As digital branding evolves, the Search Engine Results Page (SERP) becomes an important part of enhancing brand visibility. SERP, an acronym for Search Engine Results Page, is the page of results that appears when you enter a question or a set of keywords into a search engine like Google, Bing, or Yahoo. The search engine’s algorithm processes the entered query and displays a page of results associated with the entered keywords.
For businesses, SERP can help improve brand visibility, understand their competitors, and drive organic traffic. With the use of SERP APIs or SERP tracking tools, developers, marketers, and businesses can extract valuable information such as rankings, snippets, and other relevant data from search engine pages.
By leveraging this information, they can refine their SEO strategies, identify gaps, and capitalize on opportunities, ultimately staying ahead in the digital marketplace.
This article provides a comprehensive guide into SERP API, exploring its features, use cases, and practical applications in market research and analysis.
Factors to consider when choosing SERP Tools
There are a few factors to consider when choosing a SERP API or tracking tool. These include:
- Request Limits: Request limits refer to the number of requests the API is able to handle per hour. Some range from as low as two thousand requests to as high as a hundred thousand. It is important to consider your data retrieval needs and ensure the chosen SERP API or tool provides an adequate number of requests to accommodate your usage patterns.
- Accurate Location Data: In some cases, you may want to pull results specific to certain geographic locations. This requires an API that has the capability to provide accurate location-based SERP data.
- Ability to pull both Mobile and Desktop data: Depending on the objective of pulling SERP data, it is important to ensure that the SERP API supports the extraction of both mobile and desktop data. This helps in understanding how search results vary across different devices.
Getting Started with Bright Data’s SERP API
Bright Data is a web data platform that offers web scraping solutions, proxies, and infrastructure. Bright Data’s SERP API infrastructure allows users to extract data (search, travel, hotels, maps, shopping, etc.) from popular search engine results pages in a structured format.
The platform offers a playground to allow prospective users to test out the API before committing. The image below shows the query builder for the SERP API. The query parameters include:
- Localization and Language Settings (gl, hl): Set to Nigeria, this indicates that the search results should be localized to Nigeria.
- Search Type Parameter (tbm): The search type parameter is set to “shop,” indicating that we are specifically interested in shopping results.
- Pagination Settings (start, num): Pagination parameter, which indicates what page of results it should start and end on. None was specified for the search query.
- Geo-Location Parameter (uule): The geo-location parameter is set to Abuja, Federal Capital Territory, Nigeria.
- Device Type (brd_mobile): It would return mobile-specific results.
- Parsing Options (brd_json): None specified. However, it is possible to specify if we want our data in JSON or HTML format.
Use Case 1: E-Commerce Price Monitoring
As a market researcher for a major consumer electronics business, a key objective is to be able to monitor the prices of our products and those of our competitors across various online platforms. This information helps us adjust our pricing strategy to remain competitive in the market and helps us better understand how our marketplace ranks online.
The image below shows Bright Data’s SERP API playground. The parameters for the query builder have been set, so it shows laptops being sold in the location entered.
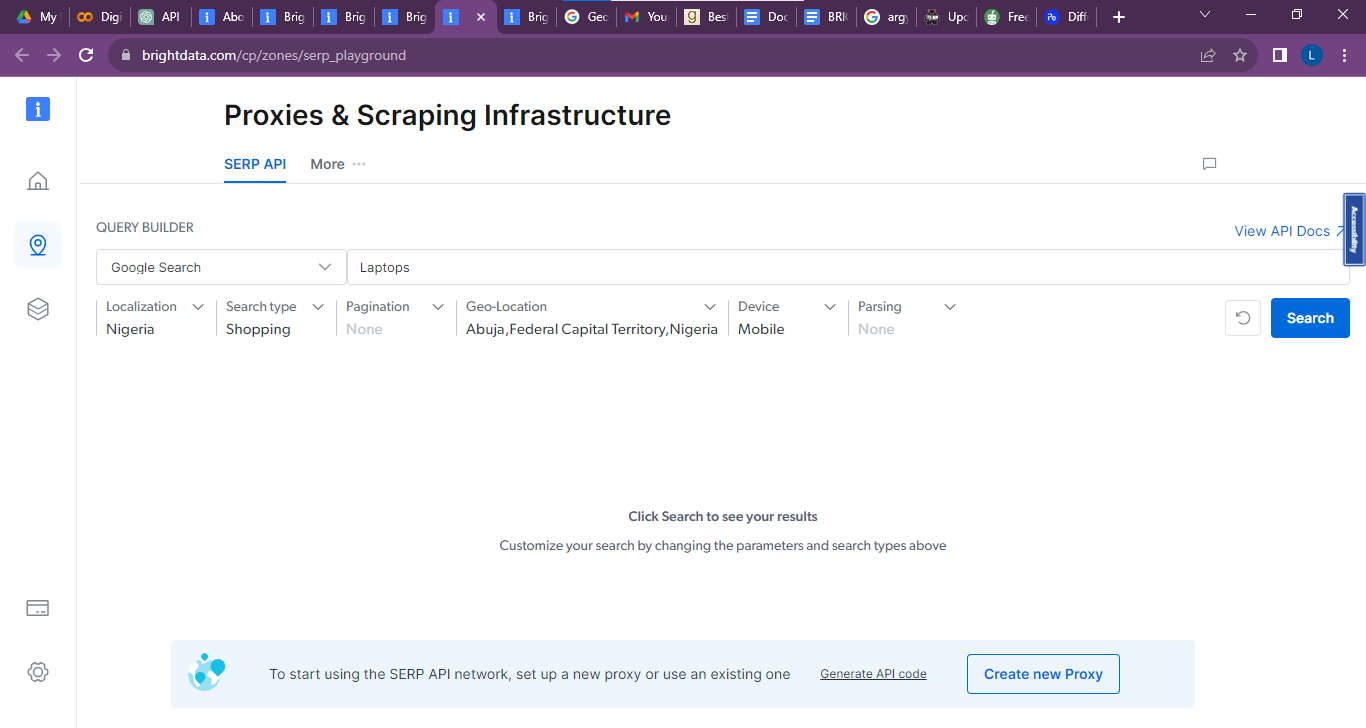
The query parameters specified above give the below search results. On the left-hand side is an overview of the search engine results page. This includes sellers (for example, Konga), the laptop specifications, and the selling price. The information provides an idea of competitors’ selling prices.
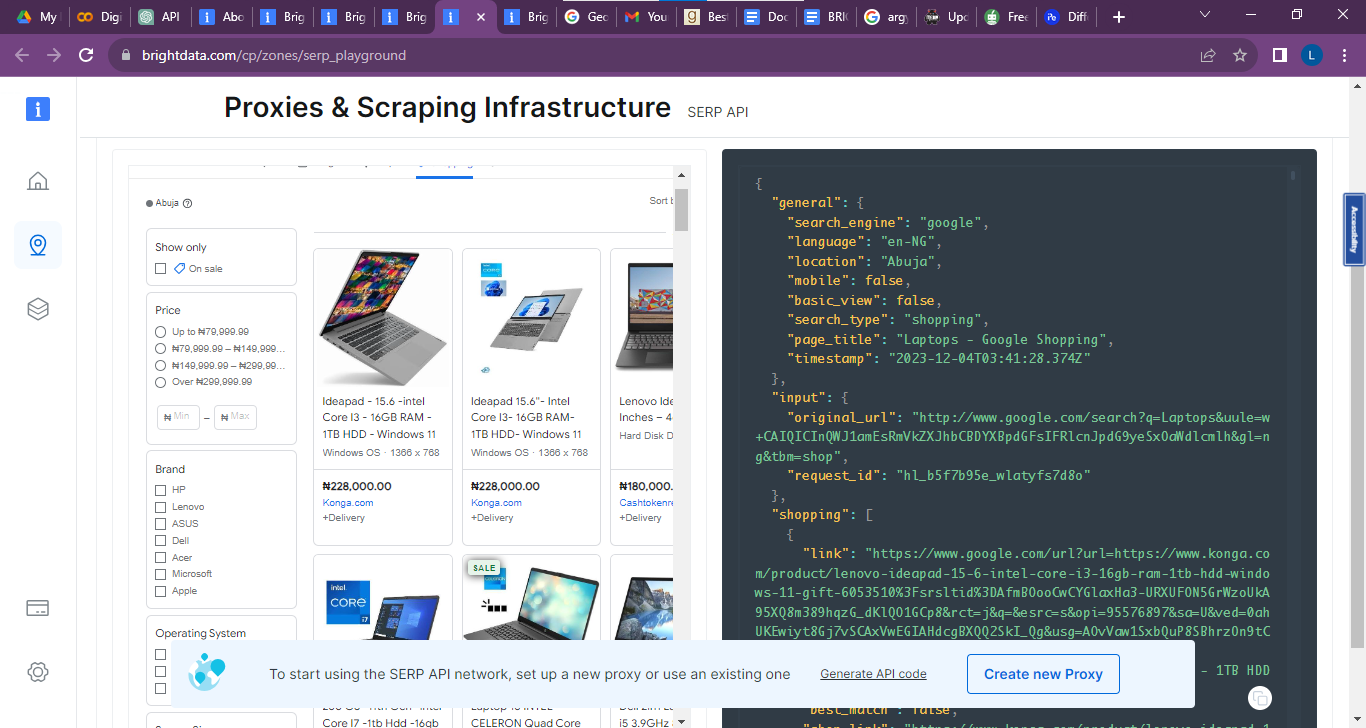
It also shows the ranking, as top-ranked sellers are shown at the top of the page. The extracted HTML data is displayed in the code editor on the right-hand side.
Use Case 2: Website Rankings and SEO Insights for a Local Pizzeria
As a marketer for a local pizzeria in Abuja, I want to know how my website or pizza offerings ranks when customers search for Pizzas in Abuja.
From the SERP data generated, a few metrics to pull insights from include:
- Ad placements of running paid campaigns of competitors.
- Organic search positions of our local pizzeria and those of key competitors.
- Website SEO performance.
Additionally, the image below shows the top-ranking search results — Domino’s Pizza and Galaxy Pizza.
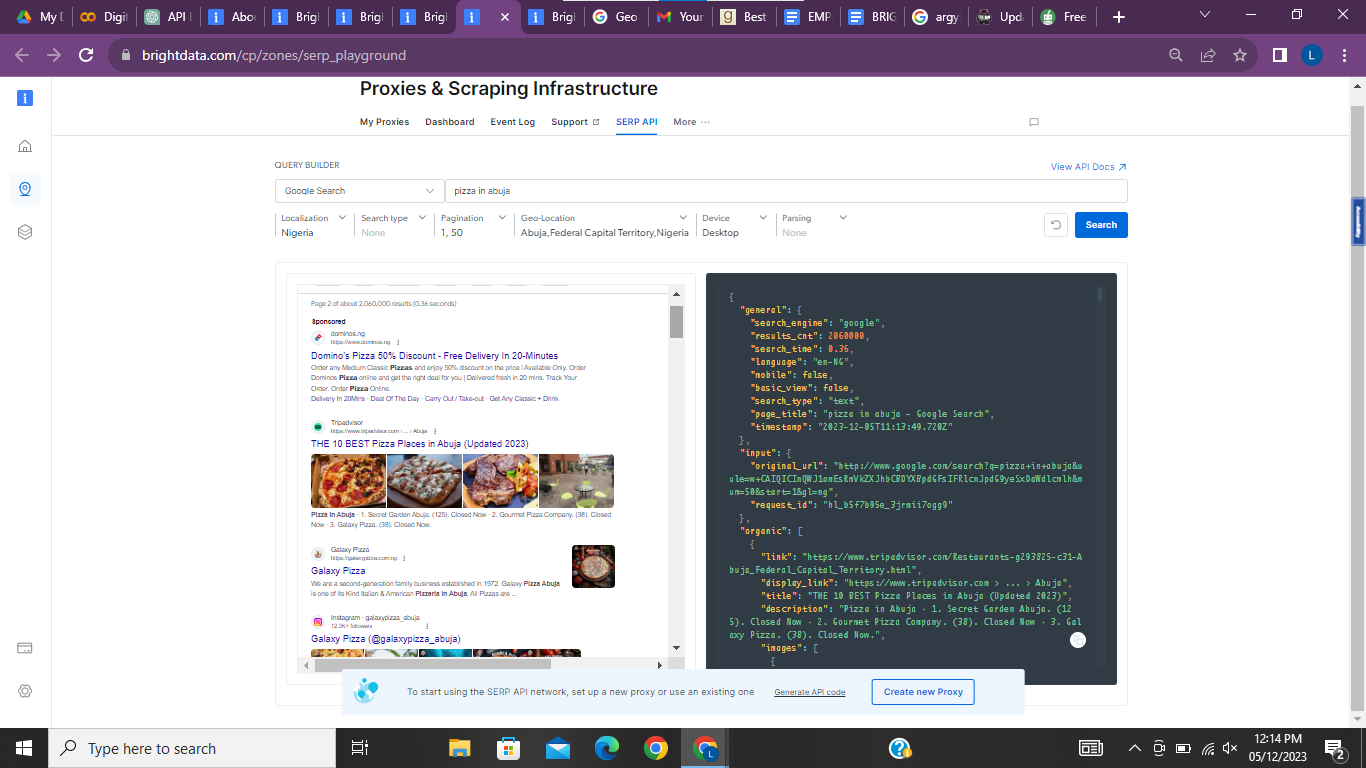
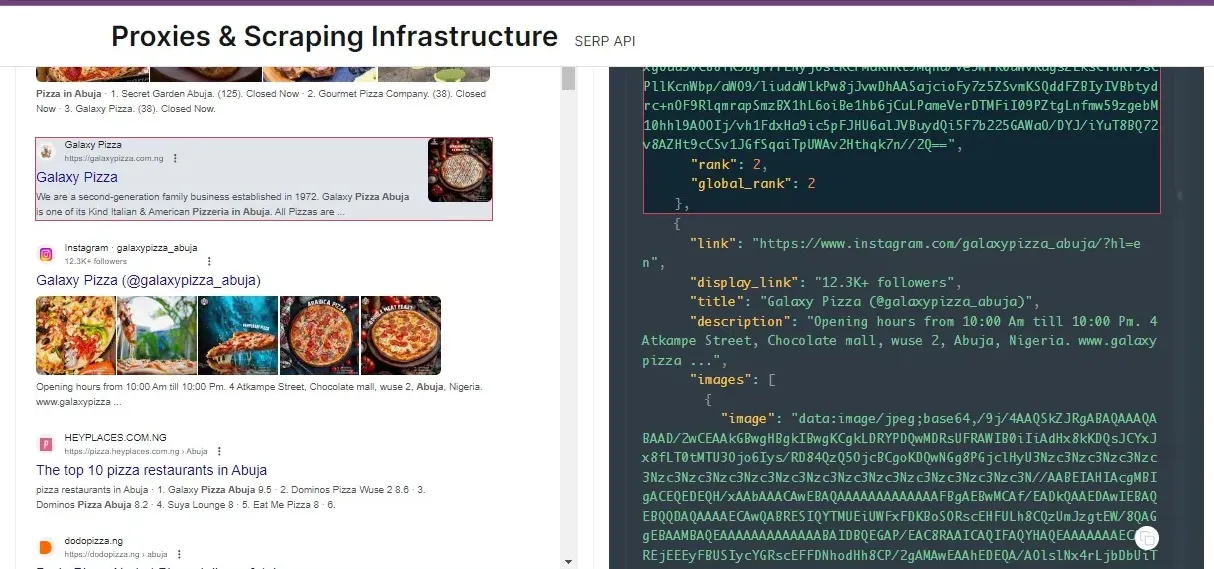
A deeper look into the HTML code shows the page rank for the selected search results, the link, description, and image info.
Setting up a SERP API account on Bright Data
- Sign-up: Sign up easily and seamlessly on Bright Data using a Google account or your company email address.
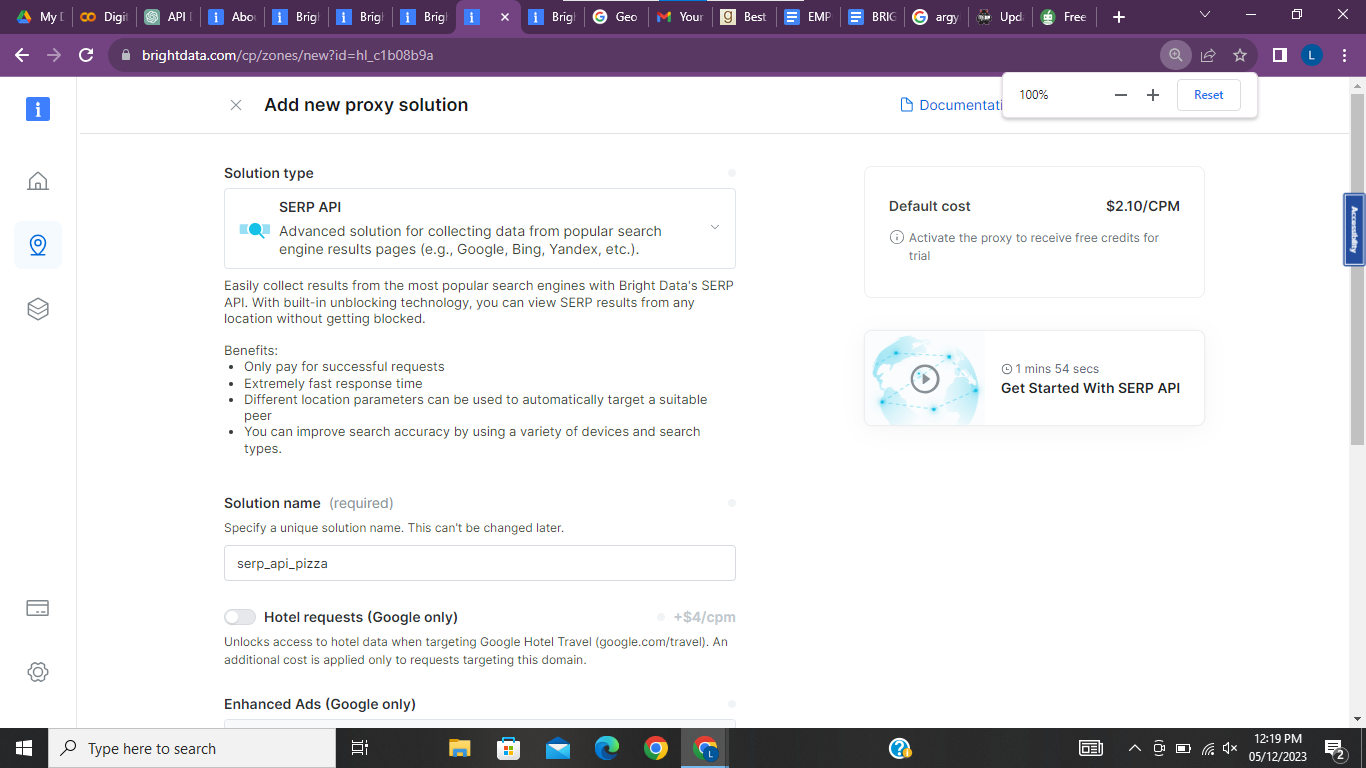
- API Access: To get API access, you need to create a SERP API proxy and configure it.
- Name your proxy, note that this name cannot be changed afterward so choose a unique name.
- Specify your Ads choice: There are three available options:
- Off, the default setting which fetches organic search results and ads
- On, which fetches a more diverse range of search results and ads, and
- Ads only, which fetches ads exclusive to your search query.
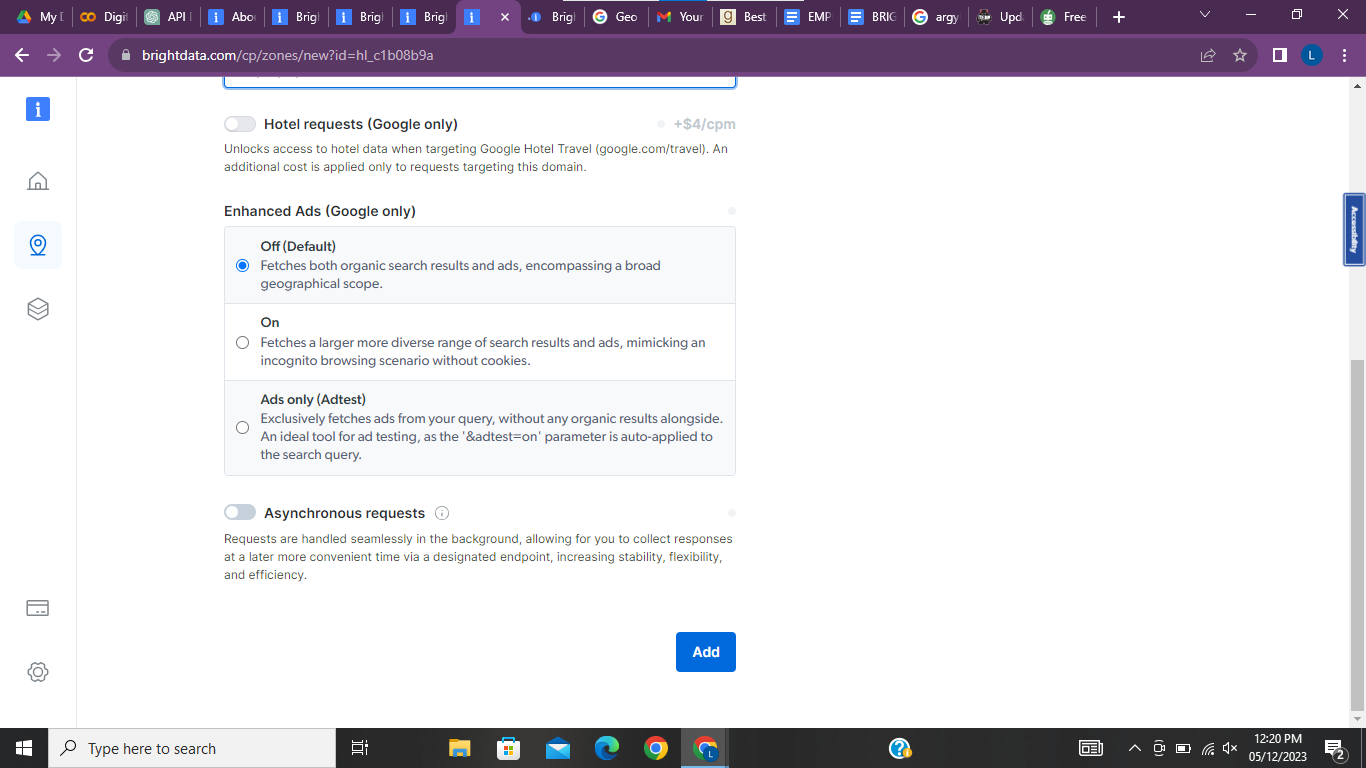
- Specify Asynchronous requests: Bright Data extends the flexibility of sending requests at a particular time and collecting the data later, with a maximum allocated time of 24 hours.
- Click on ‘Save and Activate’ to conclude the setup process, and you have successfully set up your SERP API.
- New users are eligible for a free trial account to explore the SERP API capabilities. Billing information is required for future transactions, but during the free trial, no charges will be incurred even after adding billing details.
- Read the API documentation to better understand the API Credentials
Extract your first Google Search results with Bright Data’s SERP API
Bright Data’s SERP API allows multiple language integration options. Integration examples, your password, and port can be found in your account. The example below uses Python and the API documentation provides a detailed guide on using the API.
import json
import sys
import ssl
pip install beautifulsoup4
from bs4 import BeautifulSoup
ssl._create_default_https_context = ssl._create_unverified_context
The code above imports JSON, sys and ssl modules; and the beautifulsoup library.
print(''If you get error "ImportError: No module named \''six\''" install six:\n'' +
''$ sudo pip install six'')
print(''To enable your free eval account and get CUSTOMER, YOURZONE, and '' +
''YOURPASS, please contact sales@brightdata.com'')
The above code prints two strings. The first string prints an error message — ImportError with the message “No module named ‘six’’ related to installation of the six module. The second string provides contact information for enabling a free eval account and obtaining the CUSTOMER, YOURZONE, and YOURPASS credentials.
if sys.version_info[0] == 2:
import six
from six.moves.urllib import request
opener = request.build_opener(
request.ProxyHandler(
{''http'': ''http://brd-customer-hl_c1b08b9a-zone-serp_api_pizza-country-ng:vjh9rqih398s@brd.superproxy.io:22225'',
''https'': ''http://brd-customer-hl_c1b08b9a-zone-serp_api_pizza-country-ng:vjh9rqih398s@brd.superproxy.io:22225''}))
html_content = opener.open(''http://www.google.com/search?q=pizza'').read()
elif sys.version_info[0] == 3:
import urllib.request
opener = urllib.request.build_opener(
urllib.request.ProxyHandler(
{''http'': ''http://brd-customer-hl_c1b08b9a-zone-serp_api_pizza-country-ng:vjh9rqih398s@brd.superproxy.io:22225'',
''https'': ''http://brd-customer-hl_c1b08b9a-zone-serp_api_pizza-country-ng:vjh9rqih398s@brd.superproxy.io:22225''}))
html_content = opener.open(''http://www.google.com/search?q=pizza'').read()
The first line of code above makes an HTTP request to the Google search engine and retrieves the HTML content of the search results page for the query “pizza”.
The first ‘if’ block executes on the condition that the Python version is 2.0. It imports the six modules and uses it to import the request module from the six.moves.urllib package. It then creates an opener object that uses the ProxyHandler class to specify the proxy server to use for the request. Finally, it opens the URL and reads the HTML content of the page.
The second elif block executes if the Python version is 3.0. It imports the urllib.request module and creates an opener object that uses the ProxyHandler class to specify the proxy server to use for the request. Then, it opens the URL and reads the HTML content of the page.
# Parse the HTML content using BeautifulSoup
soup = BeautifulSoup(html_content, ''html.parser'')
The Python code above uses the beautifulsoup module to parse the HTML content stored in the html_content variable. The html.parser argument specifies the parser to be used for parsing the HTML content.
#Extract relevant information (e.g., titles, URLs) and create a JSON representation
results = []
for result in soup.find_all(''div'', class_=''tF2Cxc''):
title = result.find(''h3'').get_text()
url = result.find(''a'')[''href'']
results.append({''title'': title, ''url'': url})
The Python code above uses the find_all() method of the soup object to find all the HTML elements that match the specified tag and class. In this case, it finds all the div elements with the class tF2Cxc.
It extracts the text of the h3 element and the value of the href attribute of the first element. Then, it creates a dictionary with the title and URL keys and appends it to the results list.
#Save the JSON to a file
with open(''search_results.json'', ''w'') as json_file:
json.dump(results, json_file, indent=2)
Finally, the Python code above saves the results list to a file named search_results.json. The open() function opens the file in write mode, and the json.dump() function writes the contents of the results list to the file in JSON format. The indent argument specifies the number of spaces to use for indentation in the output file.
Conclusion
In conclusion, SERP APIs are a valuable resource for businesses looking to extract data from search engines. They provide multiple benefits such as analysing search engine performance, monitor rankings, improving website content and strategies, and making data-driven decisions to optimize product offerings. When choosing a SERP scraper API, it is important to consider factors such as pricing, key capabilities, and data export formats. By using a SERP API, businesses can save time and resources while obtaining valuable data from search engines.
Comments
Loading comments…