
AWS Lambda Trigger Using CDK & S3
Lambda functions can be called or invoked directly from the Lambda console, the Lambda API, the AWS SDK, the AWS CLI, and AWS toolkits. You can also configure other AWS services to invoke your function, or you can configure Lambda to read from a stream or queue and invoke your function.
The interesting thing about Lambda is that it has native integrations with 200 service offerings from AWS. This means you can use any of these serices to trigger the lambda functions.
If you are an AWS enthusiast and wanting to learn more about Lambdas and S3 for your project or an upcoming interview, you have come to the right place. You can either follow along with the code presented in this article or you can get the code from the GitHub — CDK Lamba S3 Event Listener.
If you are using this GitHub repo, follow the readme for setting up the project in your PC.
Lambda Trigger
A trigger is a Lambda resource or a resource in another service that you configure to invoke your function in response to lifecycle events, external requests, or on a schedule. Your function can have multiple triggers.
I will show you, one of the ways you can trigger or invoke the lambda functions using S3 events. For a brief understanding of this article, have a look at the workflow image below.
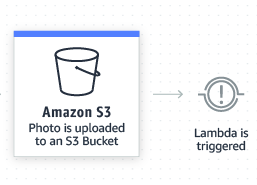
>
Lambda S3 Event Trigger Workflow
Yes, it is going to be that simple, and not many components are required for us to implement this workflow using S3 triggers.
Each trigger acts as a client invoking your function independently. Each event that Lambda passes to your function only has data from one client or trigger.
Objectives
-
Setup AWS CLI and CDK for the development environment
-
Generate a CDK app
-
Write some python code for creating a Lambda function and S3 Bucket.
-
Attaching S3 events as a trigger for the created Lambda function
-
Deploy and run the app in AWS
Prerequisites for following this article
-
AWS free tier account
-
NPM and Node v12+ installed
-
Python v3.6+ version installed
-
Your Favorite code editor to write some lambda handler code
NOTE: This article will not cost you any money if you follow along. We will be utilizing the free tier usage only for this article.

Image Source—AWS
You can learn more about the free tier by visiting this link — AWS Free Tier
Setup AWS and CDK for the development environment
Before starting to write some code, you will need to do two things —
Follow the above links to set up your IAM credentials and AWS CDK for the project. If you face any difficulties while setting up IAM credentials or CDK, comment on this article so that I can help you resolve the issues.
Generate a CDK app
Once you have successfully set up CDK, it is time to get started with creating the project using CDK. Run the below command to initialize a CDK project —
$ mkdir cdk-lambda && cd cdk-lambda
$ cdk init app --language=python
cdk init initializes the project and the structure will look something like as shown below —
.
├── README.md
├── app.py
├── cdk.json
├── cdk-lambda
│ ├── __init__.py
│ └── cdk-lambda_stack.py
├── requirements.txt
├── setup.py
└── source.bat
As an additional step, create a folder with the name — lambda inside the project directory and create a python file with the name — LambdaListener.py inside the lambda directory. After this, the project structure will look something like the below —
.
├── README.md
├── app.py
├── lambda
│ └── LambdaListener.py
├── cdk.json
├── cdk-lambda
│ ├── __init__.py
│ └── cdk-lambda_stack.py
├── requirements.txt
├── setup.py
└── source.bat
After the init process completes and the virtualenv is created, you can use the following step to activate your virtualenv for Linux and MacOS.
$ source .venv/bin/activate
If you are working on a Windows platform, you would activate the virtualenv like this:
% .venv\Scripts\activate.bat
Now, let's add some dependencies that we will be needing to successfully run this project. Place following code inside requirements.txt file —
aws_cdk.core
aws_cdk.aws_s3
aws_cdk.aws_s3_notifications
aws_cdk.aws_lambda
Once added, run the below command to install the required dependencies —
$ pip install -r requirements.txt
Create Lambda function and S3 Bucket
Lambda is a compute service that lets you run code without provisioning or managing servers.
You organize your code into Lambda functions. Lambda runs your function only when needed and scales automatically, from a few requests per day to thousands per second. You pay only for the compute time that you consume — there is no charge when your code is not running.
You can invoke your Lambda functions using the Lambda API, or Lambda can run your functions in response to events from other AWS services. For example, you can use Lambda to:
-
Build data-processing triggers for AWS services such as Amazon Simple Storage Service (Amazon S3) and Amazon DynamoDB.
-
Process streaming data stored in Amazon Kinesis.
-
Create your own backend that operates at AWS scale, performance, and security.
In our project, we will be using Amazon Simple Storage Service (Amazon S3) events to trigger the lambda function and record the event data. Following is our CDK stack code — cdk-lambda_stack.py
from aws_cdk import (aws_iam as iam,
aws_lambda as _lambda,
aws_s3 as s3,
aws_s3_notifications as s3_notify,
core as cdk)
class CdkLambdaStack(cdk.Stack):
def __init__(self, scope: cdk.Construct,
construct_id: str, **kwargs) -> None:
super().__init__(scope, construct_id, **kwargs)
# create new IAM group and use
group = iam.Group(self, "VSGroup")
user = iam.User(self, "VSUser")
# Add IAM user to the group
user.add_to_group(group)
# Create S3 Bucket
bucket = s3.Bucket(self, 'vs-bucket')
bucket.grant_read_write(user)
# Create a lambda function
lambda_func = _lambda.Function(self, 'LambdaListener',
runtime=_lambda.Runtime.PYTHON_3_8,
handler='LambdaListener.handler',
code=_lambda.Code.asset('cdk_lambda\lambda'),
environment={'BUCKET_NAME':
bucket.bucket_name})
# Create trigger for Lambda function using suffix
notification = s3_notify.LambdaDestination(lambda_func)
notification.bind(self, bucket)
# Add Create Event only for .jpg files
bucket.add_object_created_notification(
notification, s3.NotificationKeyFilter(suffix='.jpg'))
This stack will create an S3 bucket and a Lambda function. A notification handler will be created that will listen to the .jpg file create events in the s3 bucket. Once create event is fired, lambda function will get triggered and log the event inside cloudwatch logs. Below is the python code of the lambda function — LambdaListener.py
import boto3
import os
s3 = boto3.client('s3')
def handler(event, context):
bucket_name = (os.environ['BUCKET_NAME'])
key = event['Records'][0]['s3']['object']['key']
try:
# Log the event
print("[LambdaListenet] New file with name {} created in bucket {}".format(key, bucket_name))
response = {'status': 'success', 'key': key}
return response
except Exception as e:
print(e)
print("[Error] :: Error processing file {} from bucket {}. ".format(key, bucket_name))
raise e
In this lambda handler, we are going to receive the S3 event details and we will log that detail inside cloudwatch logs. Soon I will show this in action after we deploy this app to AWS.
Deploy and run the app in AWS
Now let us deploy this CDK project to AWS and see it in action.
All CDK Toolkit commands start with cdk, which is followed by a subcommand (list, synthesize, deploy, etc.).
Some subcommands have a shorter version (ls, synth, etc.) that is equivalent. Options and arguments follow the subcommand in any order. The available commands are summarized here.
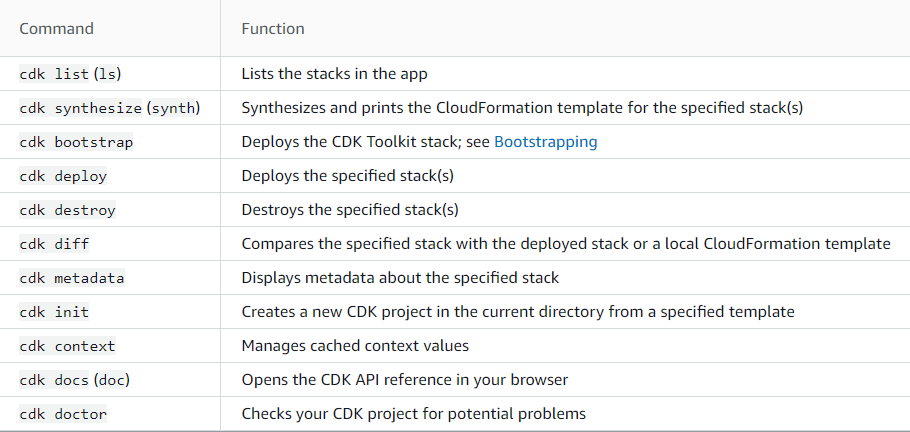
Image Source—AWS
For us, only two commands are required. Staying in the outermost directory of the project i.e., cdk_lambda, run the below-mentioned command to deploy the app on the cloud —
$ cdk bootstrap
Since this CDK app contains an S3 bucket and other resources, we have to bootstrap it using this command as per guidelines mentioned in AWS documentation.
The process of provisioning these initial resources is called bootstrapping.
The command cdk bootstrap will create minimal AWS resources required to run the app. Now run the following command to finally deploy our app on the cloud —
$ cdk deploy
This command will log few cloud formation logs that are created on resource creation or initiation. You should see something like below once it is finally completed —
✅ CdkLambdaStack ARN:
arn:aws:cloudformation:<region>:<acc-id>:stack/CDKLambda/123
Two stacks are created as visible under the CloudFormation console for that region —
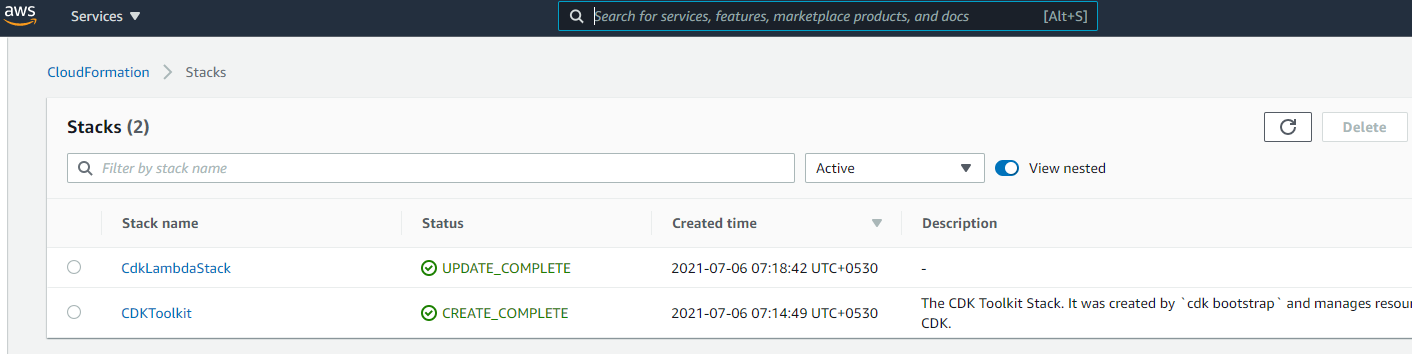
_CDK Stack in AWS CloudFormation
Now, if you upload a .jpg file inside the s3 bucket that was created using CDK stack, inside your cloudwatch log groups, you can see that the event is successfully logged.

Cloudwatch log group created for the Lambda Function
In the log groups shown above, you can select the latest one (usually the topmost log group), based on the date and time it was created, and you can see the log as shown below.

Event Logs inside Cloudwatch log group
How To Utilize This Project
There are many ways you can utilize this project.
For example, you can invoke an ECS task to initiate long-running processing on a video that was uploaded in an S3 bucket, you can invoke a glue job that will load the data inside the data catalog for data processing, etc.
This article gives you the easiest approach to get started with Lambda and S3 events and how you invoke a lambda using triggers from S3.
Find the GitHub link for this project here — https://github.com/varun-singh-01/lambda-s3-event-listener.
If you enjoyed this article, give me a clap and follow me for more updates.
More About The Author😄
I am a full-time software engineer with 4+ years of experience in Python, AWS, and many more technologies. I have started writing recently as it helps me to read more. I am looking forward to sharing technical knowledge and my life experiences with people out there.
Register Here for my Coders Weekly newsletter where I share interesting tutorials, python libraries, was, and tools, etc.

Github | LinkedIn | Twitter | Facebook | Quora | Coders Weekly
Comments
Loading comments…