience...here's a little gotcha with the artistId variable being of type MBID! and not String!. Thanks to WunderGraph, you get code hinting for that in your IDE!
Our second and third operations respectively, are to get a 1000x185 pixel banner image of the artist (from theAudioDB) via their MusicBrainz ID, and then thumbnail/biographies. This is just to prettify our UI, and you can skip these queries if you want just the concert details and nothing else (perhaps because your use-case doesn't need a UI at all).
Step 5: Displaying Our Data On The Frontend
We're in the home stretch! Let's not get too wild here, just each concert mapped to <ConcertCard> components, and a <NavBar> with a <Dropdown> to select a country to fetch concerts in its capital. Oh, and TailwindCSS for styling, of course.
All done! Fire up localhost:3000 and you'll see your app.
But before we sign off, here's a very valid - and important - concern.
What if I'm Not Using Next.js/React?
WunderGraph still works as a straightforward API Gateway/BFF without the auto-generation of a frontend client for data fetching.
In this scenario, though, you won't have access to the typesafe React hooks WunderGraph generates for you clientside, so you're going to have to take on more of the concerns - implementing data fetching yourself, watching for type-safety, and making the internal GET/POST calls manually.
Using default WunderGraph configs, each operation (.graphql file) you have, is exposed as JSON-RPC (HTTP) at:
http://localhost:9991/app/main/operations/[operation_name]?[params]
So your data fetching is going to look something like this:
Where Weather.graphql is the filename of your operation.
Achivement Unlocked: Composability for Data
With WunderGraph being part of your tooling to bring together all your APIs, databases, and microservices - whether that's as a BFF, an API Gateway, a View-Aggregator that only ever mirrors read-only data, or whatever - you get all the benefits of UI composability, in the realm of data.
-
Progressive enhancement: revisit code anytime to flesh things out, or add new parts as business needs grow.
-
Flexibility: Swap out parts as needed - so your tech stack doesn't calcify.
-
Improved end-to-end developer experience:
- Single source of truth (GraphQL layer) for all data.
- A perfectly-molded client via code generation means every team knows exactly what they can or cannot do with the data (via autocompletion in your IDE) when writing operations as GraphQL queries or mutations, allowing you to craft the exactexperience you want for your users without trial & error.
- Paired with Next.js, you can have queries ready to go in your
<Suspense>boundaries so you know exactly what is rendered within each, and exactly which queries it runs under the hood. That knowledge leads to better patching and optimization because you'd know exactly where any gotchas or bottlenecks would be.
In terms of modern, serverless web development, WunderGraph can run on anything that can run Docker, so integration into your tech stack is seamless.
That's WunderGraph's powerplay. Composability for *all *dependencies, allowing you to build modular, data-intensive experiences for the modern web without compromising on developer experience.
Comments
Loading comments…