OpenAI’s recent release of their Assistants API marks a big step forward in the world of AI. These assistants are powerful tools that can do some really cool things, like turning complex data into easy-to-read text. For instance, they can even transform information from tables into clear answers. This makes it a lot easier to handle and understand large amounts of information.
But, there’s a catch. The OpenAI Assistants have a limit — they can only work with up to 20 files at a time. This can be a bit limiting if you’re dealing with lots of data or documents. We’ve got a workaround for that: using a vector database, like Pinecone for example, to extend their capabilities.
The solution initiates with the Vector Database running a search query to locate relevant files, which it then retrieves. These files are uploaded to OpenAI, where the OpenAI Assistant processes them and generates a response. Finally, the files are deleted from OpenAI Assistant to maintain data hygiene and storage efficiency.

In this article, we’re going to show you, step by step, how to build your own Python retrieval chatbot using OpenAI Assistants and Pinecone. This way, you won’t be held back by the file limit, and you can make the most out of these awesome AI tools.
What You Will Need
- Pinecone API Key: The Pinecone vector database can store vector embeddings of documents or conversation history, allowing the chatbot to retrieve relevant responses based on the user’s input.
- OpenAI API Key: Necessary to use OpenAI’s Assistants features through python.
- Python: The programming language we will be using to build our chatbot. (Make sure to download Python versions 3.8 or higher)
Steps for Pinecone API Key
- Sign up for an account on the Pinecone website.
- Once you are signed up and logged in, on the left side navigation menu click “API Keys”.
- Copy the API key displayed on the screen (we will use this key later).
- Now, go back to the “Indexes” tab and create a new index.
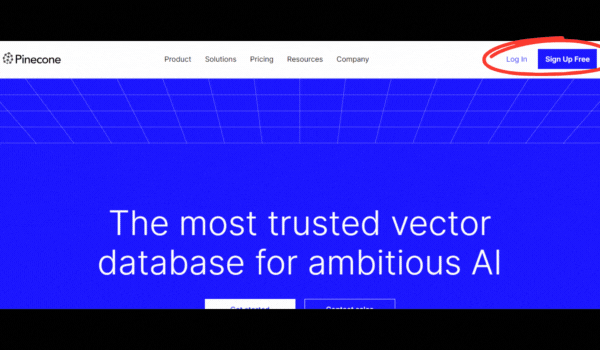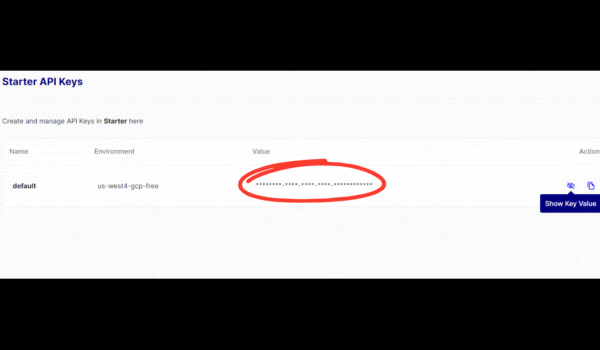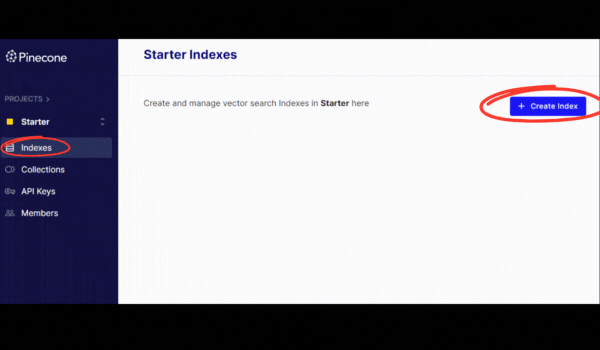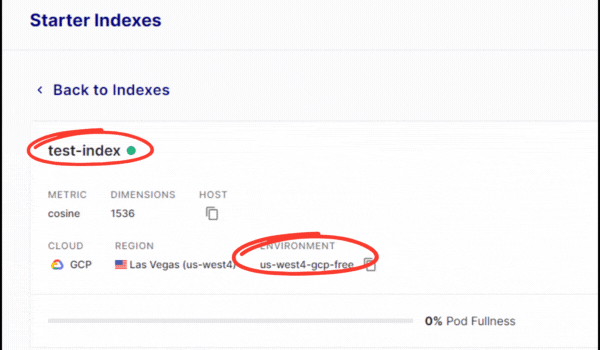
- Name it whatever you want and make the dimensions 1536.
- Create the index and copy the environment of the index, we’ll need it for later.
Steps for OpenAI API Key
- Go to OpenAI’s website and log in to your account. If you don’t have one, you’ll need to create it.
- Once logged in, click on API and select ‘API keys’ on the left side navigation.
- Click on the ‘Create New Secret key’ button to generate an API Key.
- Name your API key and then copy it once it’s shown to you.
Now, let’s get started!
Install Necessary Dependencies
To install the required Python modules used in the provided code, you can use the following pip command in your terminal.
pip install pinecone-client openai langchain
Imports and Global Variables
These lines import necessary libraries and initialize global variables for Pinecone and OpenAI configurations. dir_path is set to the directory containing the data files to be processed.
import os
import pinecone
import shelve
import time
from openai import OpenAI
from langchain.vectorstores import Pinecone
from langchain.text_splitter import CharacterTextSplitter
from langchain.document_loaders import PyPDFLoader
from langchain.embeddings.openai import OpenAIEmbeddings
# Pinecone Information
pinecone.init(api_key=''PINECONE API KEY'', environment=''PINECONE ENVIRONMENT'')
index_name = "PINECONE INDEX NAME"
# OPENAI Information
os.environ["OPENAI_API_KEY"] = "YOUR OPENAI API KEY"
client = OpenAI()
assistant_id = "YOUR ASSISTANTS ID"
dir_path = ''YOUR DIRECTORY THAT HOSTS YOUR DATA. Example: ./data''
Document Loader
This function loads documents from a specified file path, primarily focusing on PDF files. It uses PyPDFLoader for loading the document and then splits the text into smaller chunks for easier processing. The splitting is handled by CharacterTextSplitter, which divides the text based on character count, with a specified chunk size and overlap.
def load_docs(file_path):
loader = PyPDFLoader(file_path)
documents = loader.load()
text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=200)
documents = text_splitter.split_documents(documents)
return documents
Pinecone Index Initialization
Initializes a Pinecone index using the global index_name. This index is essential for storing and retrieving vector representations of documents.
def init_pinecone_index():
index = pinecone.Index(index_name)
return index
Document Ingestion into Pinecone
Inserts the processed documents into the Pinecone vector database. It uses the documents and their vector embeddings (generated by OpenAIEmbeddings) for insertion.
def insert_docs_to_pinecone(documents, embeddings):
pineconedb = Pinecone.from_documents(documents, embeddings, index_name=index_name)
return pineconedb
Processing and Storing Documents
This function orchestrates the document storage process in Pinecone. It iterates over files in a specified directory, processes each file, and inserts the data into Pinecone.
def store_docs_to_pinecone():
embeddings = OpenAIEmbeddings()
index = init_pinecone_index()
for filename in os.listdir(dir_path):
file_path = dir_path + ''/'' + filename
print(file_path)
try:
documents = load_docs(file_path)
pineconedb = insert_docs_to_pinecone(documents, embeddings)
print(f"Inserting to Pinecone for document {filename}...")
except Exception as e:
error_message = f"{filename} - Error: {e}"
print(error_message)
continue
Executing Searches in Pinecone
Performs a search in the Pinecone index using a prompt. The prompt is first embedded using OpenAI’s model, and then a query is made to the Pinecone index to find relevant documents. Feel free to change the top_k value based on your needs.
def run_pinecone_search(prompt):
sources_list = []
duplicate_source = set()
embedded_prompt = client.embeddings.create(input = [prompt], model="text-embedding-ada-002").data[0].embedding
index = init_pinecone_index()
search_results = index.query(embedded_prompt, top_k=4, include_metadata=True)
for match in search_results[''matches'']:
source = match[''metadata''][''source'']
if source not in duplicate_source:
sources_list.append(source)
duplicate_source.add(source)
return sources_list
File Management in OpenAI
Handles the uploading of files to OpenAI. It checks if each file in sources_list is already uploaded and either retrieves its ID or uploads the file and obtains a new ID.
def upload_file(sources_list):
files_list = client.files.list().data
for file_path in sources_list:
filename = os.path.basename(file_path)
existing_file = next((file_object for file_object in files_list if file_object.filename == filename), None)
with open(file_path, ''rb'') as file:
file_content = file.read()
if existing_file:
file_id = existing_file.id
client.beta.assistants.files.create(assistant_id=assistant_id, file_id=file_id)
print(f"File already exists, grabbing file Id: ", file_id)
else:
file = client.files.create(file=(filename, file_content), purpose="assistants")
client.beta.assistants.files.create(assistant_id=assistant_id, file_id=file.id)
print("File does not exist, creating file ID: ", file.id)
Assistant Creation
Creates an assistant in OpenAI. The assistant is configured with specific instructions and tools, and a specific model (GPT-4) is designated for its operations. Adjust the model based on your needs.
def create_assistant():
"""
You currently cannot set the temperature for Assistant via the API.
"""
assistant = client.beta.assistants.create(
name="Assistant",
instructions="You are a helpful assistant. When asked a question, use the sources given to answer to the best of your ability. Try to get your answer from the provided files.",
tools=[{"type": "retrieval"}],
model="gpt-4-1106-preview"
)
return assistant
Thread Existence Check
Checks the local database to see if a thread with a specific name already exists.
def if_thread_exists(name):
with shelve.open("threads_db") as threads_shelf:
return threads_shelf.get(name, None)
Storing Conversation Threads
Stores a thread ID in the local database with a given name.
def store_thread(name, thread_id):
with shelve.open("threads_db", writeback=True) as threads_shelf:
threads_shelf[name] = thread_id
Generating AI Responses
Generates a response for a given prompt. It manages the thread creation and retrieval, uploads necessary files, and sends a message to the assistant to generate a response.
def generate_response(prompt, name, sources_list):
thread_id = if_thread_exists(name)
if thread_id is None:
print(f"Creating new thread for {name}")
thread = client.beta.threads.create()
thread_id = thread.id
store_thread(name, thread_id)
else:
print(f"Retrieving existing thread for {name}")
thread = client.beta.threads.retrieve(thread_id)
upload_file(sources_list)
message = client.beta.threads.messages.create(
thread_id=thread_id,
role="user",
content=prompt,
)
new_message = run_assistant(thread)
return new_message
Running the Assistant
Runs the assistant on a specific thread. It waits for the completion of the assistant’s task and then retrieves the most recent message as the response.
def run_assistant(thread):
assistant = client.beta.assistants.retrieve(assistant_id)
run = client.beta.threads.runs.create(
thread_id=thread.id,
assistant_id=assistant_id,
model="gpt-4-1106-preview",
tools=[{"type": "retrieval"}]
)
# Wait for completion status
while run.status != "completed":
run = client.beta.threads.runs.retrieve(thread_id=thread.id, run_id=run.id)
time.sleep(1)
# Retrieve the Messages
messages = client.beta.threads.messages.list(thread_id=thread.id)
new_message = messages.data[0].content[0].text.value
return new_message
Cleaning Up Files in OpenAI
Deletes files associated with the assistant in OpenAI, ensuring that no unnecessary data is retained.
def delete_files_openai():
files_list = client.beta.assistants.files.list(assistant_id).data
for file_info in files_list:
file_id = file_info.id
client.beta.assistants.files.delete(assistant_id=assistant_id, file_id=file_id)
print(f"Deleted assistant file with ID: {file_id}")
Interactive User Interface
This is the main driver of your application. It allows the user to interactively choose tasks such as uploading documents to Pinecone, generating a response to a prompt, or creating the OpenAI assistant. The application continues running until the user decides to exit.
if __name__ == ''__main__'':
thread_id = input("Name: ")
while(True):
task = input("Task (upload/prompt/create): ")
if task == "prompt":
prompt = input("Prompt: ")
sources_list = run_pinecone_search(prompt)
response = generate_response(prompt, thread_id, sources_list)
print(response)
delete_files_openai()
elif task == "upload":
store_docs_to_pinecone()
print("Successfully uploaded document(s) to Pinecone...")
elif task == "create":
assistant = create_assistant()
print("Successfully created an assistant... ID: ", assistant.id)
else:
print("Could not understand task: exiting...")
exit()
Congratulations!
You can now chat with your OpenAI assistants chatbot without reaching the file limit! This Python application effectively combines Pinecone’s vector database management with OpenAI’s GPT-4 capabilities, offering a sophisticated solution for document handling and AI-assisted interactions. Each function is carefully crafted to handle specific aspects of document processing, from loading and segmenting texts to executing intelligent searches and generating dynamic responses. This integration showcases the potential of leveraging AI for efficient data management and interactive user experiences, making it a valuable tool for a wide range of applications in data processing and conversational AI.
Comments
Loading comments…