
With a staggering user base of over 930 million, scraping LinkedIn's public data holds immense significance for individuals and businesses alike, offering a wealth of insights that can drive informed decision-making. By analyzing job listings, profiles, and posts, you can gain valuable insights into skills in demand, hiring patterns, industry sentiment, and beyond. Businesses can also use this public data on LinkedIn to find ideal talent, conduct market research, foster strategic partnerships, and more.
Nonetheless, scraping LinkedIn's public data is fraught with challenges. LinkedIn actively employs anti-scraping measures, employing CAPTCHAs, IP blocks, and legal actions to deter automated data collection. Ensuring ethical compliance, data accuracy, and respecting user privacy while getting around website blocks requires careful navigation of technical and ethical intricacies.
To this end, we'll be making use of Puppeteer with the Scraping Browser to scrape public data on LinkedIn. The Scraping Browser is a headful, fully GUI browser that:
- Comes with block-bypassing technology right out of the box.
- Ensures ethical compliance with major data protection laws.
- Can be easily integrated with existing Puppeteer/Playwright/Selenium scripts.
At the end of this article, you will learn how to scrape public data on LinkedIn using Puppeteer in a seamless and uninterrupted manner. We'll also look into some of the challenges surrounding scraping data from LinkedIn, such as the legality of the operation and the technical obstacles.
Let's dive in.
Understanding LinkedIn's Data Policy
As web scraping has become more popular, questions about its legality have also started to arise. It's always worth remembering that web scraping itself is not illegal; in fact, as per the landmark judgment by the US Appeals Court in 2022, as long as the data you're collecting is publicly available, your operations are perfectly legal and do not violate the Computer Fraud and Abuse Act (CFAA).
However, it is important to comply with major data protection and privacy laws as well as the terms of agreement of the target website. For example, your scraping attempt might be illegal if you're scraping data that is private and requires some form of login to access (web scrapers should not log in to websites and download data because by logging in to any website, users often need to agree to terms of service (ToS), which may forbid activity like automatic data collection). You have to make sure you're not breaking any laws when doing that.
So where does LinkedIn stand on this?
Is Scraping LinkedIn Legal?
As mentioned before, scraping public data itself is not illegal. However, in practice, the ethical and legal nature of web scraping can sometimes be a dicey situation with no context-independent easy 'yes' or 'no' answer and LinkedIn is no exception to this.
Over the years, there have been cases where LinkedIn has taken certain companies to court for "allegedly" breaching the terms of its user agreement. Perhaps the most famous (or infamous) of these is the hiQ Labs v. LinkedIn case. In this case, the US 9th Circuit Court initially ruled in favor of hiQ Labs but the decision was ultimately overturned in favor of LinkedIn in November 2022.
This is why, when it comes to scraping LinkedIn, it may be worth going with a managed service that already takes care of these questions of ethical and legal compliance for you. This is also one of the reasons we'll be using the Scraping Browser because it strictly adheres to major data protection laws like Europe's General Data Protection Regulation (GDPR) and the California Consumer Privacy Act (CCPA) regulations.
💡Pro Tip: If data extraction from LinkedIn is crucial and timely to your project's operation and you wish to avoid legal and technical hassles altogether, it may be worth procuring a readymade LinkedIn scraping template or datasets from a well-reputed provider with a dedicated team.
Technical Challenges in Scraping LinkedIn
Let's now look into some of the technical challenges you might encounter when trying to scrape data from LinkedIn:
- Rate limits and IP blocks: LinkedIn limits the number of requests that can be made from a single IP address in a given period of time (around 80 per day). This is to prevent users from overloading the LinkedIn servers. If you exceed the rate limit, your IP address may be blocked.
- CAPTCHAs: LinkedIn also uses CAPTCHA challenges to prevent bots from scraping data from the platform. So, if you are scraping data from LinkedIn without being logged in and you make too many requests, you may be asked to solve a CAPTCHA challenge in order to continue scraping.
The employment of these and other anti-scraping measures makes it difficult or nearly impossible to scrape LinkedIn data at scale. But by making use of the Scraping Browser, we can easily overcome such limitations.
As mentioned before, the Scraping Browser comes built-in with block bypassing technology. This is because the Scraping Browser makes use of Bright Data's powerful unlocker infrastructure and proxy network (which includes four different types of proxy services from over 195 countries).
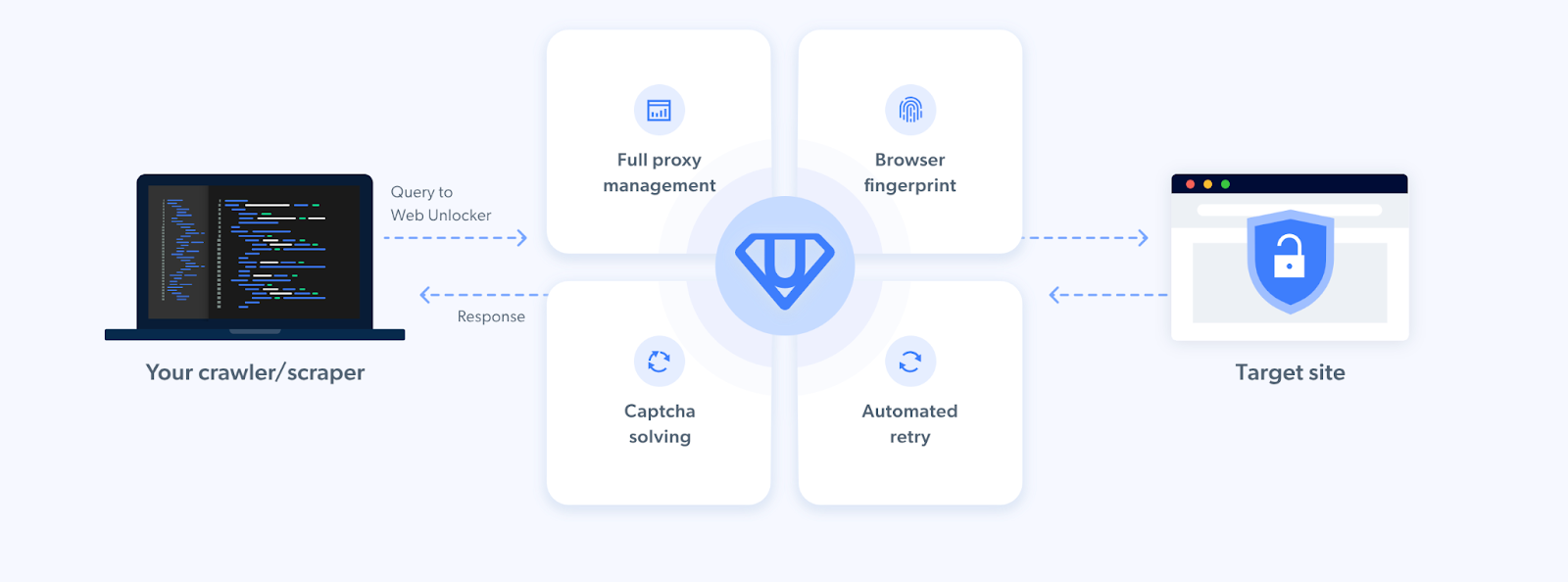
👉 You can read more about Scraping Browser's offerings
From CAPTCHA-solving to User-agent generation to cookie management and fingerprint emulation, the unlocker infrastructure takes care of all this on Bright Data's server-side infrastructure. When coupled with its premium proxy management services, the Scraping Browser ensures uninterrupted and continuous data collection at scale.
You can easily automate IP rotation, bypass CAPTCHAs, rate limits, and geolocation blocks without having to maintain additional infrastructure or rely on third-party libraries.
How to Easily Scrape Relevant Public Data from LinkedIn
As mentioned before, the Scraping Browser is fully compatible with popular browser navigation libraries, such as Puppeteer, Playwright, and Selenium. These navigation libraries are instrumental in streamlining data extraction, enhancing both accessibility and efficiency. Selenium and Playwright are both compatible with Node.js and Python. Both libraries offer a variety of browser support options, including Chrome and Firefox, among others. On the other hand, Puppeteer, our tool of choice for this tutorial, exclusively supports Chrome and Chromium and is a Node.js library.
It is worth noting that the Scraping Browser also leverages the Chrome DevTools Protocol, so either of the browser navigation libraries mentioned here will work with Bright Data's scraping browser as they all use the same protocol to control headless Chrome.
Now let's scrape some data.
Setting Up the Scraping Browser
The goal here is to create a new proxy with a username and password, which will be required in our code. You can do that by following these steps:
- Signing up: go to Bright Data's homepage and click on "Start Free Trial". If you already have an account with Bright Data, you can just log in.
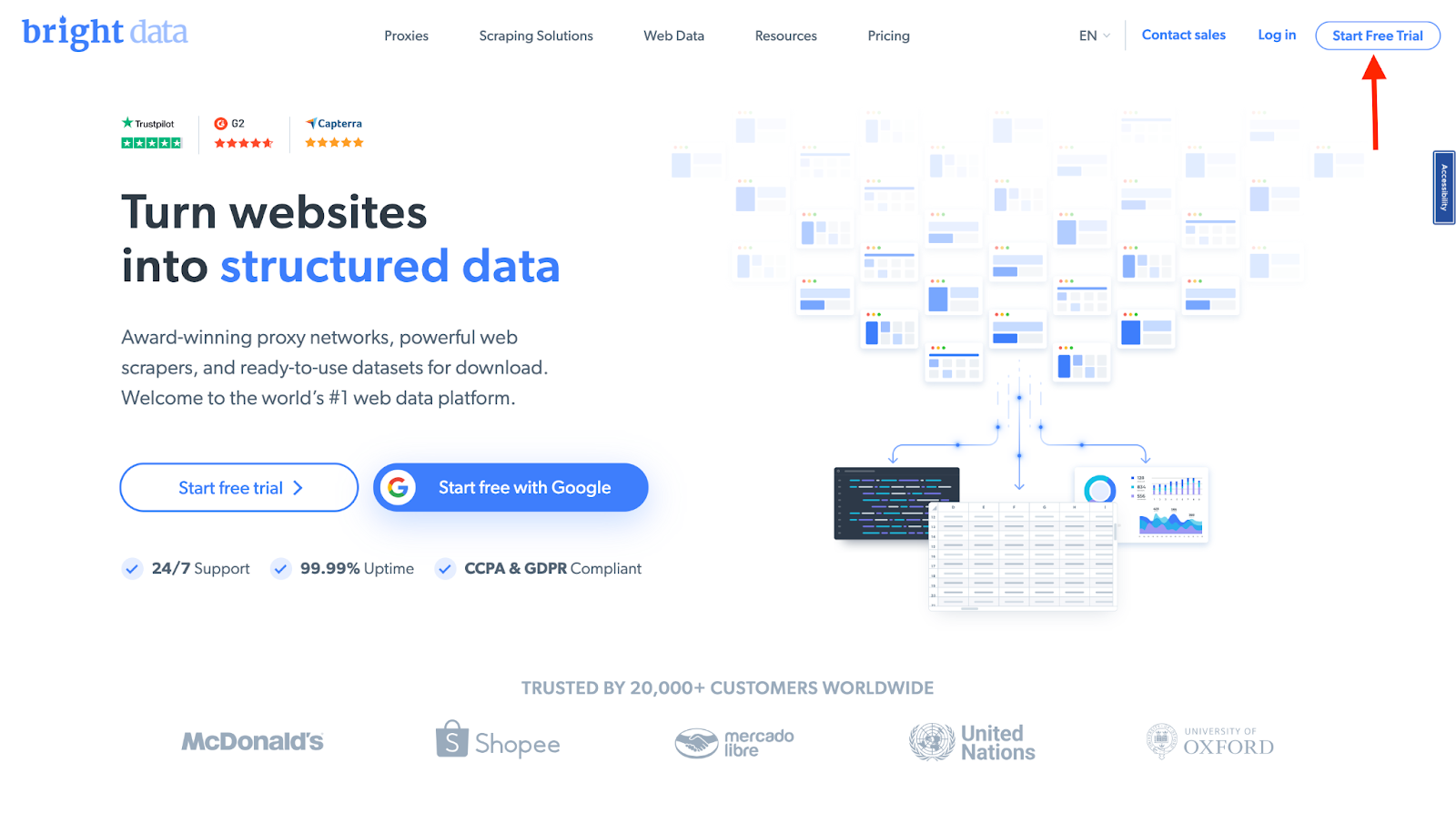
- Once you sign in after entering your details and finishing the signup process, you will be redirected to a welcome page. There, click on the "View Proxy Products" card.
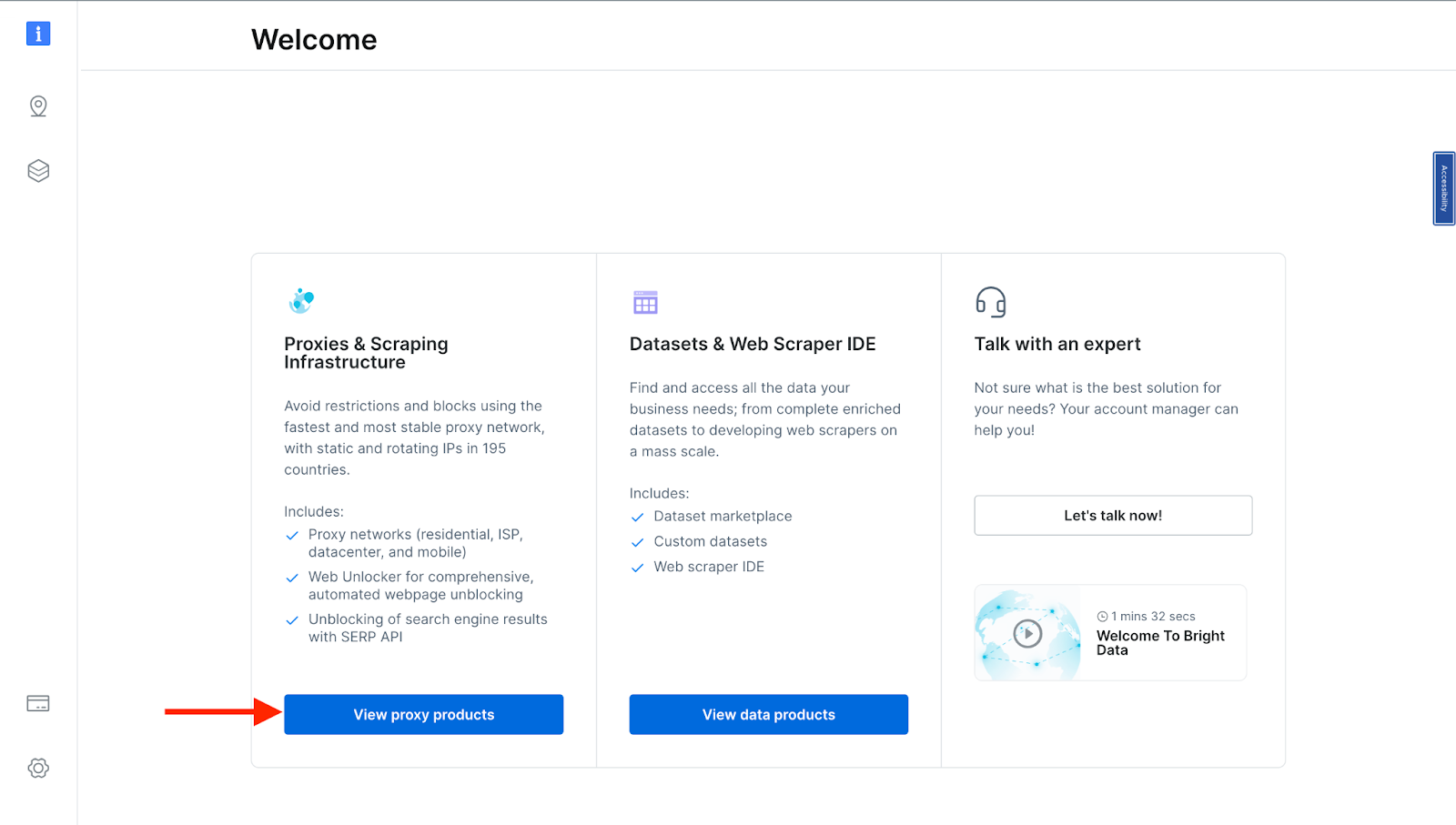
- You will be taken to the "Proxies & Scraping Infrastructure" page. Under "My proxies," select "Scraping Browser".
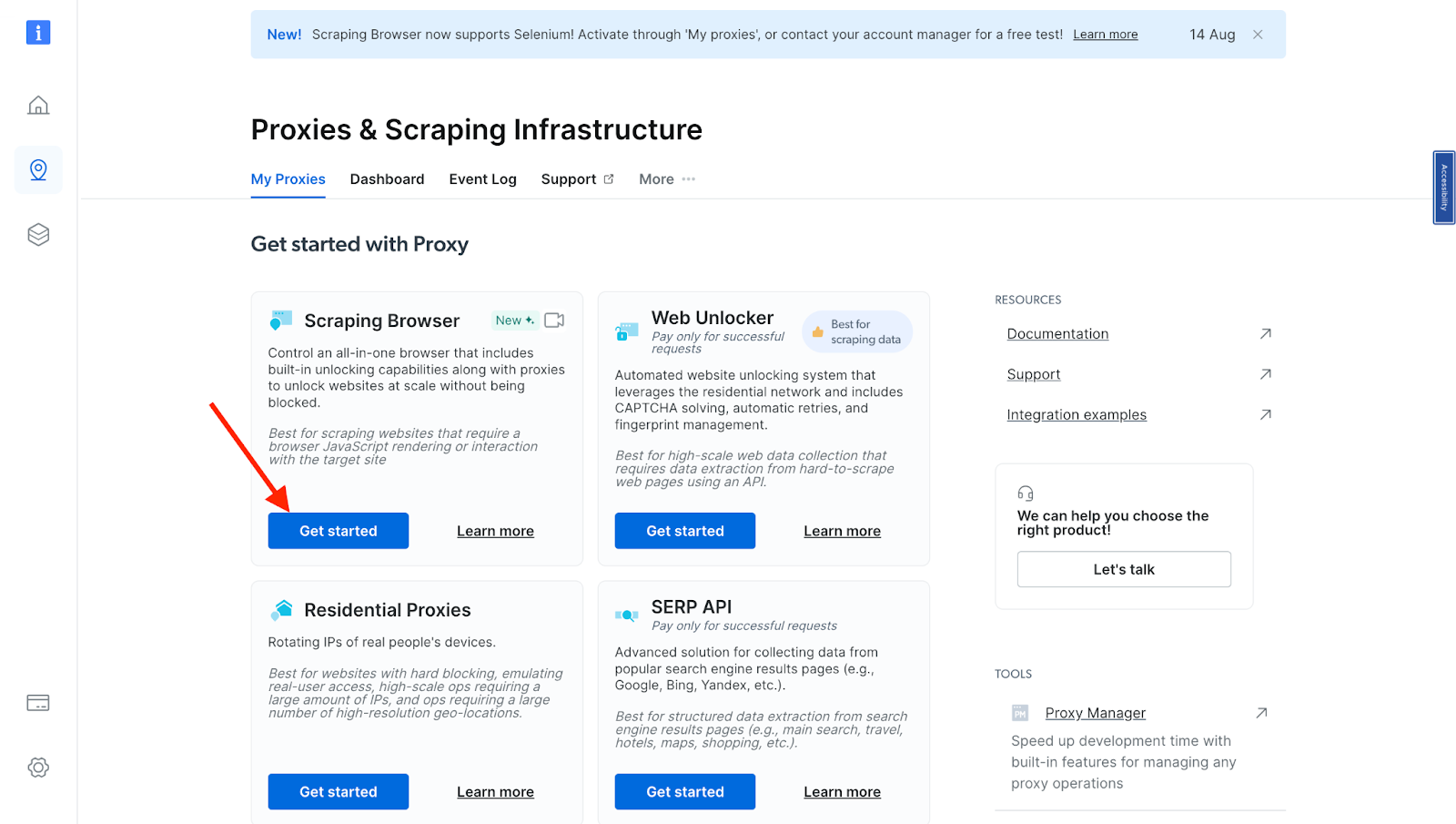
If you already have an active proxy, just click on "Add" and select "Scraping Browser."
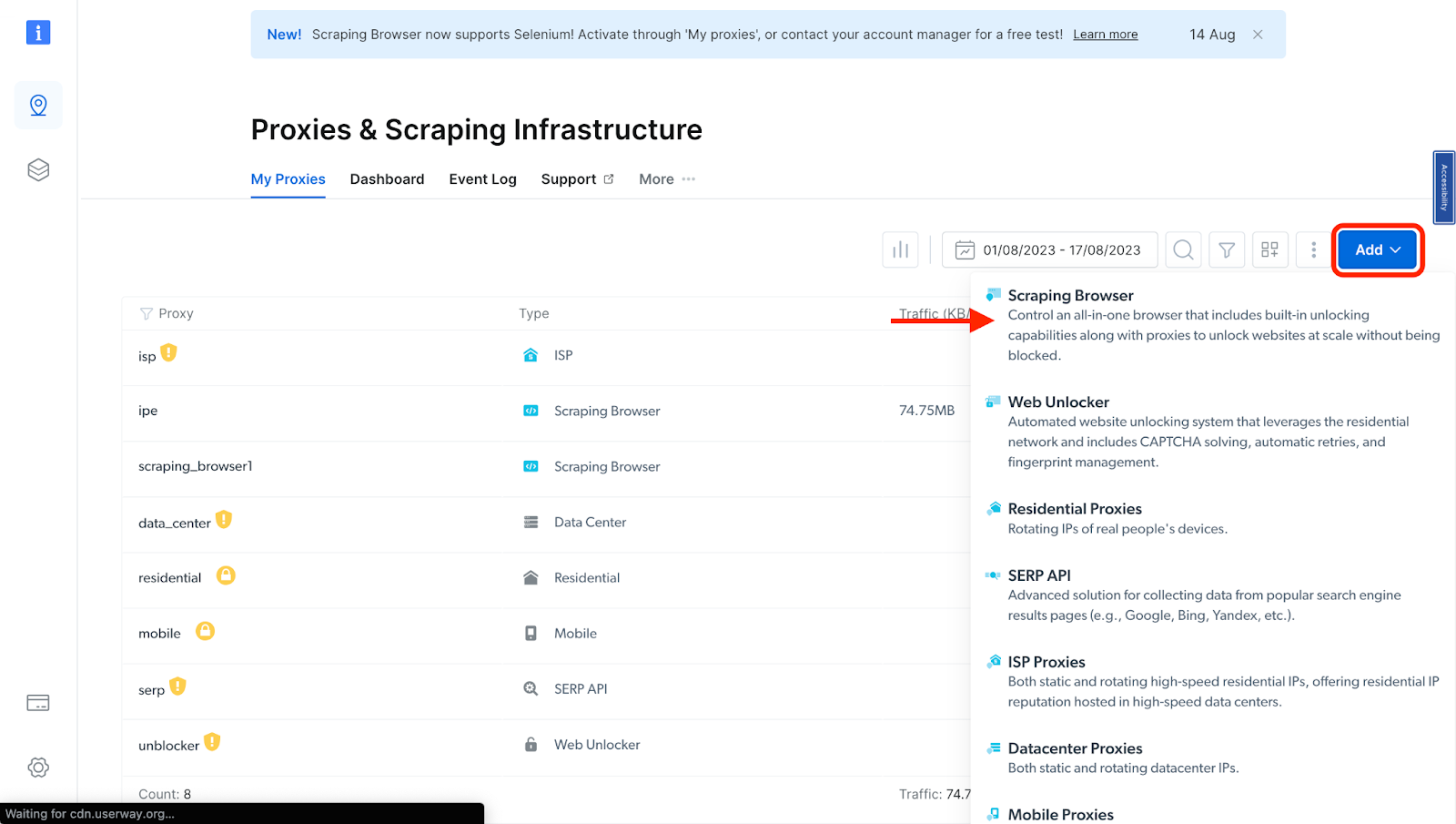
- Next, you will be taken to the "Add new proxy solution" page, where you will be required to input a name for your new scraping browser proxy zone. After inputting a solution name, click on "Add".
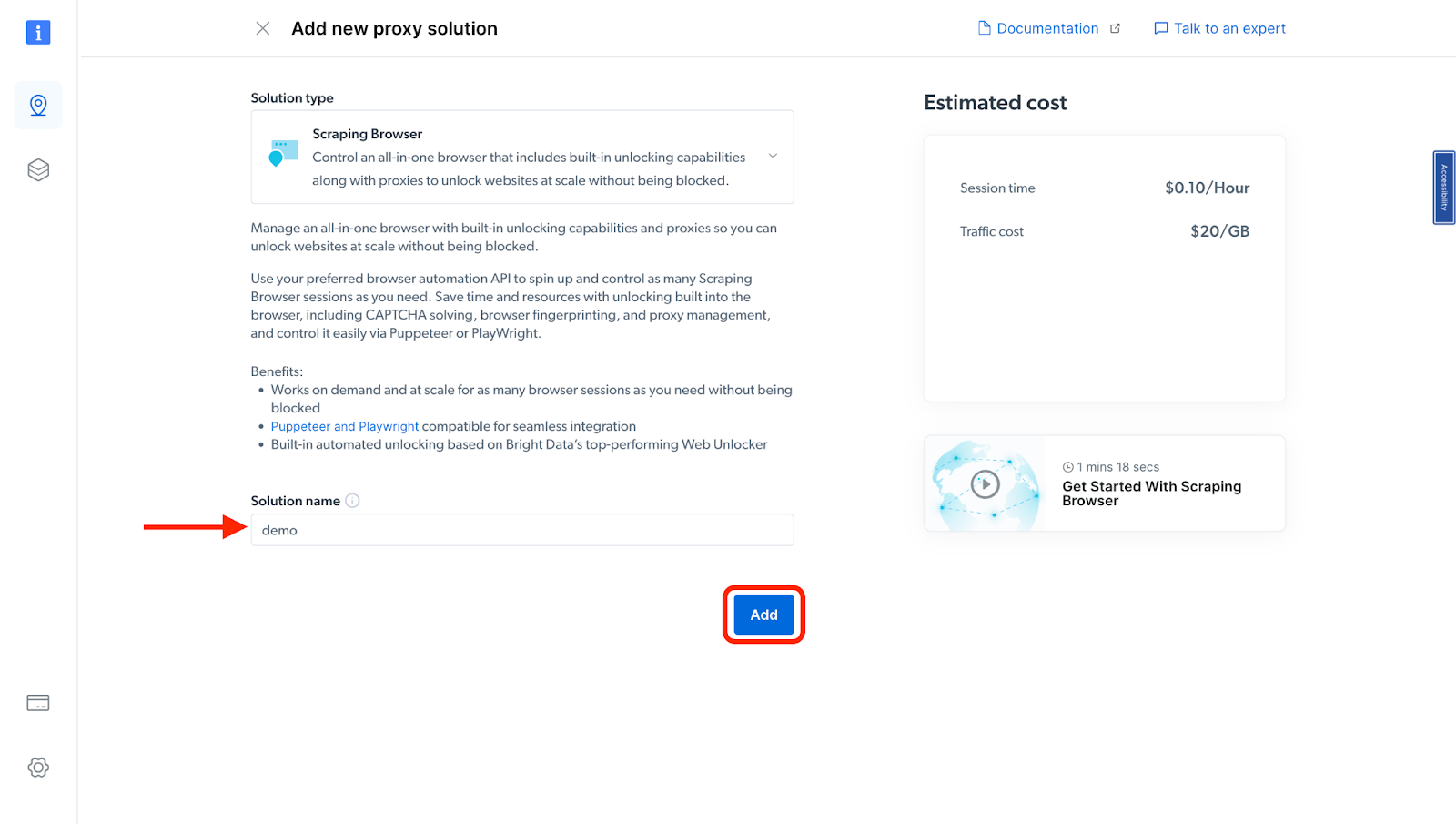
- At this point, if you haven't yet added a payment method, you'll be prompted to add one in order to verify your account. As a new user of Bright Data, you'll receive a $5 bonus credit to get you started. NB: This is mainly for verification purposes, and you will not be charged at this point
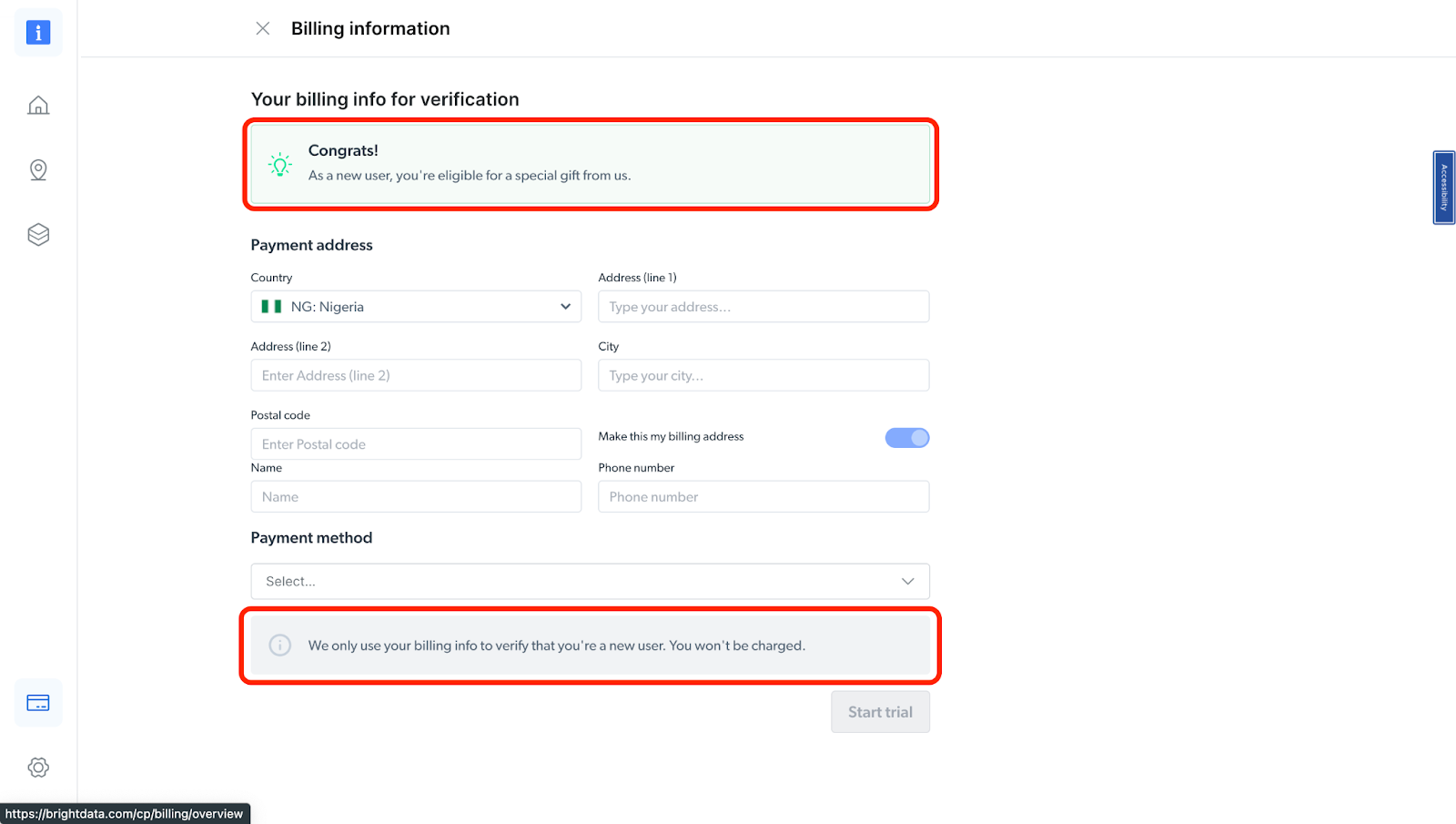
- After verifying your account, your proxy zone will be created.
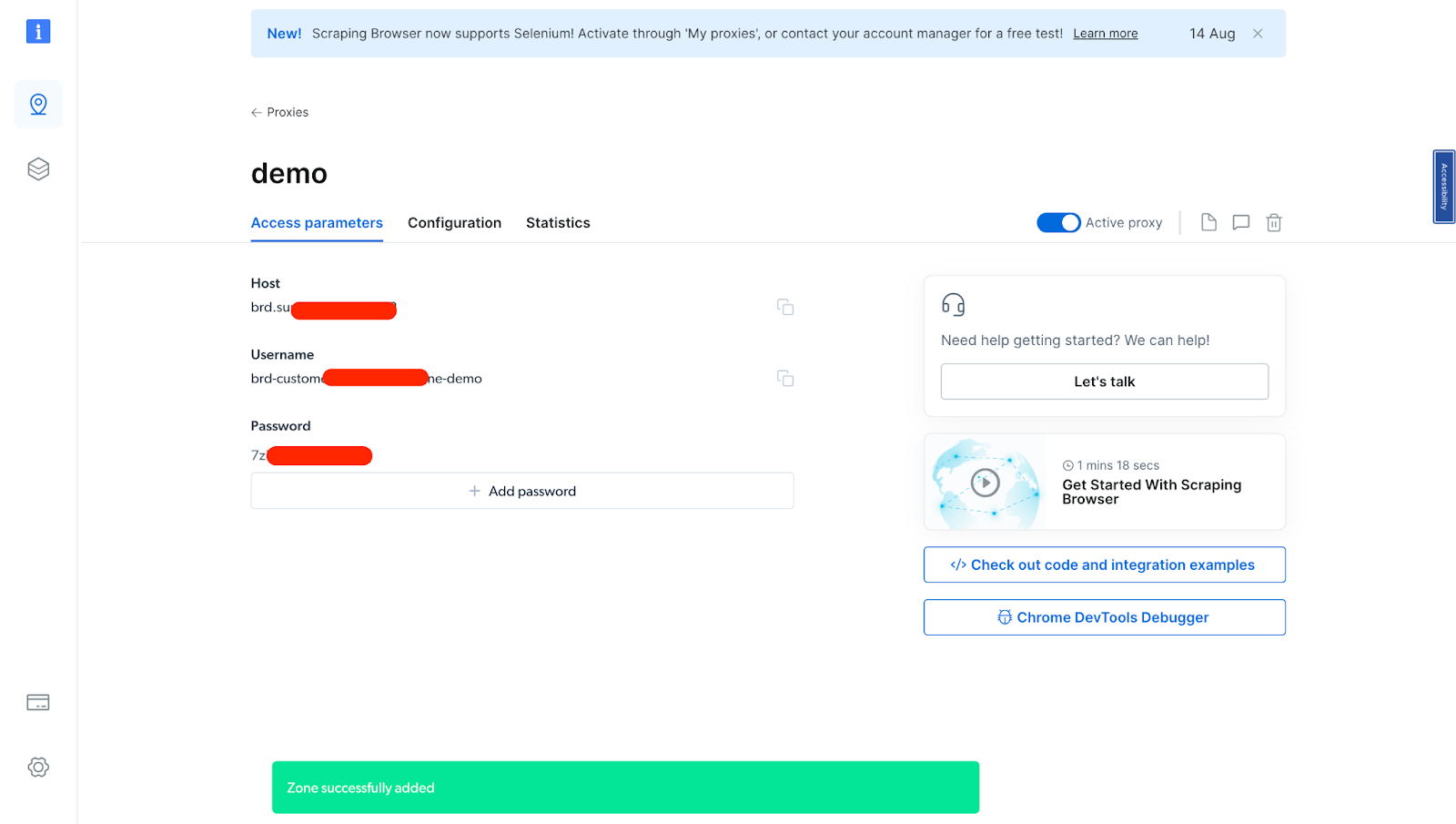
You will need these details in the next section. So you either copy them down or leave the tab open.
The Code
Now that you have your proxy setup, let's proceed to scrape some public data. In order to follow along with this section, you will need to have the things listed below.
Project Setup:
- Create a new folder/directory and open it using your preferred code editor.
- Initialize it with NPM using the command below
npm init -y
- If the above command is successful, it will create a
package.jsonfile in your folder. After which, you can install Puppeteer using the command below
npm i puppeteer-core
Once this is done, you can now proceed to integrate Bright Data's scraping browser
Scraping Job Search Results from LinkedIn
In this example, you will be searching for a particular job title (Technical Writer) on LinkedIn.
- Head over to LinkedIn.com.
- Type out the particular job title you are looking for. You can include parameters like - how long the job has been posted, full-time/part-time, level, location, or even company.
- Copy the link, open an incognito mode window, and paste the link there. This is because the
divclasses when you're logged in are different from those when you're not. And those classes are what you want to target. (If you are not logged in to LinkedIn, you don't have to worry about this.) - In your Incognito browser, inspect your page.
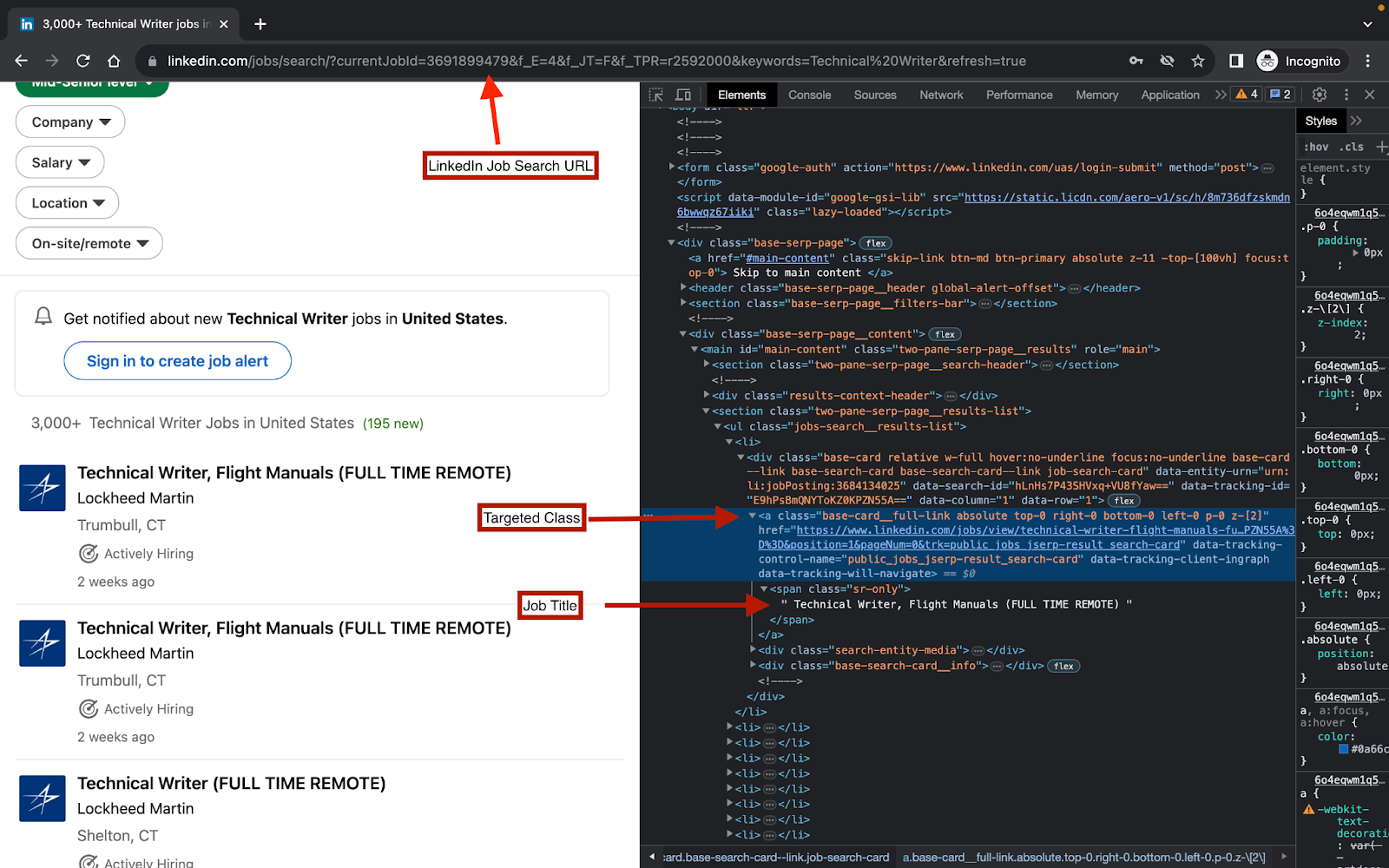
From the image above, the class you will be targeting is base-card__full-link. This is because it contains the job URL and theJob title, which is the information we want to extract.
Now that you have the above information, in your code editor, create a script.js file and implement the code below
const puppeteer = require("puppeteer-core");
const auth = "<your username>:<your password>";
async function run() {
let browser;
try {
browser = await puppeteer.connect({
browserWSEndpoint: `wss://${auth}@zproxy.lum-superproxy.io:9222`,
});
const page = await browser.newPage();
page.setDefaultNavigationTimeout(2 * 60 * 1000);
await page.goto(
"https://www.linkedin.com/jobs/search/?currentJobId=3691899479&f_E=4&f_JT=F&f_TPR=r2592000&keywords=Technical%20Writer&refresh=true"
);
await new Promise((r) => setTimeout(r, 5000));
const data = await page.$$eval(".base-card__full-link", (links) =>
links.map((link) => ({
title: link.innerText.trim(),
url: link.href,
}))
);
console.log("data", data);
} catch (e) {
console.error("run failed", e);
} finally {
if (browser) {
await browser.close();
}
}
}
if (require.main == module) (async () => await run())();
A few things to understand from the code above:
- Replace '
<your username>:<your password>', with your actual Bright Data proxy zone username and password from above. This is because Puppeteer will be connected through a remote proxy, so authentication with Bright Data is required - What we need next is to initialize a main function (
run) that will initialize the headless browser to navigate to the inserted LinkedIn job search page. Using Puppeteer's connect method (puppeteer.connect), a connection is established over a WebSocket to an existing browser instance (a Chromium instance). - The
browserWSEndpointis a WebSocket URL the Puppeteer client can use to connect to a running browser instance (this happens in the backend). As stated earlier, Puppeteer is based on the Chrome DevTools Protocol, allowing you to connect to a remote browser using a WebSocket connection. - Next, we have the try block, where a new page/tab is opened using
const page = await browser.newPage(). We also setpage.setDefaultNavigationTimeoutto 2 minutes. If the page doesn't load within this time, Puppeteer will throw an error. - The script will navigate to the inserted LinkedIn job search result URL to get data about a particular job search parameter. We also set
Promiseto make the script wait for 5 seconds. - Puppeteer then uses the
page.$$eval()function to extract data from the elements obtained from the LinkedIn URL with the class.base-card__full-link. For each of these elements, it creates an object containing the title (text content) and the URL (href attribute). The resulting array of objects is then stored in thedatavariable. - The browser is then closed using the
browser.closemethod.
And finally, the if block checks if the current module is the main module being executed directly. If the condition is true, it defines an asynchronous arrow function that awaits the completion of the run() function. Immediately after defining the arrow function, it self-invokes it, causing the run() function to execute asynchronously.
If this runs successfully, you should get an output similar to this:
data[
({
title: "Technical Writer, Flight Manuals (FULL TIME REMOTE)",
url: "https://www.linkedin.com/jobs/view/technical-writer-flight-manuals-full-time-remote-at-lockheed-martin-3684134025?refId=GNgd7%2FyXI4zzs3wOkX6ASg%3D%3D&trackingId=d8zxtTmI57I2txvebsovbw%3D%3D&position=1&pageNum=0&trk=public_jobs_jserp-result_search-card",
},
{
title: "Technical Writer, Flight Manuals (FULL TIME REMOTE)",
url: "https://www.linkedin.com/jobs/view/technical-writer-flight-manuals-full-time-remote-at-lockheed-martin-3684418066?refId=GNgd7%2FyXI4zzs3wOkX6ASg%3D%3D&trackingId=cdriVSPx1yjkM9BEoPKQUQ%3D%3D&position=2&pageNum=0&trk=public_jobs_jserp-result_search-card",
},
{
title: "Technical Writer/Editor",
url: "https://www.linkedin.com/jobs/view/technical-writer-editor-at-jsl-technologies-inc-3692971252?refId=GNgd7%2FyXI4zzs3wOkX6ASg%3D%3D&trackingId=V7v%2BmMxVU9fY5aEZOcZfWg%3D%3D&position=3&pageNum=0&trk=public_jobs_jserp-result_search-card",
},
{
title: "Technical Writer (FULL TIME REMOTE)",
url: "https://www.linkedin.com/jobs/view/technical-writer-full-time-remote-at-lockheed-martin-3670413606?refId=GNgd7%2FyXI4zzs3wOkX6ASg%3D%3D&trackingId=5jSNQCO1kN3rTH1N4DEDCA%3D%3D&position=4&pageNum=0&trk=public_jobs_jserp-result_search-card",
})
];
And just like that, you have your data. You can save this data in a CSV file or in an Excel sheet. Information from this data can be used for job market analysis, skillset identification, geographic trends, and so on.
With the right tools, the process of scraping public data isn't that complicated. You can also use this method to get other LinkedIn public data like emails from a particular category of people, names, and profiles of individuals in a particular industry, and lots more.
Conclusion
The ability to scrape public data from platforms like LinkedIn opens up a world of insights, enabling us to make informed decisions, analyze trends, and gain a competitive edge. In our quest for knowledge, data is power, and LinkedIn serves as a treasure trove of publicly available information that can be harnessed for a myriad of purposes.
In this article, we walk through the process involved in scraping data from LinkedIn using a step-by-step approach while utilizing the Scraping Browser (with Puppeteer), which made the process faster. The Scraping Browser handles all the restrictions involved in scraping public data from a platform like LinkedIn under the hood, including rate limiting, CAPTCHAs, and IP blockers. It also comes with a free trial, which you can use to get started. Aside from Puppeteer, The Scraping Browser can also be integrated with Selenium or Playwright, you can look up the official documentation for further instructions.
Scraping Browser - Automated Browser for Scraping
By leveraging web scraping for LinkedIn, you can uncover insights, gain an edge, and open doors to new opportunities - all by harnessing the power of public data that is available on the platform. I hope this article will help you do just that.
Comments
Loading comments…