I used to scrape a specific e-commerce website in Europe. My script was designed to extract product information and prices, sending the data directly to my email. However, I encountered an unexpected error indicating that the resources I sought couldn’t be located. After extensive debugging and troubleshooting, I discovered that the website had updated its accessibility, restricting it to customers in Europe. Unfortunately, I was scraping from Nigeria, located in West Africa. I believed it was the conclusion of my efforts until I discovered the concept of web scraping with proxies. Using a proxy was a transformative factor; its effectiveness seemed almost magical. The proxy not only assisted me in surpassing limitations but also elevated the scale of my web scraping endeavors.
In our previous article titled Automated Web Scraping with Node.js and Puppeteer, we focused on explaining what web scrapping is all about, when to use it, and how to use it in Node.js. In this article, we will focus on the role of proxies in web scrapping. Though we have a working application that scraps the web there are so many limitations to what we can achieve with our current solution which we shall see as we progress.
What is web scraping?
Now, we already know that web scraping is the process of extracting data from websites. Let''s then discuss proxies a little bit more.
What are proxies?
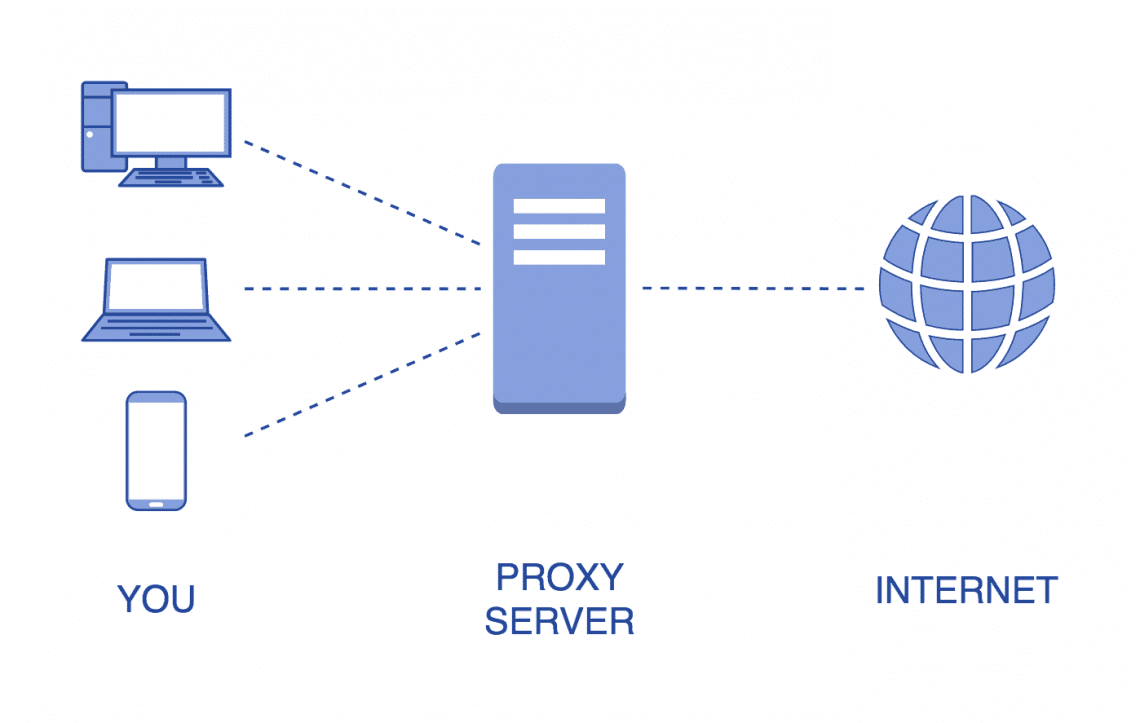
Proxies, in the context of computer networks and the internet, are intermediaries that act as a bridge between a user and the destination server. When you connect to a website or online service through a proxy server, your requests are first sent to the proxy server, which then forwards them to the destination server.
What are the types of proxies used in web scraping?
There are four types of proxies:
- Datacenter: Datacenter proxies are a type of proxy server that is not affiliated with an Internet Service Provider (ISP) or an Internet connection at a physical location. Instead, they are hosted in data centers, which are facilities designed to house multiple servers and networking equipment.
- Residential: Residential proxies are IP addresses assigned by Internet Service Providers (ISPs) to homeowners. These proxies are associated with real residential addresses, making them appear as if they are regular users accessing the internet from their homes.
- Static Residential (aka ISP): Static residential proxies are a type of residential proxy with a fixed, unchanging IP address. Unlike dynamic residential proxies, which may rotate through a pool of IP addresses assigned to different users, static residential proxies maintain a consistent IP address for the user.
- Mobile: Mobile proxies are a type of proxy server that routes internet traffic through mobile devices’ cellular networks, thereby using mobile IP addresses. Unlike traditional residential or datacenter proxies, which are associated with fixed-line broadband connections, mobile proxies use IP addresses assigned to mobile devices by mobile network providers.
Why do we need proxies for web scraping?
For efficient and scalable web scraping, proxies play a vital role by making sure of the following:
- IP Rotation and Avoiding Blocks: When you send a large number of requests to a website within a short period, the website’s server might identify this behavior as suspicious or even malicious, leading to your IP address being blocked. Proxies allow you to rotate through different IP addresses, making it more difficult for the website to detect and block your scraping activity.
- Geographical Distribution: Some websites may have restrictions on access based on geographical location. Proxies located in different regions or countries enable you to access content as if you were in those locations, helping you overcome such restrictions.
- Scalability: Proxies enable you to distribute your web scraping requests across multiple IP addresses, making it easier to scale your scraping efforts. This is especially important when dealing with large amounts of data or when scraping from websites with rate-limiting policies.
- Anonymity and Privacy: Proxies can add a layer of anonymity to your web scraping activities by masking your actual IP address. This can be useful if you want to protect your identity or if you’re scraping sensitive information.
- Avoiding Captchas: Some websites implement security measures like CAPTCHAs to prevent automated scraping. Proxies can help you bypass these measures by changing your IP address, reducing the likelihood of encountering CAPTCHAs.
- Compliance with Website Terms of Service: Proxies can be used to comply with the terms of service of a website. Some websites explicitly mention in their terms that automated access or scraping is not allowed. By using proxies, you can minimize the impact of your scraping activities on the target website and reduce the risk of being blocked.
There are several platforms that manage proxies for web scraping. Some examples are: BrightData, ScraperAPI, ScrapFly, ScrapingAnt just to name a few. But today we will dive more into one of the most popular and user-friendly platforms called Bright Data.
Introducing Bright Data: A Reliable Proxy Solution
Bright Data is the world’s #1 web data platform. Fortune 500 companies, academic institutions, and small businesses all rely on Bright Data’s solutions to retrieve crucial public web data in the most efficient, reliable, and flexible way.
Bright Data''s Scraping Solutions
Bright Data tackles the challenges in web scraping from different angles:
- Scraping Browser: Simply connect your Puppeteer, Playwright, or Selenium scripts to Bright Data’s browser. All proxy and unlocking operations are seamlessly taken care of behind the scenes.
- Web Scraper IDE: Reduce development time substantially by using ready-made JavaScript functions and code templates from major websites to build your web scrapers quickly and in scale.
- SERP API: Collect parsed search engine results
How to Scrape with Bright Data Solution
Using the Bright Data Scraping Browse approach, we will be scraping articles in the In Plain English website. In Plain English is a tech-focused media company and home to some of the world’s most recognizable tech publications.
Our solution will retrieve the titles of articles that are tagged web scraping on the blog page.
Set up
- Create a directory and name it web_scraping, then open it on your IDE(vs code preferably)
- Run the code below in your terminal to initialize npm in your project
npm init –y - Install the following packages puppeteer-core, express, and dotenv by running:
npm i express puppeteer-core dotenv - Sign up on Bright Data to generate your username, password, and host.
Step 1
Create a .env file on the root directory and populate it with the details you generated from BrightData as seen below:
HOST=<BrightData_Host>
USERNAME=<BrightData_Username>
PASSWORD=<BrightData_Password>
Step 2
On the root directory, create a file called server.js. Inside the server.js file add the code below:
const express = require(''express'');
const runScraper = require(''./scraper'');
const app = express();
const PORT = 8002;
app.listen(PORT, async function onListen() {
runScraper();
console.log(`Server is up and running on port ${PORT}`);
});
Step 3
On the root directory, create a file called scraper.js. Inside the scraper.js file add the code below:
const puppeteer = require(''puppeteer-core'');
const dotenv = require(''dotenv'');
dotenv.config();
const AUTH = `${process.env.USERNAME}:${process.env.PASSWORD}`;
async function getArticlesByTag() {
let browser;
try {
browser = await puppeteer.connect({
browserWSEndpoint: `wss://${AUTH}@brd.superproxy.io:9222`,
});
const page = await browser.newPage();
await page.setViewport({
width: 1080,
height: 768,
});
await page.goto(''https://plainenglish.io/tags/web-scraping'');
page.setDefaultNavigationTimeout(2 * 60 * 1000);
const articles = await page.$$eval(''.PostPreview_desktopSmallMobileFullWidth__LlANY'', (gadgets) =>
gadgets.map((item) => ({
title: item.querySelector(''h3'').innerText,
}))
);
console.log(articles);
} catch (error) {
console.log(error);
} finally {
await browser.close();
}
}
module.exports = getArticlesByTag;
Step 4
On your package.json file, go to scripts, and add the line of code below:
"start": "node ''./server.js''"
Step 5
Start the server by running:
npm run start
Your terminal will log all the article titles as seen below:
Conclusion
One of the most difficult problems in web scraping is scaling, and the most important tools in scaling web scrapers are proxies.
Having a set of quality proxies can prevent our web scraper from being blocked or throttled, meaning we can scrape faster and spend less time maintaining our scrapers.