What is a Proxy Server?
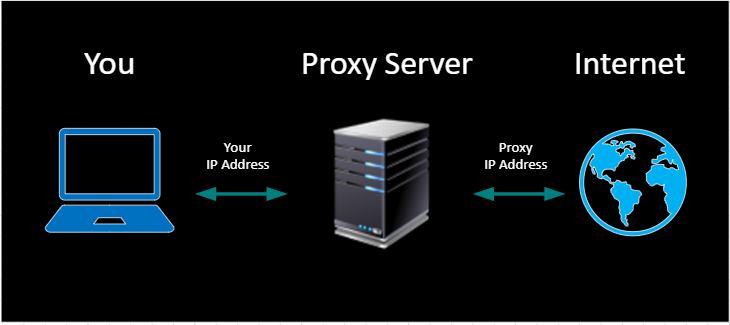
A proxy server is a computer on the internet that accepts the incoming requests from the client and forwards those requests to a destination server. The word proxy means "to act on behalf of another," and a proxy server acts on behalf of the user. Proxy servers use a different IP address on behalf of the user, concealing the user's real address from web servers.
How does a Proxy Server Work?
A standard proxy server works in the following way:
-
A user enters a website's URL into their browser or a get request is sent for the URL from a program.
-
The proxy server receives the user's request.
-
The proxy server forwards the request to the webserver.
-
The web server sends a response (website data) back to the proxy server.
-
The proxy server forwards the response to the user.

Why use a Proxy Server?
Proxy servers have many different uses including facilitating anonymous internet browsing, bypassing geo-blocking, and regulating web requests.
Sometimes, when you access and try to scrape a webpage, the website recognizes you like an unfamiliar bot crawling their website and they will temporarily or permanently block your IP address. This action prevents you from getting the data you need.
Listed below are some reasons for using a proxy server.
-
Your real IP address will be hidden. The website you access will be unable to know your real IP address because it will receive the proxy server's IP address. In addition, IP addresses will be rotated where a different IP address will be sent for each request sent to a website.
-
Change the user-agent header of the request to bypass user-agent-based blocking scripts used by websites. Most websites can detect when a request came from a Python request based on the information contained in the user-agent. You can change the user-agent header of the request and make it look like a browser which will get you past the user-agent-based blocking scripts.
-
Access geo-blocked or restricted content. Many websites restrict access to their websites based on geographical location. The proxy server can send an IP address to the website with a location that will be accepted by geo-blocked websites.
-
Load times may be reduced. When a proxy server receives a response back from a website, they store the contents in cache memory. When a cached page is subsequently requested, the contents can be retrieved and displayed faster to the user. In addition, the proxy servers will balance the requests across multiple servers to prevent overloads.
-
Malicious websites can be filtered out. The proxy server administrator can identify websites that contain malware or phishing links and can prevent proxy users from accessing those websites.
Types of Proxies
There are many different types of proxies that cover different types of configurations. I will provide a brief overview of some of the most common proxies.
-
Transparent Proxies: These pass all of your information to the web server along with the proxy's IP address. These proxies don't offer any kind of privacy protection.
-
Anonymous Proxies: These never pass your IP address to the webserver although they will identify themselves as a proxy in the request. This helps keep your browsing activity private.
-
Elite Proxies: These proxies only send the REMOTE_ADDR header while the other headers are empty. An elite proxy server is ideal to pass any restrictions on the internet and protect your privacy to the fullest extent. You will seem like a regular internet user who lives in the country that your proxy server is running in.
-
Residential Proxies: These proxies use the real IP addresses of computers. These are the best types of proxies to use because they look like regular clients to servers. They also tend to be undetectable and they get around some of the geographic restrictions.
-
Data Center Proxies: These proxies have computer-generated IP addresses that aren't attached to a real device. It's like having a proxy in the cloud. The advantages of this proxy are its speed and performance.
-
Public Proxies: These proxies are the most insecure, unreliable proxies available. They can go down at any moment and many are set up by hackers to steal data. The main reason people use them is that they are free.
-
Private Proxies: These proxies are defined by the provider offering the service. This could mean your proxy can only be used by one client at a time or that your proxy needs authentication before it can be used.
Using a Proxy in a Requests Module
The following steps will be performed in Python to illustrate the use of proxies in a request. The proxies used are free public proxies.
- Import the requests module.
- Set up a proxy IP address and port.
- Initialize a URL.
- Send a GET request to the URL and pass in the proxy.
- Return the proxy server address of the current request or show a connection error if not successful.
import requests
# Enter a proxy IP address and port.
proxy = 'http://129.226.33.104:3218'
# Initialize a URL.
url = 'https://ipecho.net/plain'
# Send a GET request to the url and pass the proxy as a parameter.
page = requests.get(url,
proxies={"http": proxy, "https": proxy})
# Prints the content of the requested url.
print(page.text)
129.226.33.104
The result was a successful connection.
Let's use the same process but use multiple proxy IP addresses and ports.
import requests
from itertools import cycle
import traceback
# Enter proxy ip's and ports in a list.
proxies = {
'http://129.226.33.104:3218',
'http://169.57.1.85:8123',
'http://85.25.91.141:15333',
'http://103.149.162.195:80',
'http://8.218.213.95:10809'
}
proxy_pool = cycle(proxies)
# Initialize a URL.
url = 'https://httpbin.org/ip'# Iterate through the proxies and check if it is working.
for i in range(1,6):
# Get a proxy from the pool
proxy = next(proxy_pool)
print("Request #%d"%i)
try:
response = requests.get(url,proxies={"http": proxy, "https": proxy}, timeout=30)
print(response.json())
except:
# Most free proxies will often get connection errors. You will need to retry the request using another proxy.
print("Skipping. Connection error")
Request #1
Skipping. Connection error
Request #2
{'origin': '169.57.1.85'}
Request #3
{'origin': '87.123.240.128'}
Request #4
Skipping. Connection error
Request #5
Skipping. Connection error
I used free public proxies from the internet for these requests which resulted in two successful connections and three connection errors.
Connection errors are very common when using free proxies and can be frustrating when you are trying to access and extract data from a website.
Free proxies on the internet are often abused and end up being on blacklists which are used by anti-scraping tools and web servers to block IP addresses.
If you are doing large-scale data extractions, you may want to consider paying for some good proxies or using a proxy service provider such as Ninjas Proxy who will provide quality IP addresses and even rotate the IPs for you. Alternatively, you can use a VPN (virtual private network) service which does what a proxy service does and also encrypts all incoming and outgoing online data so that third parties cannot access them.
Comments
Loading comments…