
Recently, Meta introduced Llama-3, a family of state-of-the-art open-access LLMs. It is now available for broad use, featuring pre-trained and instruction-fine-tuned language models with 8B and 70B parameters. It demonstrates state-of-the-art performance on industry benchmarks and offers improved reasoning. The community is encouraged to contribute to AI innovation across applications, developer tools, evaluations, and inference optimizations.
In this blog, I will:
- Introduction to Llama-3: we will have a look about Llama-3
- Code implementation: we quantize the 8B-Llama3 model.
- Conclusion.
Introduction to Llama-3
Llama-3 was published recently, on April 18, 2024. It is now ready for widespread use, with pre-trained and instruction-fine-tuned language models with 8B and 70B characteristics. It outperforms industry benchmarks and provides superior reasoning.
Meta announces that Llama 3 models will soon be available on AWS, Databricks, Google Cloud, Hugging Face, Kaggle, IBM WatsonX, Microsoft Azure, NVIDIA NIM, and Snowflake, and with support from hardware platforms offered by AMD, AWS, Dell, Intel, NVIDIA, and Qualcomm.
In keeping with their longtime open approach, Meta is putting Llama 3 in the hands of the community. Meta intends to ignite the next wave of innovation in AI across the stack—from apps to developer tools, evaluations to inference optimizations, and more.

Llama 3 models, developed for 8B and 70B parameter scales, offer enhanced pre-training and post-training procedures, reduced false refusal rates, improved alignment, and increased model diversity.
Meta introduces Meta Llama 3, the newest in their line of open-source big language models, which includes 8B and 70B parameter models:
- Llama 3 uses a standard decoder-only transformer architecture, with improvements in model performance and language encoding efficiency.
- It uses a 128K tokenizer and grouped query attention for inference efficiency, training on sequences of 8,192 tokens.
- The Llama 3 language model uses a large pre-training dataset of over 15T tokens, seven times larger than Llama 2, with four times more code and over 5% non-English content.
- Llama 3 models optimize pre-training data and make informed decisions on training computation. (They have scaling laws for benchmark evaluations and improved performance even after training on more data. The largest models use data parallelization, model parallelization, and pipeline parallelization for efficient training.)
- Meta enhances chat model performance through supervised fine-tuning, rejection sampling, proximal policy optimization (PPO), and direct preference optimization (DPO), enhancing Llama 3’s reasoning and coding tasks through PPO and DPO learning.
Note: Meta provided performance comparisons between Llama-3 and Mistral, Gemma, Gemini, and GPT-3.5. However, the comparison between Llama-3 and GPT-4 is what I expect.
Meta now looks at Llama with ambition. By that I mean, Llama 3 models are designed for industry-leading use and deployment, using a novel system-level approach. They are part of a larger system, allowing developers to control and achieve specific end goals.
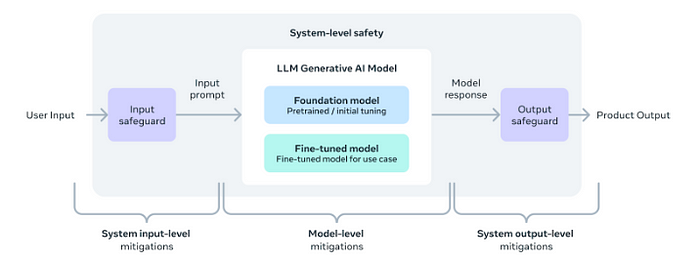
Meta have taken a novel, system-level approach to the responsible development and deployment of Llama. They envision Llama models as part of a larger system that puts the developer in control. Llama models will serve as the core of a system designed by developers with their specific end goals in mind.
Llama-3 is still under development. Meta guarantees that many intriguing things will occur shortly. A model with over 400 billion parameters is at the top of the list. In addition, they plan to produce several models with new features like multi-modality, the ability to talk in several languages, a much longer context window, and stronger overall capabilities. Furthermore, once they have completed training Llama 3, they plan to publish a full research article.
Code implementation
Keep in mind that quantization approaches save memory and computing resources by encoding weights and activations as lower-precision data types, such as 8-bit integers (int8). This allows for the loading of larger models that would otherwise be too huge to fit in memory, hence speeding up inference.
Transformers supports the AWQ and GPTQ quantization algorithms and it supports 8-bit and 4-bit quantization with bitsandbytes.
Before we begin, I’d like to point out that Llama3’s model cards require access to be used, so we must request permission before using them (on HuggingFace).
After we are granted to use. We are ready to go.
I used libraries that are provided by huggingface , which include:
!pip install -q -U accelerate \
optimum \
auto-gptq
Give access to HuggingFace via:
from huggingface_hub import login
login()
The basic way to load a model in 4bit is to pass the argument load_in_4bit=True when calling the from_pretrained method by providing a device map (pass "auto" to get a device map that will be automatically inferred).
Quantize with BitsandBytes
Bitsandbytes is the easiest way to quantize any model, as it doesn’t require calibration or post-processing. It works with any model, as long as it contains `torch.nn.Linear``modules. It’s also cross-modality interoperable, allowing users to load models like Whisper, ViT, and Blip2 in 8-bit or 4-bit without any post-processing or preparation steps.
We can use different variants of 4bit quantization, such as NF4 or pure FP4, are recommended for better performance. Other options include bnb_4bit_use_double_quant and compute type. A 16-bit compute dtype (default torch.float32) is faster for matrix multiplication and training.
To do so, we type:
from transformers import BitsAndBytesConfig
nf4_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_use_double_quant=True,
bnb_4bit_compute_dtype=torch.bfloat16
)
model_nf4 = AutoModelForCausalLM.from_pretrained(model_id,
quantization_config=nf4_config)
Quantize with optimum
Optimum is an AI extension that optimizes performance for training and running models on targeted hardware, allowing developers, like us, to use various platforms with ease as the AI ecosystem evolves rapidly with new hardware and optimizations.
In this experiment, we perform 4-bit GPTQ quantization on Llama–3–8B model.
Note: I tried to run the experiment on Colab, but it failed all the time. So I switched to Kaggle, and it worked perfectly.
The GPTQuantizer is in need to setup for the quantization configuration. It consists of:
- bits: the bits they we want the model to be quantized.
- dataset: used to calibrate the quantization.
- model_seqlen: the model sequence length used to process the dataset.
from optimum.gptq import GPTQQuantizer
dataset_id = "wikitext2"
quantizer = GPTQQuantizer(bits=4, dataset=dataset_id, model_seqlen=2048)
quantizer.quant_method = "gptq"
We call the model and set the quantizer to the model’s config. Remember that we need to be granted to use the model.
model_id = "meta-llama/Meta-Llama-3-8B"
# tokenizer = AutoTokenizer.from_pretrained(model_id)
plan_model = AutoModelForCausalLM.from_pretrained(model_id,
config=quantizer,
torch_dtype=torch.float16,
low_cpu_mem_usage=True)
At this stage, we just need to quantize the model using the following lines of code:
gptq_model = quantizer.quantize_model(plan_model, tokenizer)
gptq_model
Now, the model is quantized. We can push the model to our HuggingFace account by:
# Remember to change your hf username
gptq_model.push_to_hub("OctoOptLab/Meta-llama-3-8B-GPTQ")
Conclusion
In this piece, we are provided an overview of Llama-3, a family of cutting-edge open-access LLM. It outperforms industry benchmarks and provides superior reasoning. In addition, we quantize the model with bitsandbytesand optimumthe library using the GPTQ approach. We will use our knowledge in the future. Stay tuned!
Thank you for reading this article; I hope it added something to your knowledge bank! Just before you leave:
👉 Be sure to clap and follow me. It would be a great motivation for me.
👉 Follow me: Linkedin | Github
Reference:
- Meta — Introducing Meta Llama 3: The most capable openly available LLM to date — URL: https://ai.meta.com/blog/meta-llama-3/
- HuggingFace — Quantization (AutoGPTQ Integration) — URL: https://huggingface.co/docs/optimum/llm_quantization/usage_guides/quantization
- HuggingFace — Quantization (docs)— URL: https://huggingface.co/docs/transformers/main_classes/quantization#quantization
- Frantar et al. — GPTQ: Accurate Post-Training Quantization for Generative Pre-trained Transformers — URL: https://arxiv.org/abs/2210.17323
- Belkada et al. — Overview of natively supported quantization schemes in 🤗 Transformers — URL: https://huggingface.co/blog/overview-quantization-transformers
- Belkada et al. — Making LLMs even more accessible with bitsandbytes, 4-bit quantization and QLoRA — URL: https://huggingface.co/blog/4bit-transformers-bitsandbytes
Comments
Loading comments…