Time-series Pile data splits:

Pre-training large models on time-series data is challenging because of the absence of a large and cohesive public time-series repository. To address these challenges, MOMENT team compiled a large and diverse collection of public time-series, called the Time-series Pile to unlock large-scale multi-dataset pre-training. The code is publicly available at anonymous:
https://anonymous.4open.science/r/BETT-773F/README.md
Time-series analysis spans across a wide array of applications, from weather forecasting to health monitoring via electrocardiograms.
In this sense, MOMENT is:
- The first family of open-source, large pre-trained time-series models.
- Designed to serve foundational roles across various time-series analysis tasks: forecasting, classification, anomaly detection, and imputation.
- Includes high-capacity transformer models, pre-trained on diverse datasets via a masked time-series prediction task.
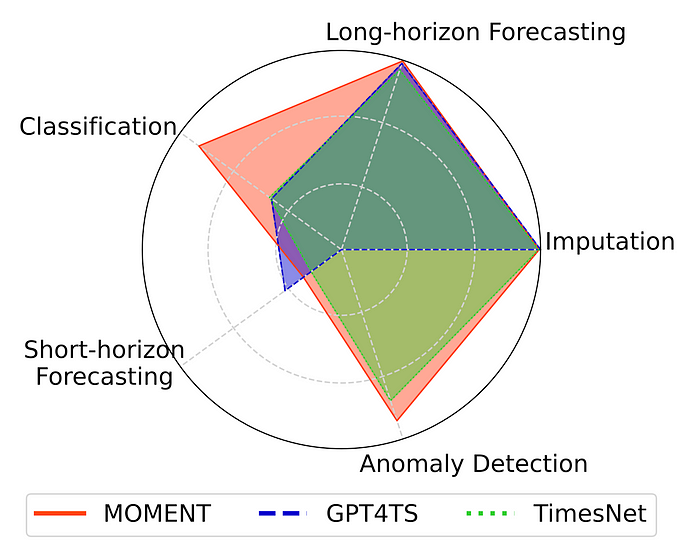
MOMENT can solve multiple time-series analysis tasks:
Background and Insights
Transformers have gained momentum in time-series tasks, but the self-attention mechanism introduces challenges, especially as complexity scales with input size. MOMENT leverages masked pre-training, a self-supervised learning approach, where models learn to reconstruct masked sections of their input. This technique is particularly suited to forecasting and imputation tasks, effectively predicting missing or future data points.
Adapting Language Models for Time-Series
MOMENT explores how to adapt large language models (LLMs) for time-series analysis through:
- Cross-Modality Modeling: Time-series transformers can model sequences across various modalities.
- Random Initialization Benefits: Starting with random weights is more effective than using language model weights.
- Superior Time-Series Pre-Training: Directly pre-trained models outperform LLM-based models across tasks and datasets.
Architectural Foundations of MOMENT
Overview of MOMENT architecture:
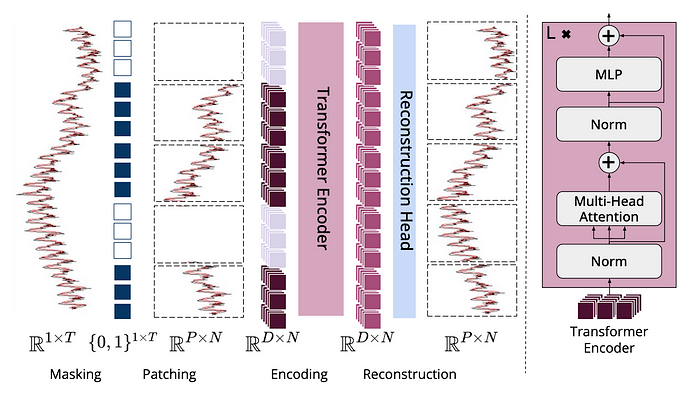
A time-series is broken into disjoint fixed-length sub-sequences called patches, and each patch is mapped into a D-dimensional patch embedding. During pre-training, patches are masked uniformly at random by replacing their patch embeddings using a special mask embedding [MASK]. The goal of pre-training is to learn patch embeddings which can be used to reconstruct the input time-series using a light-weight reconstruction head.
1- Design Enhancements
- Retains and refines original Transformer architecture.
- Key modifications: Adjusted Layer Norm placement, removed additive bias, and included relational positional embedding.
2- Handling Time-Series Variability
- Standardized input length: Adapts longer and shorter series to fit a fixed length.
- Independent channel modeling: Effective for multivariate time-series analysis.
Broad Applications of MOMENT
MOMENT demonstrates flexibility across:
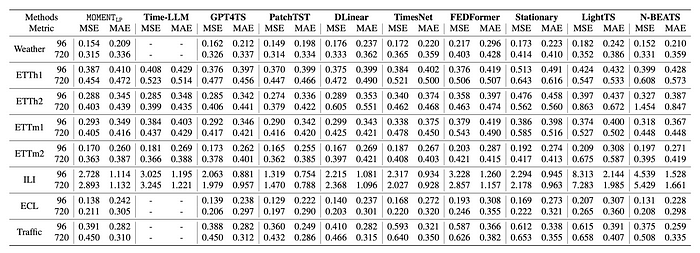
- Forecasting: Achieves near state-of-the-art in long-horizon forecasting; identifies improvement opportunities in zero-shot short-horizon forecasting.
Long-term forecasting performance:
- Classification: Excels without task-specific fine-tuning.
- Anomaly Detection: Outperforms on multiple datasets.
- Imputation: Achieves lowest reconstruction error with linear probing.
Core Learning from MOMENT
1- Characteristics Capturing:
- Principal components of the embeddings of synthetically generated sinusoids suggest that MOMENT can capture subtle trend, scale, frequency, and phase information.
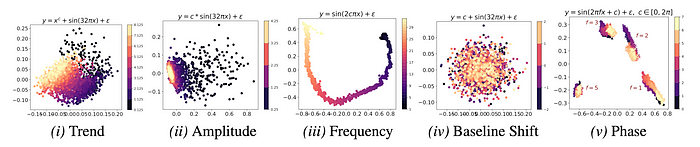
2- Representation Learning:
- Distinguishes distinct representations for different classes, even without labels.
3- Advancements Through Large Time-Series Models
- Model Scaling: Larger models correlate with improved training efficiency.
- Cross-Modal Learning: Competes with models like GPT-2 and Flan-T5 in sequence learning tasks.
- Random Initialization: Leads to lower training losses compared to language model weight initialization.
Conclusion
Utilizing the Time-series Pile for pre-training transformer models of varied sizes, MOMENT sets a new standard for minimal fine-tuning requirements and superior performance in tasks, especially in anomaly detection and classification. This shows MOMENT’s impact on time-series analysis, surpassing traditional statistical methods.
Read the paper at:
MOMENT: A Family of Open Time-series Foundation Models
For more information and to explore how my data science consulting services can benefit your company, please visit my website at samuelchazy.com
Explore my LLM website, offering a unique opportunity to interact with and analyze any document: https://gptdocanalyzer.com/
Comments
Loading comments…