
Introduction
LangChain is a formidable web scraping tool that leverages NLP models to simplify the scraping process. By capitalizing on its natural language understanding capabilities, LangChain offers an unparalleled ease of use and remarkable versatility, making it a game-changer in the world of web scraping.
Advantages of Using LangChain for Web Scraping
- Simplified Setup: LangChain offers a user-friendly interface, reducing the technical complexities associated with web scraping. Users do not need extensive programming skills to start scraping data.
- Natural Language Queries: With LangChain, you can use natural language queries to instruct the tool. Instead of writing complex code, you can simply describe what you want, and the language model will generate the necessary code for you.
- Versatility: LangChain is not limited to specific websites or data types. It can be used for scraping information from a wide range of websites, including news, e-commerce, social media, and more.
- Scalability: It is suitable for both small and large-scale scraping projects. You can easily scale your scraping operations to collect more data when needed.
Why LangChain for Web Scraping ?
Utilizing LangChain in web scraping offers a multitude of advantages. For example, it streamlines the process of scraping content from multiple websites. Instead of crafting custom scraping code for each site, LangChain simplifies the task by allowing you to define a schema that can be applied universally, saving time and effort.
Another significant benefit is the accessibility it offers to newcomers in the field. Even individuals with little to no prior knowledge of web scraping can efficiently manage and write code using LangChain. Its user-friendly interface and natural language capabilities make it approachable for beginners.
However, it’s worth noting that the LangChain document loader employs Playwright, which can sometimes lead to issues such as website blocking and delays in scraping. To mitigate these challenges, one can opt for an alternative approach by using the “requests” library for scraping instead of Playwright. This can significantly improve scraping efficiency and eliminate the potential slowdown associated with Playwright.
Using LangChain for Web Scraping
Now, let’s dive into the practical part and explore how to effectively use LangChain to scrape content from a website. In this example, we will attempt to extract data from a category page on Flipkart.
Dependencies Installation:
Before diving into the details, make sure to install the necessary dependencies using the following commands:
!pip install -q openai langchain playwright beautifulsoup4 tiktoken
!playwright install
!playwright install-deps
If you encounter async issues, you can resolve them by applying the following command:
import nest_asyncio
nest_asyncio.apply()
Setting Up OpenAI’s gpt-3.5-turbo-0613:
To interact with the OpenAI Language Model (LLM), you need to set your API key:
import os
from langchain.chat_models import ChatOpenAI
os.environ["OPENAI_API_KEY"] = "YOUR_API_KEY"
llm = ChatOpenAI(temperature=0, model="gpt-3.5-turbo-0613")
Asynchronous Loading of Web Pages:
- AsyncChromiumLoader: This module provides asynchronous loading capabilities for web pages. It allows you to fetch web content in an asynchronous manner.
- BeautifulSoupTransformer: This module is used for parsing and transforming HTML content using the BeautifulSoup library. BeautifulSoup is a popular Python library for parsing HTML and XML documents.
from langchain.document_loaders import AsyncChromiumLoader
from langchain.document_transformers import BeautifulSoupTransformer
loader = AsyncChromiumLoader(["https://www.flipkart.com/search?q=iphone"])
docs = loader.load()
bs_transformer = BeautifulSoupTransformer()
docs_transformed = bs_transformer.transform_documents(
docs, tags_to_extract=["div","span","h2","a"]
)
An instance of the AsyncChromiumLoader class is created with a single URL as a parameter. This URL is the search results page for iphone on the Flipkart website.
The loader object is used to load the HTML content from the specified URL asynchronously. The result is stored in the html variable. This html variable contains the raw HTML content of the Flipkart search results page.
The code transforms the HTML document into a BeautifulSoup format using the BeautifulSoupTransformer() function. Instead of extracting the entire HTML content, the code focuses on specific HTML tags, such as div,span, etc where relevant data might be located on a Flipkart page. These specified tags are provided in the tags_to_extract parameter to narrow down the extraction process. This approach helps to efficiently capture only the desired elements from the web page for further processing, rather than processing the entire page.
Splitting Text into Manageable Chunks:
splitter = RecursiveCharacterTextSplitter.from_tiktoken_encoder(
(chunk_size = 1000),
(chunk_overlap = 0)
);
splits = splitter.split_documents(docs_transformed);
To accommodate the limitations of passing large text content to OpenAI, we intend to utilize the RecursiveCharacterTextSplitter. This tool is employed to divide the data into smaller, more manageable chunks, making it feasible to process and interact with the content effectively. This approach helps us overcome any restrictions related to content size and ensures that we can work with manageable sections of the text
In this code, the chunk_size parameter is configured to a value of 1000, which means the splitter will aim to create chunks of text, each containing a maximum of 1000 tokens.
Additionally, the chunk_overlap parameter is explicitly set to 0,indicating that there should be no overlap between adjacent chunks. Each chunk will be distinct and not share any content with the next chunk.
Defining Data Extraction Schema:
from langchain.chains import create_extraction_chain
schema = {
"properties": {
"product_title": {"type": "string"},
"product_mrp": {"type": "integer"},
"product_description":{"type": "array", "items": {"type": "string"}},
"product_reviews_count":{"type": "string"}
},
"required": ["product_title","product_mrp","product_description"],
}
def extract(content: str, schema: dict):
return create_extraction_chain(schema=schema, llm=llm).run(content)
The exciting aspect is that, as I mentioned earlier, there’s no need for you to search for XPath, CSS selectors, or any specific path to extract the content you desire. Instead, all you have to do is outline the schema by specifying the appropriate keywords and data types for the content you want to extract.
Data Extraction:
Now, it’s time to extract the content using the defined schema. We call the extract function as follows
extracted_content = extract((schema = schema), (content = splits[0].page_content));
That’s all; the output that we receive is as follows:
[{''product_description'': [''128 GB ROM'',
''15.49 cm (6.1 inch) Super Retina XDR Display'',
''12MP + 12MP | 12MP Front Camera'',
''A15 Bionic Chip, 6 Core Processor Processor'',
''1 Year Warranty for Phone and 6 Months Warranty for ''
''In-Box Accessories''],
''product_mrp'': 55999,
''product_reviews_count'': ''2,03,188 Ratings & 7,645 Reviews'',
''product_title'': ''APPLE iPhone 14 (Blue, 128 GB)''},
{''product_description'': [''128 GB ROM'',
''15.49 cm (6.1 inch) Super Retina XDR Display'',
''12MP + 12MP | 12MP Front Camera'',
''A15 Bionic Chip, 6 Core Processor Processor'',
''1 Year Warranty for Phone and 6 Months Warranty for ''
''In-Box Accessories''],
''product_mrp'': 55999,
''product_reviews_count'': ''2,03,188 Ratings & 7,645 Reviews'',
''product_title'': ''APPLE iPhone 14 (Starlight, 128 GB)''},
{''product_description'': [''128 GB ROM'',
''15.49 cm (6.1 inch) Super Retina XDR Display'',
''12MP + 12MP | 12MP Front Camera'',
''A15 Bionic Chip, 6 Core Processor Processor'',
''1 Year Warranty for Phone and 6 Months Warranty for ''
''In-Box Accessories''],
''product_mrp'': 55999,
''product_reviews_count'': ''2,03,188 Ratings & 7,645 Reviews'',
''product_title'': ''APPLE iPhone 14 (Midnight, 128 GB)''},
{''product_description'': [''128 GB ROM'',
''15.49 cm (6.1 inch) Super Retina XDR Display'',
''12MP + 12MP | 12MP Front Camera'',
''A15 Bionic Chip, 6 Core Processor Processor'',
''1 Year Warranty for Phone and 6 Months Warranty for ''
''In-Box Accessories''],
''product_mrp'': 56999,
''product_reviews_count'': ''2,03,188 Ratings & 7,645 Reviews'',
''product_title'': ''APPLE iPhone 14 (Purple, 128 GB)''},
{''product_description'': [''128 GB ROM'',
''17.02 cm (6.7 inch) Super Retina XDR Display'',
''12MP + 12MP | 12MP Front Camera'',
''A15 Bionic Chip, 6 Core Processor Processor'',
''1 Year Warranty for Phone and 6 Months Warranty for ''
''In-Box Accessories''],
''product_mrp'': 63999,
''product_reviews_count'': ''4,44,393 Ratings & 2,591 Reviews'',
''product_title'': ''APPLE iPhone 14 Plus (Blue, 128 GB)''},
{''product_description'': [''128 GB ROM'',
''17.02 cm (6.7 inch) Super Retina XDR Display'',
''12MP + 12MP | 12MP Front Camera'',
''A15 Bionic Chip, 6 Core Processor Processor'',
''1 Year Warranty for Phone and 6 Months Warranty for ''
''In-Box Accessories''],
''product_mrp'': 63999,
''product_reviews_count'': ''4,44,393 Ratings & 2,591 Reviews'',
''product_title'': ''APPLE iPhone 14 Plus (Starlight, 128 GB)''},
{''product_description'': [''128 GB ROM'',
''17.02 cm (6.7 inch) Super Retina XDR Display'',
''12MP + 12MP | 12MP Front Camera'',
''A15 Bionic Chip, 6 Core Processor Processor'',
''1 Year Warranty for Phone and 6 Months Warranty for ''
''In-Box Accessories''],
''product_mrp'': 63999,
''product_reviews_count'': ''4,44,393 Ratings & 2,591 Reviews'',
''product_title'': ''APPLE iPhone 14 Plus (Purple, 128 GB)''}]
You can cross-check the previously mentioned output by comparing it with the image below.
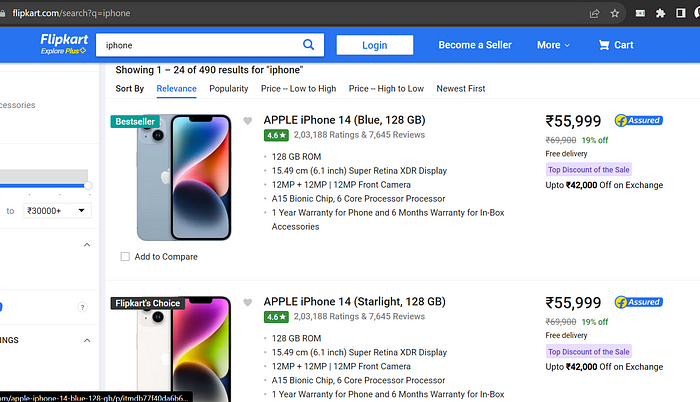 (Flipkart Category Page)
(Flipkart Category Page)
Conclusion:
While there may be some inaccuracies, this approach is particularly valuable when dealing with a large number of uncomplicated, similar websites simultaneously. It eliminates the need to create separate scripts for each individual site, streamlining the process. LangChain, in combination with OpenAI’s gpt-3.5-turbo model and various Python libraries, provides a powerful and efficient solution for web data extraction.
For more in-depth information on web scraping using Langchain, please visit the following link: https://python.langchain.com/docs/use_cases/web_scraping
Unlock the door to endless professional possibilities with me on LinkedIn! 🚀 Join the cool crew and hit that follow button. Let’s build our networks together and create a path to success!
Comments
Loading comments…