In this article, I will try to simplify the concept of the context window in large language models. I will try to avoid heavy technical words for the sake of non-technical audience.
Language models have become an important and flexible building block in a variety of user-facing language technologies, including conversational interfaces, search and summarization, and collaborative writing. These models perform downstream tasks primarily via prompting: all relevant task specification and data to process is formatted as a textual context, and the model returns a generated text completion. These input contexts can contain thousands of tokens, especially when using language models on lengthy inputs (e.g., legal or scientific documents, conversation histories, etc.) or augmenting them with external information (e.g., relevant documents from a search engine, database query results, etc.)
This is the passage from a paper ‘Lost in the Middle: How Language Models Use Long Contexts’, summarizes textual context, text completion which are related to context window**** in very simple language. Let''s understand it in detail.
Understanding the Context Window
- In simple language, a context window refers to the length of text an AI model can process and respond to in a given instance.
- More precisely, it is the number of tokens the model can consider when generating responses to prompts and inputs.
- According to OpenAI, Tokens can be thought of as pieces of words. (Rules of thumb for understanding tokens in terms of lengths: 1 token ~= 4 chars in English, 1 token ~= ¾ words, 100 tokens ~= 75 words)
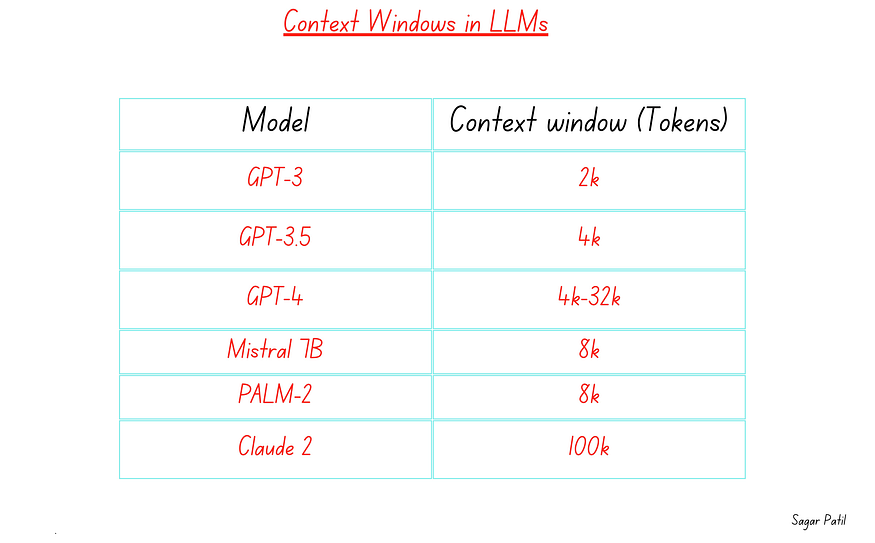
- Different models may have different context window limitations. GPT-3.5-turbo (one of the models powering ChatGPT) has a 4096 token limit, while GPT-4 varies from ~8k to ~32k.
 Examples
Examples
Imagine you’re teaching a model to understand sentences. The “context window” is like the window it looks through to understand words.
- Big Window: If the window is big, it sees a lot of words at once. This helps it understand long and complicated sentences. It’s like seeing a whole paragraph at once.
- Small Window: If the window is small, it only sees a few words at a time. This is good for simple sentences, but it might struggle with really long or complex ones. It’s like looking at just one sentence at a time.
So, the size of the window affects how well the model understands what it’s reading. A big window helps with complex stuff but needs more compute power. A small window is simpler but might not handle very long or tricky sentences as well. So, in essence, the word ‘window’ is related to number / range and context is related to your data that goes into LLMs.
Importance of Context Window
- Context windows are crucial because they allow the model to understand the relationships and dependencies between words in a sentence or text. It helps the model capture syntactic and semantic structures.
- It’s akin to the system’s ‘working memory’ for a particular analysis or conversation. GPT-4, latest text-generating model, that can “remember” roughly 50 pages of content thanks to a greatly expanded context window. Models with small context windows tend to “forget” the content of even very recent conversations, leading them to veer off topic. After a few thousand words or so, they also forget their initial instructions, instead extrapolating their behavior from the last information within their context window rather than the original request.
- The expansion of the context window size has a significant impact on the model’s performance and usefulness across various applications. By having a larger context window, LLM is capable of handling more lengthy inputs such as entire documents or comprehending the full scope of an article. This ability enables LLM to produce more contextually relevant responses by leveraging a more comprehensive understanding of the input.
Components of Context window
 Components of context window
Components of context window
The components of the context window for a language model (LLM) can be broken down as follows:
Prompt:
— Definition: The prompt is how a developer instructs the LLM to perform a specific task. A prompt could be a specific instruction or question given to the model. This is a crucial aspect of “prompt engineering.”
— Example: (Text Summarization) “Summarize the main points of the article below.”, “Give a concise summary of the key findings in the research paper.”
Inputs:
— Definition: Inputs are any context or user-provided information that is relevant for the LLM to generate useful output. Inputs may also include examples that help the model better understand the task or context.
**— Example: (**For a question-answering system) inputs may include snippets of domain-specific documents that provide context for generating accurate responses.
Completion/ Outputs:
— Definition: The outputs are the results generated by the model, which are then consumed by the application.
— Examples: In a chat application, the output may be a response generated by the model based on the provided inputs and prompt.
These components work together to facilitate the interaction between the developer, the LLM, and the application. The prompt guides the model, inputs provide the necessary context, and outputs are the actionable results that the application can use to respond to user queries or perform specific tasks.
Context Window and Computational Constraints
LLMs are powered by intricate mechanisms like self-attention, empower machines to not only comprehend text but also generate contextually coherent responses. However, while this breakthrough has been remarkable, it has not come without its challenges.
Understanding Self-Attention
When a model processes text, it dissects it into segments and performs an array of matrix computations. This process allows the model to discern the relationships between every token within the text. Essentially, self-attention ensures that each token influences the understanding of the entire text, enabling the model to grasp its meaning and context.
The Computational Conundrum
Yet, with every innovation comes its own set of hurdles. In the case of self-attention, the main challenge arises from its computational intensity. From a mathematical perspective, the computational requirements scale quadratically with the length of the input. Put simply, the larger the text provided as input (referred to as the context window), the more computational resources are consumed in training and executing the model.
Context Window Constraint
This technical limitation has led researchers to impose constraints on the size of input that can be fed to these models. Typically, models are designed to process a standard proportion of tokens, ranging from 2,000 to 8,000. While this approach mitigates computational strain, it does come at a cost.
Impact on Language Models
The limitation on context window size has repercussions for the influence and effectiveness of Language Learning Models (LLMs). By constraining the amount of context available, the models may struggle with tasks that rely heavily on a comprehensive understanding of long and complex text.
Conclusion
In the dynamic landscape of language models, the concept of the context window stands as a pivotal factor influencing their performance and capabilities. As we’ve explored, this window dictates the scope of contextual information available to the model during language generation. A larger context window offers a broader view, empowering the model to capture longer-range dependencies and nuances, while a smaller window excels in tasks requiring immediate context.
However, the trade-off between context window size and computational resources is a crucial consideration.
In our next article, we will delve into the crucial inquiry of whether a larger context window truly leads to enhanced performance or not.
Comments
Loading comments…