
Output Parsers are specialized classes that transform the raw text output from language models (LLMs) into more structured and usable formats. This is essential for many applications where you need to extract specific information or work with the model’s responses in a more organized way.
Previously:
LangChain in Chains #6: Example Selectors
Parsers organize and format output data to facilitate subsequent processing in downstream operations.
Let’s utilize the OpenAI Chat model and explore obtaining results in specific formats, without using output parsers.
First, load the model.
# creds
import os
os.environ["OPENAI_API_KEY"] = "your-api-key"
# model
from langchain.chat_models import ChatOpenAI
chat = ChatOpenAI(temperature=0.1, model="gpt-4")
Now, for our use case, we aim to extract relevant information from incoming texts and directly route this information to the pertinent department within our app. Consequently, the extracted data (the content provided by OpenAI) must be formatted as JSON. This ensures seamless integration and usability within JavaScript applications.
The production team has issued a memo detailing the schedule for the upcoming shoot day of Brad Pitt’s new movie.
text = """
Tomorrow promises to be an eventful day as we're scheduled to shoot a
pivotal scene featuring the renowned actor, Brad Pitt.
The scene requires the unique charm of Central Park's Bethesda Terrace,
precisely at 2 PM, to capture the essence of the storyline under the
gentle afternoon sun. To ensure a timely start, Brad will be picked up
from The Ritz-Carlton, New York, at 12:30 PM. This will allow for a smooth
journey, factoring in city traffic and any last-minute preparations needed
upon arrival. Please confirm that all necessary equipment and personnel
are on-site and ready by 1 PM, to fully utilize the natural light and
setting of the location.
"""
The text flows like a narrative, and the entity details are integrated naturally within the content. From these messages, our desired format is something like this:
desired_output = {
"actor_name": "Brad Pitt",
"actor_pickup_location": "The Ritz-Carlton, New York",
"scene_location": "Central Park's Bethesda Terrace",
"scene_time": "2 PM"
}
Alright, we now need to design prompt templates based on these requirements.
template = """
From the following text message, extract the following information:
actor_name: This refers to the name of the actor involved in the film scene.
It's essential for identifying which actor the logistical details pertain to.
actor_pickup_location: This is the location where the actor will be picked up or collected from before the shoot.
scene_location: This is the actual location where the scene will be filmed.
scene_time: This denotes the scheduled time when the scene is set to be shot.
Format the output as JSON with the following keys:
actor_name
actor_pickup_location
scene_location
scene_time
If there are more than one for each key, put then in square brackets
like '["Brad Pitt", "Angelina Jolie"]'
text message: {text}
"""
from langchain.prompts import ChatPromptTemplate
prompt_template = ChatPromptTemplate.from_template(template)
print(prompt_template)
"""
input_variables=['text'] messages=[HumanMessagePromptTemplate(prompt=
PromptTemplate(input_variables=['text'], template='\nFrom the following
text message, extract the following information:\n\nactor_name: This
refers to the name of the actor involved in the film scene. \nIt\'s
essential for identifying which actor the logistical details pertain
to.\n\nactor_pickup_location: This is the location where the actor
will be picked up or collected from before the shoot.\n\nscene_location:
This is the actual location where the scene will be filmed. \n\nscene_time:
This denotes the scheduled time when the scene is set to be shot.\n\nFormat
the output as JSON with the following
keys:\nactor_name\nactor_pickup_location\nscene_location\nscene_time\n\n
If there are more than one for each key, put then in square brackets like
\'["Brad Pitt", "Angelina Jolie"]\'\n\ntext message: {text}\n'))]
"""
messages = prompt_template.format_messages(text=text)
response = chat(messages)
print(response.content)
"""
{
"actor_name": "Brad Pitt",
"actor_pickup_location": "The Ritz-Carlton, New York",
"scene_location": "Central Park's Bethesda Terrace",
"scene_time": "2 PM"
}
"""
We have received the necessary information. However, in this instance, we manually specified the desired output format to the system. This is problematic.
Manual formatting can introduce errors due to inconsistencies or typos. This is a huge problem, especially for automated systems. Parsers apply structured rules to ensure accurate and consistent data extraction.
Parser Types
There are numerous types of parsers for specific purposes in LangChain.
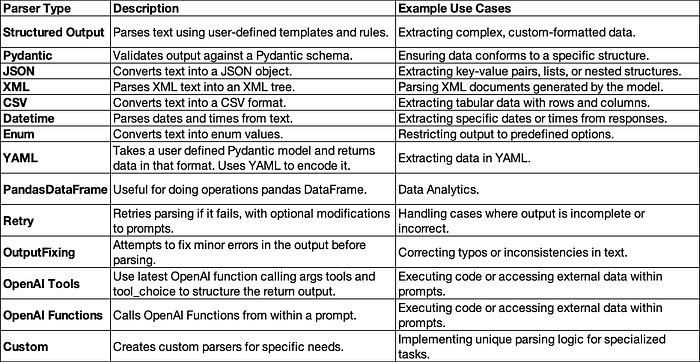
Structured
A structured output parser is designed to extract and structure information from unstructured or semi-structured text. This is suitable for scenarios requiring the extraction of multiple fields. Although the Pydantic (explained below) parser offers more robust capabilities, this parser is advantageous for use with simpler models.
from langchain.output_parsers import ResponseSchema
from langchain.output_parsers import StructuredOutputParser
actor_name_schema = ResponseSchema(name="actor_name",
description="This refers to the name of the actor involved in the film scene.")
actor_pickup_location_schema = ResponseSchema(name="actor_pickup_location",
description="This is the location where the actor will be picked up or collected from before the shoot.")
scene_location_schema = ResponseSchema(name="scene_location",
description="This is the actual location where the scene will be filmed.")
scene_time_schema = ResponseSchema(name="scene_time",
description="This denotes the scheduled time when the scene is set to be shot.")
response_schema = [
actor_name_schema,
actor_pickup_location_schema,
scene_location_schema,
scene_time_schema
]
ResponseSchema class is for defining the structure of expected output data. StructuredOutputParser class is for parsing text based on a defined schema.
Then, we create schemas for each field that we want to extract. We define each’s name and description.
output_parser = StructuredOutputParser.from_response_schemas(response_schema)
format_instructions = output_parser.get_format_instructions()
print(format_instructions)
"""
The output should be a markdown code snippet formatted in the
following schema, including the leading and trailing "```json" and "```":
` ` `json
{
"actor_name": string // This refers to the name of the actor involved in the film scene.
"actor_pickup_location": string // This is the location where the actor will be picked up or collected from before the shoot.
"scene_location": string // This is the actual location where the scene will be filmed.
"scene_time": string // This denotes the scheduled time when the scene is set to be shot.
}
` ` `
"""
After creating the output_parser, get_format_instructions() method calls on the parser. This method is likely designed to provide instructions or a template on how the parser expects the input data to be formatted, or how it will format the extracted data.
Now, we need to revise our template:
template = """
From the following text message, extract the following information:
text message: {text}
{format_instructions}
"""
prompt_template = ChatPromptTemplate.from_template(template)
messages = prompt_template.format_messages(text=text, format_instructions=format_instructions)
response = chat(messages)
print(response.content)
print(type(response.content))
"""
` ` `json
{
"actor_name": "Brad Pitt",
"actor_pickup_location": "The Ritz-Carlton, New York",
"scene_location": "Central Park's Bethesda Terrace",
"scene_time": "2 PM"
}
` ` `
<class 'str'>
"""
# convert string to python dictionary
output_dict= output_parser.parse(response.content)
print(output_dict)
print(type(output_dict))
"""
{'actor_name': 'Brad Pitt', 'actor_pickup_location': 'The Ritz-Carlton, New York', 'scene_location': "Central Park's Bethesda Terrace", 'scene_time': '2 PM'}
<class 'dict'>
"""
Pydantic
Pydantic is a data validation and settings management library for Python. It is designed to ensure that the data you work with adhere to specific formats and types, making your code more robust and maintainable.
Pydantic Parser leverages Pydantic models to validate and structure model output.
First, we will define a data class using Pydantic.
from datetime import datetime
from pydantic import BaseModel, Field, field_validator
class SceneInfo(BaseModel):
actor_name: str = Field(description="This refers to the name of the actor involved in the film scene.")
actor_pickup_location: str = Field(description="This is the location where the actor will be picked up or collected \
from before the shoot.")
scene_location: str = Field(description="This is the actual location where the scene will be filmed.")
scene_time: str = Field(description="This denotes the scheduled time when the scene is set to be shot.")
@field_validator('actor_name')
def validate_actor_name(cls, value):
if not value.strip():
raise ValueError("Actor name must not be empty.")
return value
@field_validator('actor_pickup_location')
def validate_actor_pickup_location(cls, value):
if not value.strip():
raise ValueError("Actor pickup location must not be empty.")
return value
@field_validator('scene_location')
def validate_scene_location(cls, value):
if not value.strip():
raise ValueError("Scene location must not be empty.")
return value
@field_validator('scene_time')
def validate_scene_time(cls, value):
try:
# Assuming the time is in a format like '2 PM'
datetime.strptime(value, '%I %p')
except ValueError:
raise ValueError("Scene time must be in a valid format (e.g., '2 PM').")
return value
SceneInfo class is a Pydantic model. For each field, we created custom validators (optional).
Next, let’s create Pydantic parser.
from langchain.output_parsers import PydanticOutputParser
pydantic_parser = PydanticOutputParser(pydantic_object=SceneInfo)
format_instructions = pydantic_parser.get_format_instructions()
print(format_instructions)
"""
The output should be formatted as a JSON instance that conforms to the JSON schema below.
As an example, for the schema {"properties": {"foo": {"title": "Foo", "description": "a list of strings", "type": "array", "items": {"type": "string"}}}, "required": ["foo"]}
the object {"foo": ["bar", "baz"]} is a well-formatted instance of the schema. The object {"properties": {"foo": ["bar", "baz"]}} is not well-formatted.
Here is the output schema:
` ` `
{"properties": {"actor_name": {"description": "This refers to the name of the actor involved in the film scene.", "title": "Actor Name", "type": "string"}, "actor_pickup_location": {"description": "This is the location where the actor will be picked up or collected from before the shoot.", "title": "Actor Pickup Location", "type": "string"}, "scene_location": {"description": "This is the actual location where the scene will be filmed.", "title": "Scene Location", "type": "string"}, "scene_time": {"description": "This denotes the scheduled time when the scene is set to be shot.", "title": "Scene Time", "type": "string"}}, "required": ["actor_name", "actor_pickup_location", "scene_location", "scene_time"]}
` ` `
"""
template = """
From the following text message, extract the following information:
text message: {text}
{format_instructions}
"""
prompt_template = ChatPromptTemplate.from_template(template)
messages = prompt_template.format_messages(text=text, format_instructions=format_instructions)
response = chat(messages)
print(response.content)
print(type(response.content))
"""
The JSON instance that conforms to the given JSON schema is:
` ` `
{
"actor_name": "Brad Pitt",
"actor_pickup_location": "The Ritz-Carlton, New York",
"scene_location": "Central Park's Bethesda Terrace",
"scene_time": "2 PM"
}
` ` `
<class 'str'>
"""
output_dict= pydantic_parser.parse(response.content)
print(output_dict)
print(type(output_dict))
"""
actor_name='Brad Pitt' actor_pickup_location='The Ritz-Carlton, New York' scene_location="Central Park's Bethesda Terrace" scene_time='2 PM'
<class '__main__.SceneInfo'>
"""
In the end, we obtained the result as a SceneInfo instance.
JSON
Attention! For the JsonOutputParser (as well as other types of parsers), we should utilize langchain_core.pydantic_v1 as the foundation for our Pydantic classes.
from langchain_core.output_parsers import JsonOutputParser
from langchain_core.pydantic_v1 import BaseModel, Field
class SceneInfo(BaseModel):
actor_name: str = Field(description="This refers to the name of the actor involved in the film scene.")
actor_pickup_location: str = Field(description="This is the location where the actor will be picked up or collected \
from before the shoot.")
scene_location: str = Field(description="This is the actual location where the scene will be filmed.")
scene_time: str = Field(description="This denotes the scheduled time when the scene is set to be shot.")
parser = JsonOutputParser(pydantic_object=SceneInfo)
format_instructions = parser.get_format_instructions()
template = """
From the following text message, extract the following information:
text message: {text}
{format_instructions}
"""
prompt_template = ChatPromptTemplate.from_template(template)
messages = prompt_template.format_messages(text=text, format_instructions=format_instructions)
response = chat(messages)
print(response.content)
print(type(response.content))
"""
The JSON instance that conforms to the given JSON schema is:
` ` `
{
"actor_name": "Brad Pitt",
"actor_pickup_location": "The Ritz-Carlton, New York",
"scene_location": "Central Park's Bethesda Terrace",
"scene_time": "2 PM"
}
` ` `
<class 'str'>
"""
output_dict= parser.parse(response.content)
print(output_dict)
print(type(output_dict))
"""
{'actor_name': 'Brad Pitt', 'actor_pickup_location': 'The Ritz-Carlton, New York', 'scene_location': "Central Park's Bethesda Terrace", 'scene_time': '2 PM'}
<class 'dict'>
"""
CSV
from langchain.output_parsers import CommaSeparatedListOutputParser
output_parser = CommaSeparatedListOutputParser()
format_instructions = output_parser.get_format_instructions()
messages = prompt_template.format_messages(text=text, format_instructions=format_instructions)
response = chat(messages)
print(response.content)
print(type(response.content))
"""
Tomorrow, shoot, pivotal scene, Brad Pitt, Central Park's Bethesda Terrace, 2 PM, The Ritz-Carlton, New York, 12:30 PM, equipment and personnel, 1 PM
<class 'str'>
"""
output_dict= output_parser.parse(response.content)
print(output_dict)
print(type(output_dict))
"""
['Tomorrow', 'shoot', 'pivotal scene', 'Brad Pitt', "Central Park's Bethesda Terrace", '2 PM', 'The Ritz-Carlton', 'New York', '12:30 PM', 'equipment and personnel', '1 PM']
<class 'list'>
"""
You can find comprehensive information about all the output parsers in the documentation. For now, in our LangChain series, we’ll conclude our discussion on output parsers here. However, in future chapters, we will certainly revisit and utilize the other parsers.
Next:
LangChain in Chains #8: Build a Personal Stylist Assistant
Read More
LangChain in Chains #1: A Closer Look
Exploring Hugging Face: Text Generation
VAR: Vector Auto-Regressive Model in Time Series
Data Classes, Abstraction & Interfaces in Python
Functional Programming Characteristics
Comments
Loading comments…