Introduction
Vector stores play a crucial role in handling high-dimensional data, particularly in scenarios where similarity search is paramount. In this article, we'll delve into the comparison of four notable vector stores: pgvector, Pinecone, Qdrant, and MongoDB. Each solution comes with its own set of features, advantages, and drawbacks, catering to different use cases and preferences.
Photo by Jason Leung on Unsplash
Before we start! 🦸🏻♀️
If you like this topic and you want to support me:
- Follow me on my LinkedIn and like this link for this article and other information about data 🔭
- Follow me on Medium and subscribe to get my latest article🫶
Popular Vector Stores
1. Pgvector
Description: An extension for PostgreSQL providing efficient similarity search for high-dimensional vectors.
Pros:
- Seamless Integration: pgvector is an extension for PostgreSQL that enhances the database with efficient similarity search for high-dimensional vectors. This extension seamlessly integrates with existing PostgreSQL databases, allowing users to add vector search capabilities to their relational data infrastructure.
- ACID Compliance: pgvector inherits all ACID compliance and transaction safety features from PostgreSQL. This ensures the consistency and reliability of your data, making it a robust choice for applications where data integrity is crucial.
- SQL Querying: Leveraging SQL for querying, pgvector provides an advantage for systems heavily reliant on SQL. The usage of SQL can simplify integration into existing systems where SQL is already a prevalent query language.
Cons:
- Optimization Challenges: Despite its seamless integration, pgvector may face challenges in optimization for high-performance vector search. As an extension, it might not be as fully optimized for this specific use case compared to solutions explicitly designed for vector storage.
- Schema Complexity: Introducing vector search capabilities to an existing PostgreSQL schema can add complexity, requiring expertise in database design for proper implementation.
Use Cases:
- Ideal for users already utilizing PostgreSQL for relational data who want to incorporate efficient vector search.
- Well-suited for scenarios where seamless integration with existing PostgreSQL databases is a priority.
2. Pinecone
Description: A dedicated vector database service built for similarity search with a focus on cloud-agnostic, fully-managed operations.
As a rule of thumb, a single p1 pod can store approximately 1M vectors, while a s1 pod can store 5M vectors
Use Case: Suitable for those seeking a specialized vector storage solution without the need for a dedicated database team.
Pros:
- Fully Managed Service: Pinecone is a dedicated vector database service built specifically for similarity search with a focus on cloud-agnostic, fully-managed operations. This means users can benefit from the capabilities of vector storage without the need for a dedicated database team.
- High-Dimensional Indexing: Pinecone excels in supporting high-dimensional data indexing, a crucial feature for efficient similarity search, especially in scenarios where the dimensionality of data is significant.
- API-First Design: Pinecone adopts an API-first design, facilitating easy integration with various machine learning platforms. This design choice enhances its usability in the context of modern machine learning workflows.
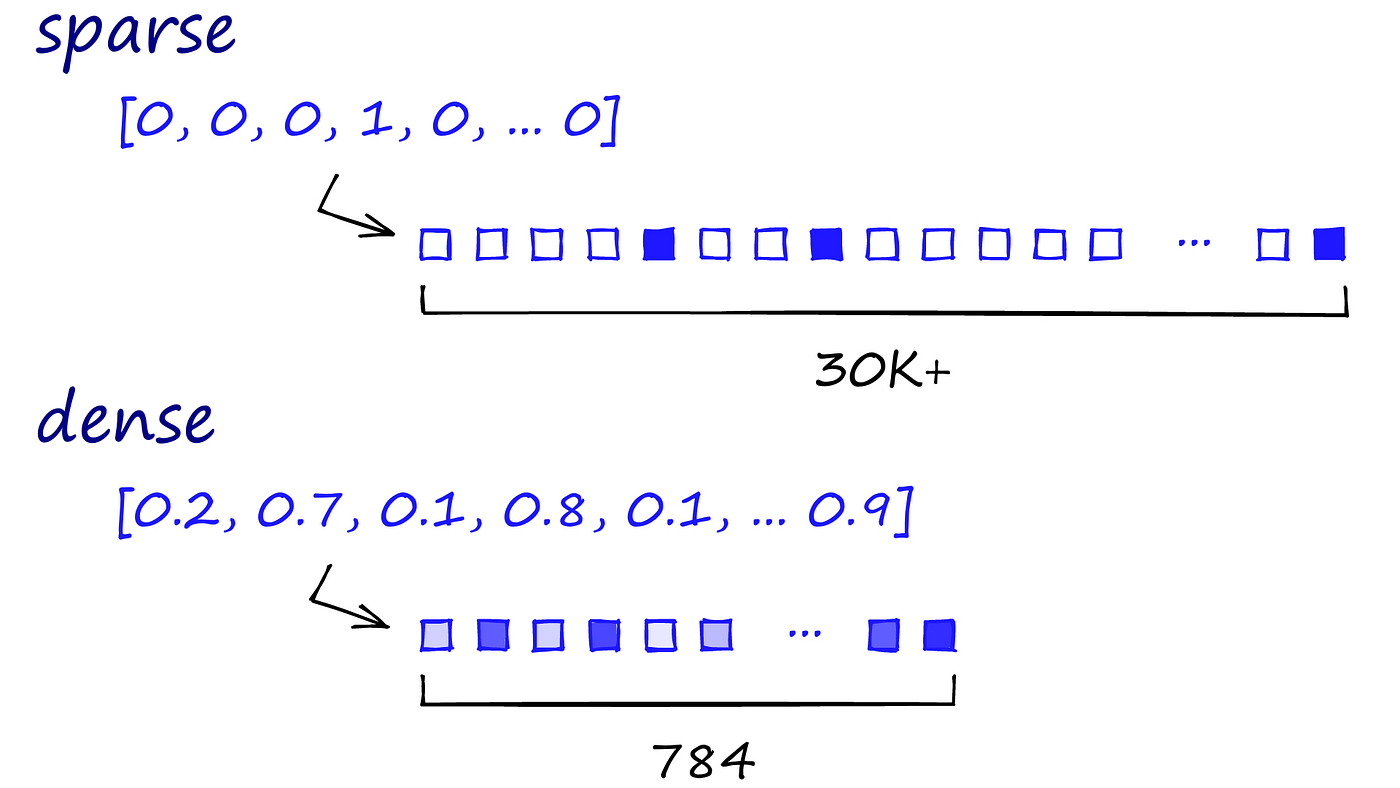
The difference beteen sparse and dense embeddings
Cons:
- Limited Functionalities: While Pinecone is specialized in vector storage and similarity search, it may not support a broader set of database functionalities. This could pose challenges for users requiring a more comprehensive database solution.
- Community Support: Pinecone, being a more niche option, might have a community that is not as extensive as some other, more widely adopted, solutions.
Use Cases:
- Suitable for users looking for a fully-managed vector storage solution with cloud-agnostic capabilities.
- Ideal for scenarios where high-dimensional data indexing is crucial for certain similarity search.
- Attractive for SME businesses without dedicated database administrators.
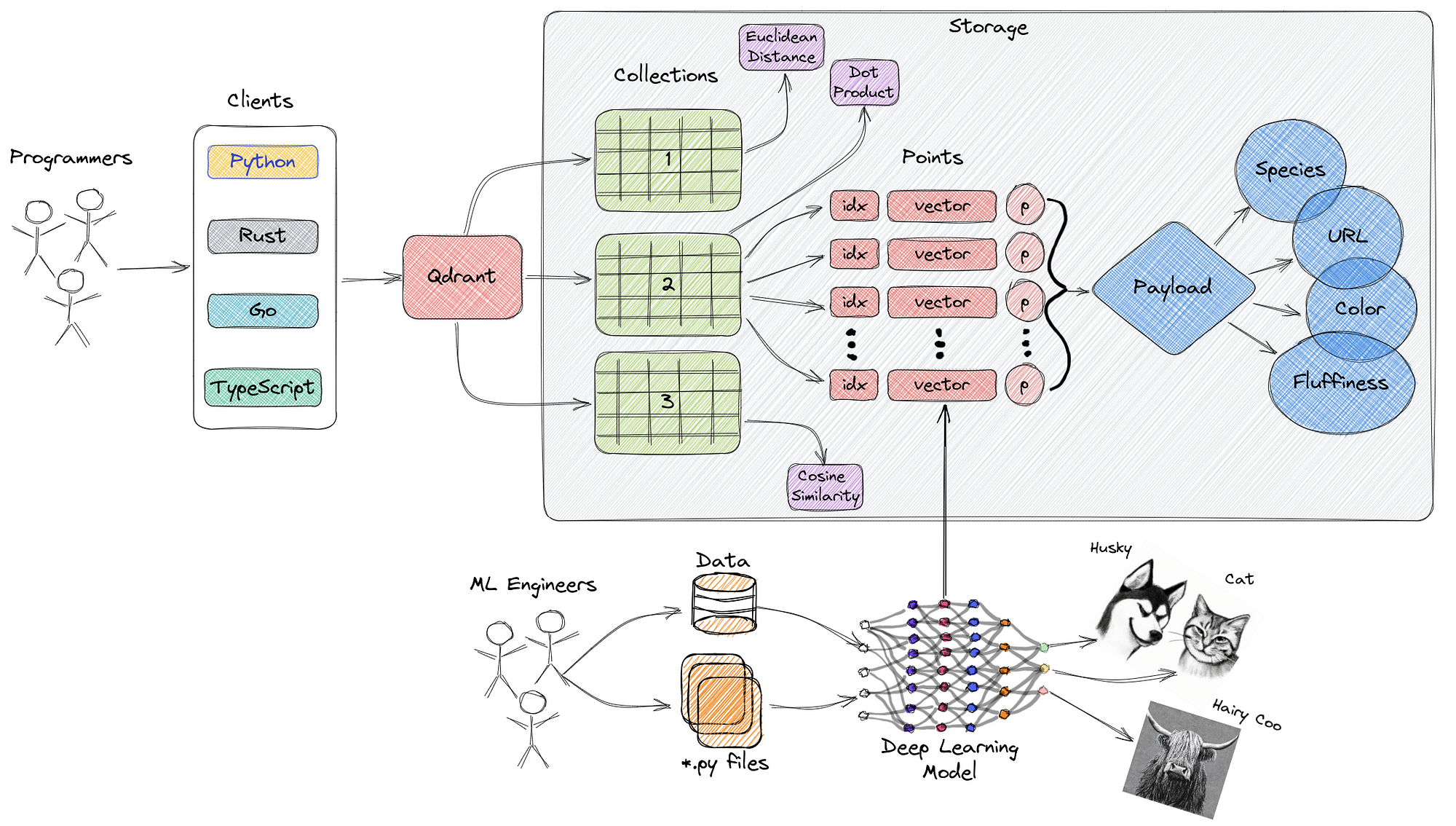
3. Qdrant
Description: An open-source vector similarity search engine designed for vector data storage and complex searches.
Pros:
- Scalability: Qdrant is an open-source vector similarity search engine designed to handle vector storage and complex vector searches. Its architecture is highly scalable, making it well-suited for scenarios involving large vector databases within distributed systems.
- Open-Source Customization: The open-source nature of Qdrant allows users to customize the engine to fit specific business requirements. This flexibility is particularly valuable for organizations with unique use cases.
- Deployment Flexibility: Qdrant offers various deployment options, including self-hosting or utilizing cloud services. This flexibility provides users with options based on their infrastructure preferences.
Cons:
- Complex Implementation: The implementation and management of Qdrant can be complex. It requires expertise in distributed systems and a deep understanding of its inner workings, which could pose a challenge for users without specialized knowledge.
- Potential Overhead Costs: Setting up and managing Qdrant might come with additional overhead costs, either in terms of finding personnel with the right expertise or investing in training existing teams.
Use Cases:
- Suitable for businesses with the expertise to manage the complexity of an open-source solution.
- Offers flexibility in deployment, making it a versatile choice for different infrastructure preferences.
4. MongoDB
Known for its document database, MongoDB offers Atlas search with vector similarity search capabilities.
Pros:
- Universal Database: MongoDB, known for its document database, offers Atlas search with vector similarity search capabilities. Its universal database nature enables it to handle various data types, including vectors, reducing database management complexity.
- Community Support: MongoDB boasts an extensive community, providing resources and expertise for users. This community support is valuable for troubleshooting and optimizing the use of the platform.
- Versatility: Fully managed, scalable, ACID, and versatile, MongoDB serves as a universal database, making it suitable for a wide range of applications beyond vector storage.
- Advanced vector search capabilities: support additional CRUD , full text search capabilities like filtering combined with vector search.
Cons:
- Limited at 2048 dimensions for vector storage.
Use Cases:
- Suitable for users looking for a universal database solution capable of handling various data types, including vectors.
- Attractive for a fully managed vector storage solution on AWS or Azure or GCP.
- Ideal for scenarios where community support and resources are crucial for troubleshooting and optimization.
- A versatile choice for businesses with diverse data management needs beyond vector storage.
Operational Considerations:
- pgvector: Provides a familiar SQL interface but may require careful schema design for optimal performance.
- Pinecone: Offers a fully-managed service, reducing operational overhead, but may be limited in broader database functionalities.
- Qdrant: Requires expertise in distributed systems for implementation but provides flexibility in deployment.
- MongoDB: Fully managed database and data platform which provides a wide range of database capabilities.
Vector Store ranking from Retool
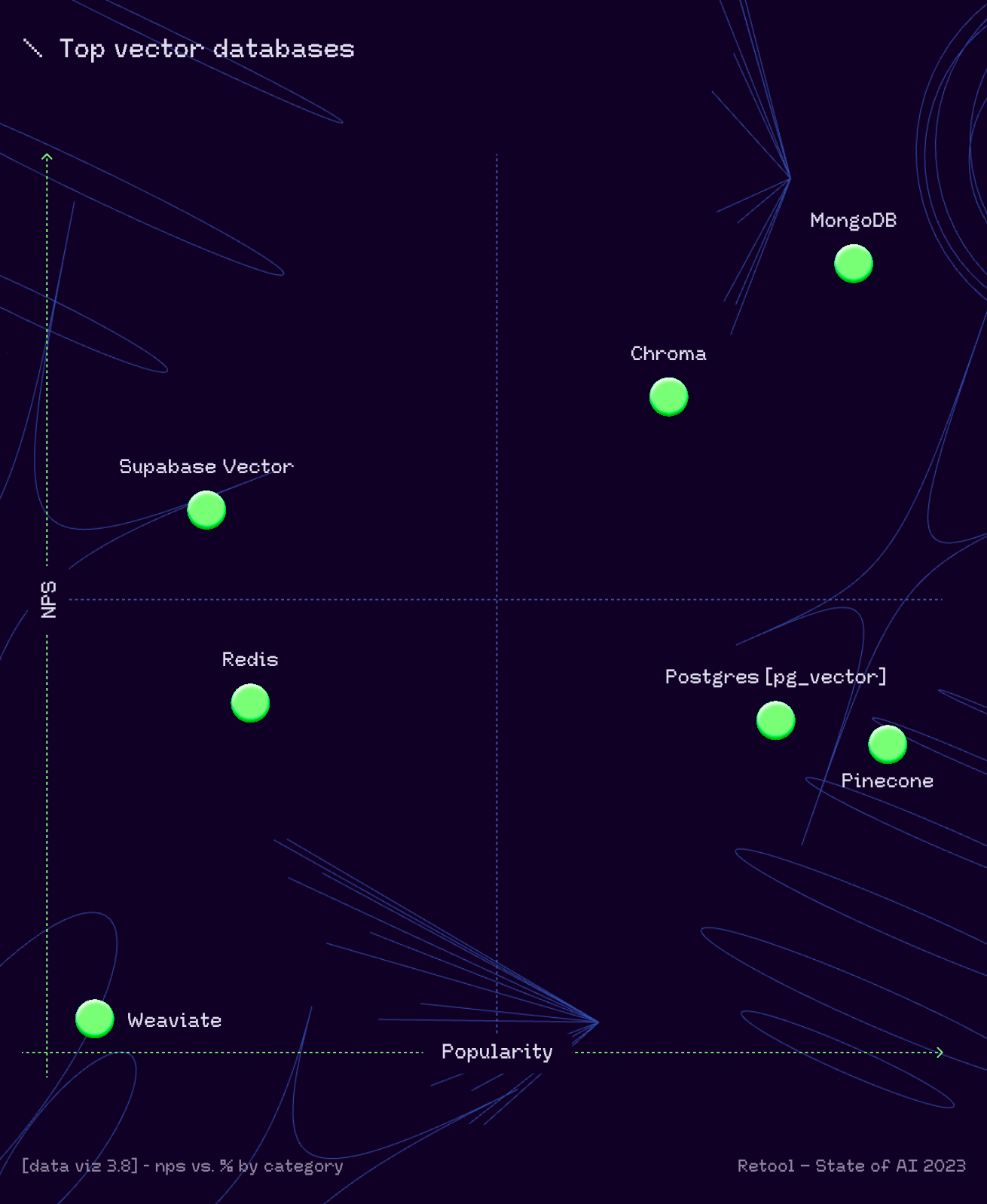
From https://retool.com/reports/state-of-ai-2023
Conclusion
In conclusion, the choice of a vector store depends on your specific requirements, existing infrastructure, and the nature of your data. Consider factors like integration ease, use case fit, and operational considerations when making your decision. Each solution has its strengths, and by aligning those strengths with your needs, you can ensure efficient and effective vector storage and similarity search in your applications.
Comments
Loading comments…