The openpyxl and psycopg2 Python libraries can be used together to effectively handle the transfer of data from a tabular format in Excel to a relational database in PostgreSQL.
Openpyxl will be used to manipulate the Excel workbook. Specifically, and starting from the location of the xlsx file, we will use it to open the workbook and load the active worksheet into a variable. With this variable we can obtain both the column headings and the data of the rest of the rows of the table.
On the other hand, the psycopg2 library allows us to create a connection to our PostgreSQL database and execute queries through an object called cursor. We can write the queries in strings and execute them using the ‘execute’ or ‘executemany’ functions in case we have a parameterized query. To make the changes in the database persistent, we will end up using the ‘commit’ method. Thus, we can go to our database manager and perform a simple query to verify that the data has been loaded correctly.
This is the general approach, next we will see step by step how to develop this idea. However, before starting I would like to thank Vicente Antonio Juan Magallanes, because his series “El Desafío Todo en Uno” laid the foundations for the creation of this article. I encourage you to visit his blog, where you will find a wide variety of interesting resources related to data analysis.
Importing Libraries
Before importing the psycopg2 and openpyxl libraries, it is necessary to install them using pip install psycopg2 and pip install openpyxl in the command prompt. If you already have them installed, you can import them directly.
# Import libraries
import psycopg2
import openpyxl
Create Database Connection and Cursor Object
Once this is done, we need to establish a connection to our database and create a cursor object that will allow us to execute SQL commands in Python.
For the connection, we use the ‘connect’ function, which creates a session in the database and returns an instance of the ‘connection’ class that we will use later for the cursor. However, this function requires several parameters:
- Database: Refers to the name of the database to which we want to connect, which must already exist.
- User: The username used to authenticate ourselves in the database. In PostgreSQL, the default user is ‘postgres’.
- Password: The password for authentication in the database.
- Host: The address of the database host. The value ‘localhost’ means that the database is located on the same machine.
- Port: The PostgreSQL port number, which defaults to 5432.
With the connection established, we can create the cursor object using the ‘cursor()’ method.
# Create a connection to existing DB
connection = psycopg2.connect(
database = 'HR_Data',
user = 'postgres',
password = '************',
host = 'localhost',
port = '5432'
)
# Open a cursor object to perform database operations
cursor = connection.cursor()
As an alternative, you can use a configuration file (e.g., a ‘.ini’ file) to store the connection parameters. This offers the advantage of being able to modify the parameters without changing the source code, which is useful when moving the code to a production environment. Additionally, you can implement security in the file to restrict access to the information, especially when storing sensitive data such as passwords or other confidential information.
To create a configuration file (in this case, ‘.ini’), open a text file and save it with the ‘.ini’ extension. Inside the file, you can define sections and configurations like this:
[database]
host = localhost
port = 5432
database = mydatabase
user = myuser
password = mypassword
Then, to access these parameters in the code, you can use the ‘configparser’ library.
import configparser
# Create a ConfigParser object
config = configparser.ConfigParser()
# Read the file using the object
config.read('config.ini')
# Obtain the configuration values
host = config.get('database', 'host')
port = config.get('database', 'port')
database = config.get('database', 'database')
user = config.get('database', 'user')
password = config.get('database', 'password')
You can use the values in the parameters of the ‘connect’ function to connect to the database.
# Create a connection to existing DB
connection = psycopg2.connect(
database = database,
user = user,
password = password,
host = host,
port = port
)
# Open a cursor object to perform database operations
cursor = connection.cursor()
Extracting data from Excel
This time, I’m using a dataset from Kaggle containing information about employees in a fictional company. You can download it by following the link or directly from my GitHub repository.
To extract data from our workbook, we first need to store the path to the xlsx file in a variable. This allows us to use it as a parameter for the ‘load_workbook’ function of openpyxl, which is responsible for opening the workbook. With the workbook open, we can activate the sheet where the data is located.
In this case, the table has a header with column titles. We can create a list containing the column names by iterating over each column and obtaining the value in each cell of the first row (sheet[1]).
On the other hand, to retrieve the data from the remaining rows, we will use the ‘iter_rows’ method of openpyxl. This method allows us to iterate over the rows of the worksheet we specify, in this case, starting from row 2 of the ‘sheet’ variable to exclude the header. Additionally, we set the ‘values_only’ argument to True so that the method only returns the values of the cells.
In each iteration of the loop, the data from the row is added to an empty list previously created (data).
# Save Excel file location into a variable
excel_file = 'C:\\Users\\Documents\\HR_Employees\\HR_Employee_Data.xlsx'
# Open the Excel workbook and load the active sheet into a variable
workbook = openpyxl.load_workbook(excel_file)
sheet = workbook.active
# Create a list with the column names in the first row of the workbook
column_names = [column.value for column in sheet[1]]
# Create an empty list
data = []
# Iterate over the rows and append the data to the list
for row in sheet.iter_rows(min_row = 2, values_only = True):
data.append(row)
Execution of SQL queries to create schemas and tables
In this case, I am using PostgreSQL to store the data, so in addition to creating a table, it is necessary to create a schema.
Schemas are used to organize and manage database objects such as tables, functions, and views. They allow related objects to be grouped in a separate logical space within a database, which also helps avoid naming conflicts between tables.
To create the schema and the table, I start by assigning them names and storing them in two variables. Then, we can write the SQL query in a f-string and use the values of the variables where the names for the schema or table would be provided. It’s important to note that for queries that span multiple lines of code, triple quotes should be used instead of single quotes.
The snippet {“,”.join([f’”{name}” TEXT’ for name in column_names])} in the code below is used to create a list of column names separated by commas, a format necessary to comply with the syntax of the CREATE TABLE statement. In this case, each name is enclosed in double quotes to ensure that the query works correctly even if the names contain special characters or spaces, although it is usually not necessary to do so.
Finally, we execute the queries using the cursor created in the previous sections along with the ‘execute’ method. We use the variable with the query as the parameter.
# Set a name for the PostgreSQL schema and table where we will put the data
schema_name = 'hr_employees'
table_name = 'evaluation'
# Write a query to create a schema using schema_name
schema_creation_query = f'CREATE SCHEMA IF NOT EXISTS {schema_name}'
# Write a query to create a table in the schema. It must contain all
# columns in column_names
table_creation_query = f"""
CREATE TABLE IF NOT EXISTS {schema_name}.{table_name} (
{", ".join([f'"{name}" TEXT' for name in column_names])}
)
"""
# Use the cursor to execute both queries
cursor.execute(schema_creation_query)
cursor.execute(table_creation_query)
Data Import Using Parameterized SQL Query
A parameterized SQL query is a query in which placeholders are used for input values, instead of encoding them directly in the SQL string. During execution, actual values are passed as parameters, which improves security and prevents SQL injection.
So, we can use placeholders in the VALUES clause to represent the data that will be inserted into the table.
List comprehension in ({", “.join(['%s' for _ in column_names])} is used to repeat the placeholder (‘%s’) as many times as the number of columns in the ‘column_names’ variable since we will insert data into each column.
To execute the query, we use ‘executemany’ instead of ‘execute’ so that we can pass the ‘data’ list — which contains the Excel data — as a parameter.
Furthermore, to make the changes made in the database persistent, we must use the ‘commit’ method on the ‘connection’ object. After doing this, we close the database communication with the ‘close’ method.”
# Create a parameterized SQL query to insert the data into the table
insert_data_query = f"""
INSERT INTO {schema_name}.{table_name} ({", ".join([f'"{name}"' for name in column_names])})
VALUES ({", ".join(['%s' for _ in column_names])})
"""
# Execute the query using the data list as parameter
cursor.executemany(insert_data_query, data)
# Make the changes to the database persistent
connection.commit()
# Close communication with the database
cursor.close()
connection.close()
# Print a message
print('Import successfully completed!')
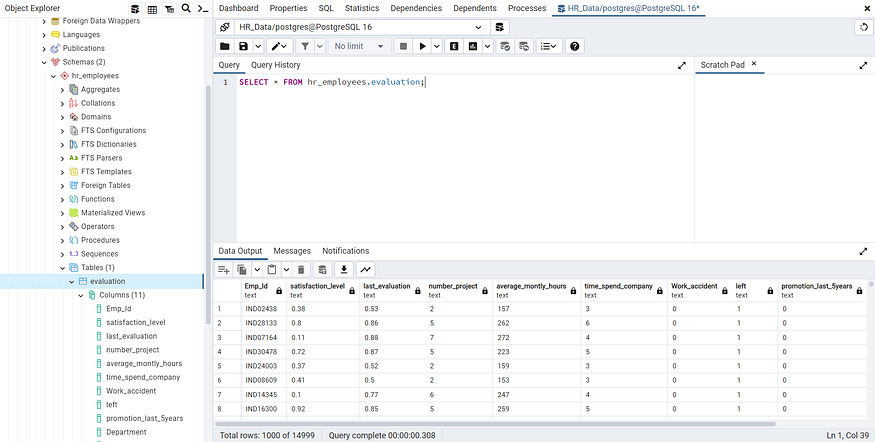
This would be the entire Python code. Once we execute it, we can go to our PostgreSQL database, update it, and run a simple SELECT * FROM hr_employees.evaluation query to verify that the data has been imported correctly. You can see it in the following image:
Conclusion
In this article, we have seen how to import data from an Excel file using Python’s psycopg2 and openpyxl libraries, with a focus on using a configuration file as an alternative to store sensitive database information.
You can find the complete code used for this article in my GitHub, as well as a copy of the Kaggle dataset.
Thank you for reading!
References
- Python en la saga: El desafío todo en uno — Vicente Antonio Juan Magallanes
- PostgreSQL Python: Connect To PostgreSQL Database Server — PostgreSQL Tutorial
- How Parameterized queries and bind parameters are implemented in PostgreSQL? — MinervaDB
- SQL Injection y Consultas Parametrizadas — Arquitectura Java
Comments
Loading comments…