But first, a little eulogy?
I started this article when Retrieval Augmented Generation (RAG) had a brighter future. It’s now overshadowed by the 1 million token context window of Google’s new model Gemini 1.5. With future models possibly having infinite context windows, does RAG matter anymore? If RAG is dead, what place does re-ranking have?
Thinking about all this, I got reminded of this scene from Top Gun, where Admiral Chester Cain tells Captain Maverick (Tom Cruise) that pilots would be soon made obsolete by autonomous planes. To that, Captain Maverick replies with a self-assured smile — “but not today”.

I think it’s the same for RAG as we know it — not today. RAG is more than just limiting the amount of data fed to an LLM to circumvent context limits. An effective RAG pipeline is also about increasing the signal to noise ratio of the information that you feed an LLM. This is going to be relevant as long as the gains in an LLM’s response quality is worth the RAG set up. This is something yet to be seen in the wild as long context models become openly available. Additionally, even given long context windows, RAG would help with decreasing latency and cost. Again, as long as the decreased latency and cost justify the effort of setting up a RAG pipeline, RAG would still exist in one form or the other. And in the world of RAG, re-ranking is still an important part of an effective pipeline. I hope that justifies this article. If not, let it be for at least the pedagogical value!
RAG is more than just limiting the amount of data fed to an LLM to circumvent context limits. An effective RAG pipeline is also about increasing the signal to noise ratio of the information that you feed an LLM.
RAG for the uninitiated
RAG has been one of the most popular applications of LLMs over the past year. It makes sense because it gives LLMs the power to answer questions from documents it wasn’t trained on, complementing its general knowledge with specific information. The most basic RAG pipeline looks something like this:
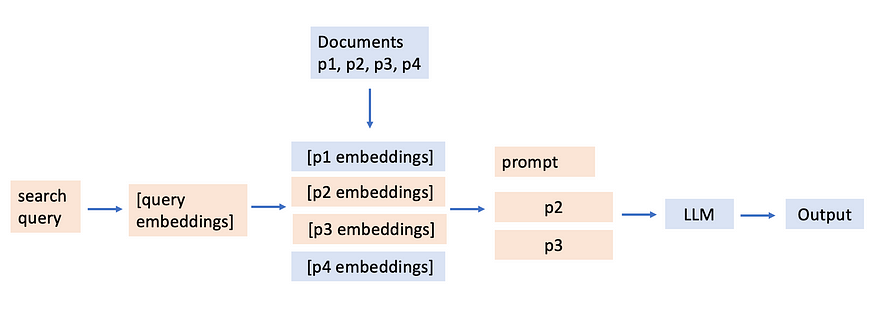
Such a simple RAG pipeline has a key limitations — a document that’s semantically the most similar might not be the most relevant to a given question. Here’s an example (which i’ll use plenty of times again) to illustrate this. Let’s say you have a question: “Was Paul vegan?” and you have a few sentences:
[1] Paul loved going for walks with Mr. McChicken
[2] Paul saw his colleague eat a juicy McDonald’s McChicken burger
[3] Paul loved to eat McDonald’s McChicken burger
[4] Paul always had dinner with Mrs. McChicken
[5] Paul had a lot of lettuce in his salad
When you read these sentences, it becomes very clear instantly that [3] Paul loved to eat McDonald’s McChicken burger is the most relevant to our question because it allows us to directly infer the answer to the question. However, let’s compare the cosine similarities of these sentences with our search query.

Overcoming the limitation — reranking results of a vector search
That’s not bad at all. But imagine this sentence mixed with other context in a much bigger set of documents, like in this test. And in a situation where you want to query a large set of documents, it makes sense retain the top ‘n’ documents out of the initial set of retrieved documents to increase the signal to noise ratio. This is where re-ranking comes in. If you wonder why perplexity is so good, it’s probably because of a very effective RAG pipeline with some form of re-ranking involved.
LLMs as reranking agents — RankGPT
LLMs have been shown to be a great general purpose tool, analogous to a Swiss Army knives. So why not use them for re-ranking? This approach could be particularly powerful because LLMs can re-rank documents with more than just semantics, but also with a layer of ‘reasoning’ that they inherently possess because of their world knowledge. What if we just pass our documents to an LLM and instruct it to re-rank our documents based on the relevance to a search query. This was the approach proposed in an arXiv paper, calling the particular method as the permutation generation approach:
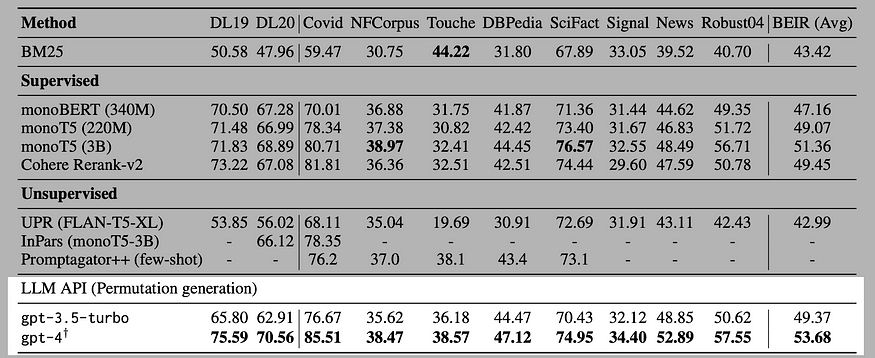
This approach beats others in almost all the benchmarks, ranking even higher than cohere rerank. I also did my own little hacked up test:
LLMs as re-ranking agents after retrieval? Just tested out RankGPT (@sunweiwei12 et al.) by randomly injecting a target sentence and multiple distractor sentence into Paul Graham's essay.
— june (@arjunkmrm) January 18, 2024
Impressive results just by using out of the box LLMs as re-rankers after single vector… pic.twitter.com/7gfDmWfb4U
The method is quite straightforward. Chunks of initially retrieved documents from a search are fed into the context window of an LLM along with a prompt to rank the chunks based on their relevance to a query. Voila, you have rankGPT. It’s purely just instruction/prompting, nothing fancy. Yet.

To the sharp reader, you would already squinted your eyes with scrutiny and asked “what if all my documents exceed the context length?” (wrote this pre-gemini 1.5, funny now — how fast AI changes!). Here is where the paper implements a clever little technique. This problem could be overcome by ranking your documents over a sliding window and then combining the ranks together. Let’s understand this with an example.
Ranking documents over a sliding window
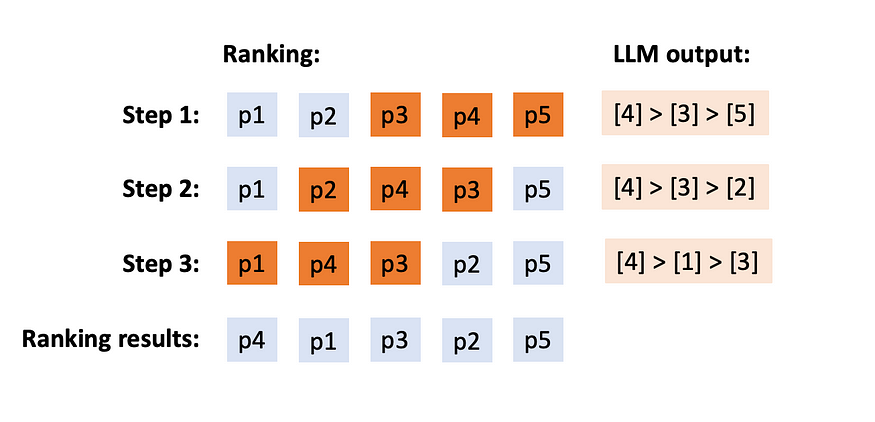
ranking using a sliding window
Simply put, you don’t give the LLM all the documents at the same time. But you give it sets of documents and you ask for it to rank each set of document and ask it to rank them. For example, let’s revisit our five sentences:
[1] Paul loved going for walks with Mr. McChicken
[2] Paul saw his colleague eat a juicy McDonald’s McChicken burger
[3] Paul loved to eat McDonald’s McChicken burger
[4] Paul always had dinner with Mrs. McChicken
[5] Paul had a lot of lettuce in his salad
The query is: “Is Paul vegan?” If I choose a context window of 3 and a step length of 2, my re-ranking pipeline would look something like this:
**Step 1:
**[3] Paul loved to eat McDonald’s McChicken burger
[4] Paul always had dinner with Mrs. McChicken
[5] Paul had a lot of lettuce in his salad
LLM output: [3] > [5] > [4]
**Step 2:
**[2] Paul saw his colleague eat a juicy McDonald’s McChicken burger
[3] Paul loved to eat McDonald’s McChicken burger
[4] Paul always had dinner with Mrs. McChicken
LLM output: [3] > [2] > [4]
Step 3:
[1] Paul loved going for walks with Mr. McChicken
[2] Paul saw his colleague eat a juicy McDonald’s McChicken burger
[3] Paul loved to eat McDonald’s McChicken burger
LLM output: [3] > [2] > [1]
Overall ranking: [3] > [2] > [5] > [4] > [1]
So, it’s simply, asking an LLM to rank documents in a over a moving context window from the end to start at the rate of the given step value.
How to implement this in python from scratch?
All of the code below is from the RankGPT paper’s github repo.
Step 1: create the prompt instruction
# prefix instruction
def get_prefix_prompt(query, num):
return [{'role': 'system',
'content': "You are RankGPT, an intelligent assistant that can rank passages based on their relevancy to the query."},
{'role': 'user',
'content': f"I will provide you with {num} passages, each indicated by number identifier []. \nRank the passages based on their relevance to query: {query}."},
{'role': 'assistant', 'content': 'Okay, please provide the passages.'}]
# suffix instruction
def get_post_prompt(query, num):
return f"Search Query: {query}. \nRank the {num} passages above based on their relevance to the search query. The passages should be listed in descending order using identifiers. The most relevant passages should be listed first. The output format should be [] > [], e.g., [1] > [2]. Only response the ranking results, do not say any word or explain."
# add passages to prompt
def create_permutation_instruction(item=None, rank_start=0, rank_end=100, model_name='gpt-3.5-turbo'):
query = item['query']
num = len(item['hits'][rank_start: rank_end])
max_length = 300
messages = get_prefix_prompt(query, num)
rank = 0
for hit in item['hits'][rank_start: rank_end]:
rank += 1
content = hit['content']
content = content.replace('Title: Content: ', '')
content = content.strip()
# For Japanese should cut by character: content = content[:int(max_length)]
content = ' '.join(content.split()[:int(max_length)])
messages.append({'role': 'user', 'content': f"[{rank}] {content}"})
messages.append({'role': 'assistant', 'content': f'Received passage [{rank}].'})
messages.append({'role': 'user', 'content': get_post_prompt(query, num)})
return messages
Overall instruction looks like this, for n passages and a given query:
‘system’: “You are RankGPT, an intelligent assistant that can rank passages based on their relevancy to the query.”
‘user’: I will provide you with {n} passages, each indicated by number identifier [].
Rank the passages based on their relevance to query: {query}.”},
‘assistant’: ‘Okay, please provide the passages.’
‘user’: [1] {content}
‘assistant’: ‘Received passage [1]’
‘assistant’: ‘Okay, please provide the passages.’
‘user’: [2] {content}
‘assistant’: ‘Received passage [2]’
………. till n passages
‘user’: Search Query: {query}.
Rank the {n} passages above based on their relevance to the search query. The passages should be listed in descending order using identifiers. The most relevant passages should be listed first. The output format should be [] > [], e.g., [1] > [2]. Only response the ranking results, do not say any word or explain.”
Step 2: get ranking and re-order
Without sliding window:
The model’s response to the given instruction would look like this:
[3] > [2] > [5] > [4] > [1] > …… (n passages)
def run_llm(messages, api_key=None, model_name="gpt-3.5-turbo"):
if 'gpt' in model_name:
Client = OpenaiClient
elif 'claude' in model_name:
Client = ClaudeClient
else:
Client = LitellmClient
agent = Client(api_key)
response = agent.chat(model=model_name, messages=messages, temperature=0, return_text=True)
return response
You have some utility functions to clean the response by running through each character in the string and extracting the digits.
input: [3] > [2] > [5] > [4] > [1]
output: 3 2 5 4 1
Also a function to remove duplicates from the model generation as a safeguard.
def clean_response(response: str):
new_response = ''
for c in response:
if not c.isdigit():
new_response += ' '
else:
new_response += c
new_response = new_response.strip()
return new_response
def remove_duplicate(response):
new_response = []
for c in response:
if c not in new_response:
new_response.append(c)
return new_response
Use the permutations to re-rank the list:
def receive_permutation(item, permutation, rank_start=0, rank_end=100): # clean the response
response = clean_response(permutation)
# zero index
response = [int(x) - 1 for x in response.split()]
# remove duplicates and convert to list
response = remove_duplicate(response)
# cut the part of the list of passages you want to re-rank
cut_range = copy.deepcopy(item['hits'][rank_start: rank_end])
# get a zero indexed initial rank of passages from the cut range
original_rank = [tt for tt in range(len(cut_range))]
# get only the response ranks which are in the possible range of
# the zero indexed original ranks
response = [ss for ss in response if ss in original_rank]
# append the items in the original rank that are not in the permutation
# response
response = response + [tt for tt in original_rank if tt not in response]
# this is where the re-ranking happens
for j, x in enumerate(response):
# move passages to their re-ranked position
item['hits'][j + rank_start] = copy.deepcopy(cut_range[x])
return item
# a function to organise everything together
def permutation_pipeline(item=None, rank_start=0, rank_end=100, model_name='gpt-3.5-turbo', api_key=None):
messages = create_permutation_instruction(item=item, rank_start=rank_start, rank_end=rank_end,
model_name=model_name) # chan
permutation = run_llm(messages, api_key=api_key, model_name=model_name)
item = receive_permutation(item, permutation, rank_start=rank_start, rank_end=rank_end)
return item
With sliding window:
With the sliding window approach, you’re basically doing the steps above, but within specific ranges through the entire list of documents. Iteratively doing this ranks the documents.
def sliding_windows(item=None, rank_start=0, rank_end=100, window_size=20, step=10, model_name='gpt-3.5-turbo',
api_key=None):
item = copy.deepcopy(item)
end_pos = rank_end
start_pos = rank_end - window_size
while start_pos >= rank_start:
start_pos = max(start_pos, rank_start)
item = permutation_pipeline(item, start_pos, end_pos, model_name=model_name, api_key=api_key)
end_pos = end_pos - step
start_pos = start_pos - step
return item
Putting it all together — complete code
# prefix instruction
def get_prefix_prompt(query, num):
return [{'role': 'system',
'content': "You are RankGPT, an intelligent assistant that can rank passages based on their relevancy to the query."},
{'role': 'user',
'content': f"I will provide you with {num} passages, each indicated by number identifier []. \nRank the passages based on their relevance to query: {query}."},
{'role': 'assistant', 'content': 'Okay, please provide the passages.'}]
# suffix instruction
def get_post_prompt(query, num):
return f"Search Query: {query}. \nRank the {num} passages above based on their relevance to the search query. The passages should be listed in descending order using identifiers. The most relevant passages should be listed first. The output format should be [] > [], e.g., [1] > [2]. Only response the ranking results, do not say any word or explain."
# add passages to prompt
def create_permutation_instruction(item=None, rank_start=0, rank_end=100, model_name='gpt-3.5-turbo'):
query = item['query']
num = len(item['hits'][rank_start: rank_end])
max_length = 300
messages = get_prefix_prompt(query, num)
rank = 0
for hit in item['hits'][rank_start: rank_end]:
rank += 1
content = hit['content']
content = content.replace('Title: Content: ', '')
content = content.strip()
# For Japanese should cut by character: content = content[:int(max_length)]
content = ' '.join(content.split()[:int(max_length)])
messages.append({'role': 'user', 'content': f"[{rank}] {content}"})
messages.append({'role': 'assistant', 'content': f'Received passage [{rank}].'})
messages.append({'role': 'user', 'content': get_post_prompt(query, num)})
return messages
def run_llm(messages, api_key=None, model_name="gpt-3.5-turbo"):
if 'gpt' in model_name:
Client = OpenaiClient
elif 'claude' in model_name:
Client = ClaudeClient
else:
Client = LitellmClient
agent = Client(api_key)
response = agent.chat(model=model_name, messages=messages, temperature=0, return_text=True)
return response
def clean_response(response: str):
new_response = ''
for c in response:
if not c.isdigit():
new_response += ' '
else:
new_response += c
new_response = new_response.strip()
return new_response
def remove_duplicate(response):
new_response = []
for c in response:
if c not in new_response:
new_response.append(c)
return new_response
def receive_permutation(item, permutation, rank_start=0, rank_end=100):
# clean the response
response = clean_response(permutation)
# zero index
response = [int(x) - 1 for x in response.split()]
# remove duplicates and convert to list
response = remove_duplicate(response)
# cut the part of the list of passages you want to re-rank
cut_range = copy.deepcopy(item['hits'][rank_start: rank_end])
# get a zero indexed initial rank of passages from the cut range
original_rank = [tt for tt in range(len(cut_range))]
# get only the response ranks which are in the possible range of
# the zero indexed original ranks
response = [ss for ss in response if ss in original_rank]
# append the items in the original rank that are not in the permutation
# response
response = response + [tt for tt in original_rank if tt not in response]
# this is where the re-ranking happens
for j, x in enumerate(response):
# move passages to their re-ranked position
item['hits'][j + rank_start] = copy.deepcopy(cut_range[x])
return item
# a function to organise everything together
def permutation_pipeline(item=None, rank_start=0, rank_end=100, model_name='gpt-3.5-turbo', api_key=None):
messages = create_permutation_instruction(item=item, rank_start=rank_start, rank_end=rank_end,
model_name=model_name) # chan
permutation = run_llm(messages, api_key=api_key, model_name=model_name)
item = receive_permutation(item, permutation, rank_start=rank_start, rank_end=rank_end)
return item
def sliding_windows(item=None, rank_start=0, rank_end=100, window_size=20, step=10, model_name='gpt-3.5-turbo',
api_key=None):
item = copy.deepcopy(item)
end_pos = rank_end
start_pos = rank_end - window_size
while start_pos >= rank_start:
start_pos = max(start_pos, rank_start)
item = permutation_pipeline(item, start_pos, end_pos, model_name=model_name, api_key=api_key)
end_pos = end_pos - step
start_pos = start_pos - step
return item
Example usage
item = {
'query': 'Was paul vegan?',
'hits': [
{'content': 'Paul loved going for walks with Mr. McChicken'},
{'content': 'Paul saw his colleague eat a juicy McDonald"s McChicken burger'},
{'content': 'Paul loved to eat McDonald"s McChicken burger'},
{'content': 'Paul always had dinner with Mrs. McChicken'},
{'content': 'Paul had a lot of lettuce in his salad'}
]
}
new_item = permutation_pipeline(item, rank_start=0, rank_end=5, model_name='gpt-3.5-turbo', api_key='Your OPENAI Key!')
print(new_item)
{'query': 'Was paul vegan?',
'hits': [
{'content': 'Paul loved to eat McDonald"s McChicken burger'},
{'content': 'Paul had a lot of lettuce in his salad'},
{'content': 'Paul saw his colleague eat a juicy McDonald"s McChicken burger'},
{'content': 'Paul loved going for walks with Mr. McChicken'},
{'content': 'Paul always had dinner with Mrs. McChicken'}
]
}
Conclusion
In an ideal world of way faster and cheaper compute, RAG might be thrown out of job. But we’re not there yet. Until then, RAG is still going to exist in one form or the other as long as the improvements in quality, latency and cost of responses are worth a RAG pipeline. Re-ranking is a necessary part of an effective RAG pipeline. In this article, I explored the RankGPT paper which uses LLMs to re-rank documents through instructional prompting and the use of sliding windows for situations where the given documents might exceed the LLMs context window. This is a simple but effective approach which beats many other approaches on several benchmarks. Here, I demonstrated this with out-of-the box LLMs. However, you can also train or use specialised fine-tuned versions of re-rankers which could be run locally.
Comments
Loading comments…