What Is Machine Learning?
Machine learning, a pivotal subset of artificial intelligence, revolves around the creation and refinement of algorithms that can learn and make inferences or predictions from data without being directly programmed for specific tasks. As an integral part of both AI and computer science, it mimics human learning processes by using data and algorithms to progressively enhance its precision. This capability allows machines to gain insights or make decisions autonomously, a trait central to its nature as a branch of artificial intelligence. The scope of machine learning is broad and diverse, finding utility in numerous sectors such as e-commerce, social networking platforms, news agencies, autonomous vehicles, and the healthcare sector. It stands as a versatile instrument for addressing complex problems, optimizing business functionalities, and driving automation. However, harnessing its full potential demands profound expertise and substantial resources. Traditionally, machine learning is categorized into three main types: supervised, unsupervised, and reinforcement learning, and today I will talk about these in this post.
1. Supervised Learning
- Involves learning a function that maps input to output based on input-output pairs.
- Generalization to new, unseen data is a primary goal.
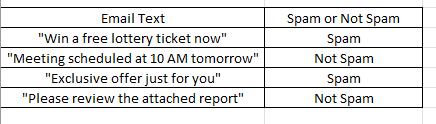
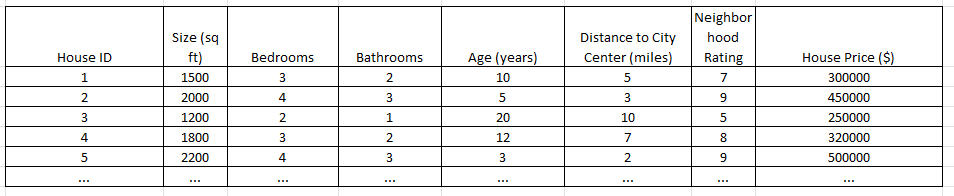
- Includes classification learning, preference learning, and function learning Classification Learning: Classifying emails as 'spam' or 'not spam'. Preference Learning: Recommending products based on customer ratings. Function Learning: Predicting house prices based on features like size, location, and age.
In supervised learning, the algorithm learns from labeled training data, helping predict outcomes for unforeseen data. The goal is to approximate the mapping function so well that when you have new input data, you can predict the output variables for that data.
Supervised learning can be separated into two types of problems when data mining --- classification and regression:
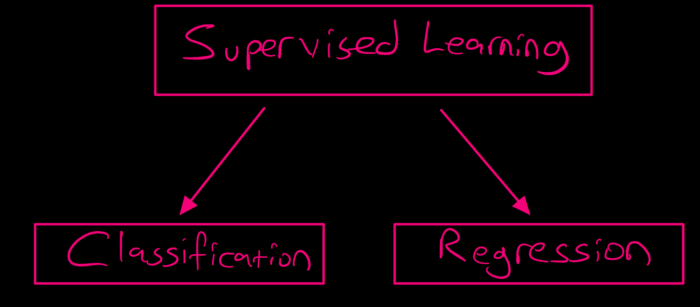
a. Classification
It uses an algorithm to accurately assign test data into specific categories. It recognizes specific entities within the dataset and attempts to draw some conclusions on how those entities should be labeled or defined. Common classification algorithms are linear classifiers, support vector machines (SVM), decision trees, k-nearest neighbor, and random forest.
b. Regression
Regression is used to understand the relationship between dependent and independent variables. It is commonly used to make projections, such as for sales revenue for a given business. Linear regression, logistical regression, and polynomial regression are popular regression algorithms.
2. Unsupervised Learning

- No Labels or Annotation: The data used in unsupervised learning doesn't come with output labels or annotations. The algorithm must make sense of the data without guidance on the desired output.
- Discovery of Hidden Patterns: Unsupervised learning algorithms aim to uncover hidden structures in unlabeled data, which can reveal insightful and often unexpected patterns.
- Data Grouping and Association: These algorithms often group data into clusters or associate items with one another based on their similarities or differences.
Unsupervised learning involves training models on data where the outcomes are not known. The model tries to find patterns and relationships in the data.
According to the data's characteristics, Clustering generates groups in this type of learning. It is uncertain whether this grouping represents a face, but providing an example picture enables the system to identify its clustering and retrieve similar ones. This machine learning is known as Unsupervised Learning.
Examples:
Clustering: Grouping customers based on purchasing behavior for market segmentation.
- Purpose: To group a set of objects in such a way that objects in the same group (a cluster) are more similar to each other than to those in other groups.
- Examples: K-means, hierarchical clustering, DBSCAN.
- Applications: Market segmentation, social network analysis, astronomical data analysis.
Anomaly Detection: Identifying unusual credit card transactions to detect fraud.
- Purpose: To identify rare items, events, or observations which raise suspicions by differing significantly from the majority of the data.
- Applications: Fraud detection, system health monitoring, outlier detection in data cleaning.
3. Reinforcement Learning
Reinforcement Learning (RL) is a type of machine learning that is inspired by behaviorist psychology and revolves around agents making decisions in an environment to achieve a goal. It differs from supervised and unsupervised learning in that the learning is guided by rewards and punishments rather than being driven by labeled data or pattern discovery.
Learning Process:
- Exploration vs. Exploitation: The agent needs to explore the environment to discover good strategies but also exploit its current knowledge to maximize the reward.
- Policy: A strategy that the agent employs to determine the next action based on the current state.
- Value Function: Measures the goodness of a state or state-action pair.
- Model of the Environment: Used for planning by predicting the next state and reward.

It's about taking suitable action to maximize reward in a particular situation. It is employed by various software and machines to find the best possible behavior or path it should take in a specific situation.
Self-driving cars where the algorithm learns to make specific maneuvers and decisions based on the driving environment. Another example is automated trading systems that learn to make profitable trades.
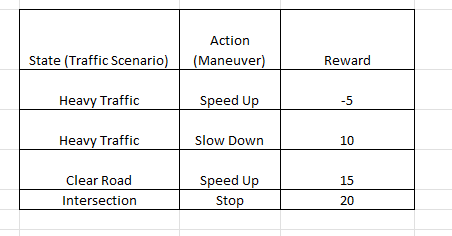
Value-Based Algorithms:
- Q-Learning: A model-free algorithm that learns the value of an action in a particular state. It uses a Q-table to store Q-values for each state-action pair.
- Deep Q-Networks (DQN): An extension of Q-learning that uses deep neural networks to approximate Q-values, enabling it to handle high-dimensional state spaces.
Policy-Based Algorithms:
- REINFORCE: A Monte Carlo variant of policy gradients which adjusts the policy directly. It's useful for high-dimensional or continuous action spaces.
- Proximal Policy Optimization (PPO): This algorithm strikes a balance between policy iteration and sample efficiency, making it more stable and robust.
Actor-Critic Algorithms:
- Advantage Actor-Critic (A2C): Combines value-based and policy-based methods where the critic updates the value function, and the actor updates the policy.
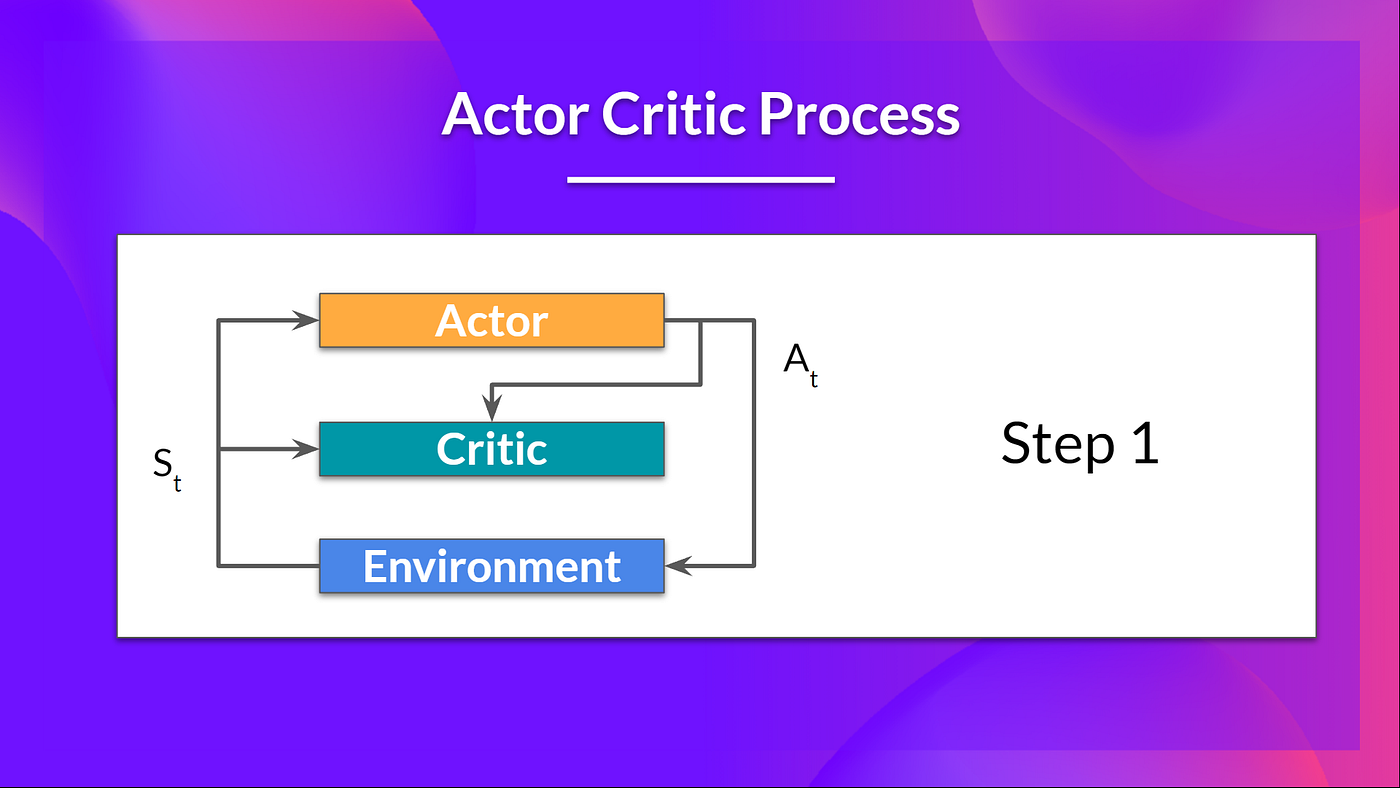
Advantage Actor Critic (A2C) --- Hugging Face
- Deep Deterministic Policy Gradients (DDPG): Suitable for continuous action spaces, it utilizes off-policy data and the Bellman equation to learn the Q-function.
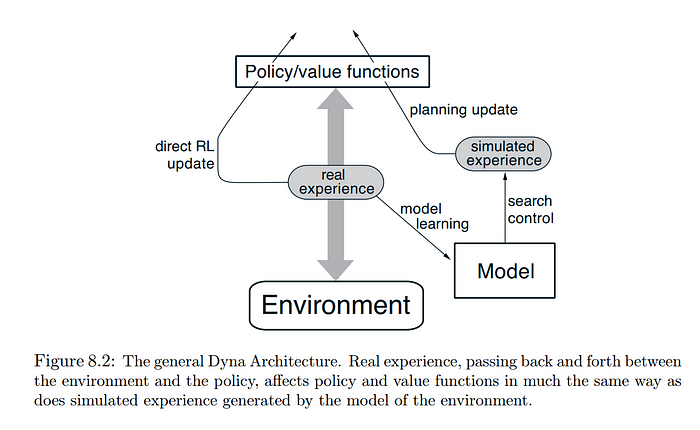
Model-Based Algorithms:
- Dyna-Q: A combination of model-free and model-based methods, where a learned model is used for planning and improving the policy.
Comments
Loading comments…