
Let's say you're a seasoned developer working on an automated data-gathering project using a Python-based web scraping library. You've fine-tuned your scraper to efficiently navigate through target websites and systematically collect the information you need. Everything is running smoothly as you anticipate the insights you'll be able to derive from the data collected when the whole process comes to an abrupt and screeching halt thanks to the website throwing up...a CAPTCHA.
CAPTCHAs are security measures implemented by websites to distinguish between legitimate human users and bots/web scrapers. We all know what they usually look like - mini-challenges involving letters, numbers, or images that we have to solve to gain further access to the website. Since these challenges are usually designed to be visually interactive, when your web scraper encounters a CAPTCHA, it gets stuck bringing the whole automated scraping process to a standstill.
A number of factors can lead to a website detecting a scraper and throwing up a CAPTCHA.
- Websites may use browser/device fingerprinting to spot scrapers/bots. By analyzing attributes like screen resolution, fonts, and plugins, as well as information regarding the configuration of a user's browser and software/hardware environment, a unique fingerprint is created. When a scraper's fingerprint is flagged as non-human, a CAPTCHA is triggered to confirm the user's identity.
- Scrapers often have identifiable User-Agent strings, making them easily noticeable. Uncommon or suspicious User-Agents can trigger a CAPTCHA to confirm legitimacy.
- Cookies track users and bots. Improper cookie management or missing session data can result in a CAPTCHA to prove user authenticity.
- Modern CAPTCHAs like ReCaptcha analyze mouse and click behavior. Predictable bot movements lead to CAPTCHA challenges.
CAPTCHAs pose a significant challenge for large-scale automated web scraping. Manual integration of CAPTCHA-bypass logic can quickly get messy. Not only do you have to incorporate complex algorithms into your code but also make ongoing adjustments to account for the website's evolving CAPTCHA mechanisms. Common solutions involve proxies but these require additional infrastructure and are often not 100% reliable.
Effectively bypassing CAPTCHAs requires emulating human-like behavior to effectively circumvent CAPTCHA challenges. In this article, we'll take a look at five tools which are able to do just that, and more. Whether you're a seasoned web scraping developer or a beginner, these tools will help ensure you're able to bypass CAPTCHAs effectively and that your data collection process remains smooth and uninterrupted at scale.
1. Bright Data's Scraping Browser
Unlike the other items on this list, the Scraping Browser is an all-in-one comprehensive solution that combines the convenience of a real, automated browser with Bright Data's powerful unlocker infrastructure and proxy management services. It's also fully compatible with Puppeteer/Playwright/Selenium APIs.
With the Scraping Browser, there is no need for you to handle numerous third-party libraries that deal with tasks such as proxy and fingerprint management, IP rotation, automated retries, logging, or CAPTCHA solving internally. The Scraping Browser takes care of all this and more on Bright Data's server-side infrastructure.
If you're wondering how, this is because the Scraping Browser comes built-in with Bright Data's powerful unlocker infrastructure, which means it arrives with CAPTCHA-bypassing technology right out of the box, no additional measures needed on your part.
It's this unlocker infrastructure that allows you to sail through CAPTCHAs without breaking a sweat. The web unlocker technology:
- Enables near-perfect emulation of browser fingerprint information including plugins, fonts, browser version, cookies, HTML5 canvas element or WebGL fingerprint, Web Audio API fingerprint, operating system, screen resolution, and more. Having this aspect down pat solves the issue at its root and not just a derivative 'symptom' like 'reCaptcha'.
- Automatically configures relevant header information (such as User-Agent strings) and manages cookies according to the requirements of the target website so that you can avoid getting detected and blocked as a "crawler".
- Mimics all devices connected to any given system, including their corresponding drivers, mouse movements, screen resolution, and other device properties, achieving full device enumeration imitation.
- Efficiently handles HTTP header management both during the process of decoding (when the request is received) and encoding (when the response is sent).
- Seamlessly upgrades HTTP protocols with ease and rotates TLS/SSL fingerprinting so that the protocol versions making the requests match that of your browser's header and your requests appear genuine.
- Can solve reCAPTCHA, hCaptcha, px_captcha, SimpleCaptcha, and GeeTest CAPTCHA, and it is constantly updated to deal with websites that discover new ways to detect your scraping efforts.
- Is a managed service, meaning that you don't have to worry about updating your code to keep up with a website's ever-changing CAPTCHA-generation mechanisms. Bright Data takes care of all of that for you, handling the updates and maintenance on their end.
💡 From CAPTCHA-solving to User-agent generation to cookie management and fingerprint emulation, the unlocker infrastructure can bypass even the most sophisticated anti-scraping measures, ensuring a smooth and uninterrupted scraping process. Learn more here.
In addition to that, the Scraping Browser also makes use of Bright Data's premium proxy network which offers four different types of proxy services - datacenter, residential, ISP, and mobile. You can pick whichever suits your use case or take advantage of the 'waterfall feature' in which requests are routed through different proxy networks using customized and automated rules.
The Scraping Browser is extremely simple to set up and integrate into your existing Playwright/Puppeteer/Selenium scripts:
- Before you write any scraping code, you use Puppeteer/Playwright/Selenium to connect to Bright Data's Scraping Browser using your credentials, via Websockets.
- From then on, all you have to worry about is developing your scraper using the standard Puppeteer/Playwright/Selenium libraries, and nothing more.
The Scraping Browser comes with a free trial and you can look up the documentation for further instructions to get started.
Scraping Browser - Build Unblockable Scrapers with Puppeteer, Playwright and Selenium
2. The Puppeteer Extra Stealth NPM Plugin
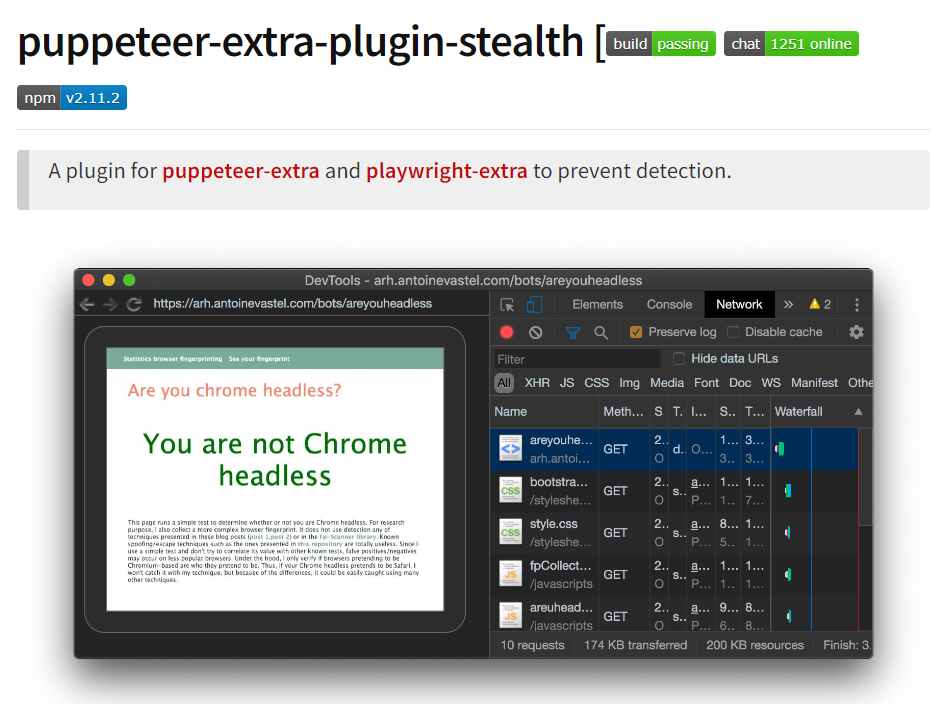
Websites have become increasingly adept at detecting headless browsers, such as Puppeteer, through identifying markers like the HeadlessChrome user-agent addition. The Puppeteer Extra Stealth NPM Plugin is an essential component of the Puppeteer Extra ecosystem, an extended library built around the popular headless browser Puppeteer.
Developed to overcome the restrictions posed by CAPTCHAs and anti-bot measures, this plugin offers developers an effective means of navigating through security mechanisms while remaining undetected.
The Puppeteer Stealth NPM Plugin **counters browser fingerprinting by masking default headless properties **--- such as headless: true, navigator.webdriver: true, and request headers - ultimately ensuring an anonymous and undetected browsing experience.
At the core of the Puppeteer Stealth NPM Plugin's efficiency lies its modular design.
Leveraging Puppeteer-extra's dependency system, the plugin introduces evasions only when activated, ensuring a streamlined and efficient experience. This approach not only enhances modularity but also facilitates quick testing and iterations, providing developers with the freedom to fine-tune their automation efforts.
The primary objective of the Puppeteer Stealth NPM Plugin is to seamlessly integrate with Puppeteer, providing an intelligent and dynamic approach to evading detection mechanisms.
The Puppeteer Stealth NPM Plugin offers two integration approaches:
- It includes a convenient wrapper that automatically employs multiple evasion techniques while adhering to default settings.
- For those seeking more granular control, the plugin can be used to selectively include specific evasion plugins, capitalizing on the standalone nature of Puppeteer-extra plugins.
puppeteer-extra-plugin-stealth
3. The Puppeteer Extra ReCaptcha NPM Plugin
Just like the previously-mentioned Stealth plugin, the reCaptcha plugin is another component of the Puppeteer Extra ecosystem which seamlessly tackles hCAPTCHAs and reCAPTCHAs, eliminating the manual intervention required for solving these security measures. It provides a page.solveRecaptchas() method that does everything needed for bypassing reCAPTCHAs and hcaptchas in web scraping.
This plugin requires a solution provider to do its work. It comes with a built-in 2Captcha provider and all you have to do is provide the plugin with your 2captcha token and ensure that you have sufficient funds in your 2Captcha account.
It's worth mentioning that you can use a solution provider of your choice by providing the plugin a function instead of your 2Captcha token (check the API docs for more details) or, you may simply stick to the built-in 2Captcha provider as it's a relatively cheap solution.
How does the plugin work?
- reCAPTCHAs use a sitekey that's specific to the site. An external solution provider is given this sitekey and the site URL, which then solves the challenge and responds with a response token. The response token after solving a challenge is not tied to a specific session or IP and can be passed on to others until they expire.
- When called with
page.solveRecaptchas(), the plugin automatically detects any active reCAPTCHAs and hCaptchas, extracts their configuration and the sitekey, passes those on to the specified solutions provider, and puts the solution back into the page to trigger any callback (form-submission, navigation to a new page, etc.) that the site owner might have specified.
Even if you call the method when the captcha isn't visible on the page, the plugin will wait till it comes on the screen, solving it once it appears. And for pages with no captchas, the page.solveRecaptchas() method will simply resolve the promise and the rest of the code will execute normally without any fuss.
The plugin can also be used to circumvent invisible reCAPTCHAs, which are basically used to determine the likelihood of a user being a bot. This is done by assigning a score to the user and based on that score the site owner can present the user with a reCAPTCHA challenge which this plugin automatically solves. Calling the page.solveRecaptchas() method automatically solves all these captchas, including multiple occurrences of them for a given site.
While the plugin supports all reCAPTCHAs and hcaptchas such as reCAPTCHA v2, reCAPTCHA v3, invisible reCAPTCHA, hCaptcha, and invisible hCaptcha, the only caveat is that it doesn't cover all kinds of CAPTCHAs.
That being said, the plugin is a well-maintained and battle-tested tool that also makes for a cost-effective solution for bypassing captchas.
puppeteer-extra-plugin-recaptcha
4. GoodByeCaptcha
GoodByeCaptcha is an async Python library designed to simplify and automate the process of solving ReCAPTCHA v2 challenges. The library is designed to specifically tackle ReCAPTCHA v2 challenges that involve images and audio, utilizing a diverse range of speech recognition APIs including Mozilla's DeepSpeech, PocketSphinx, Microsoft Azure's, Wit.AI, Google Speech, and Amazon's Transcribe Speech-to-Text API. This broad spectrum of options ensures a high success rate in deciphering audio-based CAPTCHAs.
Beyond audio challenges, GoodByeCaptcha excels in image-based CAPTCHAs as well. The library is equipped with image recognition capabilities, allowing it to accurately identify objects depicted in the CAPTCHA images. This feature adds an extra layer of versatility to the tool's arsenal, making it an even more formidable opponent against image-based CAPTCHAs.
How does GoodByeCaptcha work?
- The library harnesses the power of Puppeteer, a Chrome automation framework that closely resembles Puppeteer. This foundation enables GoodByeCaptcha to seamlessly interact with the browser, simulating human-like actions and interactions.
- To facilitate audio processing, the library integrates PyDub, a handy utility for effortlessly converting MP3 files into the WAV format. This capability streamlines the handling of audio-based CAPTCHA challenges, ensuring compatibility with various recognition APIs.
- The asynchronous nature of GoodByeCaptcha's architecture is built upon the foundation of aiohttp and Python's built-in AsyncIO. This combination empowers the library to perform its tasks efficiently and concurrently, minimizing delays and providing users with swift results.
All in all, GoodBye Captcha's incorporation of diverse speech recognition APIs, image recognition, and well-established Python technologies makes it a valuable asset for developers and researchers aiming to enhance CAPTCHA-solving efficiency.
GitHub - MacKey-255/GoodByeCatpcha: An asynchronized Python library to automate solving ReCAPTCHA...
5. 2Captcha
When it comes to bypassing CAPTCHAs for web scraping, one of the most well-known tools in the market is 2Captcha, providing solutions for reCAPTCHA V2, hCaptcha, reCAPTCHA V3, FunCaptcha, audio recognition, and more. It provides a crowd-powered approach to solving CAPTCHAs, offering APIs that allow you to seamlessly integrate its CAPTCHA-solving service into your web scraping scripts or applications, enabling you to automate the entire process.
To learn more about 2Captcha's seamless integration into web scraping scripts, check out this video.
How 2Captcha works:
- **Step 1: Sign up to obtain the API Key **To access 2Captcha's services, you'll need an API key, obtainable upon signing up.
- **Step 2: Uploading the CAPTCHA **When you encounter a CAPTCHA while scraping data from a website, you can submit the CAPTCHA image to 2captcha.com/in.php.
- **Step 3: Generating a Unique ID **Upon receiving your CAPTCHA, the server securely stores the image and generates a unique identification code, known as the CAPTCHA ID.
- **Step 4: Distribution to a Worker **Once the CAPTCHA ID is generated, 2Captcha's server promptly assigns the task to a human employee.
- **Step 5: Solving and Answer Submission **The assigned employee takes on the CAPTCHA challenge and promptly submits it back to 2Captcha's server once the solution is derived.
- **Step 6: Retrieving the Answer **You can now send a request to the server using your CAPTCHA ID to retrieve the solution.
One of the major advantages of 2Captcha is that it's a human-based CAPTCHA solver and being so it can bypass any kind of CAPTCHA verification. It's also easy to integrate into scraping scripts, supporting programming languages such as Python, PHP, Ruby, Go, C#, and Java.
When it comes to pricing, this tool can prove to be a cost-effective solution. Its price starts from 1$ per 1000 CAPTCHAs, charging only for solved CAPTCHAs, with server load not being a factor in price calculations.
Hence, if you're looking for a tool solely for solving CAPTCHAs, 2Captcha might be an ideal pick. But beyond solving CAPTCHAs, it does not offer any additional capabilities such as automated IP Rotation, vast proxy networks, etc. that other advanced web scraping solutions offer.
Conclusion
Wrapping up, while it makes sense for websites to use security mechanisms to prevent exploitation of their data, CAPTCHAs can also pose a significant challenge for legitimate web scraping projects, especially large-scale ones which rely on fresh, accurate, and uninterrupted data collection. Whether you're a beginner to the world of web scraping or a seasoned veteran, you will inevitably encounter CAPTCHAs and have to incorporate measures to bypass them. The tools discussed in this article are meant to save you time and resources and make bypassing CAPTCHAs a breeze so that you can focus instead on collecting the data you need.
Among them, Bright Data's Scraping Browser stands out as a comprehensive solution, effortlessly integrating CAPTCHA bypass technology and proxy management with the convenience of a headful, fully GUI automated browser. This is an all-in-one package and no doubt the ideal solution for enterprise-grade scraping projects. But it also comes with a free trial so you can give it a spin to see if it suits your requirements or not.
Meanwhile, the Puppeteer Extra Stealth NPM Plugin helps ensure anonymity and evade bot detection, while the Puppeteer Extra ReCaptcha NPM Plugin automates reCAPTCHA solving. These plugins are on the cost-effective side and are well-tested and dependable, especially for smaller-scale projects. Combining these two might ensure even better efficacy.
GoodByeCaptcha is a good pick for bypassing audio-based CAPTCHAs. 2Captcha is also reliable since it's a human-based CAPTCHA solver and is cost-effective but beyond that, it has limited use.
You can pick the tool that suits you best depending on your use case (or pick more than one if required). But all in all, these 5 tools will keep those pesky CAPTCHAs away and ensure your data collection process remains smooth, continuous, and uninterrupted.
Comments
Loading comments…