
What is throttling and why does it happen?
At the highest level, throttling just means that Lambda will intentionally reject one of your requests and so what we see from the user side is that when making a client call, Lambda will throw a throttling exception, which you need to handle. Typically, people handle this by backing off for some time and retrying. But there are also some different mechanisms that you can use, so that’s interesting, Lambda will reject your request. why does it occur? Throttling occurs when your concurrent execution count exceeds your concurrency limit.
Now, just as a reminder, if this wasn’t clear, Lambda can handle multiple instance invocations at the same time and the sum of all of those invocations amounts to your concurrency execution count. So assume we’re at a particular instant in time if you have more invocations that are running that exceed your configured limit, all new requests to your Lambda function will get a throttling exception.
What are the configure limits? Lambda has a default 1000 concurrency limit that’s specified per region within an account. But it does get a little bit more complicated in terms of how this rule applies when you have multiple Lambda functions in the same region and the same account.
Depending on the invocation event source, whether it’s manual, SQS, SMS, Kinesis, Dynamo, or something else. They all have different behaviors when encountering throttling exceptions.
How it works — An Example

Here we have our Lambda. And in our Lambda set up in this particular configuration, I have three functions in my region. So in this region, I have function one, function two, and function three. Now, depending on your circumstance, you may have three separate functions, maybe only one. But in this example, let’s assume that these are all completely unrelated functions. They’re all doing separate things. So function one may handle some part of an application.
Function two is for a separate application and function three, again, is for something separate. The only reason we have them in the same region, the same account is for convenience purposes. Now keep in mind that we have a default 1000 unreserved account concurrency limit.
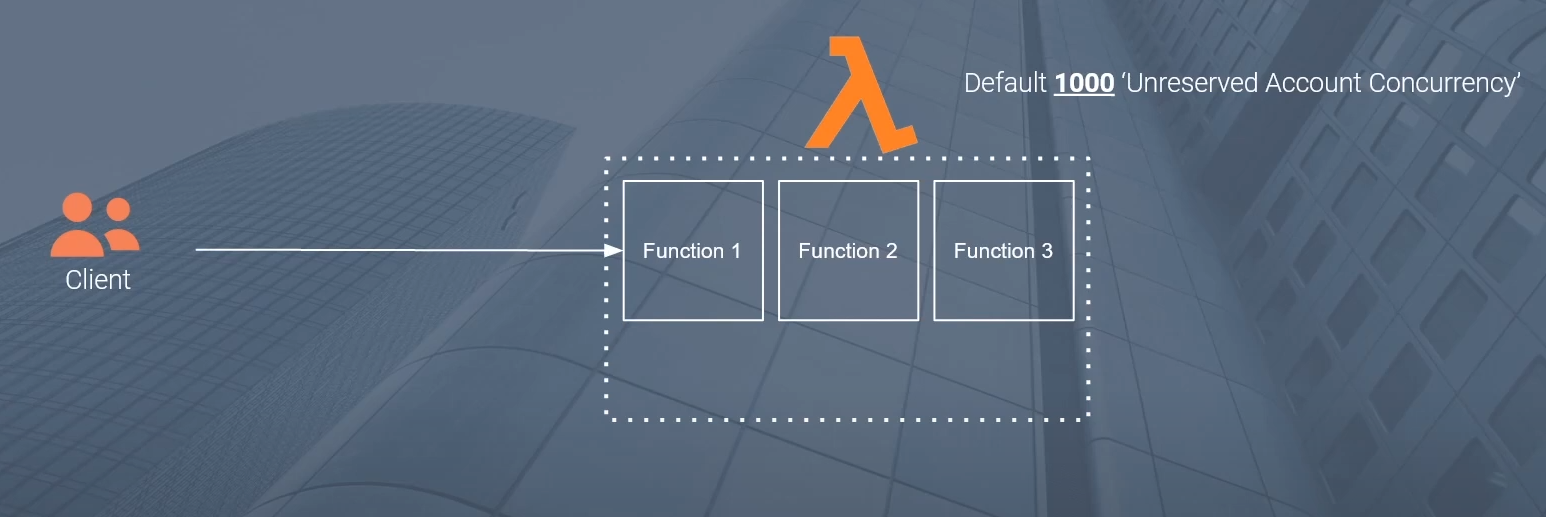
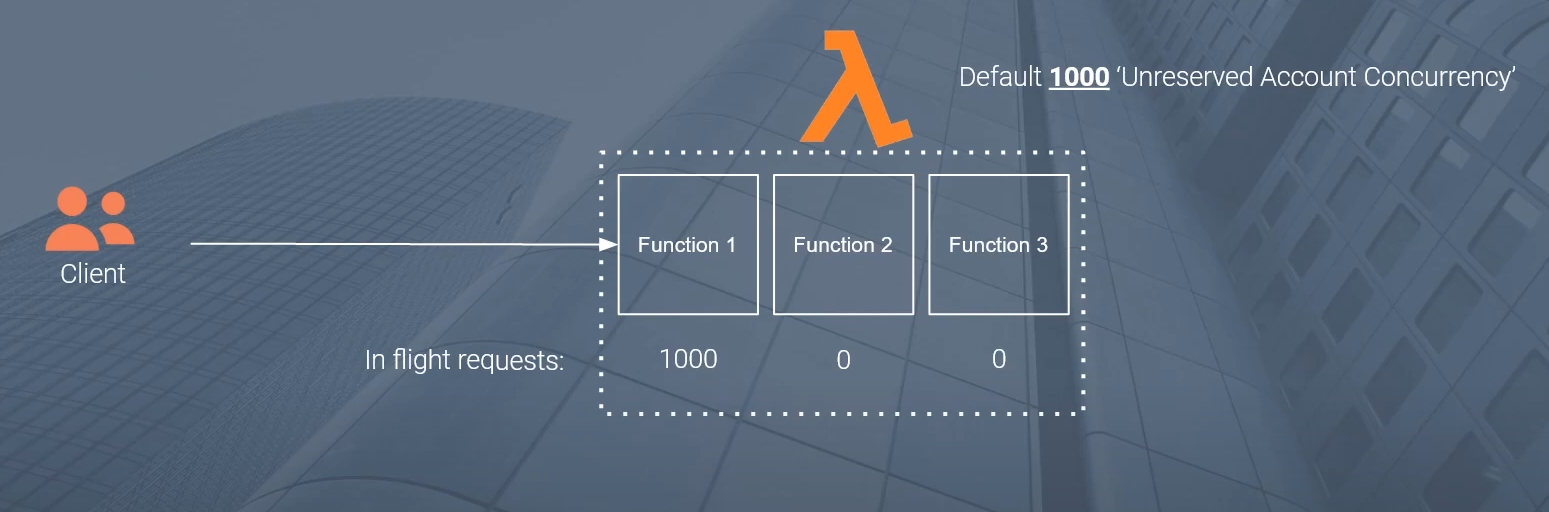
Now say we have a client over here and this client could be some rest API that is acting on behalf of some user through a front end could be some other set up. But let’s just assume it’s some API that’s calling your Lambda function. Now assume that at a particular instance a particular moment in time, I start calling this Lambda function one with a very high number of requests. I get a sudden burst of traffic and I’m making hundreds.
So let’s assume that in response to this burst of requests at a particular instance of time, I have 1000 inflight requests or 1000 concurrent executions that are running against this function one. So at the very highest level here, if a new invocation comes in at this particular instant in time, that invocation will get throttled because that exceeds our 1000 unreserved account concurrency limit. Any new invocation that exceeds that amount will get throttled and will receive that error.
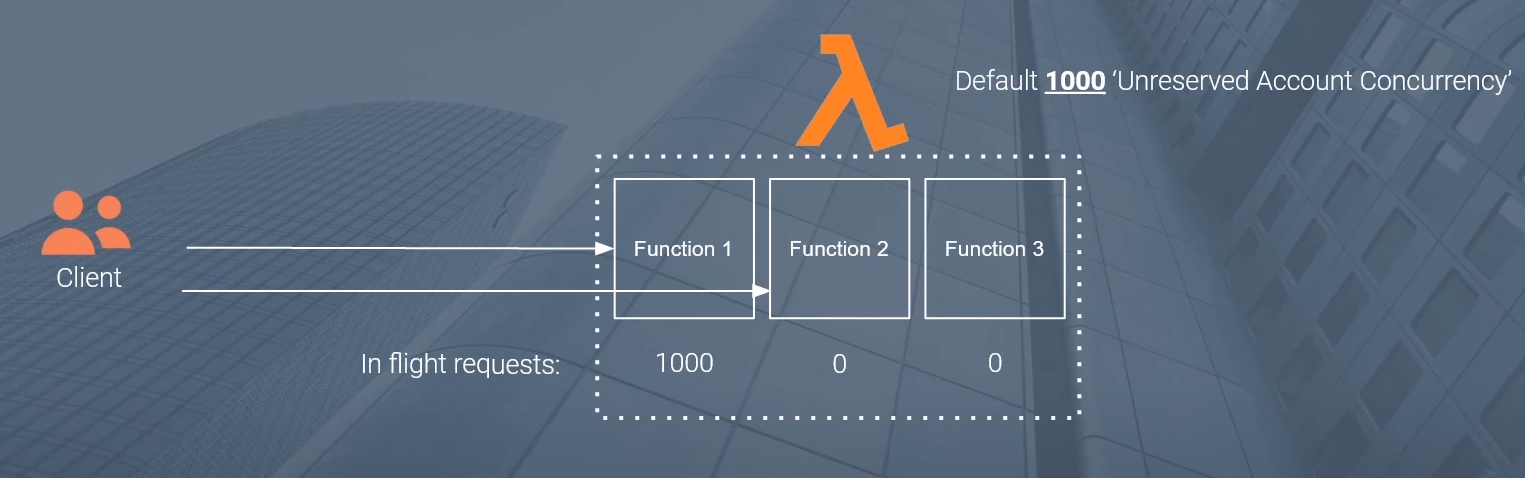
What we’re saying here is that the concurrency limit, the pool of concurrency is shared across all of your Lambda functions that are within the same account and within the same region. Function two is for another function three is for another. That means that a sudden burst of traffic to function one can start to result in throttling when new requests come in for function two and function three.
And this is the kind of problem with throttling. You can have scenarios where a high burst of traffic to one part of your application can have some cascading effects on other portions of your application. So this is truly the danger of throttling using the default configuration.
Handling by Event Source & Invocation Type
SNS -> Lambda = Immediate failures: It’s one of the more common ones, the common setups that we typically use, and this results in immediate failures. When SNS will try and invoke your Lambda function, if your throttling limit is hit, it will receive a throttling exception. Now, if you have a retry policy that’s configured on your SNS topic, SNS will try to invoke your Lambda function for some time, but it can’t guarantee that it will eventually succeed.
Manual (Sync) = Immediate failures: If a Rest API is trying to hit a Lambda function synchronously to get a response, it will receive a throttling exception. Now, typically, how people handle these types of exceptions are in your actual logic in your code If you receive a throttling exception, you can back off for some time or sleep the thread that’s making the call. So you sleep for 50 milliseconds and then you try again. If you fail again, you back off a little bit more. Maybe you sleep for 100, so you can do some kind of exponential backoff here and attempt multiple times before throwing some kind of permanent exception back to your client.
Manual (Sync) = Eventual failures: So different behavior actually and the way this one works is that when an asynchronous invocation is made against your Lambda function, Lambda will put the instance or the metadata about that invocation in an internal queue, and Lambda will pull that queue internally to process that request.
Now, if when it pulls the queue and it attempts to process that request, your concurrency limit is hit, it will fail and it’ll put that message back into the queue. Now it will automatically retry for, I believe, three times. Now, if you have a dead letter Q, a DLQ configured on this account, that message can be sent to a dead letter Q where you can kind of pick it up and redirect it at a later point in time. But if you don’t have that, this message can be potentially lost forever.
SQS -> Lambda = Eventual failures: This follows the same principles of the Asynchronous invitation that I just spoke about. So it’ll retry by putting that message back in the queue for I believe up to three or five retries before finally putting it to the DLC. So the same principle applies. Do you want a delay or queue here to accommodate for failure so you can retrieve them at a later point?
Kinesis, DynamoStreams -> Lambda = Immediate failure: Now the delivery to Lambda will result in an immediate failure. The same kind of scenario has a DLQ setup, here so that you can capture these failures.
How to Prevent it? Best Practices
-
Request unreserved concurrency limit increase: The first and probably the easiest thing that you can do is that you can request an unreserved concurrency limit increase, and this is at no cost to you. So the default limit per account per region is 1000 concurrent invocations
-
Specify reserve concurrency per function: The second mitigation technique is to specify a reserved concurrency per function, and the way you do this is by going to your Lambda function in the configuration section, and there’s a concurrency section where you can see some details about the provision concurrency limits. So what reserved concurrency does? It reserves several concurrent execution requests for a particular Lambda function. So in the example that we were discussing before, we had three Lambda functions and they were all kind of competing for that 1000 concurrency limit. Now, using this approach, you can slot a 200 concurrent limit for a particular function. So at any point in time, regardless of what your other functions are doing, this function will always be able to handle 200 concurrent requests, and the other two functions going back to the previous example will have to compete for this pool. So, in this case, it is 800. This is a mitigation technique.
-
Configure a DLQ to capture failure: The most important is to configure a dead letter Q to capture failure as I’ve kind of described before. This is very important if you are receiving Throttling and you need to redirect those messages at a later point in time.
-
Alarm on throttling exceptions: Possibly the most important is to alarm on Throttling and the presence of messages in your DLQ if you are using one. So obviously setting up a bunch of these mechanisms will help mitigate the issue But in the case that it does happen, you do need to become aware of it so that you can deal with it appropriately.
Keep in mind here that all the mechanisms, all the suggestions that we’re making here are to reduce the likelihood of throttling.
Thanks so much, folks.
Comments
Loading comments…